









数据:中华书局白话版24史,总计大小93M,已经存放到HDFS集群
分析语言:python
分析框架:Spark 1.6.0
第三方包:jieba(结巴分词)
可视化工具:D3.JS
源代码:
PS:此源代码过滤部分和可视化部分在另外的文件里面,需要的可以通过公众号邮箱获取。
分析结果:
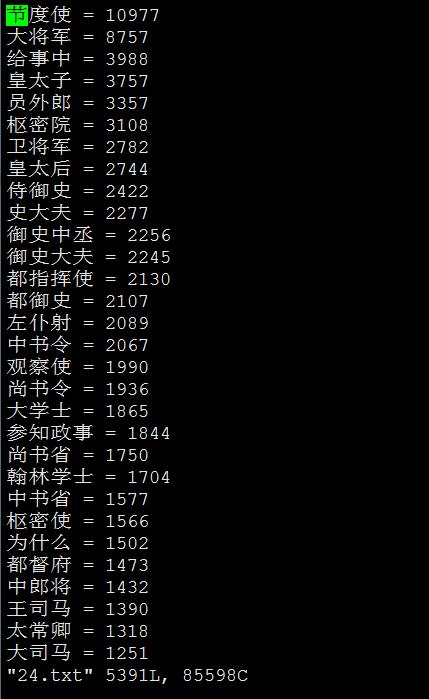
排名前100位的词频,进行词云可视化:

历史科普:
节度使官衔始于唐初,到元代被废止。
历史上有记载的第一个被授予节度使称号的是唐睿宗(武则天的儿子)时期的左武卫大将军兼幽州都督薛讷,他也是大名鼎鼎的薛仁贵的儿子。
从这张图上看,24史中,着墨最多的时代,就是唐宋两朝。
想了解这些技术后面更多的东西么?5月26、27日开发者大会见。
分析语言:python
分析框架:Spark 1.6.0
第三方包:jieba(结巴分词)
可视化工具:D3.JS
源代码:
| from pyspark import SparkConf, SparkContext import jieba,Wordfilter,datetime,WordCloud,webbrowser from operator import add def splitWord(line): seg_list = jieba.cut(line, cut_all=True) return seg_list if __name__ =="__main__": conf = SparkConf().setMaster("spark://server1.com:7077").setAppName("App %s"%datetime.datetime.now()) sc = SparkContext(conf = conf) lines = sc.textFile("hdfs://server1.com:8020/data/txt/24.txt") counts = lines.flatMap(lambda x: splitWord(x)).map(lambda x: (x, 1)).reduceByKey(add) output = counts.collect() wcount = [] for (word, count) in output: if len(word) > 2 and count > 10: if Wordfilter.wfilter(word): tup= (word,count) wcount.append(tup) sortCount = sorted(wcount,key=lambda wc:wc[1],reverse=True) file = "/home/hadoop/Documents/out/24.txt" wf = open(file,"w") for (w,c) in sortCount: wc = "%s = %s\n"%(w,c) wf.write(wc.encode("utf-8")) print(wc) wf.close() startTime = datetime.datetime.now().strftime('%Y%m%d%H%M%S%f') html = r"/home/hadoop/Documents/out/d3cloudmaster/examples/" + str(startTime) + ".html" s = WordCloud.procTextFile(file) WordCloud.createWordCloudHTML(s, html) sc.stop() webbrowser.open(html) |
PS:此源代码过滤部分和可视化部分在另外的文件里面,需要的可以通过公众号邮箱获取。
分析结果:
排名前100位的词频,进行词云可视化:
历史科普:
节度使官衔始于唐初,到元代被废止。
历史上有记载的第一个被授予节度使称号的是唐睿宗(武则天的儿子)时期的左武卫大将军兼幽州都督薛讷,他也是大名鼎鼎的薛仁贵的儿子。
从这张图上看,24史中,着墨最多的时代,就是唐宋两朝。
想了解这些技术后面更多的东西么?5月26、27日开发者大会见。
















 1852
1852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











