










原文标题:Automatic Detection of Various Malicious Traffic Using Side Channel Features on TCP Packets
原文作者:George Stergiopoulos, Alexander Talavari, Evangelos Bitsikas & Dimitris Gritzalis
发表会议:ESORICS 2018: Computer Security
原文链接:https://link.springer.com/chapter/10.1007/978-3-319-99073-6_17#Tab1
中文标题:使用侧信道特征在TCP包中自动检测各种恶意流量
1 Motivation
背景:保护当今 IT 网络安全的最严重的开放问题之一是当前解决方案(即入侵检测和预防系统 (IDPS)、防病毒等)无法检测高级且通常精心定制的持续恶意攻击。此类攻击通常是针对特定受害者量身定制的,并且使用了安全社区目前不知道的复杂代码。安全公司需要不断更新其安全解决方案,但往往无法检测到“0-day”恶意软件和针对所有向量的自定义攻击,从向网站注入命令到检测加密的恶意软件流量。此外,某些攻击(例如 Web 应用程序破坏)利用无法有效检测到的恶意数据的自定义字符串和十六进制编码。
本文提出的动机:当前的解决方案利用软件、用户和服务的复杂模式匹配或行为分析来将正在进行的网络事件归类为可疑事件。尽管如此,误报和误报仍然困扰着基于签名的安全软件。另一方面,基于行为的模型具有更好的检测率,但需要很长时间才能有效地监控用户和系统和描述多个场景的大数据集才能准确检测恶意流量,通常是不切实际的大量数据和时间。除此之外,现代恶意软件使用加密流量或将自身注入白名单应用程序(例如浏览器)与 C&C 服务器通信并泄露数据,这使得行为分析和模式匹配在网络流量上的成功率更低。
2 论文主要工作
提出了一个网络流量监控系统,该系统通过网络捕获实现机器学习,以区分正常和多种类型的恶意 TCP/IP 流量。主要内容如下:
- 同时检测多种类型的恶意流量(未加密和加密的恶意软件流量或 shellcode 连接、网站破坏攻击、勒索软件下载的密码锁攻击等),使用 TCP 数据包的一些侧信道特征而不是复杂的特征或深度数据包检查。
- 在使用较少特征(例如,无 TLS、认证功能或深度数据包检查)的同时,使用类似的检测系统实现了相同或更好的总体检测率。
- 由于其特征集较小,系统在离线训练和测试期间提供比其他检测系统更快的训练和分类。
3 数据集
利用来自各种来源的恶意和正常流量的数据集来构建我们的数据库。选择有用且平衡的数据集对于确保实现的检测率与实际能力相对应至关重要。数据集是公开的,包含真实恶意软件的流量、破坏攻击、反向 shell 和软件利用攻击以及正常流量。用于训练和测试系统的数据集如下:
- FIRST 2015:为满足网络取证动手实验室的需求而创建的数据集。它是 4.4 GB pcap 文件的集合,其中包含正常流量和恶意流量。流量由 Reverse Shell shellcode
连接、网站破坏攻击、勒索软件下载攻击密码锁和通过 SSL 接管受害者机器的命令和征服漏洞攻击 (C2) 组成。 - Milicenso:包含 Ponmocup 恶意软件的正常和恶意软件流量的数据集。它包含来自在僵尸网络上连接受害者 PC 的恶意软件/木马的恶意流量。
- CTU13-1:包含 Neris 僵尸网络的僵尸网络流量的数据集。所有流量大多是加密的僵尸网络流量,因为同时捕获的正常流量是不公开的。
数据集流量包含在包含捕获数据包的 pcap 和 pcapng 文件中。 FIRST 2015 的数据包是使用 Snort捕获的 pcap 文件,而 Milicenso 和 CTU13-1 数据集是使用 WireShark、Snort或原始 TCP 转储等方法捕获流量。
4 检测方法
4.1 问题定义
给定 TCP/IP 网络流量,系统旨在对每个连接进行采样并将其分类为恶意(即由 Web 攻击或恶意软件等恶意事件产生)或正常连接。本质上,该系统由两部分组成:流量侧信道特征选择和网络流量分类。
- 侧信道特征选择:第一个任务是选择正确的、描述性的 TCP
流量特征,这些特征不是指数据包的内容,而是指物理特征,例如数据包发送之间的时间比、有效负载的大小等。 - 流量分类:第二个任务是使用选定的特征将新的流量分类为恶意或正常(二分类),不区分恶意流量的类型。
4.2 特征选择
论文中提出了5个侧信道特征用于恶意流量的检测和分类:
- 数据包大小 (Ps):每个连接都由发送方和接收方之间交换的数据包定义。众所周知,数据包大小对于预测连接类型和使用的协议都有好处。出于这个原因,选取数据包大小作为一个基本特征。
- 有效载荷大小 (PA):有效负载是任何恶意流量的核心。在 TCP 中,有效负载包含在 TCP 数据段中。研究表明,有效载荷大小的侧信道分析可以用作信息泄漏的特征。
- 净荷比(Pr):指净荷大小与总包大小之比。恶意流量在内容比率方面可能表现出类似的模式,因此选择将其作为基本特征。公式如下所示,其中 PAs 是指负载大小,Ps 是指数据包大小。
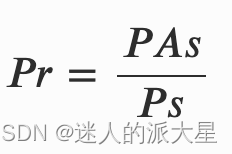
- 与前一个数据包的比率 (Rpp):我们注意到,当恶意流量在网络内流动时,数据包是连续的,并且通常呈现出特定的大小趋势。这可用于对恶意流量进行指纹识别。通过比较属于同一会话的连续两个数据包,我们可以得到与前一个数据包的比率。对于会话的第一个数据包,该值默认为
0。公式如下所示。其中,Pp 指的是当前数据包大小,PPs 指的是同一会话中的前一个数据包大小。
时间差 (Td):一个数据包与会话的前一个数据包之间的时间差可用于识别恶意流量。对于会话的第一个数据包,该值默认为 0。公式如下。其中,Pt 指数据包时间,PPt 指前一个数据包时间。这两个时间都是指交付数据包所需的时间。

4.3 流量分类
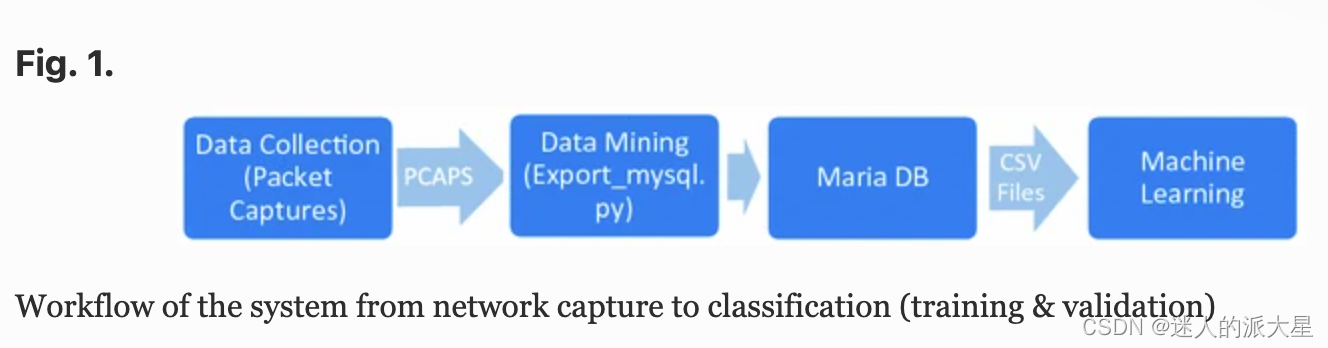
论文所提出的是一个离线的二分类系统,即只将流量分为正常流量和恶意流量。总体结构如下:
文章选取的机器学习算法为以下七种:

5 实验结果
实验 1:具有随机混合流量的整个数据集(所有类型的恶意流量)
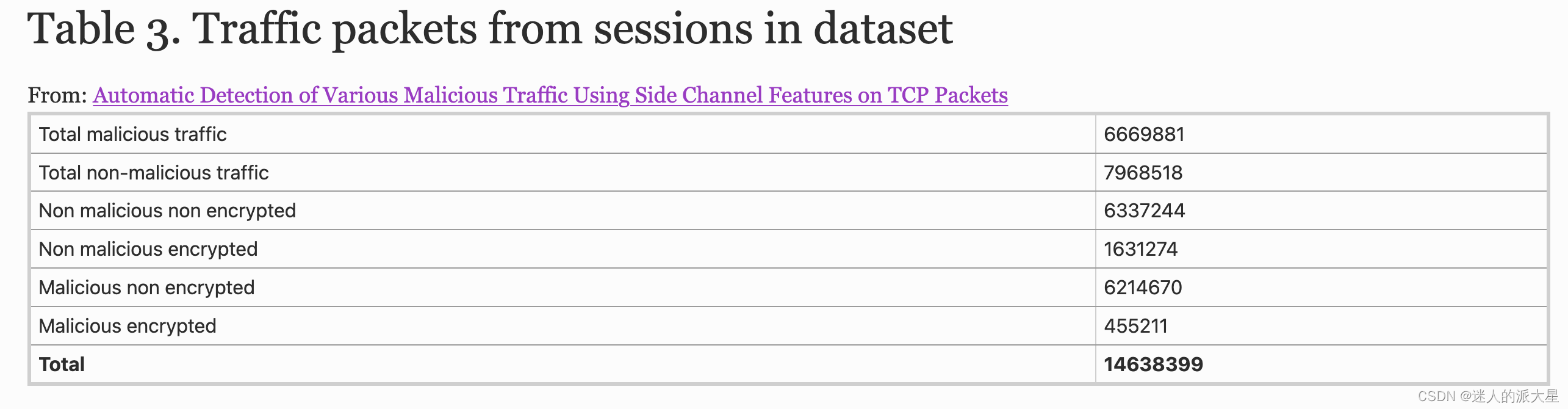
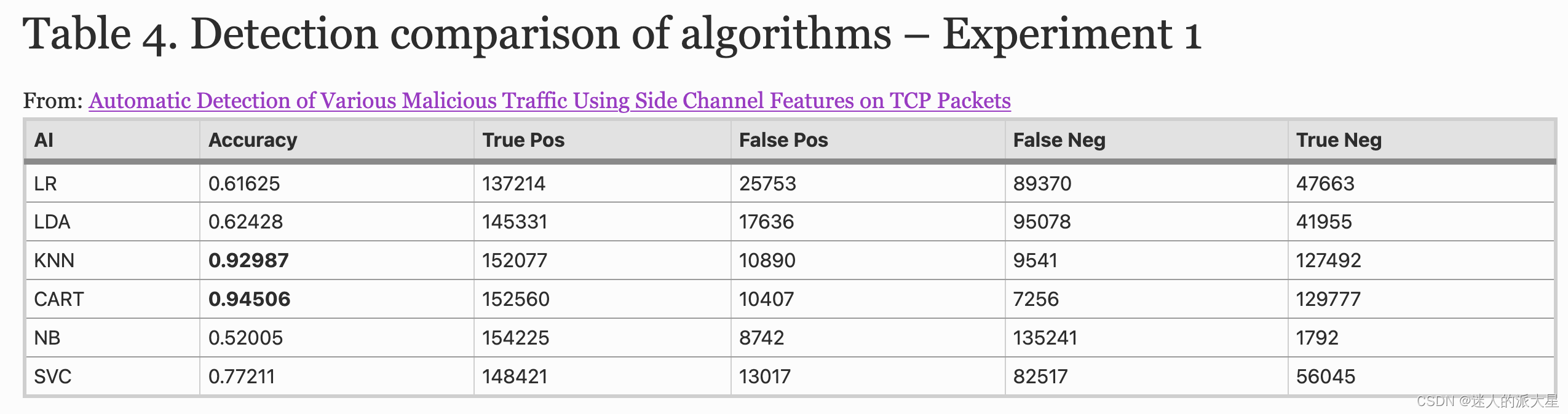
在第一个实验中,我们使用了来自所有数据集的所有流量。分类使用来自整个流量数据库的随机样本;恶意流量和正常流量。用于测试分类的数据包数量见表 3。在 CSV 导出时,使用 MariaDB 统一随机选择各种类型的恶意流量(旨在消除数据选择中的任何偏差)。数据集被拆分为 7:3,并且使用了所有约 8 GB 的数据集流量。从每个数据包中提取侧信道特征并导入 MariaDB。这包括 FIRST 2015、Milisenco 和 CTU-13 数据集,以及来自每个网络会话的所有数据包。这样做是为了使用我们的特征提取来测试非同质网络流量行为。本实验使用了所有类型的恶意流量。
机器学习和分类结果如表 4 和表 5 所示。通过查看真阳性 (TP)、真阴性 (TN)、假阳性 (FP) 和假阴性 (FN) 的命中图,很明显 CART 和 KNN算法在使用数据包的侧信道特征检测恶意流量方面具有明显的优势。在 20 万个网络流量会话样本中,CART 的检测率为 94.5%,FP 为 4.4%,FN 为 6.8%,而 KNN 的检测率为 94%,FP 约为 5%,FN 为 7.7%。我们选择不包括 SVC,因为该算法的扩展性似乎不如其他机器学习模型。总体而言,CART 和 KNN 是性能最好的模型,它们将在以下实验中使用。

实验 2:用于功能测试的 20 K 限制数据包样本(所有类型的恶意流量)
我们检测到在经过训练的分类器上使用较小的网络流数据来检测恶意流量似乎会提高真阳性检测率。因此,在第二个实验中,我们故意只使用来自 FIRST 2015 数据集的 20K 个恶意数据包(以及因此相同数量的干净、正常流量)来测试我们的分类器。该实验提供了在数据有限的情况下对每种算法的性能的洞察。
同样,MariaDB 在 CSV 导出时统一执行随机选择,以消除任何偏差。数据包的数量故意很小,因为我们想在项目的特征选择阶段确认我们的假设(即即使在数据稀缺的情况下,所选择的侧信道特征也非常适合对恶意流量进行分类)。同样,样本与同等大小的正常流量一起被分割(7:3),用于更新分类器和测试恶意流量检测。本实验使用了所有类型的恶意流量。
在我们的数据集上运行 ml.py 模块后,我们得到下表的结果。通过查看真阳性 (TP)、真阴性 (TN)、假阳性 (FP) 和假阴性 (FN) 的命中图,可以明显看出某些算法比其他算法具有明显的优势。具体来说,CART 和 KNN 显示出良好的潜力,对任何给定的混合恶意流量样本的检测率约为 89%,误报率和误报率低(约 10%)。离线训练的执行时间只需几分钟,验证时间不到 2 分钟。这证明,即使使用随机会话、有限的数据量来训练分类器,所选特征在非常短的时间范围内也能提供非常好的结果(见表 8 和表 9)。

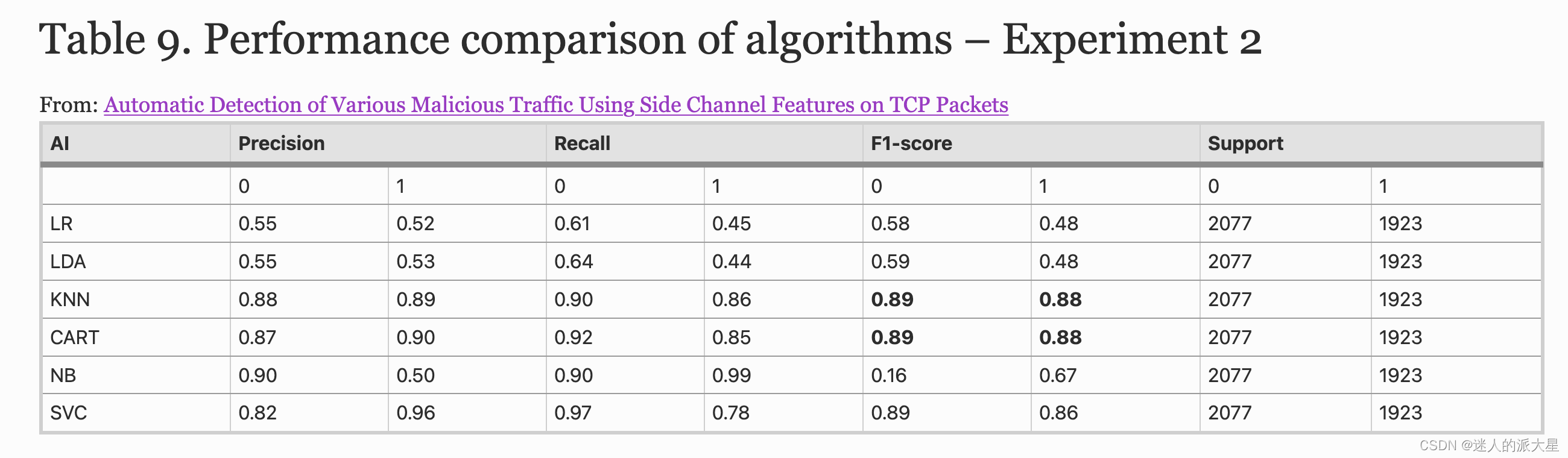
一个有趣的发现是,当使用较小的数据集进行训练和分类时,SVC 的性能会显着提高。这表明 SVC 容易出现偏差,因为随着我们增加训练样本,它的检测率下降得最快。 KNN 和 CART 仍然保持着最好的结果百分比,而它们的检测率下降是可以预料的;尽管考虑到数据的差异,但非常小。
实验 3:加密恶意软件流量检测
许多公司(例如 CISCO)正在发布有关新入侵检测系统(IDS)的技术报告,这些系统利用类似的功能,但只检测加密的恶意流量。据我们所知,没有工具能够将这种能力推广到多种类型的恶意流量,从破坏 SQLi 攻击到加密流量、僵尸网络和像我们这样的注入。
对于这个实验,我们的训练程序从所有数据集中的所有不同加密恶意流量会话中选择样本;无论是僵尸网络、反向外壳、恶意软件数据传输等。为了消除偏差,实验执行了三次,使用
- 来自所有数据集和加密流量类型的均匀随机样本(例如,参见上面的表 2)
- 有偏差(更多僵尸网络流量(80%–20%)
- 数据集被分成 7:3 用于训练和分类。
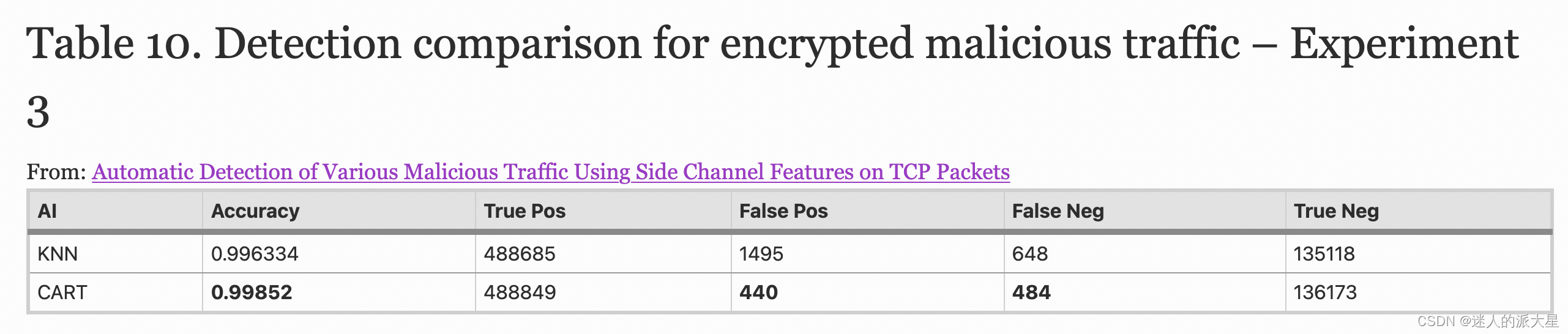
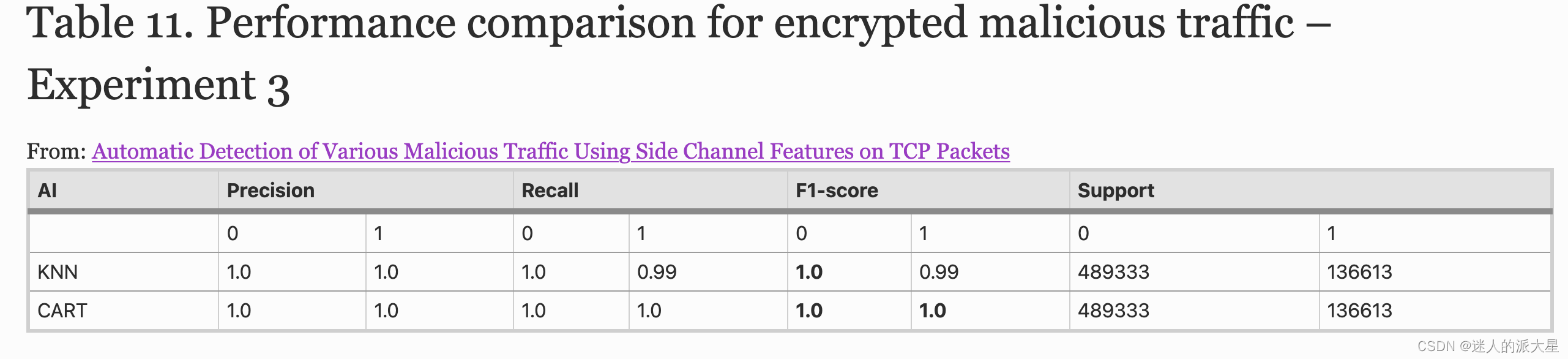
表 10 和表 11 描述了真阳性 (TP)、真阴性 (TN)、假阳性 (FP) 和假阴性 (FN) 的命中图(三次执行的平均值)。
6 总结
论文提出了一种只使用5个侧信道特征的恶意流量二分类系统,并在三个数据集、7种机器学习算法的验证下取得了较好的实验结果。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









