各货架的分类
model = KMeans(n_clusters = 5)
K_Means = model.fit(data)
K_Means.labels_
array([3, 4, 4, 3, 3, 3, 3, 3, 4, 3, 3, 4, 3, 3, 4, 4, 4, 4, 3, 4, 3, 4,
3, 4, 4, 4, 3, 3, 3, 3, 4, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 2, 2, 0, 2, 0, 2, 0, 2, 0, 2, 0, 2, 0, 2, 0, 0, 2,
2, 0, 2, 2, 0, 0, 0, 2, 0, 2, 0, 2, 0, 0, 0, 2, 2, 0, 0, 2, 0, 2,
0, 0, 2, 2, 0, 0, 2, 0, 2, 2, 0, 0, 2, 2, 0, 2, 2, 0, 2, 0, 0, 0,
2, 2, 0, 0, 0, 0, 2, 2, 2, 2, 2, 2, 2, 0, 0, 2, 2, 2, 0, 0, 2, 0,
2, 0, 0, 2, 2, 2, 2, 0, 2, 0, 2, 0, 2, 0, 0, 0, 0, 2, 0, 0, 2, 0,
2, 0, 2, 2, 2, 0, 0, 2, 0, 0, 0, 0, 2, 2, 0, 2, 0, 0, 0, 2, 0, 0,
2, 2, 0, 2, 0, 2, 0, 2, 2, 0, 0, 2, 2, 2, 0, 0, 2, 2, 2, 2, 2, 0,
2, 0, 0, 2, 2, 2, 2, 0, 0, 2, 0, 2, 2, 2, 2, 2, 0, 0, 2, 0, 2, 0,
0, 0, 0, 2, 2, 2, 2, 0, 2, 0, 2, 2, 0, 2, 0, 0, 0, 2, 2, 0, 0, 2,
2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
data.insert(3,column = 'grade', value = K_Means.labels_)
data.head()
| | GMV | LOSE | LR | grade |
|---|
| 0 | 4.236391 | 3.468713 | 3.468713 | 3 |
|---|
| 1 | 4.124695 | 2.175132 | 2.175132 | 4 |
|---|
| 2 | 4.030095 | 1.806570 | 1.806570 | 4 |
|---|
| 3 | 4.012999 | 3.569887 | 3.569887 | 3 |
|---|
| 4 | 3.999322 | 3.367539 | 3.367539 | 3 |
|---|
各类货架及其销量/货损散点图
plt.figure(figsize=(14,7), facecolor='w')
plt.ylim(-1,5)
plt.plot(data['LR'], data['grade'], 'bo',markersize = 8, zorder=2, label='LR')
plt.plot(data['GMV'], data['grade'], 'go', markersize = 16, zorder=1, label='GMV' )
plt.legend(loc = 'upper left')
plt.xlabel('grade', fontsize=18)
plt.ylabel('GMV or LR', fontsize=18)
plt.title('classfication and indicators', fontsize=20)
Text(0.5, 1.0, 'classfication and indicators')
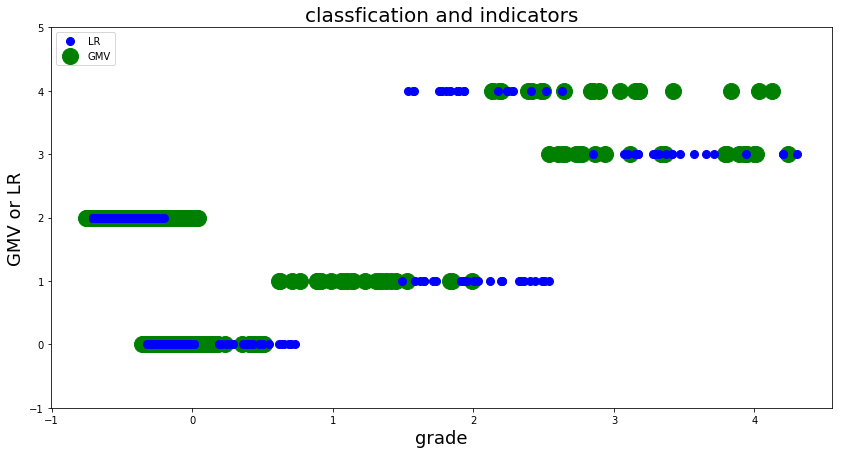
#各类货架收益与货损占比
GMV_sum = sum(abs(data['GMV']))
LR_sum = sum(abs(data['LR']))
print('一类货架收益占比:',(sum(abs(data[data.grade == 0].GMV))/GMV_sum)*100)
print('一类货架货损占比:',(sum(abs(data[data.grade == 0].LR))/LR_sum)*100)
print('二类货架收益占比:',(sum(abs(data[data.grade == 1].GMV))/GMV_sum)*100)
print('二类货架货损占比:',(sum(abs(data[data.grade == 1].LR))/LR_sum)*100)
print('三类货架收益占比:',(sum(abs(data[data.grade == 2].GMV))/GMV_sum)*100)
print('三类货架货损占比:',(sum(abs(data[data.grade == 2].LR))/LR_sum)*100)
print('四类货架收益占比:',(sum(abs(data[data.grade == 3].GMV))/GMV_sum)*100)
print('四类货架货损占比:',(sum(abs(data[data.grade == 3].LR))/LR_sum)*100)
print('五类货架收益占比:',(sum(abs(data[data.grade == 4].GMV))/GMV_sum)*100)
print('五类货架货损占比:',(sum(abs(data[data.grade == 4].LR))/LR_sum)*100)
一类货架收益占比: 6.164401861697537
一类货架货损占比: 6.652831058827551
二类货架收益占比: 9.089795550942922
二类货架货损占比: 15.101246088993388
三类货架收益占比: 45.97416334065695
三类货架货损占比: 46.421436906323414
四类货架收益占比: 19.726729310594852
四类货架货损占比: 19.542840412045173
五类货架收益占比: 19.04490993610771
五类货架货损占比: 12.281645533810488
可以看出根据货架的销量和货损将货架分为五类,分别是:
第一类:低销量中低货损,此类货架中存在部分损失远大于收益的情况,对于这部分货架考虑撤架
第二类:中等销量中上货损,损失大于收益,此类货架中存在部分损失远大于收益的情况,对于这部分货架考虑撤架
第三类:低销量低货损,收益大于损失,可根据维护成本酌情撤架
第四类:高销量高货损,此类货损贡献了很大的GMV但货损也较高几乎抵消掉了收益,应设法降低货损
第五类:高销量低货损,此类货架为优质货架
提取第一类货架中货损在总货损中占比大于销量在总销量中占比且单个货架货损占货架销量15%以上的货架,这部分货架是考虑撤架的货架
index2 = list(data[data.LR > max(data[data.grade==0].GMV)].index)
datas2 = datas.iloc[index2, :]
datas2[datas2.LR>0.15].sort_values(by=['LR'],ascending=False)
| | ID | GMV | LOSE | LR |
|---|
| 67 | A131502 | 1303 | 420 | 0.322333 |
|---|
| 66 | A515389 | 1310 | 422 | 0.322137 |
|---|
| 55 | A505492 | 1731 | 444 | 0.256499 |
|---|
| 63 | A549268 | 1542 | 391 | 0.253567 |
|---|
| 64 | A492069 | 1437 | 363 | 0.252610 |
|---|
| 53 | A275823 | 1766 | 431 | 0.244054 |
|---|
| 65 | A726433 | 1386 | 338 | 0.243867 |
|---|
| 90 | A559101 | 800 | 193 | 0.241250 |
|---|
| 61 | A326788 | 1551 | 369 | 0.237911 |
|---|
| 49 | A266437 | 1945 | 449 | 0.230848 |
|---|
| 54 | A570130 | 1764 | 402 | 0.227891 |
|---|
| 58 | A453264 | 1632 | 366 | 0.224265 |
|---|
| 88 | A625828 | 831 | 186 | 0.223827 |
|---|
| 57 | A431484 | 1691 | 375 | 0.221762 |
|---|
| 82 | A228580 | 911 | 199 | 0.218441 |
|---|
| 62 | A526263 | 1545 | 335 | 0.216828 |
|---|
| 56 | A122083 | 1704 | 366 | 0.214789 |
|---|
| 32 | A301564 | 3045 | 643 | 0.211166 |
|---|
| 51 | A407693 | 1911 | 403 | 0.210884 |
|---|
| 60 | A555168 | 1559 | 326 | 0.209108 |
|---|
| 45 | A405486 | 2102 | 435 | 0.206946 |
|---|
| 48 | A720532 | 1972 | 403 | 0.204361 |
|---|
| 87 | A283051 | 852 | 174 | 0.204225 |
|---|
| 59 | A196705 | 1569 | 317 | 0.202040 |
|---|
| 50 | A446950 | 1934 | 379 | 0.195967 |
|---|
| 29 | A365840 | 3091 | 604 | 0.195406 |
|---|
| 33 | A621554 | 2990 | 570 | 0.190635 |
|---|
| 44 | A298717 | 2370 | 444 | 0.187342 |
|---|
| 13 | A520253 | 3690 | 680 | 0.184282 |
|---|
| 27 | A630001 | 3171 | 570 | 0.179754 |
|---|
| 43 | A398851 | 2385 | 425 | 0.178197 |
|---|
| 52 | A378337 | 1842 | 326 | 0.176982 |
|---|
| 28 | A433220 | 3158 | 558 | 0.176694 |
|---|
| 42 | A162793 | 2512 | 442 | 0.175955 |
|---|
| 26 | A470397 | 3197 | 554 | 0.173287 |
|---|
| 76 | A502892 | 1132 | 195 | 0.172261 |
|---|
| 79 | A338628 | 1073 | 183 | 0.170550 |
|---|
| 9 | A323355 | 4101 | 693 | 0.168983 |
|---|
| 5 | A402586 | 4229 | 680 | 0.160795 |
|---|
| 20 | A510649 | 3341 | 537 | 0.160730 |
|---|
| 22 | A668628 | 3279 | 527 | 0.160720 |
|---|
| 47 | A557736 | 2005 | 322 | 0.160599 |
|---|
| 74 | A620952 | 1159 | 186 | 0.160483 |
|---|
| 69 | A608779 | 1203 | 193 | 0.160432 |
|---|
| 31 | A550157 | 3076 | 493 | 0.160273 |
|---|
| 70 | A371447 | 1186 | 188 | 0.158516 |
|---|
| 36 | A398789 | 2884 | 446 | 0.154646 |
|---|
| 18 | A526219 | 3498 | 534 | 0.152659 |
|---|
| 38 | A222345 | 2689 | 409 | 0.152101 |
|---|
提取第二类货架中货损在总货损中占比大于销量在总销量中占比且单个货架货损占货架销量15%以上的货架,这部分货架是考虑撤架的货架
index4 = list(data[data.LR > max(data[data.grade==1].GMV)].index)
datas4 = datas.iloc[index4, :]
datas4[datas4.LR>0.15].sort_values(by=['LR'],ascending=False)























 1011
1011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









