






整个互联网使用频率最高的协议之一*
* 在 OSI 模型中,第 7 层
每次访问网站时,您的 Web 浏览器都会使用HTTP协议与 Web服务器通信并获取页面内容。此外,当您实现后端应用程序并且必须与其他后端应用程序通信时 - 80%(或更多)的情况下您将使用HTTP .
长话短说——当你想成为一名优秀的软件开发人员时,你必须了解HTTP协议的工作原理。我认为,连接HTTP 服务器是一种很好的理解方式。
Web 浏览器向 Web服务器发送什么?
好问题。当然,您可以使用“开发人员工具”,我们来做吧。

嗯……但是现在怎么办?究竟是什么意思?我们可以看到一些 URL、一些方法、一些状态、版本(嗯?)、标题和其他东西。有用?是的,但只能在出现问题时分析 Web 应用程序。我们仍然不知道HTTP是如何工作的。
Wireshark,我的老朋友
真理之源。Wireshark 是用于分析网络流量的应用程序。您可以使用它来查看由您的(或到您的)PC 发送的每个数据包。
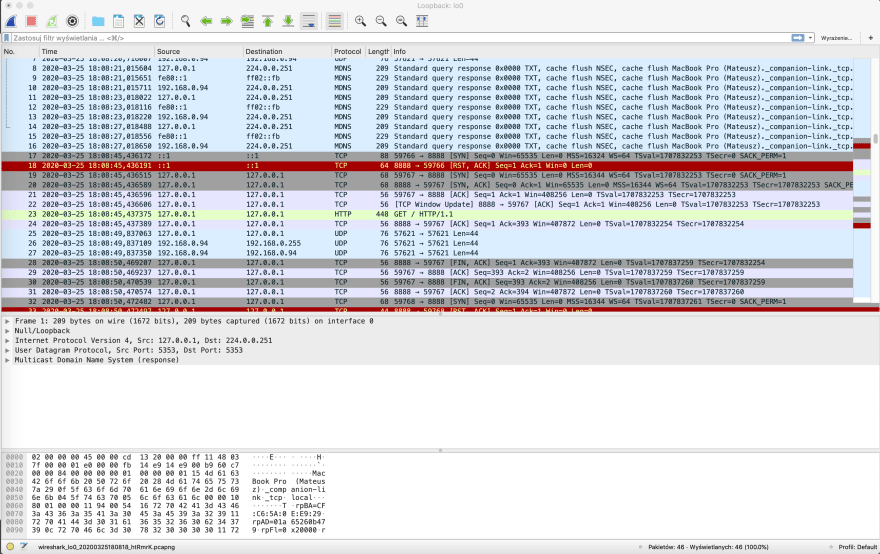
但说实话——如果你知道如何使用 Wireshark——你可能知道HTTP和 TCP是如何工作的。这是相当先进的程序。
你是对的 - 规范
每个好的(我的意思是 - 被超过 5 人使用)协议都应该有规范。在这种情况下,它称为RFC。但是不要撒谎 - 你永远不会读到这个,它太长了 - rfc2616。
只需运行服务器并测试
玩笑?不。可能您在 PC 上安装了名为 netcat 的非常强大的工具,它是非常先进的工具。
netcat 的功能之一是 TCP服务器。您可以运行 netcat 来侦听特定端口并打印它得到的每一件事。Netcat 是一个命令行应用程序。
nc -v -l -p 8080
Netcat ( nc ),请在端口 8080 ( -p 8080 )上监听 ( -l ) 并打印所有内容 ( -v )。
现在打开网络浏览器并输入http://localhost:8080/. 您的浏览器会将HTTP请求发送到由 netcat 运行的服务器。当然nc会打印整个请求并忽略它,浏览器会等待响应(很快就会超时)。要杀死nc按ctrl+c。

所以,最后,我们有一个HTTP请求!
GET / HTTP/1.1
Host: localhost:8080
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:74.0) Gecko/20100101 Firefox/74.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
Cookie: JSESSIONID=D3AF43EBFC0C9D92AD9C37823C4BB299
Upgrade-Insecure-Requests: 1正如你所看到的 - 它完全文本协议。没有要分析的位,只是纯文本。
HTTP请求
这可能有点令人困惑。也许nc在打印之前解析请求?HTTP协议应该很复杂,0和1的顺序在哪里?没有。HTTP是非常简单的文本协议。只有一个小陷阱(我将在本节末尾解释)。
我们可以将请求拆分为 4 个主要部分:
GET / HTTP/1.1
这是主要的要求。
GET- 这是HTTP方法。可能你知道有很多方法。GET方法give me
/- 资源。/意味着默认一个。
当您打开时localhost:8080/my_gf_nudes.html,资源将是/my_gf_nudes.html
HTTP/1.1- HTTP版本。版本很少,常用的是1.1。
Host: localhost:8080
主持人。一台服务器可以托管多个域,使用此字段,浏览器会准确显示它想要哪个域
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:74.0) Gecko/20100101 Firefox/74.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
Cookie: JSESSIONID=D3AF43EBFC0C9D92AD9C37823C4BB299
Upgrade-Insecure-Requests: 1标题。简而言之:一些附加信息。但我相信你知道标题是什么:)
惊喜 - 空行。意思是:请求结束。通常,HTTP 中的空行表示部分结束。
陷阱
在HTTP 中,每一个新的行分隔符都是一个 Window 的新行。\r\n 不是 \n。记住。
回复
好的。我们有一个请求。响应如何?向任何服务器发送请求,看看,没有什么比这更简单的了。
在您的笔记本电脑上,您可以找到另一个非常有用的工具 - telnet. 使用 Telenet,您可以打开 TCP 连接,向服务器写入内容并打印响应。
尝试自己做。运行telnet google.com 80(80 是默认的HTTP端口)并手动键入请求(您知道它应该是什么样子)。要关闭连接,请按ctrl+]比键入quit。

好的。我们有回应。
HTTP/1.1 301 Moved Permanently
Location: http://www.google.com/
Content-Type: text/html; charset=UTF-8
Date: Wed, 25 Mar 2020 18:53:12 GMT
Expires: Fri, 24 Apr 2020 18:53:12 GMT
Cache-Control: public, max-age=2592000
Server: gws
Content-Length: 219
X-XSS-Protection: 0
X-Frame-Options: SAMEORIGIN
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8">
<TITLE>301 Moved</TITLE></HEAD><BODY>
<H1>301 Moved</H1>
The document has moved
<A HREF="http://www.google.com/">here</A>.
</BODY></HTML>我们可以把它分成 4 个部分
HTTP/1.1 301 Moved Permanently
HTTP/1.1- 版本301-状态码。我相信您对此很熟悉Moved Permanently- 人类可读的状态代码
Location: http://www.google.com/
Content-Type: text/html; charset=UTF-8
Date: Wed, 25 Mar 2020 18:53:12 GMT
Expires: Fri, 24 Apr 2020 18:53:12 GMT
Cache-Control: public, max-age=2592000
Server: gws
Content-Length: 219
X-XSS-Protection: 0
X-Frame-Options: SAMEORIGIN标题
空行,表示内容将在下一节发送。
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8">
<TITLE>301 Moved</TITLE></HEAD><BODY>
<H1>301 Moved</H1>
The document has moved
<A HREF="http://www.google.com/">here</A>.
</BODY></HTML>内容,HTML 或二进制文件或其他内容
空行,表示请求结束。
记住:每个新行都是 \r\n
编程时间!
我们知道请求的样子,我们知道响应的样子,是时候实现我们的服务器了。
我们的期望
我们想要一个非常简单的东西——在浏览器中显示一个 HTML 页面和一张图片。
让我们准备两个 HTML 文件和一张图片
❯ pwd
/tmp/www
❯ ls
gallery.html index.html me.jpg
❯ cat index.html
<html>
<header>
<title>My homepage!</title>
</header>
<body>
<h1>Welcome!</h1>
<p><a href="gallery.html">Here</a> you can look at my pictures</p>
</body>
</html>
❯ cat gallery.html
<html>
<head>
<title>Gallery</title>
</head>
<body>
<h1>My sexi photos<h1>
<img src="me.jpg" />
</body>
</html>
❯计划
计划很简单:
- 打开 TCP 套接字并监听
- 接受客户端并读取请求
- 解析请求
- 在磁盘上查找请求的资源
- 发送响应
- 测试
打开 TCP 套接字
在本文中,我们将使用ServerSocket类来处理 TCP 连接。作为作业,您可以重新实现服务器以使用nio包中的类。
所以,打开你的IDE,让我们开始吧。
public static void main( String[] args ) throws Exception {
try (ServerSocket serverSocket = new ServerSocket(8080)) {
while (true) {
// implement client handler here
}
}
}我想保持代码简洁和干净——这就是为什么我throws Exception没有实现良好的异常处理。
所以正如我所说,我们必须在端口 8080 上打开套接字(为什么不是 80?因为要使用低端口,您需要 root 权限)。
我们还需要无限循环来“暂停服务器”。
用户telnet测试套接字: 完美,有效。

接受客户端连接
try (ServerSocket serverSocket = new ServerSocket(8080)) {
while (true) {
try (Socket client = serverSocket.accept()) {
handleClient(client);
}
}
}要接受来自客户端的连接,我们必须调用阻塞 accept()方法。Java程序将在该行等待客户端。
是时候实现客户端处理程序了:
private static void handleClient(Socket client) throws IOException {
System.out.println("Debug: got new client " + client.toString());
BufferedReader br = new BufferedReader(new InputStreamReader(client.getInputStream()));
StringBuilder requestBuilder = new StringBuilder();
String line;
while (!(line = br.readLine()).isBlank()) {
requestBuilder.append(line + "\r\n");
}
String request = requestBuilder.toString();
System.out.println(request);
}我们必须阅读请求。如何?只需从客户端的套接字读取输入流。在Java 中它不是那么简单,这就是为什么我做了这条丑陋的线
new BufferedReader(new InputStreamReader(client.getInputStream()));
好吧,Java。
请求以一个空行 ( \r\n) 结束,还记得吗?客户端将发送空行,但输入流仍将打开,我们必须读取它直到一个空行到达。
运行服务器,转到http://localhost:8080/并观察日志: 它有效!我们可以记录整个请求!

解析请求
解析请求真的很简单,我觉得没必要再解释了
String request = requestBuilder.toString();
String[] requestsLines = request.split("\r\n");
String[] requestLine = requestsLines[0].split(" ");
String method = requestLine[0];
String path = requestLine[1];
String version = requestLine[2];
String host = requestsLines[1].split(" ")[1];
List<String> headers = new ArrayList<>();
for (int h = 2; h < requestsLines.length; h++) {
String header = requestsLines[h];
headers.add(header);
}
String accessLog = String.format("Client %s, method %s, path %s, version %s, host %s, headers %s",
client.toString(), method, path, version, host, headers.toString());
System.out.println(accessLog);只是一些分裂。您可能不明白的唯一一件事是为什么我们从 2 开始循环?因为第一行(索引 0)是,第二行是主机。标头从请求的第三行开始GET / HTTP/1.1
发送回复
我们将响应发送到客户端的输出流。
OutputStream clientOutput = client.getOutputStream();
clientOutput.write("HTTP/1.1 200 OK\r\n".getBytes());
clientOutput.write(("ContentType: text/html\r\n").getBytes());
clientOutput.write("\r\n".getBytes());
clientOutput.write("<b>It works!</b>".getBytes());
clientOutput.write("\r\n\r\n".getBytes());
clientOutput.flush();
client.close();你还记得响应应该是什么样子吗?
version status code
headers
(empty line)
content
(empty line)不要忘记关闭输出流。

哇,真的好用
查找请求的资源
我们必须先实现两个方法
private static String guessContentType(Path filePath) throws IOException {
return Files.probeContentType(filePath);
}
private static Path getFilePath(String path) {
if ("/".equals(path)) {
path = "/index.html";
}
return Paths.get("/tmp/www", path);
}guessContentType- 我们必须告诉浏览器我们正在发送什么样的内容。这是 callend content type。幸运的是,Java中有为此提供内置机制。我们不必制作一个大的开关块。
getFilePath- 在我们返回文件之前 - 我们需要知道它的位置。
这种情况值得关注
if ("/".equals(path)) {
path = "/index.html";
}如果用户想要默认资源,则返回index.html.
发送响应
您还记得向用户发送响应的代码(块clientOutput.write)吗?我们需要将它移动到方法中
private static void sendResponse(Socket client, String status, String contentType, byte[] content) throws IOException {
OutputStream clientOutput = client.getOutputStream();
clientOutput.write(("HTTP/1.1 \r\n" + status).getBytes());
clientOutput.write(("ContentType: " + contentType + "\r\n").getBytes());
clientOutput.write("\r\n".getBytes());
clientOutput.write(content);
clientOutput.write("\r\n\r\n".getBytes());
clientOutput.flush();
client.close();
}好了,终于可以返回文件了
Path filePath = getFilePath(path);
if (Files.exists(filePath)) {
// file exist
String contentType = guessContentType(filePath);
sendResponse(client, "200 OK", contentType, Files.readAllBytes(filePath));
} else {
// 404
byte[] notFoundContent = "<h1>Not found :(</h1>".getBytes();
sendResponse(client, "404 Not Found", "text/html", notFoundContent);
}有用!
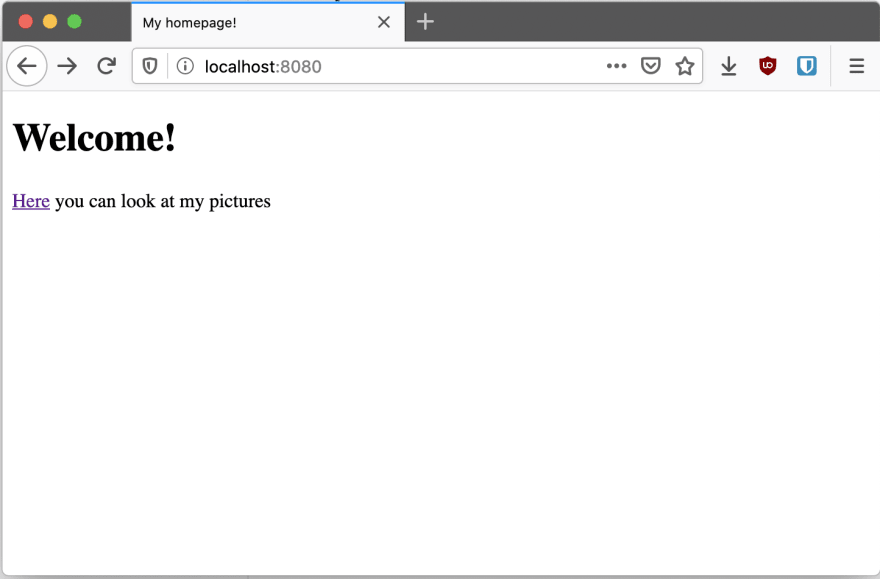
最后,我们可以看到由我们的 Web服务器提供的 html 页面!
在家工作
- 使其成为多线程。
- 创建线程池
- 将
handleClient方法移动到分离的类并在新线程中运行它
- 使用非阻塞 IO 重写它
- 实现POST方法
- 启动网猫
- 发送一些 HTML 表单
- 分析请求
完整的源代码















 170
170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









