






redis数据类型
数据类型描述的是value的类型,key都是string,长江的数据类型(value)有:
-
string(embstr,raw,int)
-
list(链表,quicklist(多个ziplist双向链表))
-
hash表(ziplist,hashtable)
-
set(无序的集合,intset,hashtable)
-
sorted(在set的基础上加入了有序的功能)
-
bitmap(主要做一些统计)
-
hyperloglog(主要做一些统计)
每一种类型都用redisObject结构体来表示,情况不同,编码(底层数据结构)就不同
spring
-
如果保存的是整数,则底层编码使用int,实际使用long存储,存储的时候直接存成数字,因为数字占用空间少,进行数据运算方便.
-
如果字符串保存的非整数,(浮点数或者其他),又分两种情况
① 长度<=39字节,使用embstr编码来保存,即将redisObject和sdshdr结构体存在一起,分配内存只需要一次
② 长度>39字节 ,使用raw编码来保存,及redisObject结构体分配一次内存,sdshdr结构体也分配一次内存,用 指针相连.
-
sdshdr:简单动态字符串,实现类似与Java的StringBuilder,有以下特性:
①单独存储字符长度,相比于char获取长度效率高(char是C语言原生字符串表示)
②支持动态扩容,方便字符串拼接
③预留空间,减少内存分配,释放次数(<1M时容量是字符串长度的2倍,>=1M时容量是原有容量+1M)
④二进制安全,可以存储视频图片等二进制数据
List
-
3.2 开始,Redis 采用quicklist作为其编码方式,它是一个双向链表,节点元素是ziplist,简单来说就是,quicklist是一个大链表,里面存储的是小链表ziplist,小链表中存储的才是数据
1.由于是链表,内存上不连续
2.操作头尾效率高,时间复杂度0(1),所以查询尽量使用头部和尾部 的数据
3.链表中 ziplist的大小和元素个数都可以设置,其中大小默认8kb
-
ziplist用一块连续的内存存储数据,设计目标是让数据存储更紧凑, 减少碎片开销,节约内存,它的结构如下
①zlbytes -记录整个ziplist占用字节数
②zltail-offset -记录尾节点偏移量
③zllength -记录节点数量
④entry-节点,1~N个,每个entry记录了前一entry长度(方便查询,查前一个entry的时候直接减去前一entry的长度即可),本entry的编码、长度、实际数据,为了节省内存,根据实际数据长度不同,用于记录长度的字节数也不同,例如前一entry长度是253时,需要用1个字节,但超过了253,需要用5个字节
⑤zlend -结束标记
-
ziplist适合存储少量元素,否则查询效率不高,并且长度可变的设计会带来连锁更新问题
面试经常会问quicklist和ziplist的区别,就是上面说的. quicklist是一个大链表,ziplist是小链表.
hash
1.在数据量较小时, 采用zplist作为其编码,当键或值长度过大(64)或个数过多(512) 时,转为hashtable编码
2.hashtable编码(面试重点)
①hash函数,Redis 5.0采用了SipHash算法
②采用拉链法解决key冲突(重要):解决hash冲突就用拉链法
③rehash时机
-
当元索数<1*桶个数时,不扩容
-
当元素数>5*桶个数时,一定扩容
-
当1桶个数<=元索数<=5*桶个数时,如果此时没有进行AOF或RDB操作时,就进行rehash,如果有就暂时不进行.
-
当元素数<桶个数/10时,缩容
④rehash要点:
-
每个字典有两个哈希表,桶个数为2的n次方,平时使用ht[0], ht[1] 开始为null,在扩容时新数组大小为元素个数* 2并且最接近一个2的n次幂的值,因为要满足2的n次方
-
渐进式rehash,即不是一次将所有桶都迁移过去,每次对这张表CRUD仅迁移一个桶,不影响其他命令的性能,而且还是被动的有一次增删改查就进行一次
-
active rehash, server 的主循环中,每100 ms里留出1s进行主动迁移
-
rehash过程中,新增操作ht[1] ,其它操作先操作ht[0],若没有,再操作ht[1]
-
redis所有CRUD都是单线程,因此rehash一定是线程安全的
Sorted Set(有序set)
1.在数据量较小时,采用ziplist作为其编码,按score有序,当键或值长度过大(64)或个数过多(128) 时,转为skiplist(跳表) + hashtable编码,同时采用的理由是
-
只用hashtable, CRUD是0(1),但要执行有序操作,需要排序,带来额外时间空间复杂度
-
只用skiplist,虽然范围操作优点保留,但时间复杂度上升
-
虽然同时采用了两种结构,但由于采用了指针,元素并不会占用双份内存
我们看这个图
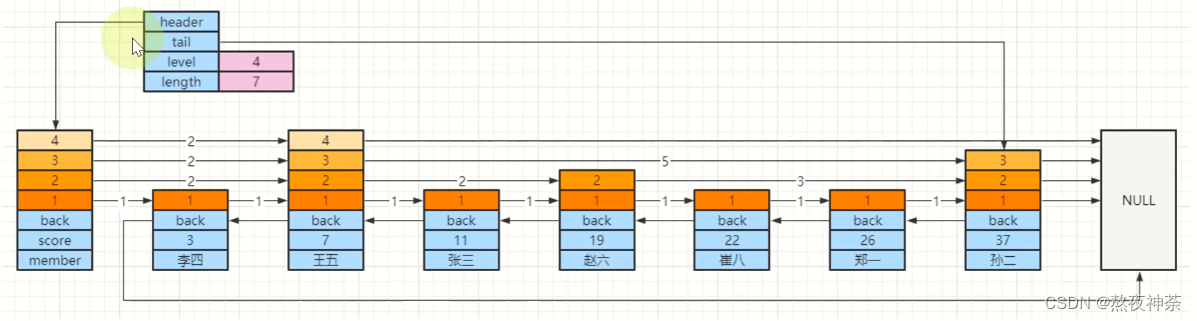
skiplist要点:多层链表,排序规则,backward,level(span,forward)
下面那些是跳表中的节点,调表有个头节点指向第一个节点(不存数据),尾节点指向最后一个节点
score:按照顺序排序用的分数(相同的话就按照member排序)
member:具体存储的数据值
1234:这些叫层(level):最大层数会被记录到外面,length是总数,level的forward是方便正序的,span则是计算排名的,计算每个节点之间的跨度,例如孙二和赵六之间差三个空,使用就是3,根据span可以判断出来每个元素的排名
backward:反向指针,方便倒叙遍历,通过tall找到尾节点
跳表查询
查找要点,从顶层开始(就是按照那个1234的level层,一层一层过):
1.>大于右边的,继续向右
2.=右边的就是找到了
3.<右边的或者右边的为null,则继续从下一层,继续按照1,2的规则















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









