






存在的问题:
现有的自监督医学图像分割通常会遇到域偏移问题(也就是说,预训练的输入分布不同于微调的输入分布)和/或多模态问题(也就是说,它仅基于单模态数据,无法利用医学图像丰富的多模态信息)。针对这些问题,本文提出多模态对比域共享( Multi-Con Do S )生成对抗网络,实现有效的多模态对比自监督医学图像分割。
ConDoS具有以下3个优势:
- 利用多模态医学图像,通过多模态对比学习,学习更全面的目标特征;
- 通过集成CycleGAN的循环学习策略和Pix2Pix的跨域翻译损失实现领域翻译 ;
- 新的域共享层不仅可以从多模态医学图像中学习特定域的信息,还可以学习域共享的信息。
contributions:
- 本文针对现有自监督医学图像分割方法的不足,提出了一种多模态对比自监督医学图像分割方法Multi - ConDoS,该方法利用一种新颖的域共享生成对抗网络( domain-shared Generative Adversarial Networks,DSGANs )从多模态医学图像中学习更全面的目标特征进行自监督预训练。
- DSGAN有三个方面的进步:第一,DSGAN是CycleGAN与经典的成对图像翻译模型Pix2Pix的融合,因此它可以同时利用CycleGAN的循环学习策略和Pix2Pix的跨域翻译损失来获得更好的域翻译能力。其次,引入新的领域共享层来帮助DSGAN不仅学习特定领域的信息,而且学习领域共享的信息。第三,多模态对比损失也被用来更好地学习多模态特征。
- 在两个公开的多模态医学图像分割数据集上进行了广泛的实验。实验结果表明,在仅有5 % (分别为10 %)的标记数据的情况下,Multi - ConDoS不仅在标记数据比例相同的情况下,大大优于目前最先进的自监督和半监督医学图像分割基线,而且在标记数据比例为50 % (分别为100 %)的情况下,也取得了与全监督分割方法相当的(有时甚至更好)性能。
method:
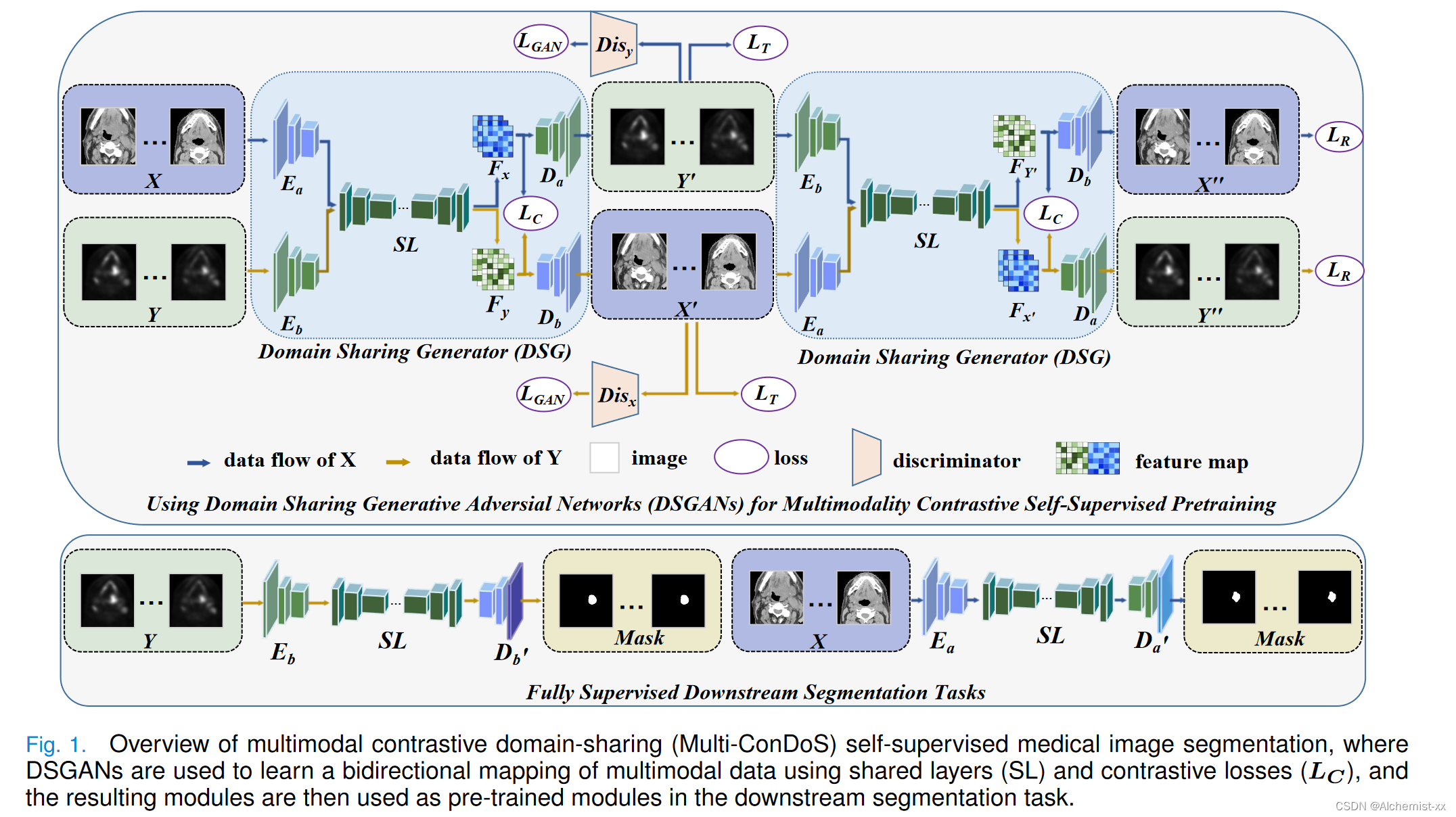
整体上来说:
- 首先,DSGANs利用一个域共享生成器( domain-shared generator,DSG )将原始未标记的医学图像X (Y )作为输入,生成另一个域的图像,将这个图像生成过程称为图像平移,并将得到的图像Y′(X′)称为平移图像。
- 然后,与CycleGANs类似,Y′和X′被进一步用作DSG的输入,分别生成图像X′′和Y′′。由于X′′(Y′′)是由X ( Y )得到的Y′(X′)生成的,因此X′′(Y′′)可以看作是X (Y )的重构图像。
- DSG的结构与CycleGANs的生成器类似,但使用了共享层( SL ),以更好地捕获两个域中普遍存在的通用特征。进一步地,使用两个判别器Dis X和Dis Y对平移后的图像X′(Y′)和原始输入图像X (Y )进行判别,以鼓励域共享生成器生成与真实原始输入图像更相似的图像。
- 最后,将DSG的结果模块用于全监督的下游分割任务作为预训练模块。
域生成对抗网络:
生成式对抗网络在图像到图像的翻译中有着出色的表现。域共享生成对抗网络( Domain Sharing Generative Adversarial Networks,DSGANs )通过双向跨域学习和多模态对比学习来学习一种表示。具体来说,跨领域学习可以学习模式特异性知识,而共享层( SL )和多模态对比学习旨在学习两种模态的通用知识。整体框架由一个生成模块和两个特定域的判别器组成。
判别器DisX和DisY旨在对域X和Y中的真实图像和翻译图像进行判别,从而方便生成器生成更真实的图像。生成器DSG旨在生成尽可能接近现实的图像,它包含两个编码器{ Ea,Eb },一个共享层模块( SL )和两个解码器{ Da,Db }。两个编码器(即Ea和Eb)从不同模态的图像中提取特征(提取的特征实际上包含了领域特定和领域共享的信息),并将输入图像的特征送入共享层SL,使两个域的内容映射到同一个隐空间(共享层的设计虽然可能导致较少的特定领域特征,但有助于获得更多的领域共享特征)。然后将两个域的SL编码的内容输入到各自的解码器(即Da和Db)中。
多模态对比损失:
由于共享相同的潜在空间并不意味着SL编码了两个域的成对图像特征的一致性信息。因此,利用对比损失最小化(分别最大化),使成对的(分别为未配对)图像之间的距离最小,以突出重要的域共享信息。
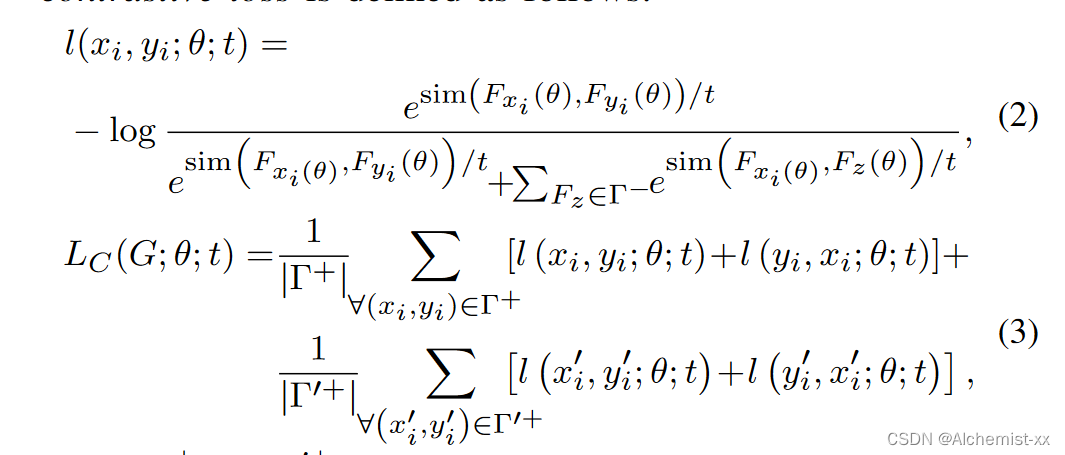
损失函数:
adversarial GAN loss LGAN:
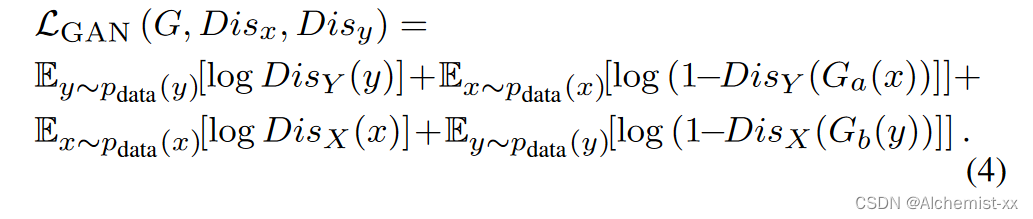
将GAN损失与L1损失相结合,有助于减少模糊,并帮助模型从成对图像中学习像素级的详细信息和特征;进一步使用基于L1的翻译损失来最小化输入和翻译图像之间的差异(类似于Pix2Pix )。

应用一个重建损失来最小化重建图像X′′(、Y′′)和输入图像X (分别为, Y )之间的距离:
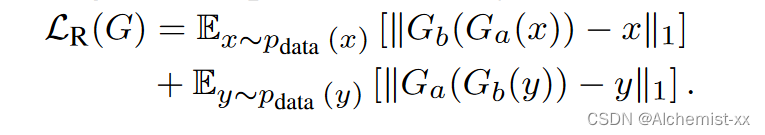
总损失为:
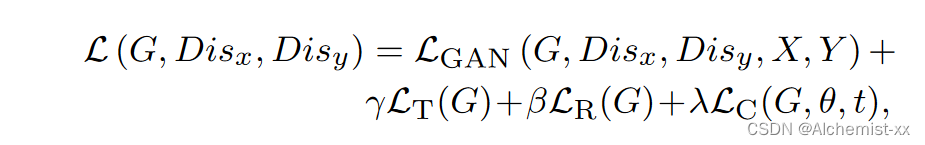
DSGAN是CycleGAN和经典的成对图像翻译模型Pix2Pix的融合,并有额外的改进(加入多模态对比学习和共享层:目的是为了更好的学习领域共享特征,实现多模态信息之间的相互补充)。可以将DSGAN看成是CycleGAN的配对翻译扩展或者是Pix2Pix的循环扩展。
为什么不单独使用CycleGAN或者单独使用Pix2Pix?
- 与经典的成对图像翻译模型(Pix2Pix)相比,CycleGAN的循环训练策略非常有利于充分全面地学习模态特征信息:Pix2Pix仅学习成对多模态图像的单向映射关系,而CycleGAN的循环训练策略可以学习成对多模态图像的一对一双向映射关系,这有助于生成器网络学习到更准确的潜在表示空间。
- CycleGAN可以同时学习两个域的特征信息,并在两个方向上进行跨域生成,这是设置共享层( SL )和引入对比损失的结构基础。
- 通过将Pix2Pix中的跨域翻译损失LT引入到DSGAN中,与成对图像翻译模型(pix2pix)类似,DSGAN也可以从成对图像中学习像素级的细节信息和特征。因此,将CycleGAN与Pix2Pix相结合,使得DSGAN兼具两种模型的优点。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









