









python常用数据类型str、list、tuple、set、dict的常用方法汇总&编码与解码
一、字符串(str)的常用方法
1.1 字符串的格式化
1.1.1 %s、%d、%f进行占位
# 1. 字符串占位:%s 备注:其实可以代替%d、%f
# 2. 整数占位:%d 小数占位:%f
name = "zhangsan"
address = "chengdu"
age = 18
hobby = "meiniu"
str1 = "我的名字%s,家住%s,年龄%d岁,爱好%s" % (name,address,age,hobby)
1.1.2 {}进行占位,.format()填充
name = "zhangsan"
address = "chengdu"
age = 18
hobby = "meiniu"
str2 = "我的名字{},家住{},年龄{}岁,爱好{}".format(name,address,age,hobby)
1.1.3 f-string(最推荐的方式)
name = "zhangsan"
address = "chengdu"
age = 18
hobby = "meiniu"
# 方法三:f-string
str3 = f"我的名字{name},家住{address},年龄{age}岁,爱好{hobby}"
1.2 字符串的索引、切片、常用方法、切割、替换等
1.2.1 字符串的索引、切片
str_1 = "张三爱上了李四的妹妹"
# 索引
print(str_1[3])#从0开始,index=3的位置:上
# 切片1
print(str_1[2:5])# 前闭后开,从index=2开始取,到5-1的位置:爱上了
# 切片2
print(str_1[5:2:-1])# 李了上
print(str_1[::-1])# 妹妹的四李了上爱三张
1.2.2 字符串的常用方法:upper()、lower()
# str的常规操作
# 字符串的操作一般不对原字符串产生影响,一般是返回一个新的字符串
# 字符串:首字母大小,其余小写
s = "pytHOn"
s1 = s.capitalize()# Python
# 单词的首字母大写
str = "i hava a big dream!!"
str1 = str.title() # I Hava A Big Dream!!
print(str1)
# 所有小写字母变为大写
str2 = str.upper()
print(str2)
# 所有大写字母变为小写
str3 = str.lower()
print(str3)
1.2.3 字符串的切割与替换:strip()、replace()、split()
# strip()去掉一个字符串前后两端的空白符(空格、\t,\n),在登录功能的时候应该实现的用户体验优化
s = " 你好, 我的名字 是 德华 "
s1 = s.strip()# 你好, 我的名字 是 德华
print(s1)
# replace(old,new),字符串替换
s = " 你好, 我的名字 是 德华 "
s1 = s.replace(" ","")
print(s1) #你好,我的名字是德华
s2 = s1.replace("德华","星驰")
print(s2)#你好,我的名字是星驰
# split(使用什么切割),返回列表;注意:使用什么切割,返回结果就没有该切割元素
s = "python_java_vue_js_c_c#_javascript"
li = s.split("_") # ['python', 'java', 'vue', 'js', 'c', 'c#', 'javascript']
print(li)
1.3 字符串的查找和判断
1.3.1 字符串的查找:find()、startswith()、endswith()
# find(要寻找的内容),返回内容所在,如果返回:-1,,表示不存在;
s = "你好,欢迎光临,周先生"
ret = s.find("先生")# 9
print(ret)
ret = s.index("先生")# 9 index如果不存在,则报错
print(ret)
一般情况下判断字符串A在另一个字符串中,使用:in
name = "张无忌#"
if name.startswith("张"):
print("姓张")
else:
print("不姓张")
# endswith()
if name.endswith("#"):
print("以#结尾")
else:
print("不以#结尾")
1.3.1 字符串的判断:isdigit()、isdecimal()
# 判断字符串是否是由整数组成
money = "12"
if money.isdigit():
print("是整数组成,可以转换")
money = int(money)
print(money)
1.4 字符串的补充方法:len()、join()
# len():长度
s = "张三李四王二麻子"
print(len(s)) # 长度:8
# join() 和 split()是相反的;split将字符串分割返回list; join则是将list串为字符串
li = ["刘德华","周星驰","吴奇隆","周润发"]
str1 ="&".join(li)
print(str1)# 刘德华&周星驰&吴奇隆&周润发
二、list的常用方法
2.1 列表的追加、插入、合并:append()、insert()、extend()
# append()
li.append("吴奇隆")
li.append("刘德华")
print(li)# ['吴奇隆', '刘德华']
# insert()
li.insert(1,"周星驰")# ['吴奇隆', '周星驰', '刘德华']
print(li)
li_1 = ["赵本山","刘德华"]
li_2 = ["吴奇隆","周星驰"]
# 将li_2合并到 li_1
li_1.extend(li_2)
print(li_1) # ['赵本山', '刘德华', '吴奇隆', '周星驰']
2.2 列表的元素删除:pop()、remove()
li_3 = ['赵本山', '刘德华', '吴奇隆', '周星驰']
ret = li_3.pop(3) # 给出被删除的索引,return被删除的元素
print(li_3)
print(ret)
li_3.remove("周星驰") # 不返回
2.3 列表的元素修改、查询:使用index进行修改、查询
2.4 列表元素的排序:sort()
li_3 = ['赵本山', '刘德华', '吴奇隆', '周星驰']
li_4 = [123,234,321,2,3,1,6,7,67,78]
# sort():升序 排列
li_3.sort() #['刘德华', '吴奇隆', '周星驰', '赵本山']
li_4.sort() #[1, 2, 3, 6, 7, 67, 78, 123, 234, 321]
print(li_3)
print(li_4)
# sort(reverse=True):降序 排列
li_3.sort(reverse=True) #['赵本山', '周星驰', '吴奇隆', '刘德华']
li_4.sort(reverse=True) #[321, 234, 123, 78, 67, 7, 6, 3, 2, 1]
print(li_3)
print(li_4)
2.5 列表元素的循环删除:(删除一个,后面的元素会向前移动,会导致循环漏掉部分元素)
li = ["刘皇叔","刘天王",'赵本山', '周星驰', '吴奇隆', '刘德华']
# for item in li :
# if item.startswith("刘"):
# li.remove(item) # 把姓刘的删除(但是,后面的元素就前移动了,就会漏掉个别姓刘的,导致漏删)
# 最稳妥的删除方式:
# 准备一个临时list
temp = []
for item in li :
if item.startswith("刘"):
temp.append(item) # 把姓刘的先记录在另一个list
for item in temp:
li.remove(item) # 再循环临时list,去原列表删除;这样临时的列表每个元素都会被循环到;原列表要删除的元素都会被删除;
三、tuple(元祖:不可变的)
某些固定的数据,不允许外界修改的时候,使用tuple;
特殊1:如果元祖tuple只有一个元素,需要在元素的末尾添加一个逗号
tup = ("元祖元素") # 程序会认为是字符串,默认()是优先级
# 如果硬是要设置一个元素的元祖数据
tup = ("元祖元素",)
特殊2:tuple不可变,但是元祖元素如果是可变的类型,如:list;
tup = (1,2,3,"张三",["元素1","元素2","元素3"])
tup[3].append("元素4")# 这样是可以的;只要元祖元素tup[3]本身是个list,如果你tup[3]="改成字符串类型或其他",这样就会报错;
四、set(集合):元素间是无序的
4.1、set(集合)定义的注意事项:元素可哈希
# 可哈希:python中set集合进行数据存储的时候,需要对数据进行哈希计算,根据计算出来的哈希值进行存储数据;
# set集合要求存储的元素,必须是可以进行哈希计算的:
# 不可变的数据类型值(是值,不是变量类型):int、str、tuple、bool
#
# 不可哈希:可变的数据类型值(是值,不是变量类型):list、dict、set 这些是不可作为set元素值存储在set变量中的;
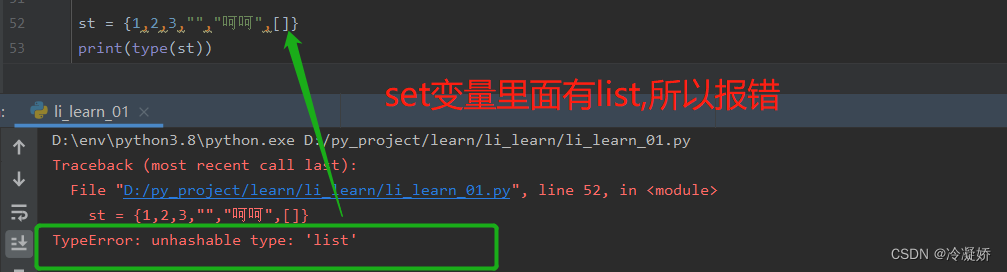
4.2、set(集合)创建空集合的方式:不是st = {} ,这样默认是dict
st = set()
4.3、set(集合)元素的添加、删除:add()
s = set()
s.add("赵本山")
s.add(123)
s.pop()# 因为set是无序的,所以没有index;pop()里面就不传参数,默认删除最后一个(随机的),没什么用;
s.remove("范伟")# 作用大于pop()
五、dict(字典):键值对的形式存储数据,字典的key必须是可哈希的数据类型
5.1 、dict的增删改查:setdefault()、get()
dict1 = {}
dict1["name1"] = "周杰伦"
# 设置默认值:setdefault("key","value"),如果所传入的key已经有值了,则该默认值不生效;
dict1.setdefault("test_key","我是默认值")
# 删除
# dict1.pop("name1") # 根据key来删除
# 查询
# 1.根据key进行查询:dict1["key"],如果key不存在,则 报错;当key是确定时,使用;
print(dict1["name1"])
# 2.使用get方法查询:dict1.get("key"),如果key不存在,则返回None;当key不确定时,使用;
print(dict1.get("name1"))
5.2 、dict的循环、嵌套(嵌套就不记录了)
# 2. 希望把所有的key放在一起,如:放在列表中
print(list(dict2.keys())) # 拿到所有的key,强制转list
# 3. 希望把所有的value放在一起,如:放在列表中
print(list(dict2.values())) # 拿到所有的value,强制转list
# 1. for循环,直接拿到key:
for key in dict2:
print(key,dict2[key])
# 4. 直接拿到字典的key:value
for item in dict2.items():
print(item) #返回tuple:(key,value)
key = item[0]
val = item[1]
# 5. 优化 方法4,,,元祖或列表(备注:dict2.items()返回的就是tuple:(key,value))都可以执行该操作。该操作被称为解包(解构)
for key,val in dict2.items():
print(key,val)
5.3 、dict的循环删除(和list一样类似的问题)
dict2 = {
"王二":"丑",
"赵四":"嘴歪",
"刘能":"结巴",
"刘天王":"帅"
}
#删除 姓刘的
for key,val in dict2.items():
if key.startswith("刘"):
dict2.pop(key) # 报错:RuntimeError: dictionary changed size during iteration 在循环的时候改变了大小(和列表删除类似)
dict2 = {
"王二":"丑",
"赵四":"嘴歪",
"刘能":"结巴",
"刘天王":"帅"
}
# 稳妥的删除,准备一个临时dict,放要删除的key:val
temp = {}
for key,val in dict2.items():
if key.startswith("刘"):
temp[key] = val
# 循环临时的dict,删除原dict
for key,val in temp.items():
dict2.pop(key)
print(dict2)
六、字符集、编码、解码
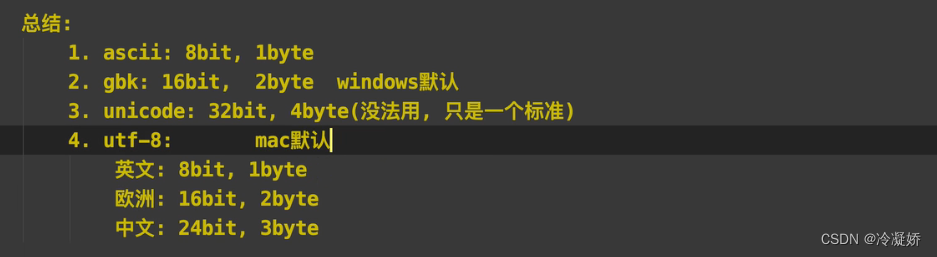
6.1 、编码与解码
1. str.encode("编码") # 进行编码
"刘德华".encode("gbk") # b'\xe5\x91\xe6\x9d\xe6\x9d'
"刘德华".encode("utf-8")# b'\xe5\x91\xe6\x9d\xe6\x9dx9d\xe6\x9d'
2. bytes.decode("编码") # 进行解码
b'\xe5\x91\xe6\x9d\xe6\x9d'.decode("gbk")
b'\xe5\x91\xe6\x9d\xe6\x9dx9d\xe6\x9d'.decode("utf-8")
















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











