







原文传送门:sklearn浅析(一)——sklearn的组织结构
sklearn是基于numpy和scipy的一个机器学习算法库,设计的非常优雅,它让我们能够使用同样的接口来实现所有不同的算法调用。本文首先介绍下sklearn内的模块组织和算法类的顶层设计图。
三大模块
监督学习(supervised learning)
1.
- neighbors:近邻算法
- svm:支持向量机
- kernel-ridge:核——岭回归
- discriminant_analysis:判别分析
- linear_model:广义线性模型
2.
- ensemle:集成方法
- tree:决策树
- naive_bayes:朴素贝叶斯
- cross_decomposition:交叉分解
- gaussian_process:高斯过程
3.
- neural_network:神经网络
- calibration:概率校准
- isotonic:保序回归
- feature_selection:特征选择
- multiclass:多类多标签算法
以上的每个模块都包括多个算法,在调用时直接import即可,譬如:
from sklearn.svm import SVC
svc = SVC()- 1
- 2
无监督学习(unsupervised learning)
1.
- decomposition:矩阵因子分解
- cluster:聚类
- manifold:流形学习
- mixture:高斯混合模型
2.
- neural_network:无监督神经网络
- density:密度估计
- covariance:协方差估计
使用方式同上。
数据变换
1.
- feature_extraction:特征抽取
- feature_selection:特征选择
- preprocess:预处理
2.
- random_projection:随机投影
- kernel_approximation:核逼近
- pipline:管道流(这个严格说不算是数据变换模块)
算法类的顶层设计图
- baseEstimator:所有评估器的父类
- ClassifierMixin:所有分类器的父类,其子类必须实现一个score函数
- RegressorMixin:所有回归器的父类,其子类必须实现一个score函数
- ClusterMixin:所有聚类的父类,其子类必须实现一个fit_predict函数
- BiClusterMixin:
- TransformerMixin:所有数据变换的父类,其子类必须实现一个fit_transform函数
- DensityMixin:所有密度估计相关的父类,其子类必须实现一个score函数
- MetaEsimatorMixin:可能是出于兼容性考虑,看名字就能知道,目前里面没有内容
我们以svm和cluster为例,介绍其继承关系图:
svm
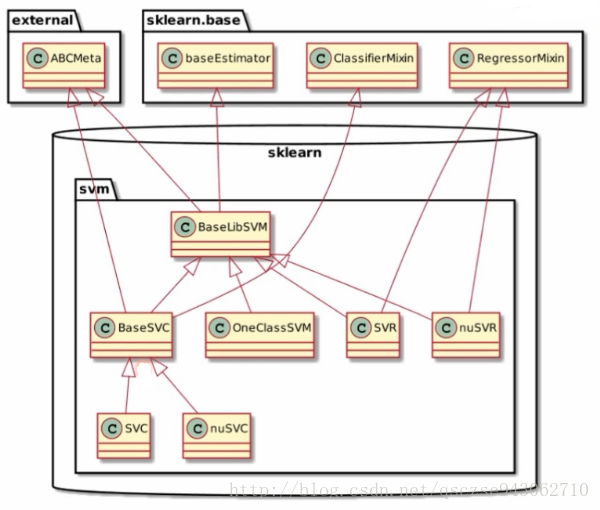
这里SVC即support vector classifier,SVR即support vector regression,svm既可以作为分类器,也可以作为回归器,所以,它们分别继承实现了ClassifierMixin和RegressorMixin。
cluster
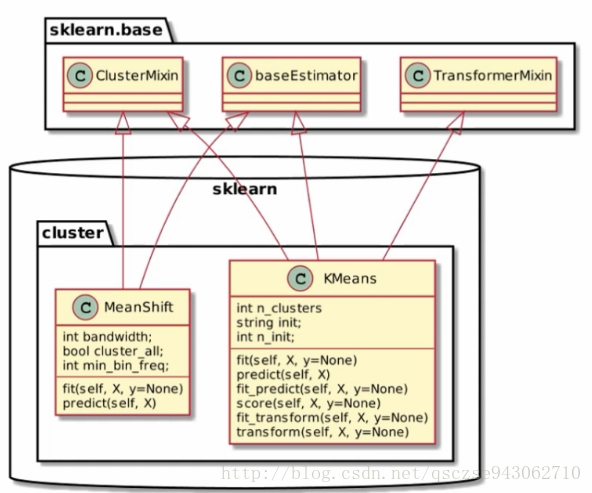
这里以MeanShift和KMeans为例,可以看到KMeans实现了TransformerMixin类,因此它有一个transform方法。
统一的API接口
在sklearn里面,我们可以使用完全一样的接口来实现不同的机器学习算法,通俗的流程可以理解如下:
- 数据加载和预处理
- 定义分类器(回归器等等),譬如svc = svm.svc()
- 用训练集对模型进行训练,只需调用fit方法,svc.fit(X_train, y_train)
- 用训练好的模型进行预测:y_pred=svc.predict(X_test)
- 对模型进行性能评估:svc.score(X_test, y_test)
模型评估中,可以通过传入一个score参数来自定义评估标准,该函数的返回值越大代表模型越好。sklearn有一些预定义的score方法,这些方法名在sklearn.metrics.SCORERS中定义,调用时只需传入相应的字符串即可,可以通过如下方式获取到所有预定义的方法名:
from sklearn.metrics import SCORERS
for i in SCORERS.keys():
print(i)- 1
- 2
- 3
从下一节开始,我们将进行sklearn机器学习算法的源码解读。
题外话:上面的ABCMeta是python中实现抽象类和接口机制的一个模块,ABC是Abstract Base Class的简写,由于python自身不提供抽象类和接口机制,因此需要借助它来实现。详情请自行百度。















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









