







随着文本到图像扩散模型的发展,很多模型已经可以合成各种新的概念和场景。然而,它们仍然难以生成结构化、不常见的概念、组合图像。今年4月巴伊兰大学和OriginAI发表《It’s all about where you start: Text-to-image generation with seed selection》一文,提出了一种SeedSelect技术,微调Diffusion Model来改进该问题,获得了不错的效果:
原文地址:https://arxiv.org/abs/2304.14530
一、原文摘要
文本到图像的扩散模型可以在新的组合和场景中综合各种各样的概念。然而,他们仍然很难产生不寻常的概念,罕见的不寻常的组合,或者像手掌这样的结构化概念。它们的局限性部分是由于其训练数据的长尾特性:网络抓取的数据集非常不平衡,导致模型对分布尾部的概念表示不足。在这里,我们描述了不平衡训练数据对文本到图像模型的影响,并提供了补救措施。我们表明,通过在噪声空间中仔细选择合适的生成种子,我们将这种技术称为SeedSelect,可以正确地生成稀有概念。
SeedSelect是高效的,不需要重新训练扩散模型。我们评估了SeedSelect在一系列问题上的效益。首先,在少量语义数据增强中,我们为少量和长尾基准生成语义正确的图像。我们从扩散模型的训练数据的头部和尾部显示了所有类别的分类改进。我们进一步评估了SeedSelect在校正手的图像上的效果,这是当前扩散模型的一个众所周知的缺陷,结果表明它大大改善了手的生成。
二、为什么提出SeedSelect?
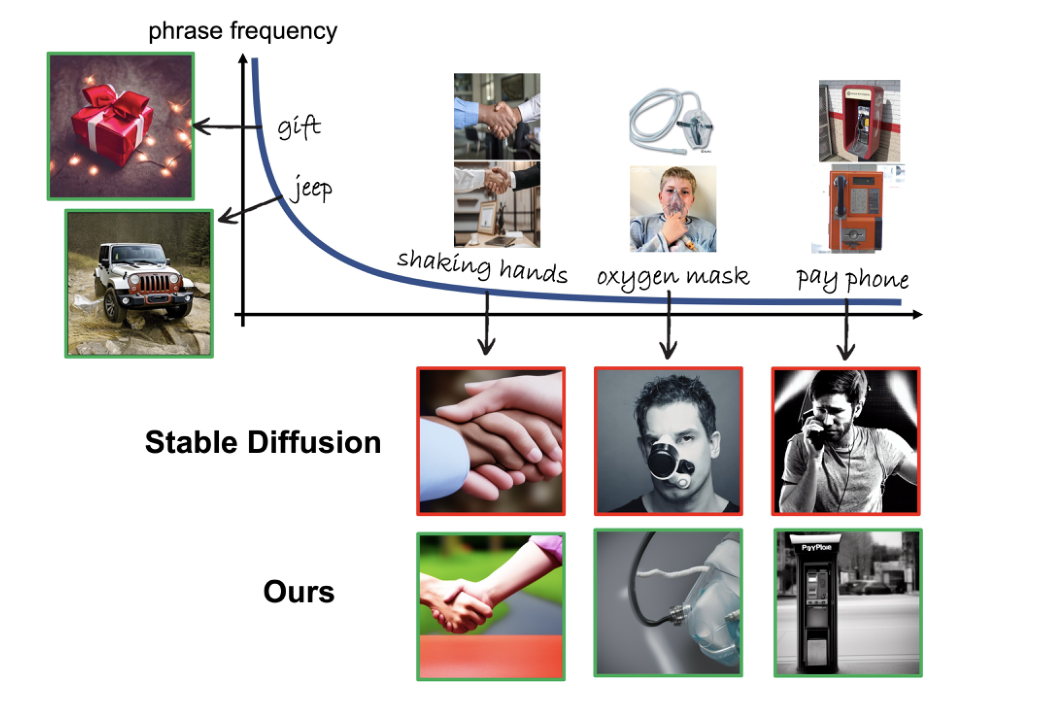
众所周知,扩散模型在文本-图像生成方面无论是在视觉效果还是在指标上面,均取得了令人惊讶的成果,但仍然在生成罕见的概念短语、结构化的对象等结果上存在局限性。
例如,当提示输入“Pine-Warbler”(一种鸟类)时,“稳定扩散”系统会生成松树球果的图像。
深度学习中的长尾效应:深度学习的长尾问题指的是在大规模数据集中,存在一些类别的样本数量非常少,而大部分样本都属于少数几个常见类别的情况。这些少数类别被称为“长尾类别”,而大部分样本属于的常见类别则被称为“头部类别”。
数据分布的不平衡特性导致模型倾向于头部类。深度学习模型在训练时通常会倾向于学习头部类别,因为这些类别的样本数量多,模型可以更好地学习它们的特征。而对于长尾类别,由于样本数量少,模型很难学习到它们的特征,导致预测准确率较低。
当前扩散模型的长尾效应:同样,扩散模型对于初始随机噪声及其文本提示的输入非常敏感。当一个扩散模型被训练为频繁出现的概念(例如“一只狗”)时,训练过程中使用了大量的输入空间学习将该空间映射到可行图像的方法。相比之下,对于罕见概念,模型仅使用了少量输入空间进行训练。这就导致了扩散模型的长尾效应。
基于此问题,作者假设:如果仔细选择噪声,扩散模型可以产生罕见的实例,而无需对模型进行任何过多的微调。
在此假设上,作者开发了一种有效的方法SeedSelect,用于少量种子选择,在初始噪声分布中找到那些可以从期望的概念生成图像的区域。
全文做出如下贡献:
- 量化了文本到图像扩散模型如何无法生成罕见概念的图像。
- 提出了一种新的方法SeedSelect,用于改进扩散模型中不常见概念的生成。它通过从几个训练样本中学习一代种子来运行。
- 提出了一种有效的bootapping技术来加速SeedSelect图像的生成。
- 在长尾学习和少量学习基准上获得了许多新的SoTA结果,包括细粒度基准,比其他语义数据增强方法有所改进。
- 最终实验结果表明SeedSelect比vanilla Stable Diffusion改进了手掌等结构化概念的生成。
三、Stable Diffusion基本原理
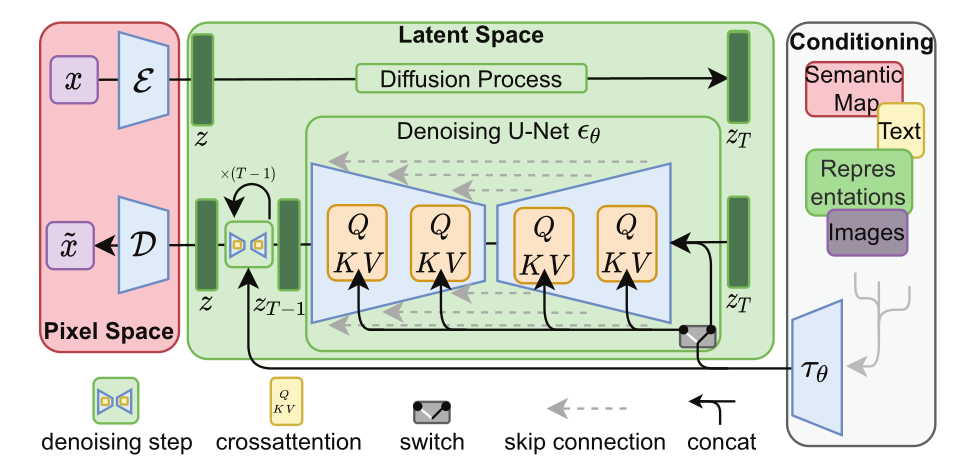
Stable Diffusion (SD)结构图如下图所示。
红色部分Pixel Space:训练编码器E将给定图像x映射到空间潜码z = E(x)。随后,解码器D负责重建输入图像,使D(E(x))≈x,从而确保潜在表示准确捕获原始图像。
绿色部分Latent Space:主体是一个去噪扩散概率模型(DDPM),其对学习到的潜空间进行操作,其在每个时间步长t产生一个去噪版本的输入潜zt。在去噪过程中,扩散模型可以以一个额外的输入向量为条件。
白色部分:条件信息。在Stable Diffusion中,额外的条件输入通常是由预训练的CLIP文本编码器产生的文本编码。给定条件提示y,条件向量记为c(y)。
损失函数为:
L
=
E
z
∼
E
(
x
)
,
y
,
ε
∼
N
(
0
,
1
)
,
t
[
∥
ε
−
ε
θ
(
z
t
,
t
,
c
(
y
)
)
∥
2
2
]
\mathcal{L}=\mathbb{E}_{z \sim \mathcal{E}(x), y, \varepsilon \sim \mathcal{N}(0,1), t}\left[\left\|\varepsilon-\varepsilon_{\theta}\left(z_{t}, t, c(y)\right)\right\|_{2}^{2}\right]
L=Ez∼E(x),y,ε∼N(0,1),t[∥ε−εθ(zt,t,c(y))∥22]
其中,z表示噪声,zt表示噪声的潜在编码向量,c(y)表示条件编码,t表示时间步长, ε \varepsilon ε是一个包含自注意力层和交叉注意力层的UNet网络。
四、Few-shot Seed Selection
4.1、目标
主要想法是使用少数训练图像: I 1 I^1 I1、 I 2 I^2 I2、 I 3 I^3 I3… I n I^n In,n为3~5,目标是找到一个初始张量 z T G z^G_T zTG,其生成的图像与训练图像相似,这种一致包括语义一致性和表现一致性:
- 语义一致性: L S e m a n t i c = dist v ( μ v , v G ) \mathcal{L}_{S e m a n t i c}=\operatorname{dist}_{v}\left(\mu_{v}, v^{G}\right) LSemantic=distv(μv,vG),其中 μ v \mu_{v} μv为真实图像集使用CLIP编码后的质心, v G v^{G} vG为生成图像使用CLIP编码后的特征,dist为欧几里得距离。
- 表现一致性: L A p p e a r a n c e = dist z ( μ z , z 0 G ) \mathcal{L}_{Appearance}=\operatorname{dist}_{z}\left(\mu_{z}, z^{G}_0\right) LAppearance=distz(μz,z0G),其中 μ z \mu_{z} μz为真实图像集使用VAE编码后的质心, z G z^{G} zG为生成图像使用VAE编码后的特征,dist为欧几里得距离。
最终 L T o t a l = λ L S e m a n t i c + ( 1 − λ ) L A p p e a r a n c e c \mathcal{L}_{Total}=λ\mathcal{L}_{S e m a n t i c} + (1-λ)\mathcal{L}_{Appearancec} LTotal=λLSemantic+(1−λ)LAppearancec
4.2、Seed Select
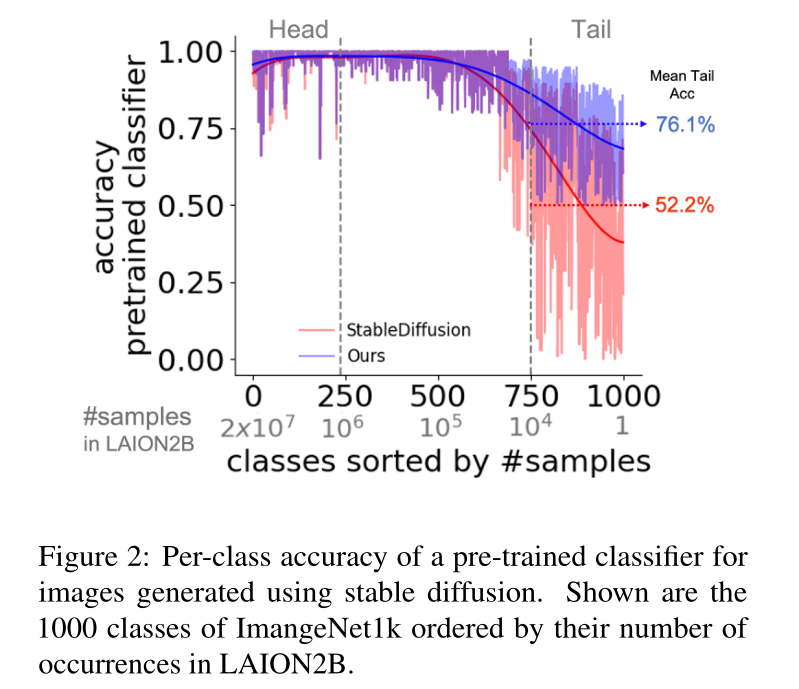
当用头部类训练时,模型学习将高斯分布的大部分映射到正确类的图像中。然而,对于尾部类,模型只能为该分布的有限区域生成正确的类。
那么如果可以定位分布的这些区域,就仍然可以从尾部类生成图像。基于此,提出通过在噪声空间中对种子进行优化来发现这些区域,从而提高与目标稀有概念的一小组训练图像的语义和外观一致性。
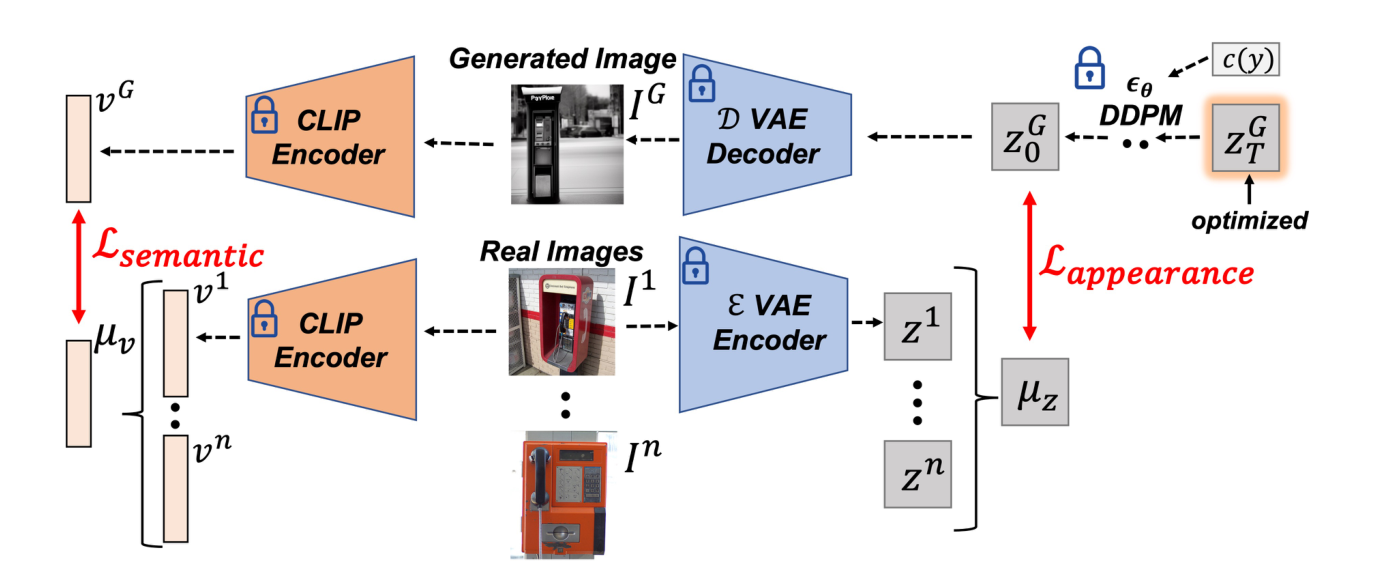
方法这一小节,我感觉作者并没有说的很清楚,下面是我结合图像的一些理解,如有错误,敬请指出:
如上图所示,固定VAE编码器、CLIP编码器、DDPM主扩散过程。选取部分罕见样本图像使用VAE和CLIP分别编码,然后选取罕见样本的文本c(y)作为输入,然后使用初始噪声生成图像
I
G
I^G
IG,然后将其与真实图像编码后的特征分别相比,利用语义损失和表现损失来微调,以找到合适的随机种子
z
T
G
z^G_T
zTG。
4.3、提高选取速度和质量
Contrasting classes:当从一组C类生成图像时,作者通过使用监督对比损失进一步提高训练收敛性和图像质量。这种损失发生在语义空间;它使语义向量vG更接近其类的质心µcv,并使其远离其他类的质心。更新后的语义损失为:
L Semantic = − log e − dist ( μ v c , v G ) ∑ c ′ ∈ C e − dist ( μ v c ′ , v G ) \mathcal{L}_{\text {Semantic }}=-\log \frac{e^{-\operatorname{dist}\left(\mu_{v}^{c}, v^{G}\right)}}{\sum_{c^{\prime} \in C} e^{-\operatorname{dist}\left(\mu_{v}^{c^{\prime}, v^{G}}\right)}} LSemantic =−log∑c′∈Ce−dist(μvc′,vG)e−dist(μvc,vG)
稳定训练:最后几个去噪步骤往往能够生成高质量的图像,为了加快收敛速度,作者计算了最后k步的所有图像语义一致性损失: L Semantic = ∑ i = 0 k L Semantic i \mathcal{L}_{\text {Semantic }}=\sum_{i=0}^{k} \mathcal{L}_{\text {Semantic }}^{i} LSemantic =∑i=0kLSemantic i,通过实验,最终选取了最后2步,即k=2。
使用bootstrap加快速度:首先,使用较少的迭代次数找到完整训练集的最优zGT。然后,使用自助法对训练图像的子集进行采样,并为子集找到最优的zGST,但是从zGT开始优化并生成图像。这个过程可以重复多次,以获得多样化的图像集。这种方法的优点是可以将单个图像的优化持续时间从几分钟缩短到几秒钟。
五、实验
5.1、数据集
作者在三个常见的几次分类基准上评估了SeedSelect:
- CUB-200:由200种鸟类的11,788张图像组成的细粒度数据集。200种数据被分成:100类作为训练集,50类作为验证集、50类作为测试集。
- miniImageNet:源自标准ImageNet数据集,由50000张训练图像和10000张测试图像组成,均匀分布在所有100个类,其中64个类用于训练,16个类用于验证,20个类用于测试。
- CIFAR-FS:从CIFAR-100数据集[33]中获得,使用与miniImageNet采样相同的标准。64个类用于元训练,16个类用于元验证,20个类用于元测试。每个类包含600个图像。
5.2、定量结果
Few-shot识别:
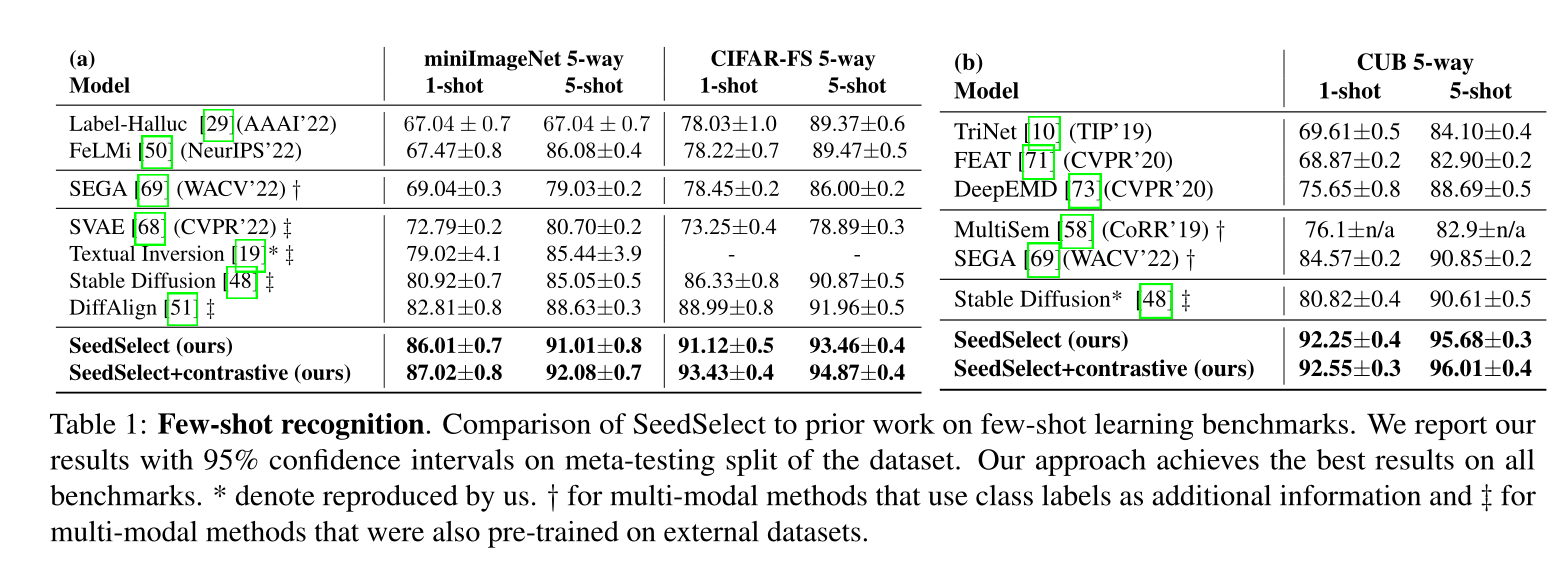
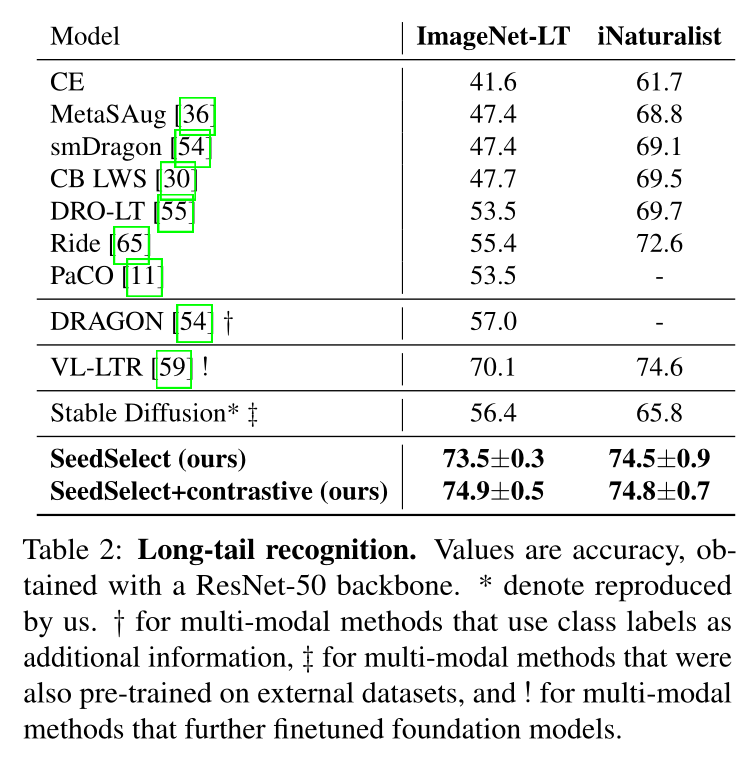
长尾分析:
主观评价(基于手掌):

5.3、视觉效果

六、讨论
尽管现代文本到图像生成模型非常强大,但其仍然存在一些缺点。特别是当扩散模型的训练集中频繁出现一个密切相关的概念时,它们往往会产生不正确的图像。
SeedSelect方法通过在噪声空间中仔细选择合适的生成种子进行微调,可以正确地生成稀有概念,准确意义上来讲,其主要在于微调Diffusion Model的种子选择机制,通过有效选择一个生成种子,驱动扩散模型生成语义一致性强、视觉效果好的合理图像。
但其仍然存在以下局限:
- 很难模仿训练图像的风格;
- 优化的zT是特定于提示符的,不会直接泛化到其他提示符;
- 仍然不能为非常罕见的概念生成图像
💡 最后
我们已经建立了🏤T2I研学社群,如果你还有其他疑问或者对🎓文本生成图像很感兴趣,可以私信我加入社群。
📝 加入社群 抱团学习:中杯可乐多加冰-深度学习T2I研习群
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝

















 7298
7298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











