






作者:寒斜
目前,声音的推理和合成在很多领域都有广泛的应用,比如儿童/成人教育、疗愈/陪伴、销售/客服、游戏 NPC、车载通信,工/农业线下辅助等。CosyVoice 是一款优秀的语音合成模型,支持语音合成、情感控制、多语言语音合成等诸多功能,效果体验极佳。然而,对于很多普通用户和应用开发者而言,托管其专属模型,进行使用或者应用开发比较困难,今天分享一下,基于阿里云函数计算 FC 以及 CAP(云应用开发平台),极速托管专属的 CosyVoice 应用。并且我们提供了 API 调用方案以及镜像构建源码方便您根据自己的业务任意 DIY。
CosyVoice 部署托管
Step1 访问阿里云函数计算控制台 [ 1] ,打开应用中心
选择 CosyVoice 智能语音应用模板,进行部署。
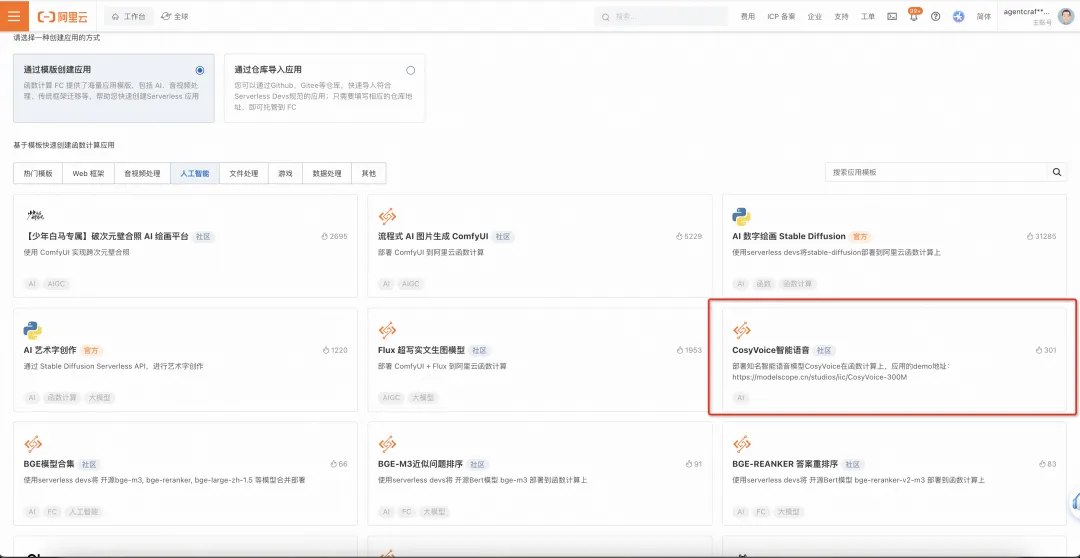
Step2 根据应用配置引导填写,点击“创建应用”
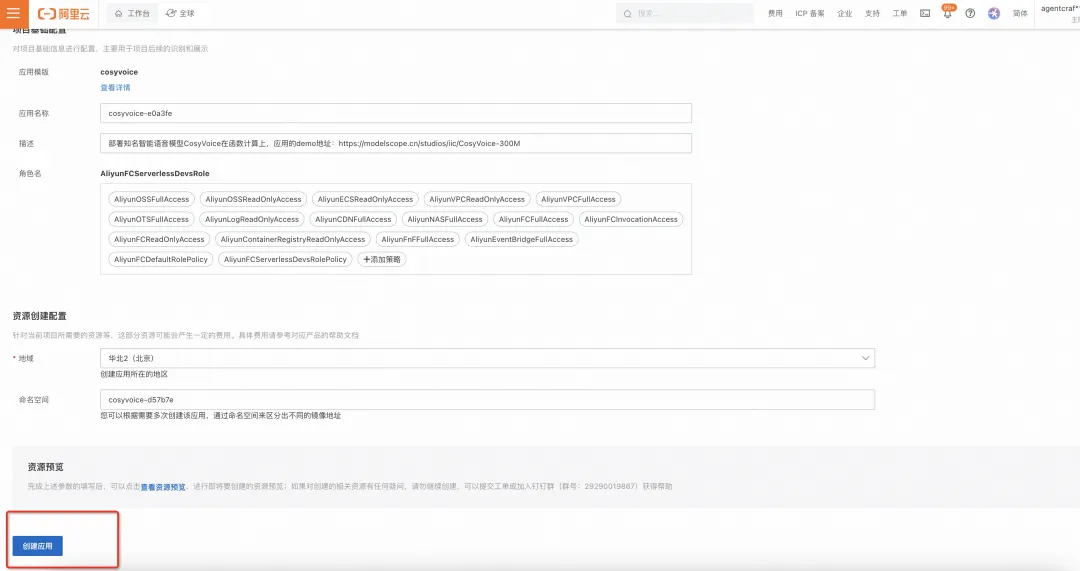
Step3 产品依赖确认,部署详细
点击后进行部署。
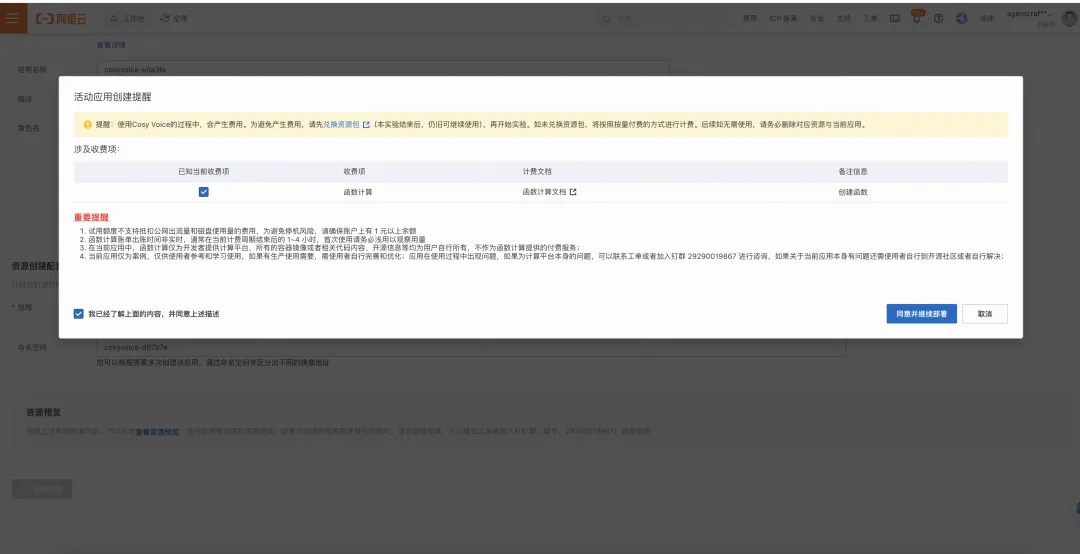
进入部署。
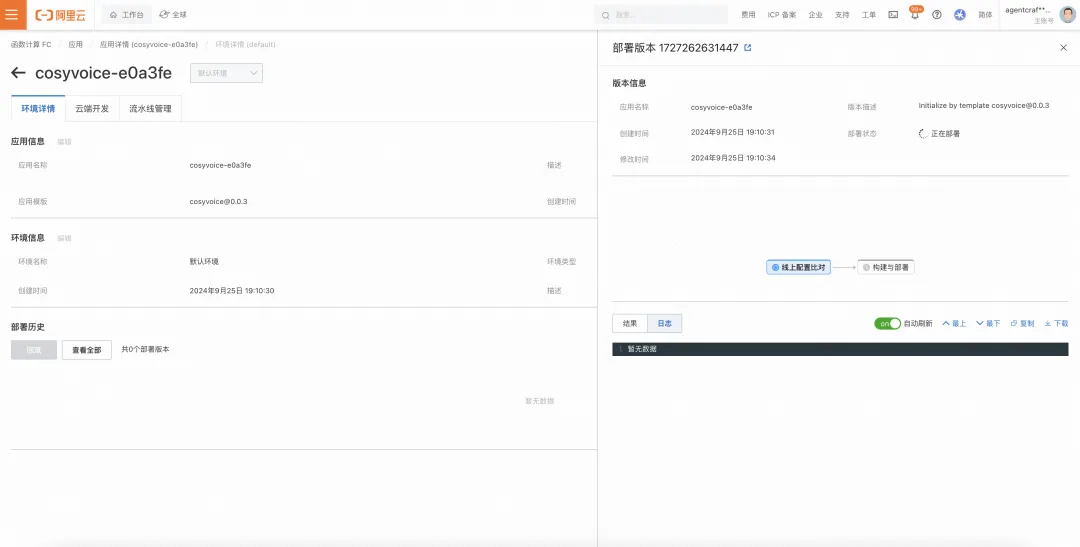
Step4 访问 web 界面
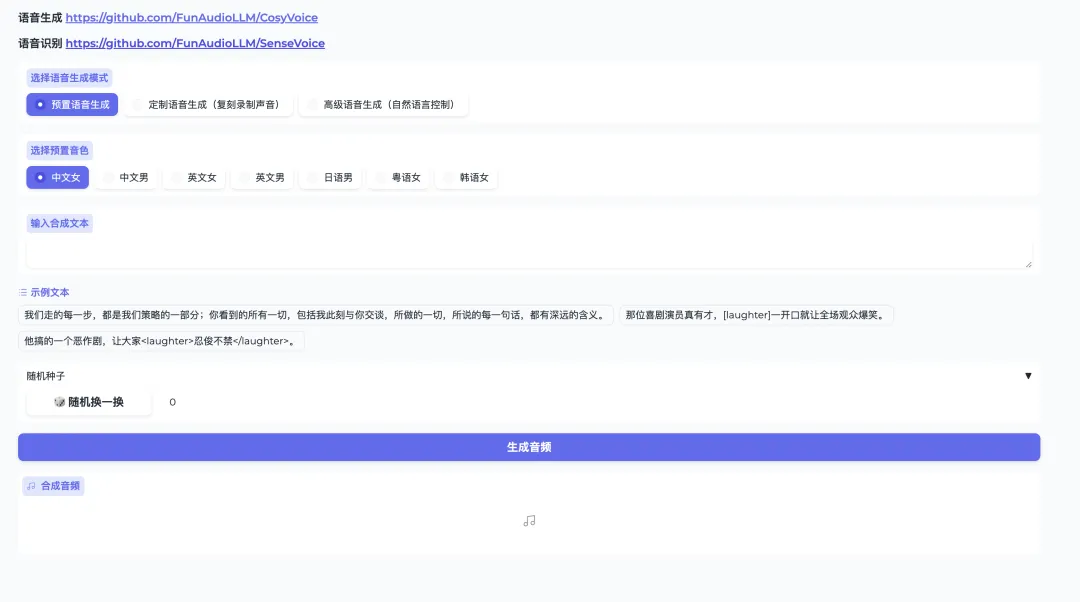
您可以直接在线体验预置语音生成、定制语音生成、高级语音生成三个模块。
API 调用
获取 EndPoint
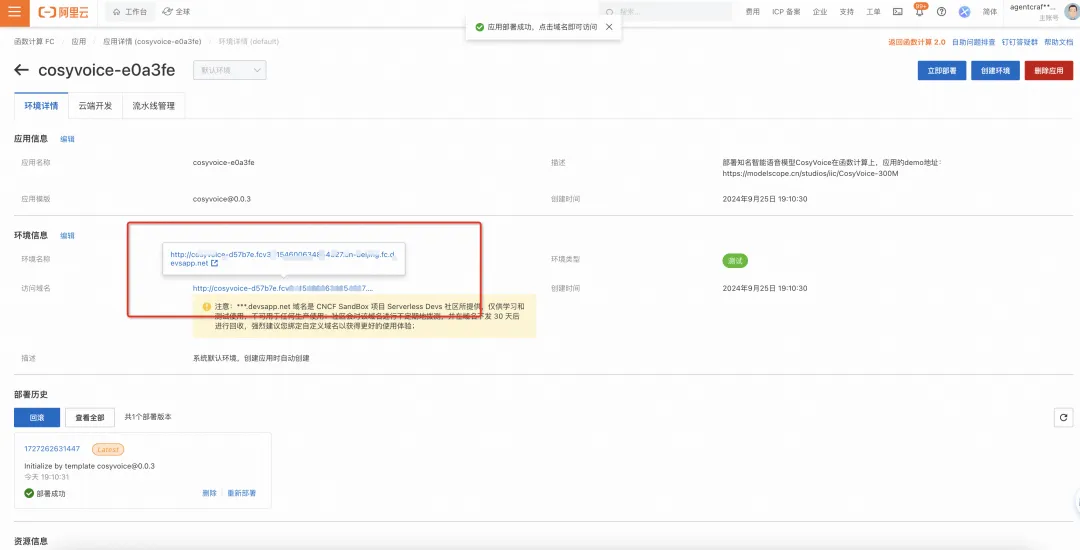
CosyVoice 部署完毕之后,可以进行 API 调用。首先是需要获取 API 的 endpoint,这里有两个地址。
临时域名地址(30 天访问期)

Http 触发器地址(永久地址)
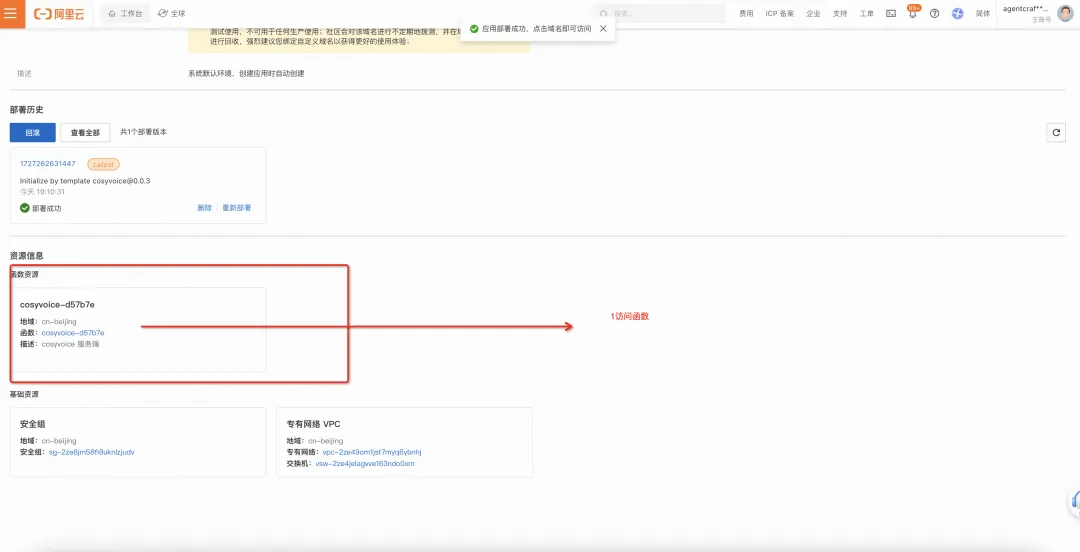
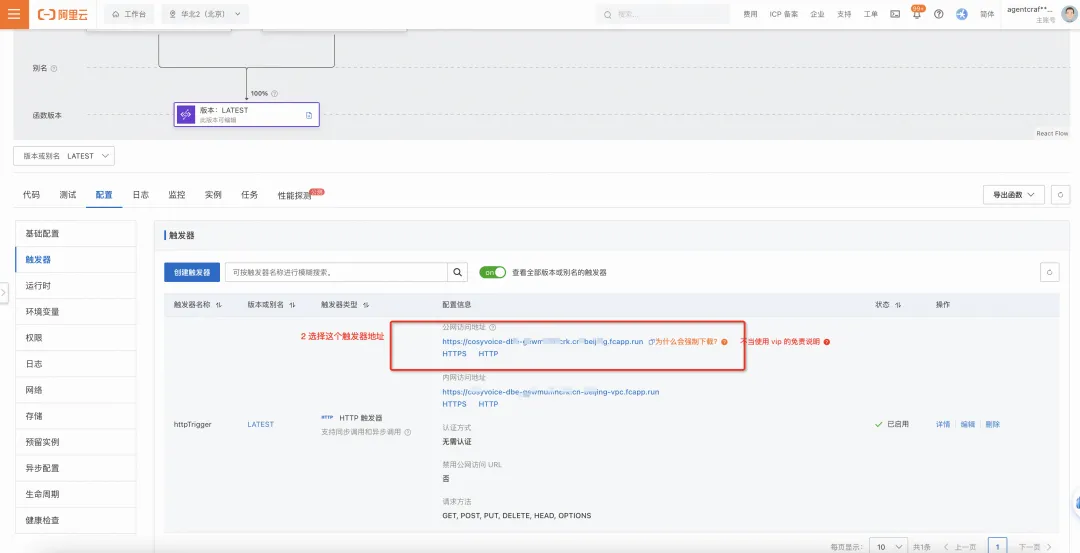
(注: http 触发器地址因安全限制直接访问无法看到 web 页面,但是可以通过 http 访问 api。)
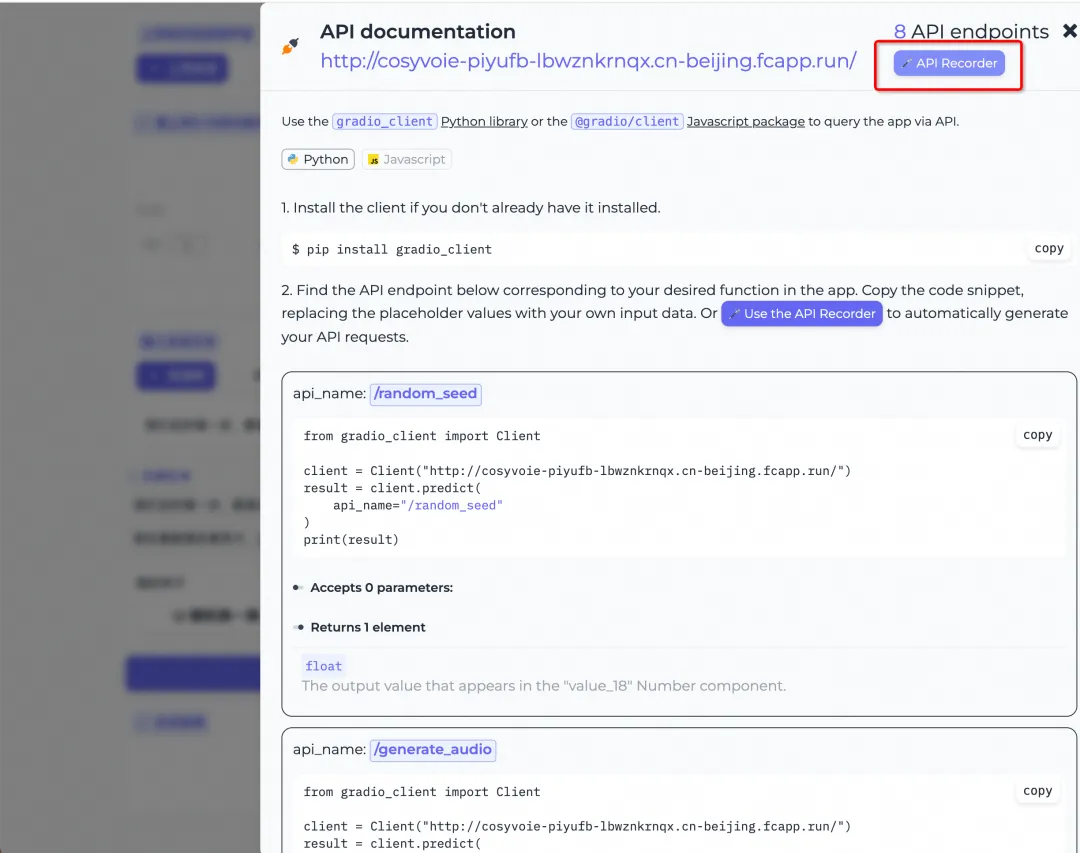
使用 API Recorder 调试
通过 API Recorder,仅需点击 Web UI 页面即可获取访问 API 的相关代码示例,非常方便。下面演示一下如何使用 API Recorder 进行 API 获取。
Step1 打开 API Recorder
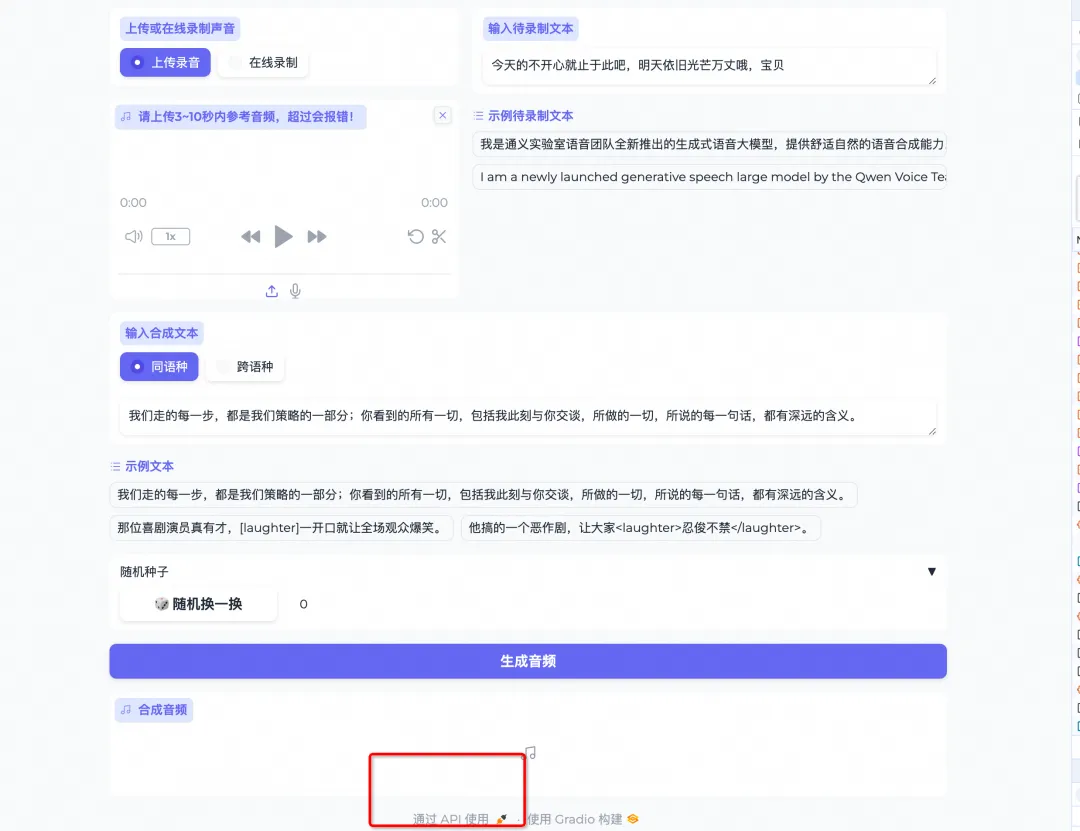
Step2 回到 Web UI 进行语音合成访问(上传声音文件,点击生成音频)
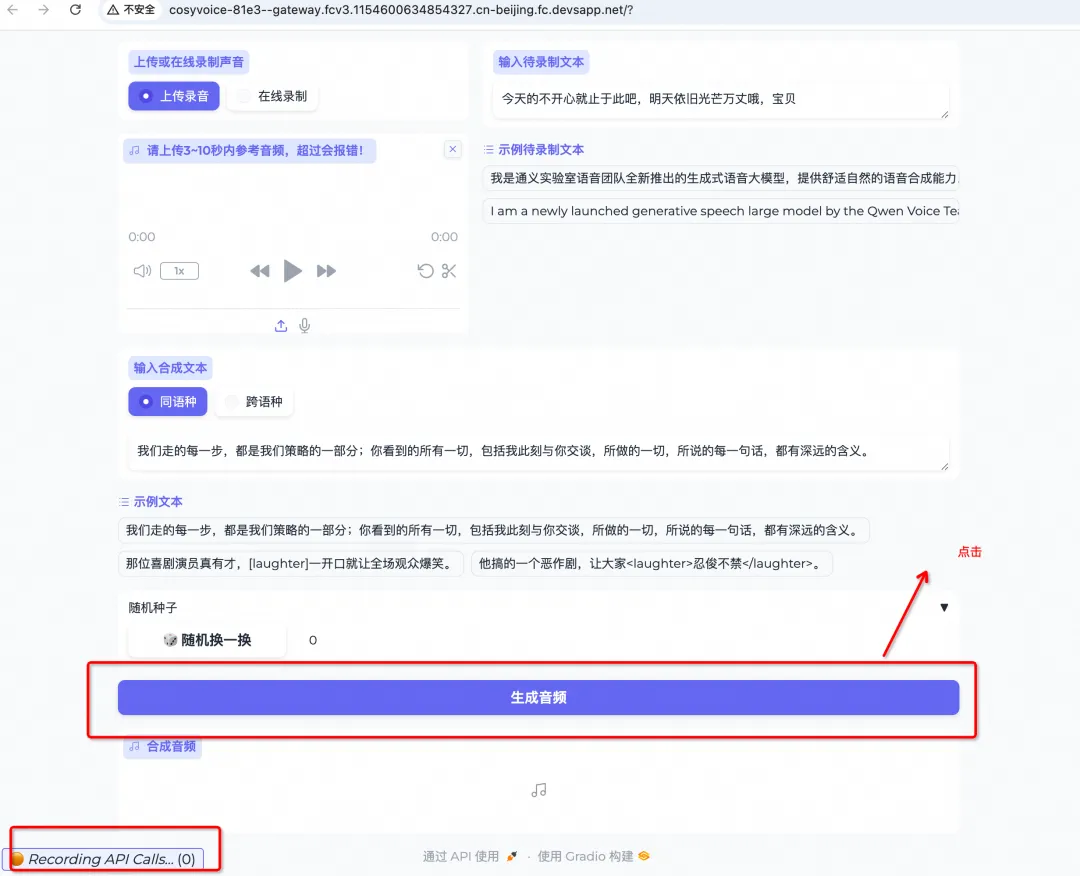
Step3 查看调用记录和生成的 API 示例代码


本地调试代码
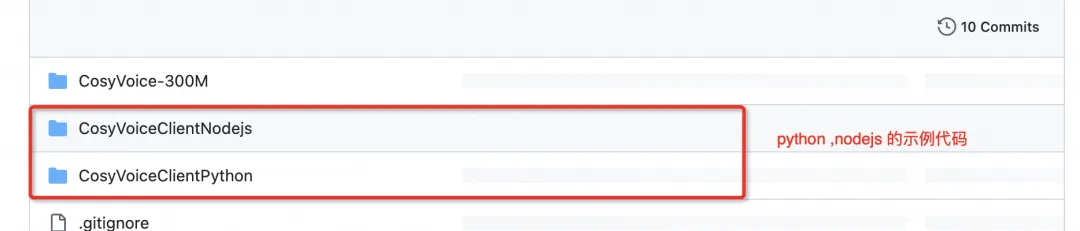
以上生成的代码可以直接在本地安装调试,为了进一步方便实用,下面提供示例代码,完整的代码获取 [ 2] 。
声音推理
声音推理较为简单,复制以下代码(需要安装 gradio_client),修改 cosyvoice_endpoint 地址即可。
from gradio_client import Client
import os
import shutil
cosyvoice_endpoint = "<endpoint>"
client = Client(cosyvoice_endpoint)
result = client.predict(
_sound_radio="中文女",
_synthetic_input_textbox="天天好心情,我们走的每一步,都是我们策略的一部分;你看到的所有一切,包括我此刻与你交谈,所做的一切,所说的每一句话,都有深远的含义。",
_seed=0,
api_name="/generate_audio"
)
# result 是返回的本地音频地址
# 把result 保存到当前的目录下
audio_filename = "preset.mp3"
shutil.copy(result, audio_filename)
# 删除原始的 音频
os.remove(result)
语音合成
新建 custom.py 文件,并复制这段代码(需要安装 gradio_client)。
import os
import shutil
from gradio_client import Client, file
cosyvoice_endpoint = "endpoint"
uploaded_voice_path = ""
client = Client(cosyvoice_endpoint)
result = client.predict(
_recorded_audio1=file(f"{cap_cosyvoice_endpoint}file={uploaded_voice_path}"),
_recorded_audio2=None,
_prompt_input_textbox="今天的不开心就止于此吧,明天依旧光芒万丈哦",
_language_radio="same",
_synthetic_input_textbox="来来来,我们走的每一步,都是我们策略的一部分;你看到的所有一切,包括我此刻与你交谈,所做的一切,所说的每一句话,都有深远的含义。",
_seed=0,
_audio_input_type_radio="upload_audio",
api_name="/generate_audio_1"
)
print(result)
# result 是返回的本地音频地址
# 把result 保存到当前的目录下
audio_filename = "custom.mp3"
shutil.copy(result, audio_filename)
# 删除原始的 音频
os.remove(result)
高级情感Å
from gradio_client import Client
client = Client("<endpoint>")
result = client.predict(
_sound_radio="中文女",
_synthetic_input_textbox="Hello!!",
_seed=0,
api_name="/generate_audio"
)
print(result)
补充
对于声音推理,由于 Serverless 实例会轮转(比如无调用实例会被释放),无法持久化存储被合成的语音,所以如果您希望持久化存储所合成的语音,使其能够提供长期的 API 服务,需要增加阿里云文件存储产品 NAS 存储解决,函数计算挂载 NAS 非常简单,如下示例。
挂载 NAS
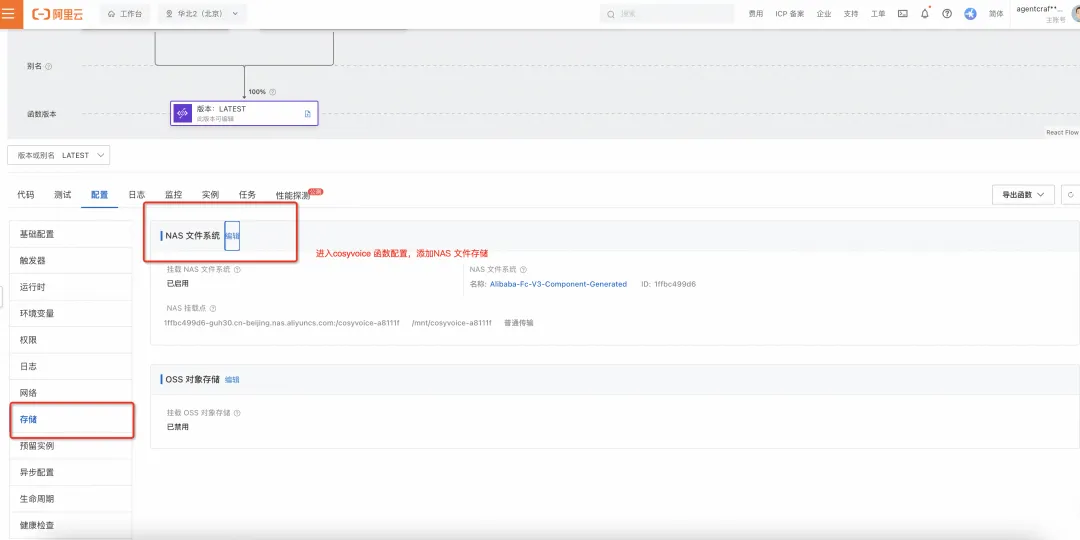
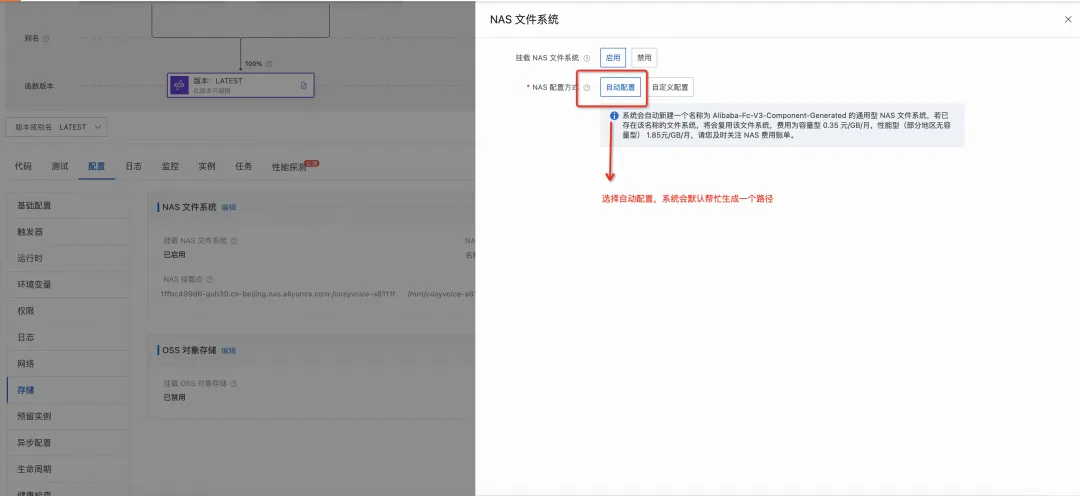
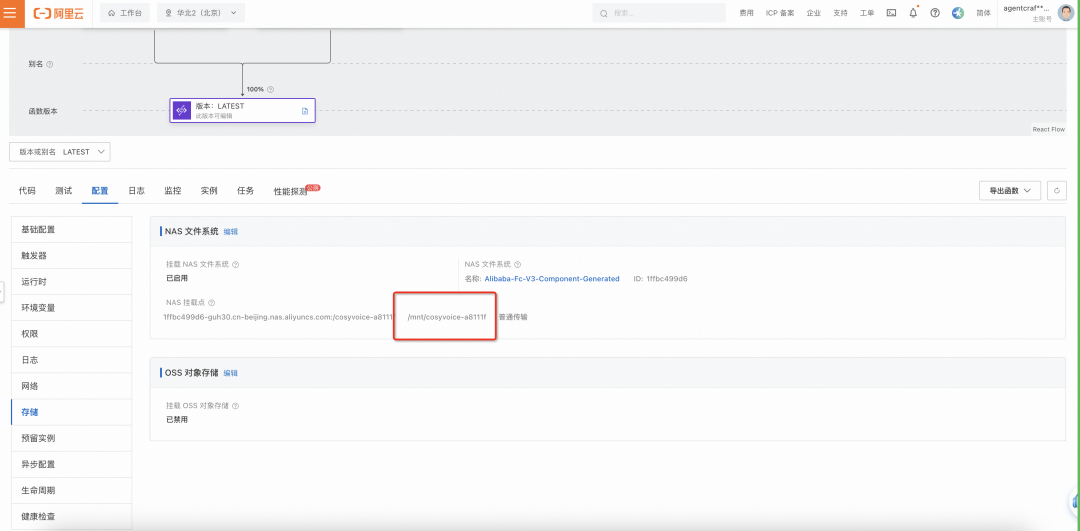
配置好之后获取 NAS 文件路径。
配置 CosyVoice 文件存储环境变量
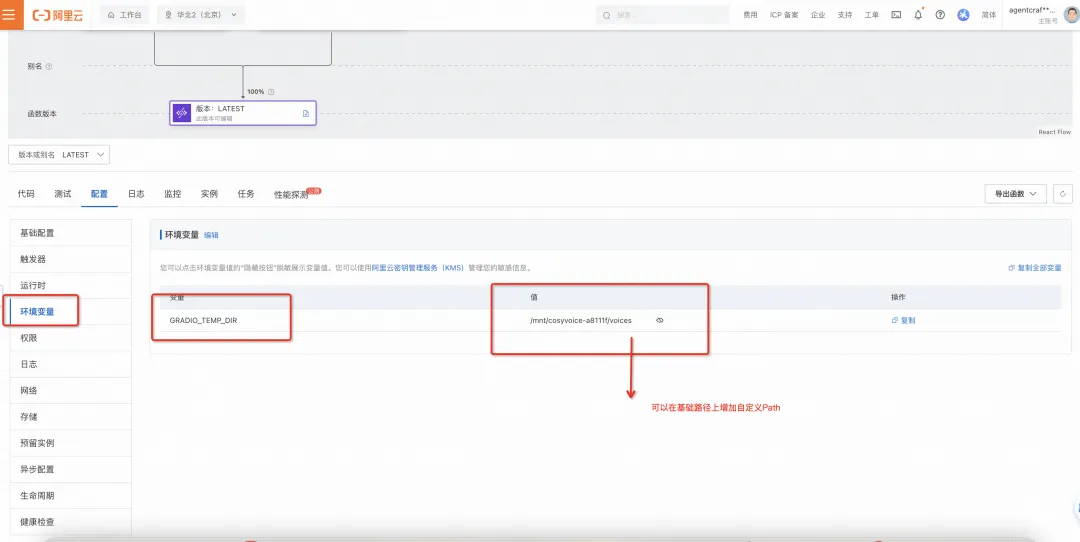
之后重新使用 API Recorder 录制语音合成 API ,会发现 上传录制文件后的视频地址已经固定为 NAS 的地址了,接下来您便可以长久使用这个合成的声音了。

如何更新 CozyVoice 以及如何对后端服务修改定制
函数计算 CosyVoice 应用模版同步社区的更新存在滞后性,如果您希望体验社区最新的模型效果,本方案提供了 CozyVoice 构建的完整代码 [ 3] ,支持您进行更新。
您可以更新代码工程,重新构建新的 Docker 镜像,将 Docker 镜像上传至阿里云容器镜像服务 ACR 服务。
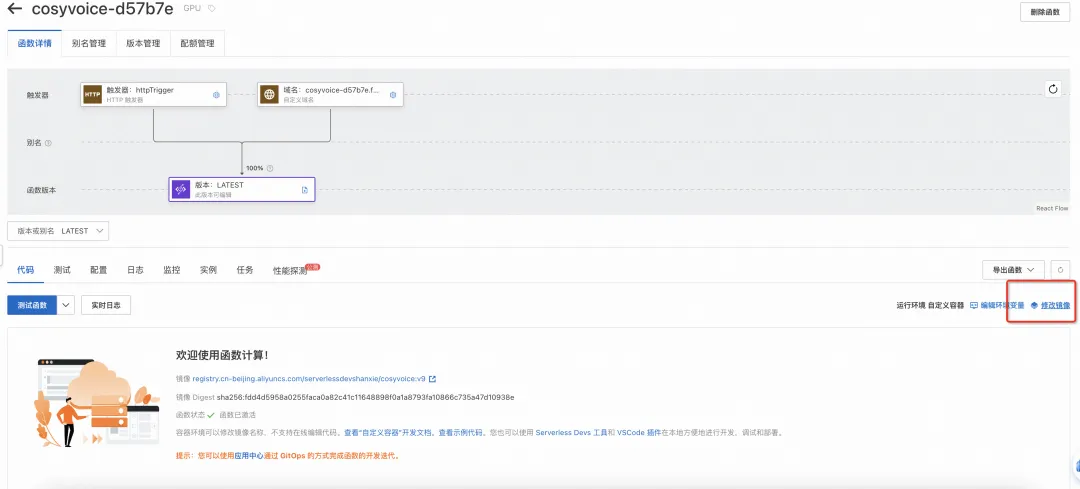
然后修改函数计算上的镜像配置即可。

注意,上述源码的 CosyVoice-300M 工程中不包含模型, 需要先将对应的模型下载到本地,然后构建镜像。
cd CozyVoice-300M
mkdir -p pretrained_models
git clone https://www.modelscope.cn/iic/CosyVoice-300M.git pretrained_models/CosyVoice-300M
git clone https://www.modelscope.cn/iic/CosyVoice-300M-SFT.git pretrained_models/CosyVoice-300M-SFT
git clone https://www.modelscope.cn/iic/CosyVoice-300M-Instruct.git pretrained_models/CosyVoice-300M-Instruct
git clone https://www.modelscope.cn/iic/CosyVoice-ttsfrd.git pretrained_models/CosyVoice-ttsfrd
还需要 audioseal 文件,可以从魔搭创空间获取 [ 4] 。

点击链接,立即部署:https://fcnext.console.aliyun.com/applications/ai/create?template=109
相关链接:
[1] 阿里云函数计算控制台
https://fcnext.console.aliyun.com/applications/create
[2] 代码获取
https://github.com/hanxie-crypto/serverless_ai_cosyvoice
[3] 完整代码
https://github.com/hanxie-crypto/serverless_ai_cosyvoice
[4] 魔搭创空间获取
https://modelscope.cn/studios/iic/CosyVoice-300M/files
















 522
522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









