







 本文介绍了如何在Windows环境下使用Eclipse和Maven构建Hadoop MapReduce项目。通过创建Maven项目,设置目录结构,编写Mapper、Reducer类,实现了对大文件的处理,过滤掉不需要的数据列。最终,通过打包和上传到Hadoop集群执行MR任务,获取处理后的结果。
本文介绍了如何在Windows环境下使用Eclipse和Maven构建Hadoop MapReduce项目。通过创建Maven项目,设置目录结构,编写Mapper、Reducer类,实现了对大文件的处理,过滤掉不需要的数据列。最终,通过打包和上传到Hadoop集群执行MR任务,获取处理后的结果。
- 开发环境:Windows系统+Eclipse+Hadoop(2.2.0)集群(在虚拟机上)
- 用到的工具:
SecureCRT 用来连接Hadoop集群
SecureFX 用来Windows与hadoop集群文件传输
Notepad++ 用来文本编辑,它可以连接hadoop集群中的某个节点,连接成功后可以在本地直接编辑hadoop集群中的文件构建Maven项目
1. 在Eclipse中新建Maven项目,目录结构如下(如果Eclipse中没有Maven,下载Maven包配置即可,配置方法不做介绍)
2. 目录介绍
src/main/java 存放java源程序
src/main/resources 存放资源文件,例如property文件
src/test/java 存放测试的源文件,比如单元测试之类的
src/test/resoutces 存放测试文件用到的资源文件
根下面的pom.xml文件 定义项目的GAV(groupId、artifactId、version),管理依赖等。
简单的Mapper-Reducer流程
1、在src/main/java建立四个包,main存放入口文件,map存放自己写mapper,reduce存放自己写reducer,model存放JavaBean
2、我写的这个Mapper-Reducer主要是用来简单过滤用户信息的数据文件,先看需要过滤的数据文件,这个文件是从http://www.last.fm/中获取到的数据,下图是部分文件信息,
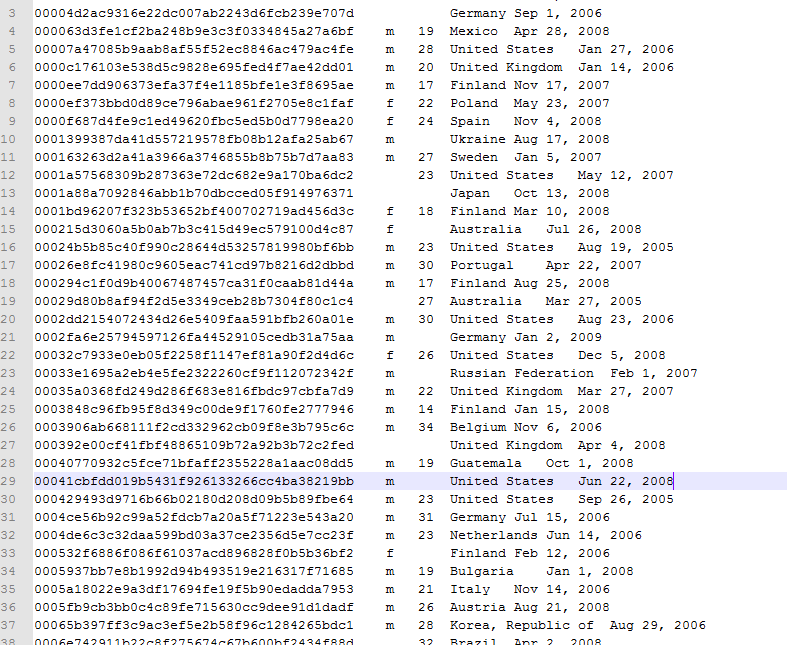
每一列数据的分隔符为“\t”
第一列:用户唯一ID,是用MD5加密过的
第二列:用户的性别(m代表女,f代表男)
第三列:用户年龄
第四列:用户所在国家
第五列:用户注册日期
要达到的目的:我所需要的是第一列、第二列、第四列、第五列,也就是说将第三列去掉,如果文件数量很小,可以手动去删除,但是我所要处理的这个文件用1.5G这么大,想要单纯的打开这个文件都是个问题,所以这里用hadoop集群来处理。
3、问题描述清楚了,现在开始写Mapper-Reducer
- 在pom.xml中导入开发所需用的jar包,也就是依赖,jar包在你写好依赖以后保存,Maven会自动从网上下载所需用的jar包(需联网,如果已下载Maven所需的仓库,配置即可,具体配置这里不做介绍)
<dependency>
<groupId>org. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









