






作者:子矜
审核&校对:风云、雨芙
编辑&排版:雯燕
客户的故事
全链路压测被誉为大促备战的 “核武器” ,如果之前有关注过阿里双 11 相关的技术总结,对 “全链路压测” 一定不会陌生,这个词的出场率几乎 100%。从对双 11 稳定性的价值来看,用 “核武器” 来形容全链路压测毫不为过。
在某知名电商大促中,该电商平台也想用全链路压测来为自己的大促提前排除风险。但是他遇到几个困难:
-
全链路压测是一个需要多角色参与的活动:业务方,测试,运维,研发,数据库,都需要参与进来。然而能够像阿里具备成熟的组织体系,可以强有力的推动各种不同的角色,都是需要较长时间来积累的。
-
全链路压测,常常涉及到框架的改造:而该电商平台的业务复杂,做结构梳理与业务改造并不现实。
那这个知名电商平台,有什么办法可以在 1 个星期之内,不进行业务改造,不改变业务部署,就能够用上全链路压测呢?
接下来的内容,我们会从全链路压测的原理开始,并引入基于同样原理的 “敏捷版” 全链路压测,让该知名电商平台能够在 2 周之内就能用上全链路压测的方案。
全链路压测
首先,我们来看看阿里的全链路压测,到底解决了什么问题:
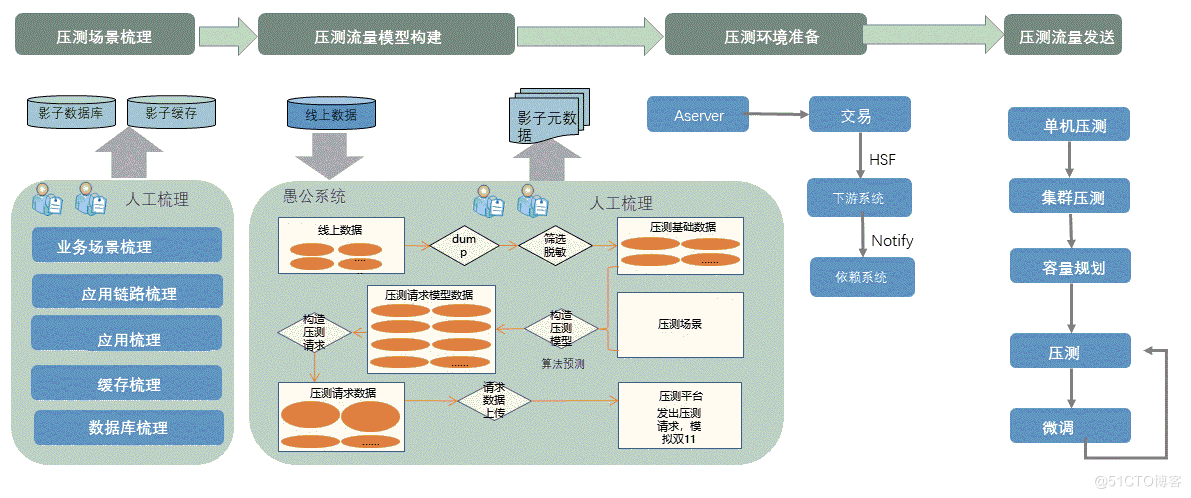
全链路压测实际上解决的问题是:在线上的压测。线上压测,能够最快、最直接的发现线上的问题。然而,线上压测会带来数据污染的问题:如何把压测数据和真实数据区分开来,是压测里至关重要的一点。那么,阿里是怎么做的呢?我们一起来看下图:
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MwAikMee-1637330839944)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/d0ba1e503e514fb2bb35e96bffed5fa0~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MwAikMee-1637330839944)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/d0ba1e503e514fb2bb35e96bffed5fa0~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
阿里的全链路压测具有一套成熟又复杂的系统:压测的梳理、构建、准备、发送。然而,这套体系对于一个云上的用户是需要长期建设得到的。那我们如何能够让用户快速,敏捷的享受这套技术呢?
在这里,PTS 把整个流程进行沉淀,都以标准化的输出来提供给云上的用户。用户可以直接享用一整套的全链路压测体系,也可以在压测的关键环节:例如场景梳理、请求构建、压测环境、压测等步骤中,根据自己的需求来定制自己想要的压测效果。
场景梳理
业务场景,即对应的是压测的输入请求。这是压测第一步,也是最重要的一步。最常见的是把涉及到业务的 URL 进行梳理,汇总。例如下图就是一个常见的场景汇总:

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oB9ZRRvo-1637330839949)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/0a05d3c322b846239decf751f07baea2~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
然而,这是不够的。当若干个 URL 汇总成一个场景之后,URL 之间的比例、时间间隔,也是影响业务场景的关键。用常见的场景打一个比方:一个用户的下单,可能背后蕴含着 10 个用户登录,每个用户平均浏览了 4 个商品,每个商品中平均被浏览了 5 个评价,最后一个用户在 10 点大促开始的时候,购买了一个商品。
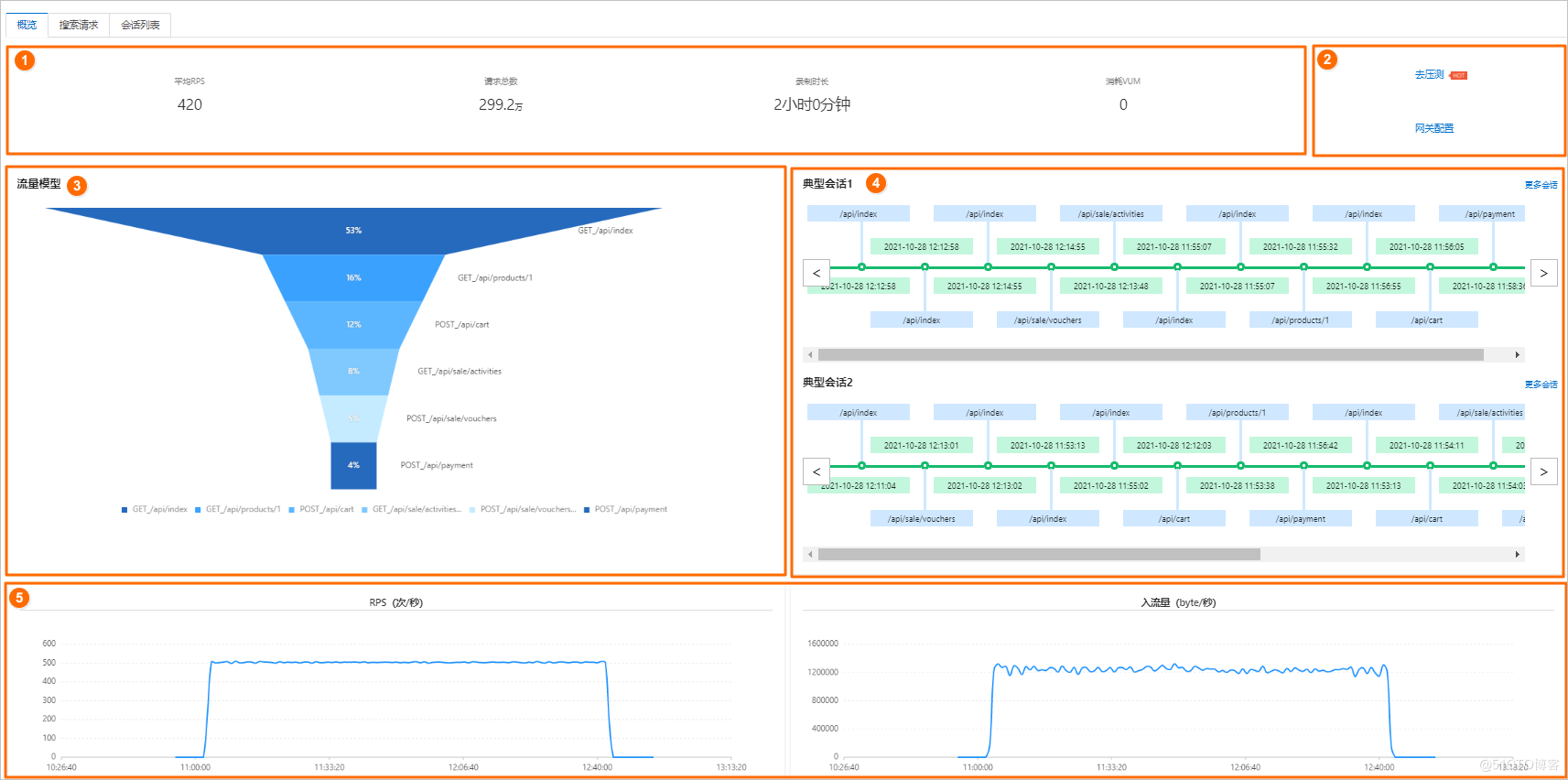
这些 URL 之间的关系、时间点,需要人员有丰富的业务知识才能梳理清楚。为此,PTS 提供服务端流量录制的功能,方便用户来录制流量,并且轻松的得到其中不同维度的比例关系:
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zvCTPmun-1637330839950)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/84f64ef951df411ba72f111b9cf706b5~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zvCTPmun-1637330839950)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/84f64ef951df411ba72f111b9cf706b5~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
如上图所示,用户可以清晰的得到 URL 之间的比例关系、用户 URL 之间的时间行为等等。基于这个梳理好的数据模型,用户可以在这个基础上进行裁剪。
测试数据构造
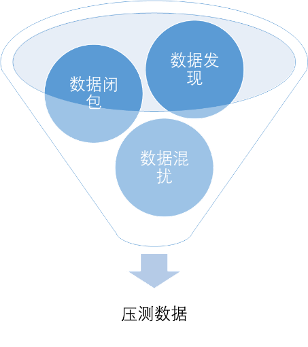
接下来,就是构造用户数据了。这一步涉及的角色最多,也最为繁琐。整个数据构造由三个步骤构成,如下图所示:
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bVaSKT0r-1637330839953)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/641e91b4b211475680222ea3cfb25247~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bVaSKT0r-1637330839953)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/641e91b4b211475680222ea3cfb25247~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
首先是数据发现。通常,我们可以通过人工业务梳理,得到该业务所涉及到的所有表,并进行分析。PTS 为免除这个烦恼,和DMS打通,提供表结构预览,让测试人员方便的看清楚和场景相关联的结构,大大的提升效率。
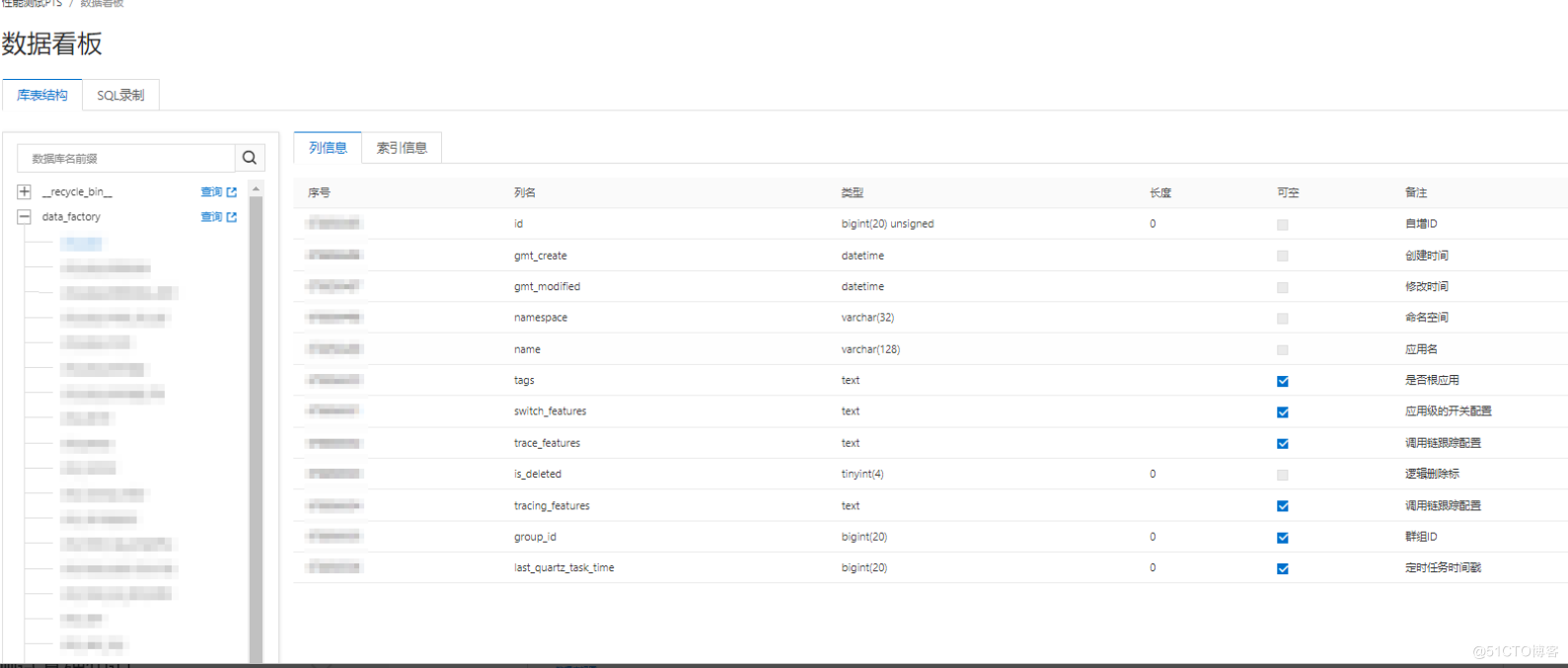
如果还是觉得太复杂,PTS将提供数据录制工具,安装了这个 agent 之后,该业务所涉及的表,都会被完整的记录下来:
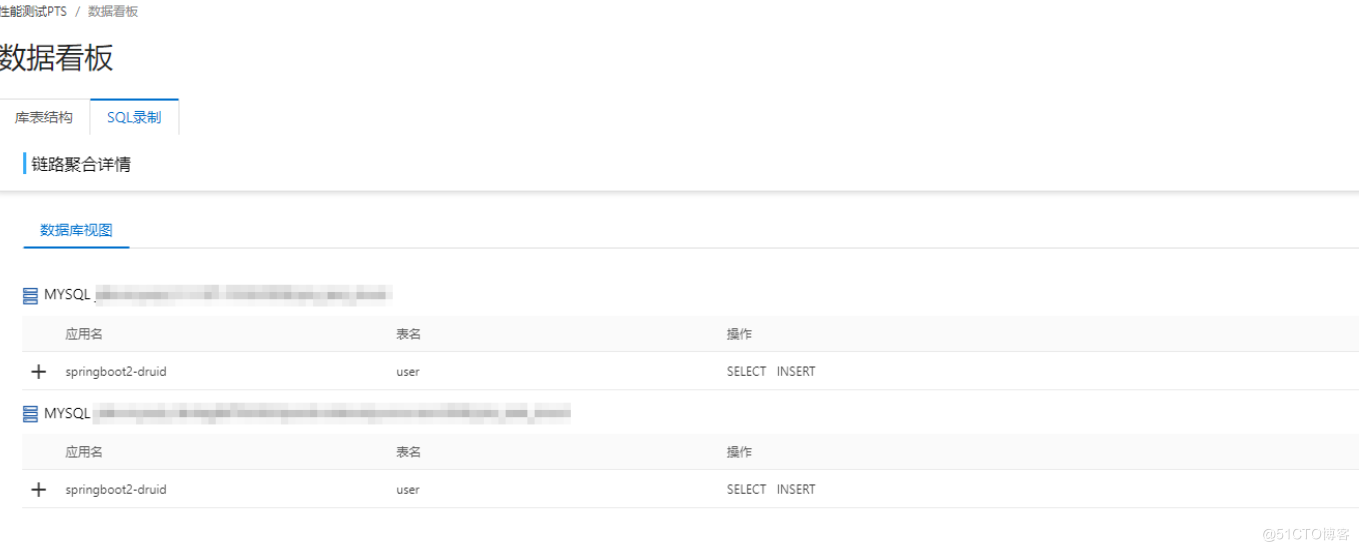
有了这些工具,测试人员就可以无须 DBA 的协助,轻松的得到场景关联的表信息了。
数据闭包
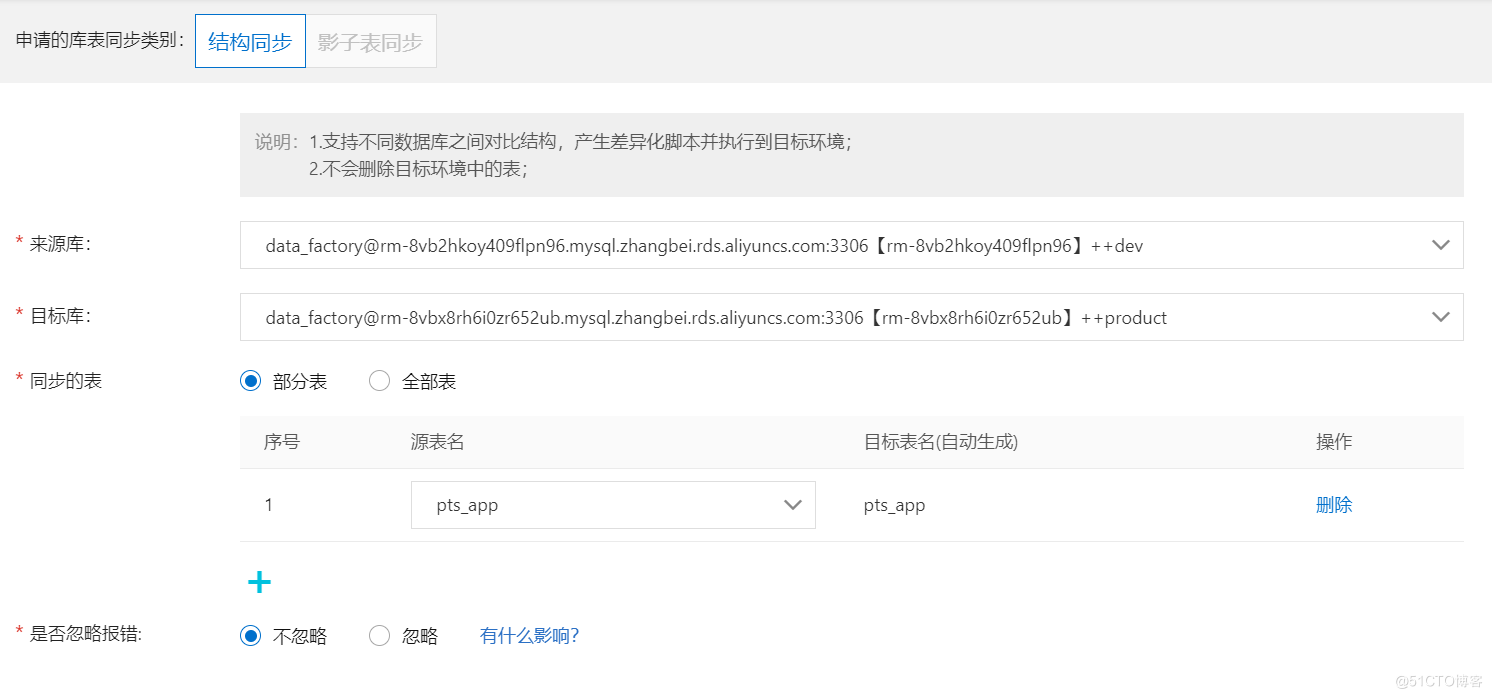
有了这些数据表,并且在这基础之上分析出来数据闭包后,我们可以开始制作压测数据了。通常,我们制作影子表的方式有三种:
-
影子库 – 全量的进行影子库映射。该方法的优势是简单,劣势是消耗资源多;
-
影子表 – 将表闭包里的表,通过一定规则,进行名字关联。该方法的优势是节省资源,劣势是需要对表进行充分梳理,并且一一对应;
-
不新建表,在同一张表内,将影子数据进行大位移偏移。这个将在后面的敏捷版内进行介绍。
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8JE07v8u-1637330839955)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/2522f543ff0442caa5533d4e88a4b884~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8JE07v8u-1637330839955)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/2522f543ff0442caa5533d4e88a4b884~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
这三种方式可以根据需求组合使用。
数据导入/混扰
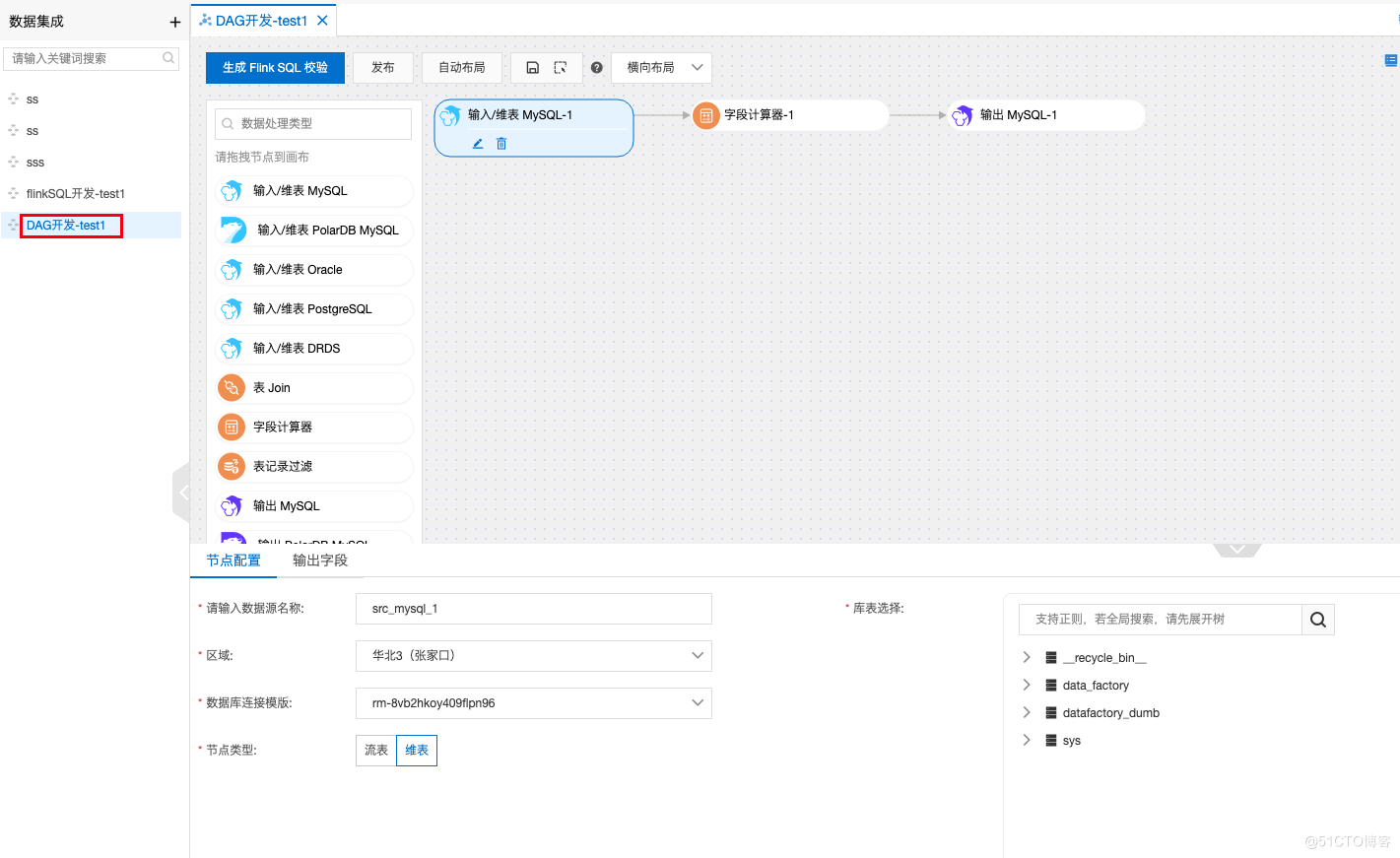
有了这些前提之后,我们可以利用 DMS 来数据导入,进行数据制作了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8MD6jBoP-1637330839956)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/0c3d4c73a2394058b11ec0678c475f8f~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
到这里,我们完成了全链路压测中最复杂的两个步骤:压测场景梳理、压测数据制作。
接下来我们通过数据加工,把这两个元素最终加工为压测数据。
数据加工
此时,我们对压测数据做最后一个步骤,进行数据加工。即我们把业务场景、压测数据,按照我们的业务模型进行最后的调整与加工:
到这里,我们可以看到,全链路压测的压测请求,都已经成型了。接下来,我们可以开始设计压测流量在压测对象中的行为了。
测试环境
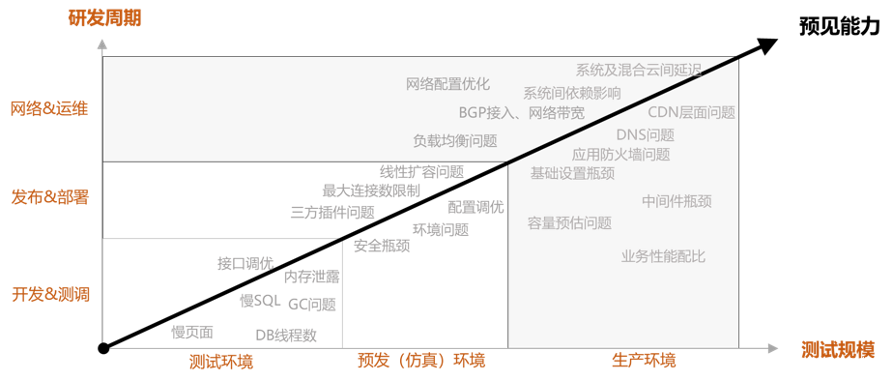
压测可以在仿真环境、线上环境中进行。不同的环境,选取数据,制造数据都有不同的考量。如下图所示:
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I8CI5bZH-1637330839957)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/35cd0e7b0fd54d4f9003dae3ee82d133~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I8CI5bZH-1637330839957)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/35cd0e7b0fd54d4f9003dae3ee82d133~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
简单的说,测试环境关注的是单个组件:例如微服务、接口、但协议(SQL,Redis)等压测;预发环境(通常是VPC环境)则关注链路整合;生产环境则最逼近真实场景。在这里,我们只讨论线上生产环境。
传统全链路压测
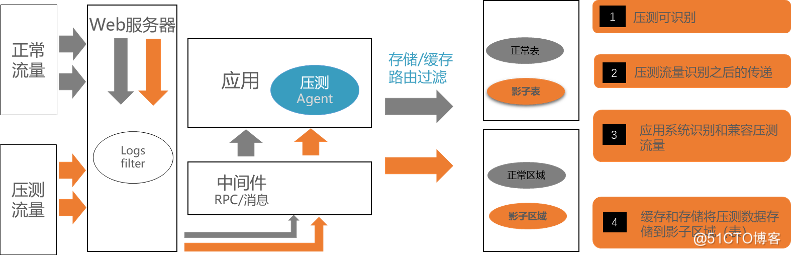
下图简单的诠释了传统全链路压测的运作方式;
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4rweA6K8-1637330839957)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/47f78c130b064e3b949266d20bf0be5b~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4rweA6K8-1637330839957)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/47f78c130b064e3b949266d20bf0be5b~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
我们看到,传统的全链路压测,主要通过流量打标,来区分压测流量和真实流量,做到这一点,需要保证这个压测标能够被层层的透传下去。而当流量到了 “写” 的这层,部署好的 agent 根据压测标,来决定 “写” 的行为,是写到真实的数据库呢?还是写到影子区域?道理很简单,但是实施的时候还是会碰到不少的难点。其中,主要涉及的问题是:
-
如果应用使用到的框架不标准,则需要进行适配;
-
推动开发安装 agent 的流程复杂;
-
验证 agent 的覆盖面复杂。
敏捷版的全链路压测
如果我们不想要改造业务,也不想要挂载 agent,我们能如何去做到这一点呢?
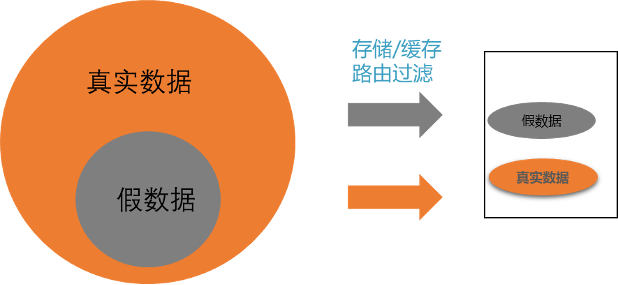
我们来看一下抽样测试的原理。在测试的时候,通常有一种手段,即通过选取几个特定的真实用户数据来进行测试,来验证程序的正确性;如果我们把这些真实用户数据,变成假用户,那么需要满足下面这个关键条件:假用户以及假用户在这个业务场景下涉及到的业务数据,以及业务场景下相关的数据,都能够被识别出来。
例如,我们模拟一个假用户,购买某个假商品,这里的用户,商品,都能够有一个特定的特征,这个假用户生成的浏览记录、购买记录,在数据库的表现中都有该用户的 ID;在这个前提下,我们是能够把脏数据从真实数据中识别出来的;
这种压测,需要盘点出以下两点:
-
完整的找出业务涉及到的数据表 – 参考上一章节里面的PTS SQL录制功能;
-
制作影子数据 – 和传统全链路压测不一样,这里我们选取的是第三种方式,即在一张表里做大位移,而不是制作影子表或者影子库。压测结束后,根据影子数据的特征,巡检数据库并且进行清理;
这种方式,是基于使用者对业务有清晰的了解,制作出来的压测数据有明显的压测标识(比正常数据大的多的偏移量),所有涉及的写压测,都带有这些偏移量;这样,所有压测产生的数据,都能够被识别出来。压测结束之后,根据这个数据特征,来清理压测数据;
流量引擎的选择
为了更好的模拟用户的行为,我们常常会使用压测地域的定制。但是把压测引擎部署到全国各地是不现实的;而PTS 可以方便的让用户选择地域的发起,如下图所示:
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vBjrIRYa-1637330839959)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/68e2be120d84431ea2b4549b4d9c3568~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vBjrIRYa-1637330839959)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/68e2be120d84431ea2b4549b4d9c3568~tplv-k3u1fbpfcp-zoom-1.image “图片”)]
总结
PTS 结合 10 多年来阿里的全链路压测的经验,让阿里云的用户可以如同享用满汉全席般的享用全套标准的全链路压测,也可以根据自己的需求,选择最适合自己的方式。
另外,PTS 最近价格上也做了 “敏捷” 优化,更多的选择,点击此处即可查看~
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









