






第一次在CSDN发博客,望有什么错误的话,希望各位大牛指出
- 关于scikit-learn可以处理的文本类型
通过参考网站的内容是直接建立一维列表,列表中的内容都是已经被分好词的字符串,每一行的字符串称作相应行的 第几类文本,如
中文效果就是:corpus=["我 来到 北京 清华大学", #第一类文本切词后的结果,词之间以空格隔开"他 来到 了 网易 杭研 大厦", #第二类文本的切词结果"小明 硕士 毕业 与 中国 科学院", #第三类文本的切词结果"我 爱 北京 天安门"] #第四类文本的切词结果
之所以是这样,我认为是因为计算词频时它识别的词的分隔符就是一个 空格,正因如此,我们利用jieba要做的事情就是要产生这样的文件(用空格来分词)(小常识,用python的readlines()在读入文件时是根据换行符来自动产生一个字符串列表中的下一个元素的) scikit-learn是可以对中文词完成算TFIDF的,但他只是无法完成对中文的分词而已(scikit-learn内置的分词器并不支持中文)(不像英文,英文每个单词之间都是用空格分隔的)但我发现sklearn还有一个不知道是好事还是坏事的功能,他会自动过滤掉单个字的词,例如爱,我……
corpus:语料库,一般都是这样定义列表但因为我们都知道 jieba.cut()返回的结果是迭代器对象,要产生上述结果的最好方法就是用for循环输出到文本文档中(要达到同一个文本的词之间有空格分隔,下一个文本要换行),再读入进来
- CountVectorizer类
- fit_transform( )函数获得词频矩阵
fit_transform函数的参数是jieba库返回的一维矩阵,里面的元素都是字符串如:假设这个类实例化为vectorizer(矢量化)result = vectorizer.fit_transform(corpus)
- get_feature_names( )在你运行了 fit_transform处理了一个corpus后,词袋模型就会被构建了出来,而这个方法,就是返回词袋模型(一维字符串列表类型,参见附件图1)(词袋模型假定对于你给定的语料corpus,忽略其词序和语法,句法,将其仅仅看做是一个词集合,例如第一类文本是"我 来自 中国",而第二行是 "我 爱 广州",则词带模型就是 我 中国 爱 广州 来自 所以,他在输出词频矩阵时,是基于词袋模型的,就是它会认为当前类文本包含 总类的所有文本词 下 的词频,所以肯定有一些是0的,而且这样做同时也保证了词频矩阵每行的长度的相等性,不会因为第一类文本只有3个词,第二类6个词,然后输出的矩阵将非常奇怪 这种组合我是在***处的链接看到的),此时你可以通过这个方法可看到所有文本的关键字
word=vectorizer.get_feature_names()
- toarray( ) 返回词频矩阵(array类型),元素a[i][j]表示 j 词在 i 类文本中的tf-idf权重,代码用例
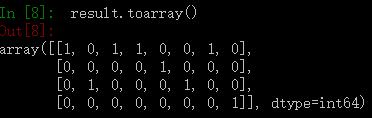
tfMat = result.toarray()(输出样子参见附件图2,始终要记得,词频和只和当前类文本有关)但不知道你有没有发现,你完全不知道这个位置的数值是对应该类(行)文本的哪个(列)词,此时你要清楚,因为词频是基于词袋模型来输出的,所以你想搞清楚对应关系,就先输出词袋模型的样子,就知道对应关系了。例如通过附件图1来对照观看附件图2
- TfidfTransformer类
- fit_transform( ) 来计算TF-IDF权重值
fit_transform的参数就是 上面的CountVectorizer类用fit_transform返回的结果如:假设TfidfTransformer类实例化为transformer(变换器)tfidf=transformer.fit_transform(result)
- toarray( ) 返回tf-idf矩阵(array类型),元素a[i][j]表示 j 词在 i 类文本中的tf-idf权重,代码用例
weight=tfidf.toarray()
- 导入CountVectorizer类和TfidfTransformer类的方式是
from sklearn.feature_extraction.text import CountVectorizerfrom sklearn.feature_extraction.text import TfidfTransformer
注:(因为CountVectorizer是一个类所以在调用它的方法fit_transform前要先实例化,即vectorizer =CountVectorizer())
附件图:
1.(一维List)

2.(二维Array)















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









