







目录
- 问题1:pytorch下,对多维tensor进行缩放
- 问题2:'PIL.Image' has no attribute '****'
- 问题3:ImportError: cannot import name 'imread'
- 问题4:models/bird/netG.pth is a zip archive (did you mean to use torch.jit.load()?)
- 问题5:模型的保存与加载
- 问题6:UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 226: illegal multibyte sequence
问题1:pytorch下,对多维tensor进行缩放
问题原因:有的时候想要把得到图像的尺寸过大过小,想要对生成的tensor张量进行缩放,同时要保持原有图像等比例。如现在有一个tensor,他的大小是:[64,3,256,256],64代表batch size,3表示通道数,256代表长和宽,想要将其缩小为32*32的尺寸。
解决方案:我们可以使用transform.resize(),但在试过后,发现使用torch.nn.functional.interpolate会更好用
首先说明其参数:torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None)
- input是我们的输入张量(Tensor)
- size是输出大小
- scale_factor (float or Tuple[float]) 指定输出为输入的多少倍数
- mode是上采样算法的选择:有’nearest’, ‘linear’, ‘bilinear’, ‘bicubic’ , ‘trilinear’和’area’,其中默认是’nearest’
- align_corners (bool, optional) 如果设置为True,则输入和输出张量由其角像素的中心点对齐,从而保留角像素处的值。如果设置为False,则输入和输出张量由它们的角像素的角点对齐,插值使用边界外值的边值填充
使用样例:
print(train_mask.size())
# train_mask尺寸本来是[64,3,256,256]
train_mask = torch.nn.functional.interpolate(train_mask, scale_factor=1 / 4, mode='bilinear',align_corners=False)
#变换之后,train_mask尺寸变为[64,3,64,64]
print(train_mask.size())
问题2:‘PIL.Image’ has no attribute ‘****’
问题原因:这个是因为系统已经安装的PIL太新了,有些属性在新版中已经被弃用
解决方案:改回原来的版本就可以:pip install pillow==4.1.1,安装老版本pillow,最后会告诉你这个版本已经过时了,不用管。
问题3:ImportError: cannot import name ‘imread’
问题原因:“scipy”库的版本过高
解决方案:改回原来的版本:pip install scipy==1.2.1
问题4:models/bird/netG.pth is a zip archive (did you mean to use torch.jit.load()?)
问题原因:原来训练后保存参数时所在的pytorch环境和现在加载参数的pytorch环境可能不同,版本不一致,导致当时保存的参数现在读不出来。
解决方案:先在1.x版本下加载模型,然后在保存为非zip格式的,即设置use_new_zipfile_serialization=False 就行了。
#torch_version==1.x
import torch
from models import net
checkpoint = 'xxx.pth'
model = net()
model.load_state_dict(torch.load(checkpoint))
model.eval()
torch.save(model.state_dict(), model_path, use_new_zipfile_serialization=False)
对于这种情况,你也有可能需要使用 torch.jit.load() 方法来加载模型文件。torch.jit.load() 是用于加载 PyTorch JIT 模型的方法,它可以加载包含脚本化模型或跟踪模型的文件。
问题5:模型的保存与加载
问题描述:在实际运行当中,要注意每100轮epoch或者每50轮epoch要保存训练好的参数,以防不测(断电、断连、硬件故障、地震火灾等),这样下次可以直接加载该轮epoch的参数接着训练,就不用重头开始。
解决方案:
参数的保存:
torch.save(model.state_dict(), path)
参数的加载
model.load_state_dict(torch.load(path))
问题6:UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x80 in position 226: illegal multibyte sequence
问题原因:这个错误 “UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x80 in position 226: illegal multibyte sequence” 是在使用 Python 解码字符串时遇到的问题。
该错误发生在使用 ‘gbk’ 编解码器尝试解码一个字符串时,遇到了一个无效的多字节序列(illegal multibyte sequence)。这通常是因为尝试使用错误的编解码器或者字符串中包含了无效的字符。这里某个文件是gbk编码,其无法被解码。
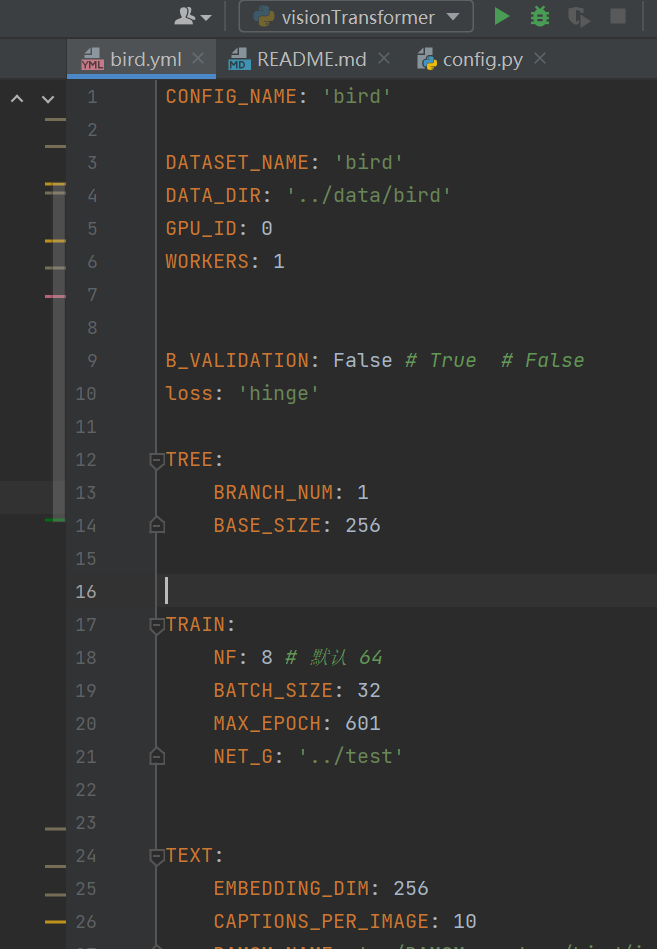
解决方案:看看是不是自己在yml文件或者其他文件中写了中文(如在下图中 不小心在注释写了中文,导致解码失败),删除就好了

















 7583
7583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











