










《操作系统概念》
PART TWO PROCESS MANAGEMENT(进程管理)
进程可看做是正在执行的程序。进程需要一定的资源(如 CPU时间、内存、文件 和 I/O设备)来完成其任务。这些资源在创建进程或执行进程时被分配。
进程是大多数系统中的工作单元。这样的系统由一组进程组成:操作系统进程执行系统代码,用户进程执行用户代码。所有这些进程可以并发执行。
虽然从传统意义上讲,进程运行时只包含一个控制线程,但目前大多数现代操作系统支持多线程进程。
操作系统负责进程和线程管理,包括用户进程与系统进程的创建与删除,进程调度,提供进程同步机制、进程通信机制与进程死锁处理机制。
Chapter 3 Processes(进程)
3.1 Process Concept 105(进程概念)
3.1.1 Process(进程)
进程包含了当前的状态,这由程序计数器和处理器中的寄存器表示。另外,进程通常也包含了进程栈(process stack)(如方法参数(method parameters)、返回地址和本地变量)和一个数据段(存储全局变量)。
我们强调程序本身不是进程;程序是静态实体(就像是存储在磁盘上的文件),进程是动态实体,它有一个程序计数器指明下一条要执行的指令,并且拥有一组相关的资源。
如,Java虚拟机是操作系统下的一个进程:
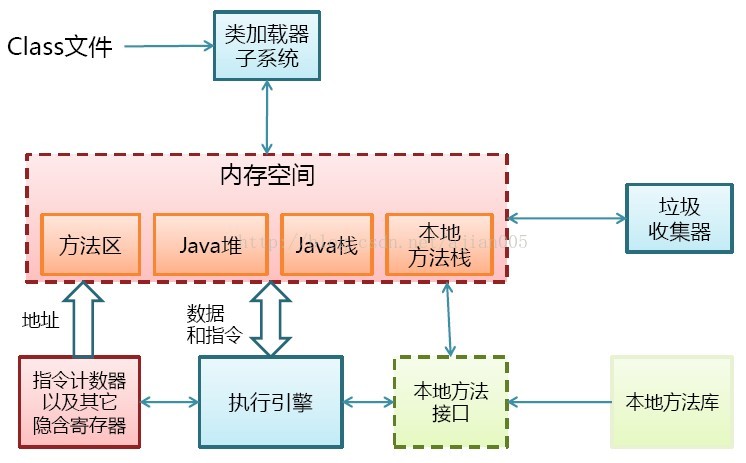
3.1.2 进程状态
3.1.3 进程控制块(PCB Program Control Block)
操作系统通过进程控制块(PCB)表示进程,进程控制块也被称为任务控制块。
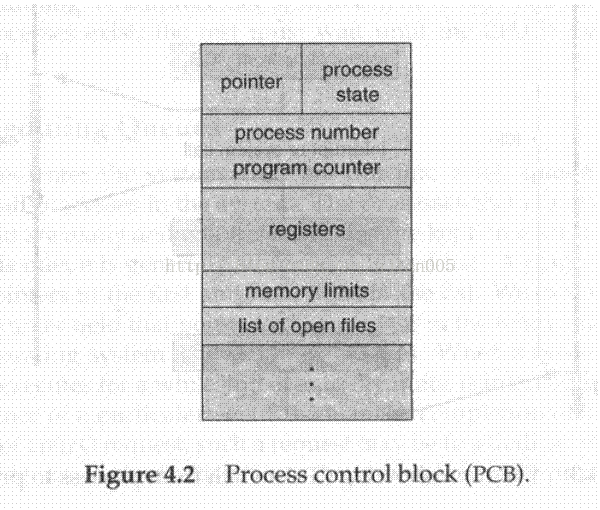
图4.2 描述了一个进程控制块。它存储了某一具体进程的信息,这包括:
进程状态:该状态可能是新、就绪、运行、等待、停止等等。
程序计数器:该计数器指明了该进程要执行的下一条指令的地址。
CPU 寄存器:基于计算机体系结构,这些寄存器的数量和类型很不相同。这包括了累加器、变址寄存器、栈指针、通用寄存器,
以及条件信息(condition-code information)。连同程序计数器,在中断发生时必须要保存这些状态信息,这样便于后来进程继续正确执行(图4.3)。
CPU 调度信息:包括进程优先权、指向调度队列的指针和其它的调度参数。(第六章描述进程调度。)
存储器管理信息:可能包括诸如基址寄存器和界限寄存器值、页表或段表,这取决于操作系统所选用的存储系统(第九章)。
记账信息(accounting information):包括CPU 数量和实时使用量、时间限制、账户数目、作业或进程数目等等。
I/O 状态信息:包括分配给该进程的I/O 设备的列表、打开的文件的列表等等。
3.1.4 线程(Thread)
3.2 Process Scheduling(进程调度) 110
多道程序设计的目标是为了保持总是有多个进程运行,以最大化CPU 利用率。分时系统的目标是为
了在进程之间频繁转换CPU 以便于用户与运行的程序交互
3.2.1调度队列(scheduling)
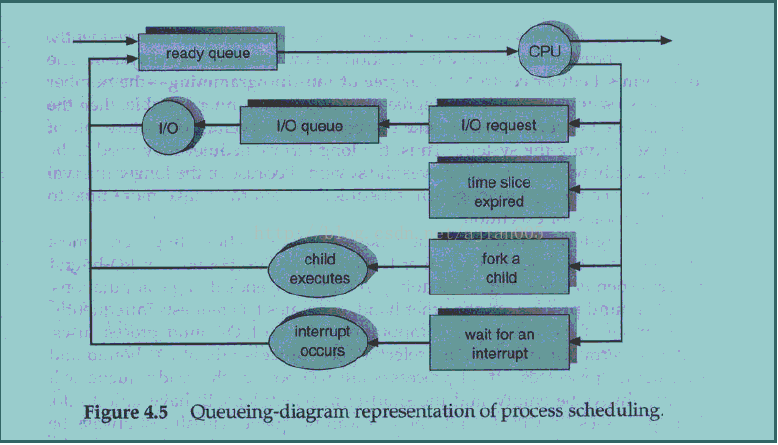
一个通用的进程调度的表示法是队列状态图(queueing diagram),如图4.5。每个矩形框表示一个队列。有两种类型的队列:就绪队列和设备队列。圆圈表示服务于队列的资源,箭头指示系统中的进程流。
新进程最初被放在就绪队列中。它在就绪队列中等待,直到被选中执行(或调度)。一旦进程获得了CPU 并执行,可能会发生下面的某个事件:
(1) 进程可能发出一个I/O 请求,然后被放置在I/O 队列中。
(1) 进程可以创建新的子进程并等待它终止。
(1) 发生一个中断,导致进程被强行从CPU 中移出并返回就绪队列。
在前两种情况下,进程最终会从等待状态转换为就绪状态,并返回就绪队列中。一个进程会持续这个循环直到终止执行,此时退出所有对列并释放自己的PCB 和资源。
3.2.2 调度程序(Scheduling program)
进程在其生命周期中于各种调度队列之间转移。为了进行调度,操作系统必须要以某种方式从这些队列里选择进程。而调度程序负责选择进程。
长程调度程序(或作业调度程序)从这个池中选择进程并将其载入内存。
短程调度程序(或CPU 调度程序)从这些进程中选择就绪进程并为其中某个分配CPU。
如果所有的进程都是I/O 繁忙型的,那么就绪队列几乎总是空的,而且短程调度程序几乎无事可做。如果所有的进程都是CPU 繁忙型的,那么I/O 等待队列
几乎总是空的,设备将处于空闲状态,系统将失去平衡。性能最好的系统要有一个CPU 繁忙型和I/O 繁忙型进程的组合。
中程调度程序,如分时系统(如UNIX),将进程从内存中移除(不再占用CPU)并降低了多道程序度。稍后再把进程重新载入内存并从停止的地方继续运行。这种机制被称为交换。 通过中程调度程序,进程被换出,然后被换入。为了改善进程混合集,或者内存需求过多或者太多空闲了,就有必要进行交换。第九章讨论交换技术。
3.2.3 上下文转换(Context Switch)
要将CPU 转向另一个进程需要保存当前进程的状态并载入为新进程存储的状态。这个工作被称为上下文转换。一个进程的上下文表示在进程的PCB 中;它包括了CPU 寄存器值、进程状态和内存管理信息。当上下文转换发生时,内核存储当前进程PCB 中的上下文信息并载入被调度运行的新进程存储的上下文信息。上下文转换时间是纯粹的开销,因为在转换进行时系统不能做任何有用的工作。根据内存速度、必须要拷贝的寄存器数量和是否存在用于上下文转换的专门指令(例如有独立的指令来载入或存储
所有的寄存器),转换速度与具体的机器有关。典型的速度范围在1 到1000 毫秒之间。
3.3 Operations on Processes 115(进程操作)
进程在系统中能够并行执行,并且它们必须要动态的创建和删除。因此,操作系统必须要提供进程创建和终止的机制(或方法)。
3.3.1 进程的创建(Process Creation)
进程在运行期间通过创建进程系统调用可以创建多个新进程。创建进程的进程(the creating process)被称为父进程(parent),而新进程被称为子进程(children)。每个新进程都可以创建另外的进程,从而形成一个进程树。
通常一个进程需要特定的资源(如CPU 时间、内存、文件、I/O 设备)。当一个进程创建了一个子进程时,这个子进程可能直接从操作系统获取它所需的资源或者获取父进程资源的一部分。父进程可能必须要把自己的资源分配给它的子进程,也可能在它的若干个子进程之间共享某些资源(如内存或文件)。通过限制子进程只能够获取父进程的部分资源可以阻止进程通过创建过多的子进程而导致系统过载。
当一个进程创建了一个新进程时,会以两种可能的方式执行:
1. 父进程(继续执行)与子进程并行执行。
2. 父进程等待部分或全部子进程终止执行。
新进程的地址空间也有两种可能:
1. 子进程是父进程的一个拷贝。(The child process is a duplicate of the parent process. )
2. 载入一个程序运行。(The child process has a program loaded into it. )
3.3.2 进程的终止(Process Termination)
进程执行完最后一条语句后就终止执行,并调用exit 系统调用来使操作系统删除它。在此,该进程可能要把数据(输出)返回给它的父进程(通过wait 系统调用)。操作系统回收该进程的所有资源——包括物理和虚拟内存、打开文件和I/O 缓冲器。
进程也可能在其它的情况下终止运行。一个进程可以利用系统调用(例如:abort)终止其它的进程。
通常,只有进程的父进程可以调用这样的系统调用来终止它。否则,用户可以任意的取消其它用户的作业。
所以父进程需要知道其子进程的标识符。如此,当一个进程创建一个新进程时,新创建的进程的标识符要传给其父进程。
父进程可能会出于某个原因而结束它的一个子进程,例如:
(1) 子进程需要更多的资源。(The child has exceeded its usage of some of the resources that it has beenallocated.)这需要父进程能够检查其子进程的状态。
(2)分配给子进程的任务已经不再需要。
(3)父进程退出,而且操作系统禁止子进程在父进程终止后继续执行。在这样的系统中,如果一个进程(正常或非正常)终止,那么它的所有子进程也必须要终止。这种级联式的进程终止通常是操作系统发起的。(This phenomenon, referred to as cascading termination, is normally initiated by the operatingsystem.)
3.4 Interprocess Communication 122(进程间通信)
3.4.1 Shared-Memory Systems(共享存储器)
协作进程如何在共享存储器环境下进行通信。这种方案需要这些进程共享一个共同的缓冲池而且实现缓冲区的代码由应用程序程序员亲自完成。
不与其它进程共享数据(临时的或长久的)的进程是独立进程。
另一方面,如果一个进程会影响系统中其它的进程而且也被影响,那么它是一个协作进程。无疑,与其它进程共享数据的进程是协作进程。
协同进程例子:
考虑一下生产者—消费者问题(the producer -consumer problem),这是一个协同进程的范例。一个生产者进程生产信息,而消费者进程消费这些信息。
为了实现生产者进程和消费者进程的并行执行,我们必须要有一个有效的缓冲区,它可以由生产者装入信息并由消费者取走信息。在(不定数量的)消费者消费条目的时候一个生产者能够生产条目。生产者和消费者必须要同步,即消费者不能够消费一个尚未产出的条目。在这种情况下,消费者必须要等待该条目产出。
无限长度缓冲区(unbounded-buffer)的生产者—消费者问题采用了没有实际容量限制的缓冲区。消费者可能必须要等待新条目,但是生产者总是可以生产新条目。
有限长度缓冲区(bounded-buffer)的生产者—消费者问题采取了一个固定容量的缓冲区。这样,如果缓冲区空,消费者必须等待;如果缓冲区满,生产者必须等待。
缓冲区或者由操作系统使用进程间通信(IPC)机制提供(3.4.2),或者由使用共享存储器的程序员亲自编码实现。
3.4.2 Message-Passing Systems(消息系统)
协作进程除了共享存储器环境下进行通信外,还有另一种方法是通过进程间通信(IPC)为操作系统提供协作进程互相通信的机制。
IPC 提供了一个无需共享地址空间就能实现进程通信以及同步进程活动的机制。
最好是通过消息传递系统提供IPC,而且有很多种定义消息系统的方法。消息系统的功能是允许进程与其它的进程进行通信而不必借助共享数据。
IPC 至少提供了两种操作:send(message)和receive(message)。
进程发送的消息可以是定长的也可以是变长的。如果只可以发送定长的消息,那么系统层的实现就很简单。然而,这种限制增加了程序设计的难度。另一方面,变长的消息需要更复杂的系统层实现,但是程序设计工作更简单。
几种用于进程间通信逻辑实现和send/receive 操作的方法:
(1) 直接或间接通信
(2) 同步或异步通信
(3) 自动或手动缓冲(Automatic or explicit buffering)
3.4.2.1 命名(Naming)
需要通信的进程必须要有一种方式来互相识别,这可以使用直接或间接通信方式。
直接通信
直接通信中,需要通信的每个进程都必须直接指明通信的接收方或发送方。在这种方式下,发送和接收原语定义如下:
(1) send(P, message) –发送一个消息给进程P。
(2) receive (Q, message) –从进程Q 中接收一个消息。
这种通信链路具有如下特点:
(1) 每对需要通信的进程之间自动的建立一条链路。进程只需要知道彼此的标识符(identity)。
(2) 一个连接就只连接到这两个进程。
(3) 每对进程间只能够建立一条链路。(Exactly one link exists between each pair of processes.)这种机制在寻址上对称。(This scheme exhibits symmetry in addressing);发送者和接收者进程都必须要指明通信的另一方。
这种机制的一个变种在寻址上采用了不对称通信的方式。(A variant of this scheme employsasymmetry in addressing.)只有发送者指明接收者;而接收者不需要指明发送者。在这种方式下,发送和接收原语定义如下:
(1) send(P, message) –发送一个消息给进程P。
(2) receive (id, message) –从任意进程中接收一个消息;变量id 被联系到与之通信的进程的名称。
对称和不对称机制的缺点在于它限制了进程定义的模块化程度。(The disadvantage in both symmetricand asymmetric schemes is the limited modularity of the resulting process definitions.)更改一个进程的名称可能必须要检查其它所有进程的定义。必须要发现所有对原名称的引用,以便于更换为新名称。从独立编译角度来看,这种情形可不是希望看到的。
对称或不对称通信
间接通信:
间接通信中,消息的发送和接收通过信箱(或端口)进行。可以抽象的把信箱看成一个对象,进程可以把消息放置其中也能从中取走。每个信箱都有一个唯一的标识符。在这种方式下,进程可以通过不同的信箱与其它进程通信。两个进程只有共享一个信箱才可以进行通信。发送和接收原语定义如下:
(1) send(A, message) –向信箱A 中发送一个消息。
(2) receive (A, message) –从信箱A 中接收一个消息。
这种通信链路具有如下特点:
(1)只有在两个进程间有一个共享信箱的情况下才能在二者之间建立一个链接。
(2) 一条链路可以连接两个或更多进程。
(3)在每对通信进程之间可以同时存在多个不同的链路,每条链路对应一个信箱。
自动或手动缓冲(Automatic or explicit buffering)
3.4.2.2 同步(Synchronization)
进程通过调用发送和接收原语来实现通信。有不同的方法来实现每个原语。消息传递可能是有阻塞(blocking)或无阻塞(nonblocking)
(1)发送进程阻塞: 发送进程被阻塞,直到消息被接收进程或信箱接收。
(2)发送进程不阻塞:发送进程发送消息并恢复执行。
(3)接收进程阻塞:接收进程被阻塞,直到一个消息有效。
(4)接收进程不阻塞:接收进程获取一个有效消息或空消息。
3.4.2.3 缓冲(Buffering)
不管通信是直接的还是间接的,通信进程交换的消息都是驻留在一个临时队列中。这样的队列有三种基本的实现方式:
(1) 零长度(Zero capacity):队列的最大长度是0;从而不能有任何消息在链表中等待。在这种情况下,发送者必须阻塞,直到接收者接收到消息。
(2) 限定长度(Bounded capacity):对列有限定的长度n;从而最多允许n 个消息驻留其中。如果当一个发送消息时对列未满,那么消息就会被放置在对列中稍后的位置(拷贝消息或保留指向消息的指针),而且发送者可以继续执行而无需等待。然而,链表的容量有限。如果链表满,那么发送者必须阻塞,直到对列中出现有效空间。
(3) 无限长度(Unbounded capacity):对列的潜在长度无限;从而可以有任意数目的消息在对列中等待。发送者不会阻塞。
零缓冲区的情况有时被称为无缓冲区消息系统;其它的两种情况被称为自动缓冲。(The zero-capacitycase is sometimes referred to as a message system with no buffering; the other cases are referred to as automaticbuffering. )
3.5 Examples of IPC Systems 130
3.5.1 实例:POSIX共享内存 (有几种IPC机制适用于POSIX系统,包括共享内存和消息传递)
3.5.2 实例:Mach 消息传递
3.5.3 实例:Windows
WindowsXP 的消息传通工具称为本地过程调用 (LPC) 工具。
3.6 Communication in Client–Server Systems 136
3.6.1 套接字(Socket):面向连接(TCP),无连接(UDP)
3.6.2 远程过程调用(RPC)
RPC 方法对实现分布式文件系统非常有用。
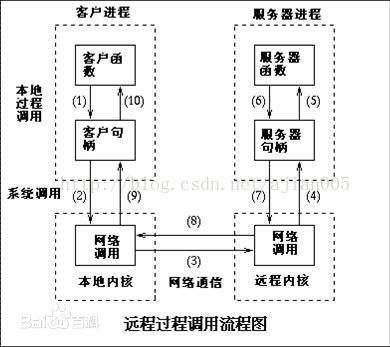
3.6.3 管道(Pipe)
根据Unix哲学——“一切都是文件”,netcat和socat这样的工具可以将管道连接到TCP/IP套接字
3.6.4 Java的远程方法调用(RMI)
远程方法调用(RMI)是一个类似于RPC的Java 特性。如果对象驻留在不同的Java 虚拟机(JVM)上,那么它们被认为是远程的。所以,远程对象或者在同一台计算机上的不同JVM 上或者在一个通过网络连接的远程主机上。RMI 和RPC 有两个基本的不同。首先,RPC 支持过程程序设计,只可以调用远程的过程或函数。RMI 是基于对象的(object-based):它支持远程对象的方法调用。第二,在RPC 中传递给远程过程的参数是普通的数据结构;而RMI 中可以传送对象作为远程方法的参数。
通过允许Java 程序调用远程对象的方法,RMI 使用户开发分布在网络上的Java 应用程序成为可能。为了把远程方法传送给客户端和服务器,RMI 采用stub 和skeleton 来实现远程对象。stub 是一个远程对象的代理;它驻留在客户端。当一个客户端调用一个远程方法时,这个远程对象的stub 被调用。这个在客户端一方的stub 负责创建一个包含了在服务器中调用的方法的名称的包(parcel)并对方法的参数进行编组。(This client-side stub is responsible for creating a parcel consisting of the name of the method to be
invoked on the server and the marshalled parameters for the method.)然后stub 将这个包发送给服务器,在服务器上该远程对象的skeleton 接收它。skeleton 负责对参数分组并调用服务器上所需的方法。然后skeleton对返回值(或异常)编组打包并将这个包返回给客户端。stub 将返回值分组并传给客户端。
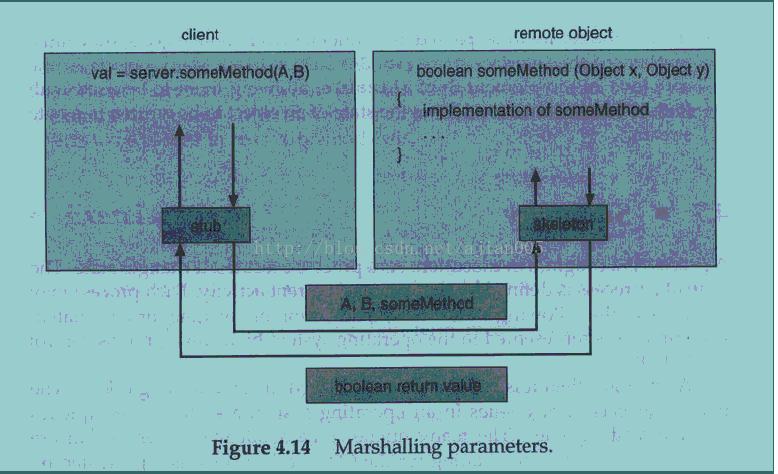
幸而RMI 的抽象使stub 和skeleton 透明化,允许Java 开发者调用分布式的方法就像调用本地方法一样。(Fortunately, the level of abstraction that RMI provides makes the stubs and skeletons transparent, allowingJava developers to write programs that invoke distributed methods just as they would invoke local methods.)然而
你必须要掌握一点参数传递行为的规则。
(1) 如果编排的参数是本地的(或非远程的)对象,那么它们利用一种叫做object serialization 的技术通过拷贝传递。然而,如果参数也是远程对象,那么它们通过引用传递。在上面的例子中,如果A 是一个本地对象而B 是一个远程对象,那么A 被串行化并通过拷贝的方式传递,B 通过引用传递。这样一来,服务器就可以远程调用对象B 的方法。(This would in turn allow the server to invokemethods on B remotely.)
(2)如果本地对象作为参数传递给远程对象,它们必须实现接口java.io.Serializable。Java 核心API 中的一些对象实现了Serializable,这允许它们在RMI 中使用。Object serialization 允许把一个对象的状态写入一个字节流。
3.7 Summary 147
Exercises 149
Bibliographical Notes 161
Chapter 4 Threads(线程)
4.1 Overview 163(线程概览)
线程,有时也被称为轻量级进程(LWP),是一个基本的CPU 执行单元;它包含了一个线程ID、一个程序计数器、一个寄存器组和一个堆栈。
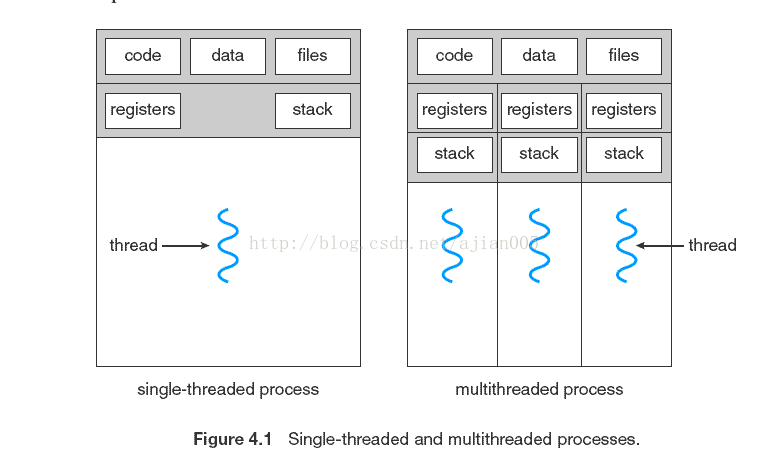
4.2 Multicore Programming 166(多核编程)
In general, five areas present challenges in programming for multicore systems:
1. Identifying tasks.
2. Balance.
3. Data splitting.
4. Data dependency.
5. Testing and debugging.
In general, there are two types of parallelism: data parallelism andtaskparallelism.Data parallelism focuses on distributing subsets of the same data
across multiple computing cores and performing the same operation on eachcore.
Task parallelism involves distributing not data but tasks (threads) acrossmultiple computing cores.
4.3 Multithreading Models 169(多线程模型)
user threads
kernel threads
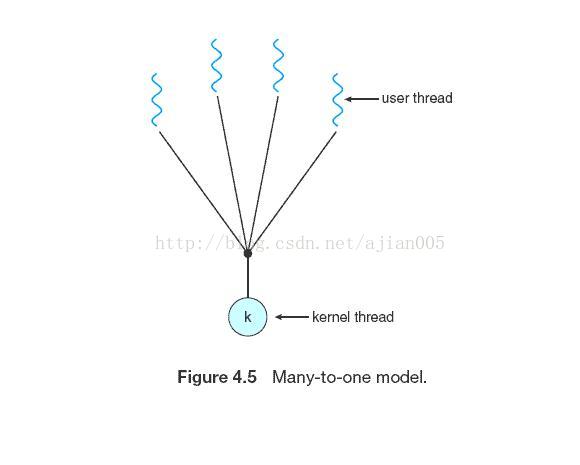
4.3.1 Many-to-One Model(多对一模型)
4.3.2 One-to-One Model(一对一模型)
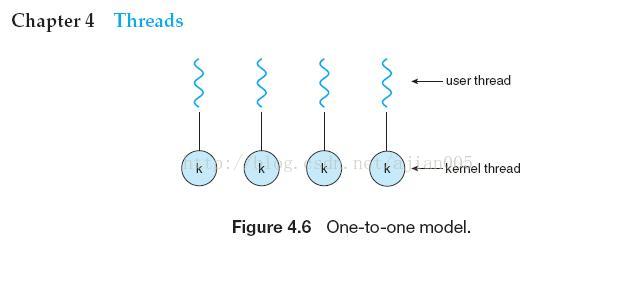
4.3.3 Many-to-Many Model(多对多模型)
4.4 Thread Libraries 171(线程库)
Three main thread libraries are in use today: POSIX Pthreads,Windows, andJava.
Pthreads, the threads extension of the POSIX standard, may be provided as either a user-level or a kernel-level library.
The Windows thread libraryis a kernel-level library available on Windows systems.
The Java thread APIallows threads to be created and managed directly in Java programs. However,because in most instances the JVM is running on top of a host operating system,the Java thread API is generally implemented using a thread library available on the host system. This means that on Windows systems, Java threads are typically implemented using theWindows API; UNIX and Linux systems often use Pthreads.
4.4.1 Pthreads
Pthreads refers to the POSIX standard (IEEE 1003.1c) defining an API for thread creation and synchronization. This is a specification for thread behavior, not an implementation. Operating-system designers may implement the specification in any way they wish. Numerous systems implement the Pthreads specification; most are UNIX-type systems, including Linux, Mac OS X, and Solaris. Although Windows doesn’t support Pthreads natively, some thirdparty implementations for Windows are available.
4.4.2 Windows Threads
The technique for creating threads using theWindows thread library is similar to the Pthreads technique in several ways. We illustrate the Windows thread
API in the C program shown in Figure 4.11. Notice that we must include the windows.h header file when using theWindows API.
4.4.3 Java Threads
Threads are the fundamental model of program execution in a Java program, and the Java language and its API provide a rich set of features for the creation
and management of threads. All Java programs comprise at least a single thread of control—even a simple Java program consisting of only a main() method
runs as a single thread in the JVM. Java threads are available on any system that provides a JVM includingWindows, Linux, and Mac OS X. The Java thread API
is available for Android applications as well. There are two techniques for creating threads in a Java program. One approach is to create a new class that is derived from the Thread class and to override its run() method. An alternative—and more commonly used—technique is to define a class that implements the Runnable interface. The
Runnable interface is defined as follows:
4.5 Implicit Threading 177(线程的本质相关问题)
threading from application developers to compilers and run-time libraries.This strategy, termed implicit threading, is a popular trend today. In this
section, we explore three alternative approaches for designing multithreaded programs that can take advantage of multicore processors through implicit threading.
THE JVM AND THE HOST OPERATING SYSTEM
The JVM is typically implemented on top of a host operating system (see Figure 16.10). This setup allows the JVM to hide the implementation details
of the underlying operating system and to provide a consistent, abstract environment that allows Java programs to operate on any platform that
supports a JVM. The specification for the JVM does not indicate how Java threads are to be mapped to the underlying operating system, instead leaving
that decision to the particular implementation of the JVM. For example, the Windows XP operating system uses the one-to-one model; therefore, each
Java thread for a JVM running on such a system maps to a kernel thread. On operating systems that use the many-to-many model (such as Tru64 UNIX), a
Java thread is mapped according to the many-to-many model. Solaris initially implemented the JVMusing the many-to-one model (the green threads library,
mentioned earlier). Later releases of the JVM were implemented using the many-to-many model. Beginning with Solaris 9, Java threads were mapped
using the one-to-one model. In addition, theremay be a relationship between the Java thread library and the thread library on the host operating system.
For example, implementations of a JVM for theWindows family of operating systems might use the Windows API when creating Java threads; Linux,
Solaris, and Mac OS X systems might use the Pthreads API.
4.5.1 Thread Pools
Whereas creating a separate thread is certainly superior to creatinga separate process, amultithreaded server nonetheless has potential problems.
The first issue concerns the amount of time required to create the thread,together with the fact that the thread will be discarded once it has completed
its work. The second issue is more troublesome. If we allow all concurrentrequests to be serviced in a new thread, we have not placed a bound on the
number of threads concurrently active in the system. Unlimited threads couldexhaust system resources, such as CPU time or memory. One solution to this
problem is to use a thread pool.
The general idea behind a thread pool is to create a number of threads at process startup and place them into a pool, where they sit and wait for work.
When a server receives a request, it awakens a thread from this pool—if one is available—and passes it the request for service. Once the thread completes
its service, it returns to the pool and awaits more work. If the pool contains no available thread, the server waits until one becomes free.
Thread pools offer these benefits:
1. Servicing a request with an existing thread is faster than waiting to create a thread.
2. A thread pool limits the number of threads that exist at any one point. This is particularly important on systems that cannot support a large
number of concurrent threads.
3. Separating the task to be performed from the mechanics of creating the task allows us to use different strategies for running the task. For example,
the task could be scheduled to execute after a time delay or to execute periodically.
The number of threads in the pool can be set heuristically based on factors such as the number of CPUs in the system, the amount of physical memory,
and the expected number of concurrent client requests. More sophisticated thread-pool architectures can dynamically adjust the number of threads in the
pool according to usage patterns. Such architectures provide the further benefit of having a smaller pool—thereby consuming less memory—when the load
on the system is low. We discuss one such architecture, Apple’s Grand Central Dispatch, later in this section.
4.5.2 OpenMP
OpenMP is a set of compiler directives as well as an API for programs written in C, C++, or FORTRAN that provides support for parallel programming in
shared-memory environments. OpenMP identifies parallel regions as blocks of code that may run in parallel. Application developers insert compiler
directives into their code at parallel regions, and these directives instruct the OpenMP run-time library to execute the region in parallel.
In addition to providing directives for parallelization, OpenMP allows developers to choose among several levels of parallelism. For example, they can set
the number of threads manually. It also allows developers to identify whether data are shared between threads or are private to a thread. OpenMP is available
on several open-source and commercial compilers for Linux, Windows, and Mac OS X systems. We encourage readers interested in learning more about
OpenMP to consult the bibliography at the end of the chapter.
4.5.3 Grand Central Dispatch
Grand Central Dispatch (GCD)—a technology for Apple’s Mac OS X and iOS operating systems—is a combination of extensions to the C language, an API,
and a run-time library that allows application developers to identify sections of code to run in parallel. Like OpenMP, GCD manages most of the details of
threading.
Internally, GCD’s thread pool is composed of POSIX threads. GCD actively manages the pool, allowing the number of threads to grow and shrink
according to application demand and system capacity.
4.5.4 Other Approaches
Thread pools, OpenMP, and Grand Central Dispatch are just a few of many emerging technologies for managing multithreaded applications. Other commercial
approaches include parallel and concurrent libraries, such as Intel’s Threading Building Blocks (TBB) and several products fromMicrosoft. The Java
language and API have seen significant movement toward supporting concurrent programming as well. A notable example is the java.util.concurrent
package, which supports implicit thread creation and management.
4.6 Threading Issues 183(线程问题)
4.6.1 The fork() and exec() System Calls
4.6.2 Signal Handling
A signal is used in UNIX systems to notify a process that a particular event has occurred. A signal may be received either synchronously or asynchronously,depending on the source of and the reason for the event being signaled. All signals, whether synchronous or asynchronous, follow the same pattern:
1. A signal is generated by the occurrence of a particular event.
2. The signal is delivered to a process.
3. Once delivered, the signal must be handled.
A signal may be handled by one of two possible handlers:
1. A default signal handler
2. A user-defined signal handler
4.6.3 Thread Cancellation
Thread cancellation involves terminating a thread before it has completed.
A thread that is to be canceled is often referred to as the target thread. Cancellation of a target thread may occur in two different scenarios:
1. Asynchronous cancellation. One thread immediately terminates the target thread.
2. Deferred cancellation. The target thread periodically checks whether it should terminate, allowing it an opportunity to terminate itself in an orderly fashion.
4.6.4 Thread-Local Storage
Threads belonging to a process share the data of the process. Indeed, this data sharing provides one of the benefits of multithreaded programming.
However, in some circumstances, each thread might need its own copy of certain data.We will call such data thread-local storage (or TLS.)
It is easy to confuse TLS with local variables. However, local variables are visible only during a single function invocation, whereas TLS data are
visible across function invocations. In some ways, TLS is similar to static data. The difference is that TLS data are unique to each thread. Most thread
libraries—including Windows and Pthreads—provide some form of support for thread-local storage; Java provides support as well.
4.6.5 Scheduler Activations
A final issue to be considered with multithreaded programs concerns communication between the kernel and the thread library, which may be required
by the many-to-many and two-level models discussed in Section 4.3.3. Such coordination allows the number of kernel threads to be dynamically adjusted
to help ensure the best performance. Many systems implementing either the many-to-many or the two-level
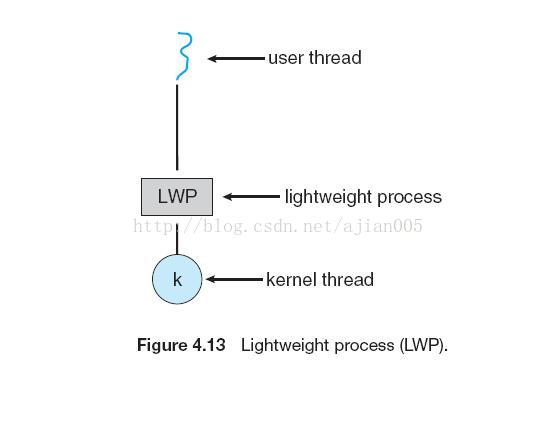
model place an intermediate data structure between the user and kernel threads. This data structure—typically known as a lightweight process, or
LWP—is shown in Figure 4.13. To the user-thread library, the LWP appears to be a virtual processor on which the application can schedule a user thread to
run. Each LWP is attached to a kernel thread, and it is kernel threads that the
4.7 Operating-System Examples 188(线程操作系统例子)
4.7.1 Windows Threads
4.7.2 Linux Threads
4.8 Summary 191
Exercises 191
Bibliographical Notes 199
Chapter 5 Process Synchronization(进程同步)
5.1 Background 203(背景)
竞争条件(race condition)
协作进程(cooperating process)不但影响系统中其它的进程,也受它们影响。协作进程之间可以直接 共享一个逻辑地址空间(确切的说是代码和数据),也可以通过文件实现数据共享。前者通过轻量级进程 或线程实现,我们在第5 节讨论。对共享数据的并发访问可能会导致数据的不一致。在本章,我们要讨论各种确保共享逻辑地址空间的协作进程有序执行的机制,以此来维护数据的一致性。
5.2 The Critical-Section Problem 206(临界区问题)
考虑由n 个进程{P0, P1, ..., Pn-l}构成的系统。每个进程有一个代码段,被称作临界区(critical section),进程在临界区内可能会修改公有变量、更新一个表、写一个文件等等。该系统的一个重要的特征是当一个进程在其临界区内执行时就不允许其它进程在它的临界区内执行。这样,进程对临界区的执行在时间上是
互斥的。(Thus, the execution of critical sections by the processes is mutually exclusive in time.)临界区问题是设计一个用于协作进程执行的协议。每个进程必须请求许可进入其临界区。实现这个请求的代码为进入区(entry section)。临界区随后可能会有一个退出区(exit section)。其余代码为剩余区(remainder section)。

临界区问题的解决方案必须要满足如下的三个要求:
1. 互斥(Mutual Exclusion):如果进程Pi 正在其临界区中执行,那么就不允许有其它进程在临界区中执行。
2. 有空让进(Progress):如果没有进程处于临界区而此时有进程希望进入临界区,那么只可以从这些不在剩余区执行的进程中挑选出下一个进入临界区的进程,而且这个选择不可以长时间的延缓。
3. 有限等待(Bounded Waiting):在一个进程请求进入临界区之后和获准之前,允许其它进程在有限的时间内进入临界区。
5.3 Peterson’s Solution 207 临界区的解决方案
5.3.1 两个进程的方案
5.3.2 多个进程的临界区问题
5.4 Synchronization Hardware 209(硬件支持同步)
有些机器提供了专门的硬件指令,允许我们原子地(atomically)测试或修改一个字(word)或交换两个字的内容——也就是说,把这些操作作为一个不可中断的单元。利用这些专门的指令,我们可以以一种相对简单的方式来解决临界区问题。在此,我们并不讨论具体某个机器的具体指令,而是要抽象出这些指令类型的主要概念
TestAndSet该指令最大的特点是它执行的原子性。这样,如果两个TestAndSet 指令同时执行(在不同的CPU 上),那么它们的顺序可以是以任意的。
Details describing the implementation of the atomic test_and_set() and compare_and_swap() instructions are discussed more fully in books on computer architecture.
如果机器支持TestAndSet 指令,我们就可以通过声明一个布尔变量lock(初始化为false)来实现互斥。
Swap 指令操作两个字;如同TestAndSet 指令,它也是原子执行的。
5.5 Mutex Locks 212(互斥锁)
operating-systems designers build software tools to solve the critical-section problem. The simplest of these tools is the mutex
lock. (In fact, the term mutex is short for mutual exclusion.) We use the mutex lock to protect critical regions and thus prevent race conditions. That is, a
process must acquire the lock before entering a critical section; it releases the lock when it exits the critical section. Theacquire()function acquires the lock,
and the release() function releases the lock,
5.6 Semaphores 213(信号量)
7.3 节讨论的临界区问题的解决方案难以适用于更为复杂的问题。为此,我们可以使用一种被称为信
号量的同步工具。信号量S 是一个整形数,除初始化以外,对它的访问只能通过两个标准原子操作:wait
和signal。最初,这被称为P 操作(for wait; from the Dutch proberen, to test)和V操作(for signal; from verhogen,to increment)
5.7 Classic Problems of Synchronization 219(经典同步问题)
5.7.1 The Bounded-Buffer Problem
5.7.2 The Readers–Writers Problem
5.7.3 The Dining-Philosophers Problem
5.8 Monitors 223(管程)
5.9 Synchronization Examples 232(同步例子)
5.10 Alternative Approaches 238
5.11 Summary 242
Exercises 242
Bibliographical Notes 258
5.12 原子事务
临界区的互斥访问确保了临界区执行的原子性。
7.9.1 系统模型
数据库事务模型
7.9.2 基于日志的数据恢复
一种确保原子性的方法是在稳态存储器中记录事务对所访问的各种数据的所有修改。应用最广泛的是写在前日志(write-ahead logging)。系统在稳态存储器中维护一个被称为日志(log)的数据结构。每个日志记录描述一个单独的事务写操作,它包含如下的字段:
(1)事务名称:执行写操作的事务的唯一名称。
(2)数据项名称:被写入的数据项的唯一名称。
(3) 旧值:数据项在写操作执行前的值。
(4) 新值:数据项在写操作执行后的值。
其它的日志记录记录事务处理过程中的重要事件,如事务的开始和事务的提交或放弃。
利用日志,系统可以应对任何故障而不会导致在非易失性存储器中丢失信息。恢复算法利用两个函数:
(1) undo(Ti),将事务Ti 更新的所有数据的值恢复到旧值。
(2) redo(Ti),将事务Ti 更新的所有数据的值设为新值。
7.9.3 检查点
为了减少这些开销,我们引入检查点(check-point)。在执行的过程中,系统维护写在前日志。另外,
系统周期性的执行检查点,需要进行如下的操作:
1. 将当前驻留在易失性存储器(通常使用主存储器)中的所有的日志记录输出到稳态存储器中。
2. 将当前驻留在易失性存储器中的所有已修改的数据输出到稳态存储器中。
3. 将一个日志记录 <checkpoint>输出到稳态存储器。
7.9.4 并发原子事务
并行控制(concurrency-control)算法
7.9.4.1 可串行性
7.9.4.2 封锁协议:两段锁协议(two-phase locking protocol)
7.9.4.3 基于时间戳的协议
Chapter 6 CPU Scheduling(CPU调度)
6.1 Basic Concepts 261(基本概念)
CPU 调度是多道程序操作系统的基础。通过在进程间转换CPU,操作系统可以提高计算机的生产力。
为了最大限度的提高CPU 利用率,多道程序设计的目标是保持总是有进程可供执行。
多道程序设计的思想十分简单。一个进程持续运行直到它必须等待某些操作(I/O 请求是个典型)的完成。在简单的计算机系统中,进程等待时CPU 将处于空闲状态;这浪费了所有的等待时间。利用多道程序设计,我们可以有效地利用这段时间。在内存中同时保留多个进程。当一个进程必须等待时,操作系统将CPU 撤离该进程并把CPU 分配给另一个进程。然后以这种方式继续运行。调度是一个基本的操作系统功能。几乎所有的计算机资源在使用前都需要调度。当然了,CPU 是首要的计算机资源之一。因此CPU 调度是操作系统设计的核心问题。
6.1.1 CPU-I/O Burst 周期
CPU 调度依赖于进程的这一特性:进程执行包含了CPU 执行周期(cycle)和I/O 等待时间。进程在这两个状态之间交替转换。进程执行开始于一个CPU burst。随后是一个I/O burst,然后是另一个CPUburst,再是一个I/O burst,等等。最终,最后的CPU burst 以一个终止执行的系统请求结束,而不是一个I/O burst。
6.1.2 CPU 调度程序
只要CPU 空闲,操作系统就必须从就绪队列中选择一个进程执行。进程的选择由短程调度程序(或CPU 调度程序)完成。调度程序从内存中的就绪进程中做出选择,并将CPU 分配给其中之一(调度程序选择的进程)。就绪队列没有必要是一个先进先出(FIFO)队列。正如在稍后讨论各种调度算法时所见,可以把就绪队列实现为FIFO 队列、优先队列、树或者仅仅是个无序链表(unordered linked list)。然而从概念上讲,就绪队列中的所有进程排队等待获取CPU 执行的机会。队列中的记录通常是进程的进程控制块(PCB)
6.1.3 抢占式调度
在如下的四种情况下可能会进行CPU 调度:
1. 当进程从运行状态转换到等待状态时( 例如:I/O 请求或等待一个子进程的终止)(for example, I/O
request, or invocation of wait for the termination of one of the child processes )
2. 当进程从运行状态转换到就绪状态时(例如:当发生中断时)
3. 当进程从等待状态转换到就绪状态时(例如:I/O 完成)
4. 当进程终止时
在第一种和第四种情况下没有调度方面的选择。(In circumstances 1 and 4, there is no choice in terms of
scheduling.)必须要选择一个新进程(如果就绪队列中有进程存在)执行。然而,在第二种和第三种情况
下需要作出选择。(There is a choice, however, in circumstances 2 and 3.)
我们称只在第一种和第四种情况下进行的调度为非抢占式的(nonpreemptive);否则为抢占式的
(preemptive )。在非抢占式调度下,一旦把CPU 分配给一个进程,那么该进程就会保持CPU 直到终止或
转换到等待状态
6.1.4 调度程序
CPU 调度中的另一个组成部分是调度程序(dispatcher)。调度程序是一个模块,它将CPU 控制提交给
短程调度程序选择的进程。其工作包括:
l 转换上下文
l 转换到用户摸式
l 跳转到用户程序中的正确位置重新开始该程序
调度程序应该尽可能的快,因为每次进程转换都要调用它。调度程序停止一个进程并开始运行另一个进程所需的时间被称为调度时间。
6.2 Scheduling Criteria 265(调度准则)
调度准则包括:
CPU 利用率:我们希望尽可能的保持CPU 忙碌。CPU 利用率可能在0 到100 之间。在实际的系统中,CPU 利用率的范围应该在40%(系统负荷较轻)到90%(系统负荷较重)之间。
吞吐量:如果CPU 忙于执行进程,那么工作正在进行(就要完成了)。对工作量的一种测量是单位时间内完成的进程数,被称为吞吐量。(If the CPU is busy executing processes, then work is being done. Onemeasure of work is the number of processes completed per time unit, called throughput.)对较长的进程来说吞吐量可能是每小时一个进程;对于较短的事务来说可能是每秒十个进程。
周转时间:对一个进程来说,一个重要的指标是它执行所需要的时间。(From the point of view of a particular process, the important criterion is how long it takes to execute that process.)从进程提交到进程完成的时间间隔为周转时间。周转时间是等待进入内存的时间、在就绪队列中等待的时间、在CPU 中执行的时间和I/O 操作的时间的总和。
等待时间:CPU 调度算法并不能影响进程的执行时间和I/O 操作时间;它只能影响进程在就绪队列中等待的时间。等待时间是进程在就绪队列中耗费时间的总和。
响应时间:在交互式系统中,周转时间可能不是最好的指标。进程通常会很早的产生一些输出,并且在先前的结果输出给用户时继续计算。因此,另一个度量标准是从进程提交请求到产生首次响应的时间。这被称为响应时间,是开始响应所需的时间,而不是到产生输出结果所需的时间。周转时间通常受限于输出设备的速度。
我们希望最大化CPU 利用率和吞吐量,最小化周转时间、等待时间和响应时间。在大多数情况下,我们最优化平均值。然而,在某些情况下我们需要最优化最小或最大值,而不是平均值。例如,为了保证所有的用户获得满意的服务,我们可能需要最小化最大的响应时间。
6.3 Scheduling Algorithms 266(调度算法)
6.3.1 先来先服务调度算法
6.3.2 短作业优先调度算法
6.3.3 优先调度算法
6.3.4 轮转调度算法
6.3.5 多级队列调度算法
6.3.6 多级反馈队列调度算法
6.4 Thread Scheduling 277(线程调度)
6.4.1 Contention Scope
6.4.2 Pthread Scheduling
6.5 Multiple-Processor Scheduling 278(多处理机调度)
有两种调度方法可供使用。第一种方法,每个处理器是自调度的(self-scheduling)。每个处理器检查公共队列并选择一个进程执行。正如我们将在第七章所见,如果有多个处理器试图访问并更新一个公共数据结构,那么每个处理器都必须仔细设计(be programmed very carefully)。必须确保两个处理器不会选择同样的进程,还要保证队列中不会丢失进程。
另一种方法是指定一个处理器作为其它处理器的调度者,这样就避免了上述问题,从而创建了一种主从结构(master-slave structure)。有些系统进一步扩展了这种结构:使用一个单独的处理器(主服务器)处理所有的调度、I/O 处理和其它的系统活动。其它的处理器只是执行用户代码。因为只有一个处理器访问系统数据结构,减轻了对数
据共享的需求,所以这种不对称多处理远比对称多处理简单。然而,它也不如对称多处理那样高效。I/O繁忙型进程可能会阻塞执行所有操作的那个CPU。(I/O-bound processes may bottleneck on the one CPU thatis performing all of the operations.)通常在一个操作系统中首先实现不对称多处理,然后随着系统的发展将其升级为对称多处理。
6.6 Real-Time CPU Scheduling 283(实时调度)
实时计算可以分为两种类型。
硬实时系统用于在保证的时间内完成关键性的任务。
软实时计算受到的约束就少一些。要确保其关键性进程的优先权要高于其它进程的优先权。
6.7 Operating-System Examples 290(6.7 进程调度模型)
我们将线程引入了进程模型,这允许一个单独的进程有多个控制执行序列。此外,我们还要区分用户级线程和内核级线程。用户级线程由一个线程库管理,内核并不知道它们。为了在CPU 上运行,用户级线程最终要映象到一个相关的内核级线程,虽然这种映象可能会使用一个轻量级进程(LWP)间接进行。用户级线程和内核级线程的差别在与它们被调度的方式不同。线程库调度用户级进程在一个有效的LWP 上运行,一种方案被称为process local scheduling,应用程序在本地进行线程调度。相反,内核采用system global scheduling 来决定调度那个内核线程。我们并不详细讨论这与线程库本地调度线程的不同之处;线程调度是一个软件库(software-library)所关心的问题,而不是操作系统需要关心的。我们要讨论全局调度(global scheduling)是因为这是由操作系统实现的。
6.7.1 实例:Solaris 2
Solaris 2采用了基于优先权的进程调度。它有四种调度类型,按照优先权顺序依次为:实时类型、系统类型、分时类型和交互式类型。每种类型都包含了不同的优先权和调度算法,而分时类型和交互式类型采用了同样的调度策略。
6.7.2 实例:Windows 2000
Windows 2000 线程调度采用基于优先权的抢占式调度算法。
6.7.3 实例:Linux
Linux 提供了两个单独的调度算法。一个是分时调度,用于在多个进程之间公平的抢占调度;另一个是实时作业,在此,绝对优先权比公平更加重要。
要注意,Linux 实时调度是软实时调度,而不是硬实时调度。调度程序提供了关于相对优先权的严格的保证,但是内核并不保证实时进程就绪时要多久就能够被调度运行。记住:Linux 内核代码永远不会被用户模式下运行的代码抢占。如果在内核为一个进程执行一个系统调用时有一个中断到达唤醒一个实时进程,那么这个实时进程只好等待当前系统调用完成或者阻塞。
6.8 Algorithm Evaluation 300
我们怎样为具体系统选择一个CPU 调度算法呢?
所以说选择一个算法是非常困难的。第一个问题是定义选择算法所参考的标准。在6.2 节我们看到,这些标准通常涉及到CPU 利用率、响应时间或吞吐量。为了选择一个算法,我们必须首先定义相对重要的一些方面。我们的标准可能包括了几个问题,如:
(1) 在最大化响应时间为1 秒的约束条件下最大化CPU 利用率。
(2)最大化吞吐量,以使周转时间(平均值)与总执行时间线性成比例。
一旦定义了选择的标准,我们就要在关注的条件下评估各种算法。(Once the selection criteria have beendefined, we want to evaluate the various algorithms under consideration.)从6.6.1 节到6.6.4 节我们描述各种不同的评估方法
6.6.1 确定模型法
一种重要的评估类型被称为analytic evaluation。Analytic evaluation 使用给定的算法和系统工作量来产生能够评价在该工作量下这种算法性能的一个公式或数字。
确定模型法(deterministic modeling)是一种analytic evaluation。这种方法利用了具体的预定义的工作负荷并判定在这种工作负荷下各种算法的性能。
6.6.2 队列模型(Queueing Models)
运行在很多系统中的进程日复一日的不断改变,没有一个静态的进程集可以用于确定模型法。然而,我们可以确定CPU 和I/O burst 的分布。这种分布是可测量的,并可以近似的或简单的估算。可以生成一个描述具体的CPU burst 的数学公式。通常,这种分布成指数分布并可以通过它的意义来描述。类似的,必须给定进程到达系统的时间的分布——到达时间分布(arrival-time destribution)。我们把计算机系统描述为一个服务器网络。每个服务器有一个等待进程队列。CPU 是服务器,有自己的就绪队列;同样,I/O 系统有自己的设备队列。只要知道到达速率和服务速率,我们就可以计算利用率、平均队列长度、平均等待时间等等。这种研究方法被称为队列网络分析(queueing-network analysis)
6.6.3 模拟法
为了更加精确的评估调度算法,可以使用模拟法(simulation)。模拟法包括了设计一个计算机系统模型。利用软件数据结构来表示主要的系统组件。模拟器(simulator)利用一个变量来表示时钟;随着这个变量值的增加,模拟器修改系统的状态来反映设备、进程和调度程序的活动。随着模拟器的运行,指示算法性能的统计报表被集中起来并打印。有多种方法可以生成驱动模拟器的数据。最通用的方法是使用一个随机数发生器,这是一个程序,它根据概率分布产生进程数目、CPU burst 时间、到达时间、离开时间等等。这种分布可能是算术的(均匀分布、指数分布或泊松分布)或以经验为主。如果根据经验来定义分布,那么可以获得研究中的真实系统的测量数据。(If the distribution is to be defined empirically, measurements of the actual system under study aretaken.)其结果用于在实系统(real system)中定义事件的实际分布,这个分布可以用来驱动模拟器。
6.9 Summary 304
Exercises 305
Bibliographical Notes 311
Chapter 7 Deadlocks(死锁)
7.1 System Model 315(系统模型)
在普通操作方式下,进程只能通过如下的顺序使用资源:
1. 请求:如果请求不能够立刻得到允许(例如,所请求的资源正为另一个进程所用),那么发出请求的进程必须等待,直到它可以获得该资源。
2. 使用:进程可以对资源进行操作(例如,如果资源是打印机,那么该进程可以在这个打印机上打印)。
3. 释放:进程释放资源。
7.2 Deadlock Characterization 317(死锁的特征)
在死锁中,进程不会结束执行,而且系统资源被占据,其它进程不能开始执行。在讨论处理死锁的各种方法之前,我们首先描述死锁的特征。
7.2.1 产生死锁的必要条件
在系统中,如果如下四个条件同时成立,那么死锁能够发生:
1. 互斥条件:必须至少有一个资源以非共享的方式被进程持有;更确切的说,同时只有一个进程可以使用该资源。如果另一个进程请求这个资源,那么该进程必须等待这个资源被释放。
2. 持有并等待条件:进程必须持有至少一个资源且等待获取另外的当前被其它进程持有的资源。
3. 不可抢占条件:不可以抢占资源;也就是说,资源的释放只可以是由持有它的进程完成工作后自动释放。
4. 循环等待条件:对一组等待进程{P0, P1, …, Pn}来说,必须:P0 等待P1 持有的资源,P1 等待P2持有的资源,…,Pn-1 等待Pn 持有的资源,而Pn 等待P0 持有的资源。
我们强调所有的这四个条件必须成立时死锁才会发生。循环等待条件意味着持有并等待条件,所以这四个条件并不完全是独立的。
7.2.2 资源分配图
可以利用系统资源分配图(system resource-allocation graph)来更精确的描绘死锁。这种图有一组顶点V和一组边E组成。顶点V分为两个不同类型的节点:由系统中所有的活动进程组成的节点P = { P0, P1, …,Pn }和由系统中所有的资源类型组成的节点R = { R0, R1, …, Rm }。
7.3 Methods for Handling Deadlocks 322(处理死锁的方法)
主要有三种方法可以处理死锁:
(1) 采用某种协议预防或避免死锁,确保系统不会进入死锁状态。
(2) 允许系统进入死锁状态,然后检测并恢复。
(3) 完全忽视死锁并假设系统中不会发生死锁。包括UNIX 在内的大多数操作系统采用了这种方法。
7.4 Deadlock Prevention 323(死锁预防)
只有四个必要条件同时成立才会发生死锁。只要确保其中的一个条件不会成立,我们就可以预防死锁。让我们逐个测试这四个必要条件来详细说明这中方法。
7.4.1 互斥条件
必须确保对不可共享资源(nonsharable resource)的互斥条件
7.4.2 持有和等待条件
为了确保系统中不会发生持有和等待条件,我们必须确保:不论进程何时请求资源,它都不可以持有其它任何资源。可以采用一种协议:要求每个进程在开始执行之前请求并获取所需的所有资源。要求进程请求资源的系统调用在所有其它的系统调用之前执行,这样可以实现这个规定。
7.4.3 不可抢占条件
第三个必要条件是不可抢占已经分配给进程的资源。为了确保这个条件不会成立,我们可以采用如下的协议。如果一个进程持有一些资源并请求另外的资源,而不能够立刻获取所请求的资源(也就是说,这个进程必须等待),那么当前持有的所有资源被抢占。换句话说,这些资源隐含的被释放了。被抢占的资源被添加到这个进程所等待的资源列表。只有当这个进程可以重新获取它的旧资源和所请求的新资源时,它才可以重新开始运行。
7.4.4 循环等待条件
循环等待条件是死锁的第四个也是最后一个条件。确保这个条件不会成立的一种方法是对所有的资源类型进行总的排序,并要求进程以递增的顺序请求资源。
7.5 Deadlock Avoidance 327(死锁避免)
各种算法在所需信息的数量和类型上有所不同。最简单也是最常用的算法要求每个进程声明它可能需要的每种资源的最大数目。预先给定进程所需各类资源的最大数量就有可能构建一个可以确保系统不会进入死锁状态的算法。这个算法定义了死锁避免的方法。死锁避免算法动态检查资源分配状态(resource-allocation state)以确保不会出现循环等待条件。有效资源的数量、被分配资源的数量和进程的最大需求量共同定义了资源分配状态。
7.5.1 安全状态
如果系统能够以某些顺序为每个进程分配资源(可满足进程的最大需求)并依然可以避免死锁,那么系统的状态是安全的。
7.5.2 资源分配图算法
如果资源分配系统的每种资源只有一个实例,那么可以使用一种与8.2.2 节定义的资源分配图有所不同的资源分配图来避免死锁。
7.5.3 银行家算法
资源分配图算法不适于每种类型的资源有多个实例的系统。我们稍后描述的死锁避免算法适合这种系统,但是它的效率不如资源分配图算法。这个算法被称为银行家算法。选择这个名字是因为这个算法可以用杂银行系统中来确保银行安全的将现金分配给客户以满足他们的要求。
7.6 Deadlock Detection 333(死锁检测)
如果系统没有采用死锁预防或死锁避免算法,那么就有可能发生死锁。在这种环境下,系统必须提供:
(1) 用于检测系统状态以确定是否发生死锁的算法
(2) 从死锁中恢复的算法
7.6.1 每种资源类型都只有单个实例的系统
如果每种资源只有一个实例,那么我们修改资源分配图来定义一种死锁检测算法,这被称为等待图(wait-for graph)。我们从资源分配图中移除资源类型节点和相应的边。
7.6.2 资源类型有多个实例的系统
等待图机制不适于每种资源类型有多个实例的系统。我们稍后描述的死锁检测算法适于这样的系统。
7.6.3 死锁检测算法的应用
什么时候我们应该调用死锁检测算法呢?要考虑两个因素:
1. 可能多久发生一次死锁?
2. 死锁发生时会影响到多少进程?
如果死锁频繁发生,那么应该经常性的调用死锁检测算法。占有资源的死锁进程在死锁解除前处于空闲状态。另外,包含在死锁中的进程数量可能会增加。
7.7 Recovery from Deadlock 337(从死锁中恢复)
7.7.1 进程终止
为了通过异常终止进程来消除死锁,我们有两种方法可以选择。在这两种方法中,系统都需要回收被终止进程所持有的所有资源。
(1)异常终止所有的死锁进程:这种方法无疑可以打断死锁循环,但是代价高昂:这些进程可能已经计算了很长一段时间,而且必须丢弃这些计算结果并稍后可能需要重新计算。
(2)每次异常终止一个进程直到消除死锁循环:这种方法会招致相当可观的开销,因为每次终止进程之后都需要执行一次死锁解除算法来确定是否仍旧有进程死锁。
7.7.2 抢占资源
为了采用抢占资源的方式来消除死锁,我们不断抢占进程的资源并将这些资源分配给其它进程,直到打破死锁循环。
7.8 Summary 339
Exercises 339
Bibliographical Notes 346
参考:
《操作系统概念第七/九版》:[Operating.System.Concepts(9th,2012.12)].Abraham.Silberschatz
NPTL(Native POSIX Thread Library):http://zh.wikipedia.org/wiki/Native_POSIX_Thread_Library
Linux线程 http://www.cnblogs.com/forstudy/archive/2012/04/05/2433853.html
Pthread、 Qthread、 BoostThread、WindowThread、JavaThread
JVM中可生成的最大Thread数量 http://jzhihui.iteye.com/blog/1271122
JDK 7 中的 Fork/Join 模式: http://www.ibm.com/developerworks/cn/java/j-lo-forkjoin/















 4525
4525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









