







服务雪崩
服务雪崩效应是一种因“服务提供者的不可用”(原因)导致“服务调用者不可用”(结果),并将不可用逐渐放大的现象
如下图: 一个服务失败,导致整条链路的服务都失败的情形,我们称之为服务雪崩
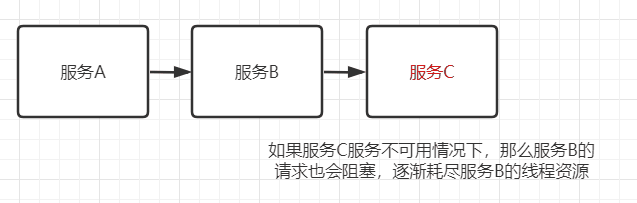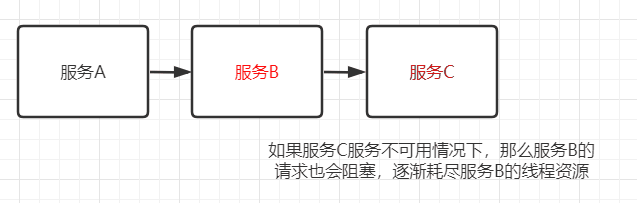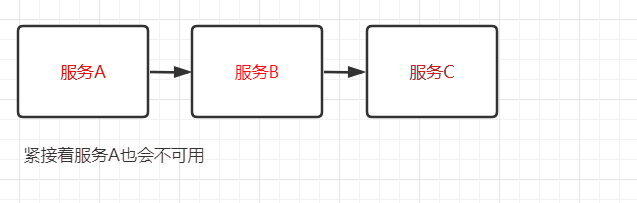
我把服务雪崩的参与者简化为 服务提供者 和 服务调用者,并将服务雪崩产生的过程分为以下三个阶段来分析形成的原因:
- 服务提供者不可用
- 重试加大流量
- 服务调用者不可用
服务雪崩的每个阶段都可能由不同的原因造成,比如造成 服务不可用 的原因有:
- 硬件故障
- 程序 Bug
- 缓存击穿
- 用户大量请求
硬件故障可能为硬件损坏造成的服务器主机宕机,网络硬件故障造成的服务提供者的不可访问。
缓存击穿一般发生在缓存应用重启,所有缓存被清空时,以及短时间内大量缓存失效时。大量的缓存不命中,使请求直击后端,造成服务提供者超负荷运行,引起服务不可用。
在秒杀和大促开始前,如果准备不充分,用户发起大量请求也会造成服务提供者的不可用。
而形成 重试加大流量 的原因有:
- 用户重试
- 代码逻辑重试
在服务提供者不可用后,用户由于忍受不了界面上长时间的等待,而不断刷新页面甚至提交表单。
服务调用端的会存在大量服务异常后的重试逻辑。
这些重试都会进一步加大请求流量。
最后, 服务调用者不可用 产生的主要原因是:
- 同步等待造成的资源耗尽
当服务调用者使用 同步调用 时,会产生大量的等待线程占用系统资源。一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态,于是服务雪崩效应产生了。
应对策略
针对造成服务雪崩的不同原因,可以使用不同的应对策略:
流量控制
- 网关限流
- 用户交互限流
- 关闭重试
因为 Nginx 的高性能,目前一线互联网公司大量采用 Nginx+Lua 的网关进行流量控制,由此而来的 OpenResty 也越来越热门。
用户交互限流的具体措施有: 1. 采用加载动画,提高用户的忍耐等待时间。2. 提交按钮添加强制等待时间机制。
改进缓存模式
- 缓存预加载
- 同步改为异步刷新
服务自动扩容
- AWS 的 auto scaling
服务调用者降级服务
- 资源隔离
- 对依赖服务进行分类
- 不可用服务的调用快速失败
资源隔离主要是对调用服务的线程池进行隔离。
我们根据具体业务,将依赖服务分为: 强依赖和若依赖。强依赖服务不可用会导致当前业务中止,而弱依赖服务的不可用不会导致当前业务的中止。
不可用服务的调用快速失败一般通过 超时机制, 熔断器 和熔断后的 降级方法 来实现。














 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









