







图像生成目录
DDPM: Denoising Diffusion Probabilistic Models (NIPS 2020)
首先会讲一下diffusion model,这部份内容会较多的参考李宏毅老师的课程视频,里面也有很多的图像来自于此
视频链接
Diffusion Model概述
首先diffusion的概念是什么?
diffusion的基本思想就是一张原始的图像,可以经过很多次加噪声的过程,当噪声非常大的时候,原始的图像就会变成几乎完全都是噪声了,而进行图像生成的过程,就是不断的把原始的噪声去除(若干的Denoise层)从而还原出原始的图像。
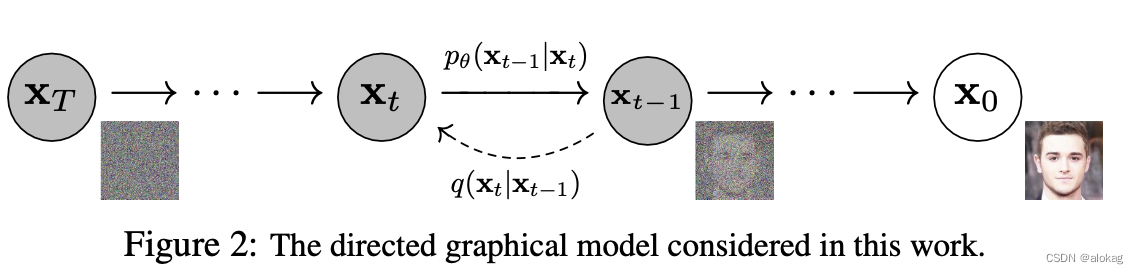
总体网络的框架上,diffusion网络的结构是和VAE的结构很相近的,都是基于中间层的特征(噪声图)进行生成。Diffusion的过程如下:

训练的过程:
首先对干净样本进行采样
在1到T中采样一个数字
然后在一个正态分布空间中,获取一个 ϵ \epsilon ϵ,大小和image大小相同
然后用加权求和的方法加噪声(在 α t \alpha_t αt中, t t t越大, α t \alpha_t αt越小,t较小的时候代表加的噪声很大)。
最后如图中的公式,计算出原本采样的噪音,以及一个经过 ϵ θ \epsilon_\theta ϵθ计算出的噪声图,将其之间的差的范数作为损失,进行梯度下降学习
这里会有点奇怪,那这个训练的学习目标是什么? 学习的目标其实是通过一个Noice Predicter来基于加了噪声的图像和 t t t 来对所加的噪声进行预测,即对一个正态分布空间下的实例进行预测。
为什么会这么做?这样的话就可以基于一个整数 t t t,实现对于图像噪声的层层去噪,从而实现原始图像的恢复。
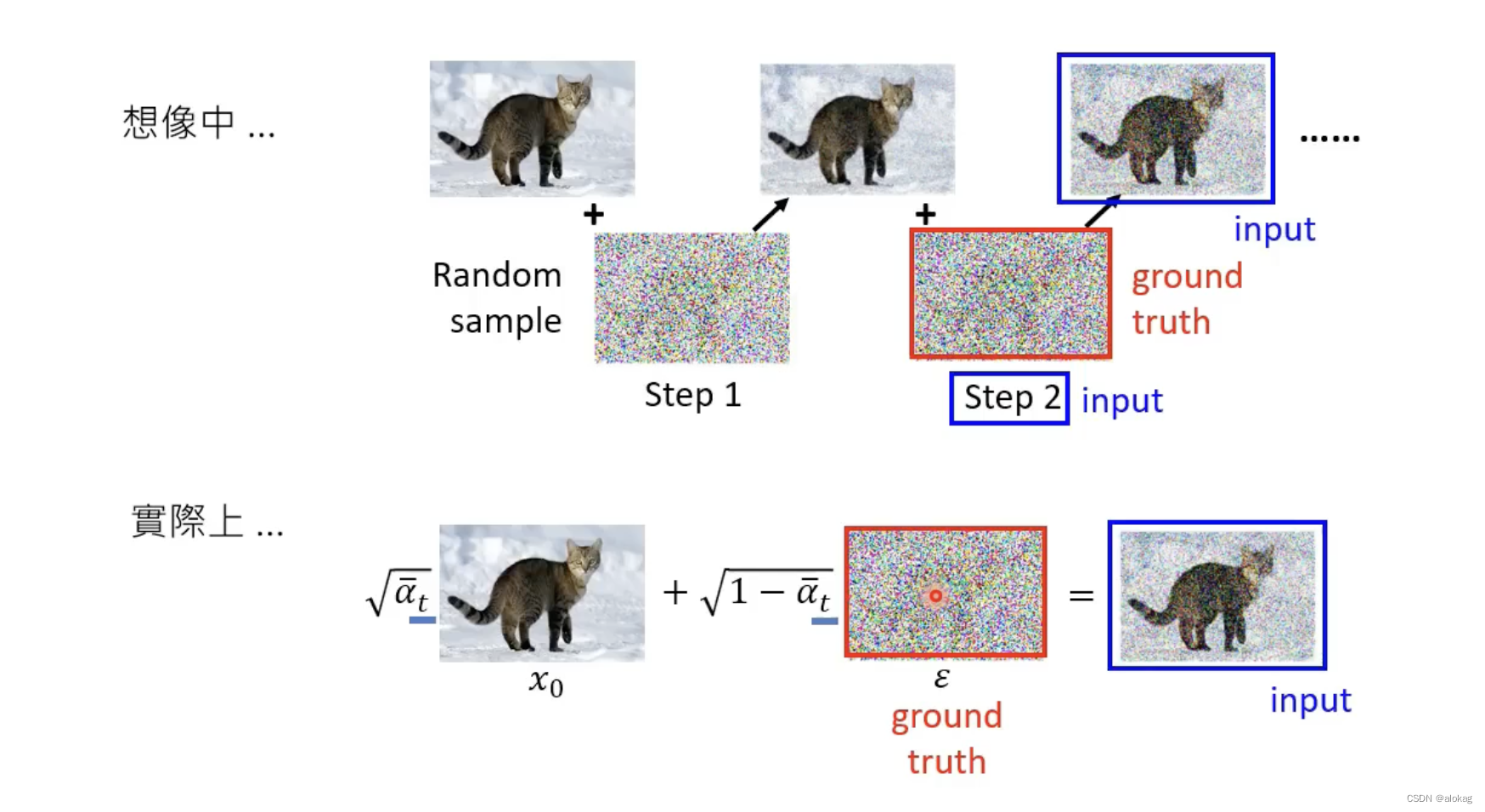
实际上的DDPM其实并不是一个一个的进行的而是所有噪声一起处理的。
生成的过程:
直接遍历所有的t
首先还要再sample一个噪声 z \textbf z z
基于原本的图像和 t t t,就能够计算出来的图,但是在这个图后,还需要加上这个噪声 z \textbf z z
为什么?
图像生成的共同目标
这在VAE的时候就已经思考过了。每次从一个分布,通过神经网络,形成一个复杂的分布。那么目标就是,建立一个从高斯分布到现实图像的分布的Network,而学习的过程就是让学习的分布更接近现实分布。而跨模态生成,则是生成文字的条件下的分布(但是DDPM中不做跨模态文生图,不考虑条件)
如何界定分布更为接近呢?很多的方法采用极大似然估计:首先从真实分布
P
d
a
t
a
(
x
)
P_{data}(x)
Pdata(x)中进行sample,
{
x
1
,
x
2
,
…
,
x
m
}
\{x^1,x^2,\dots,x^m\}
{x1,x2,…,xm},可以计算出一个
P
θ
(
x
i
)
P_\theta(x^i)
Pθ(xi),然后优化目标是使得所有
P
θ
(
x
i
)
P_\theta(x^i)
Pθ(xi)乘积最大的
θ
∗
\theta^*
θ∗
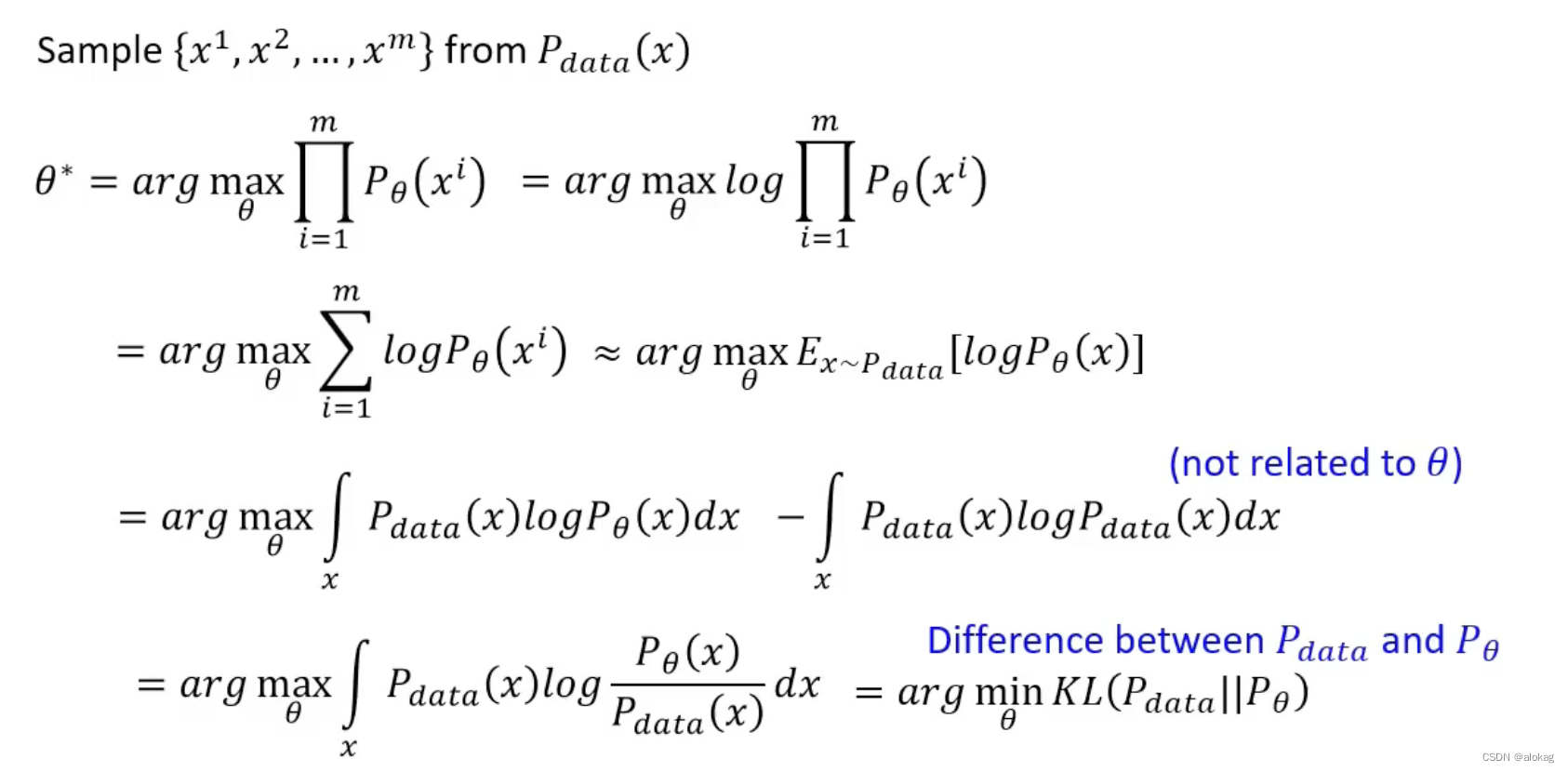
但是经过公式推导后发现,其实计算分布之间的极大似然估计就是最小化KL散度
VAE是怎么做的
VAE的目标是直接计算这个 P θ ( x ) P_\theta(x) Pθ(x),它假设输入了一个z,就会输出一个G(z),这是一个高斯分布的平均值,而最终的距离,就是直接将x和G(z)进行距离计算,如果距离越近则概率越高,越远则概率越低。
在计算的过程中,计算的是
P
(
x
)
P(x)
P(x)(此后
θ
\theta
θ略)的一个ELBO(不细讲,讲过了)。首先有
l
o
g
P
θ
(
x
)
=
∫
z
q
(
z
∣
x
)
l
o
g
P
(
x
)
d
z
=
∫
z
q
(
z
∣
x
)
l
o
g
(
P
(
z
,
x
)
q
(
z
∣
x
)
)
d
z
+
K
L
(
q
(
z
∣
x
)
∣
∣
P
(
z
∣
x
)
)
≥
∫
z
q
(
z
∣
x
)
l
o
g
(
P
(
z
,
x
)
q
(
z
∣
x
)
)
d
z
=
E
q
(
z
∣
x
)
[
l
o
g
(
P
(
z
,
x
)
q
(
z
∣
x
)
)
]
logP_\theta(x)=\int_zq(z|x)logP(x)dz=\int_zq(z|x)log(\frac{P(z,x)}{q(z|x)})dz+KL(q(z|x)||P(z|x)) \\\geq\int_zq(z|x)log(\frac{P(z,x)}{q(z|x)})dz=\Epsilon_{q(z|x)}[log(\frac{P(z,x)}{q(z|x)})]
logPθ(x)=∫zq(z∣x)logP(x)dz=∫zq(z∣x)log(q(z∣x)P(z,x))dz+KL(q(z∣x)∣∣P(z∣x))≥∫zq(z∣x)log(q(z∣x)P(z,x))dz=Eq(z∣x)[log(q(z∣x)P(z,x))]
其中
q
(
z
∣
x
)
q(z|x)
q(z∣x)对应的就是VAE中的encoder
DDPM是怎么做的
DDPM可以看作是一种VAE的模型,将每一个image的denoise结果,也同样当作一个高斯分布的均值。
整体的有
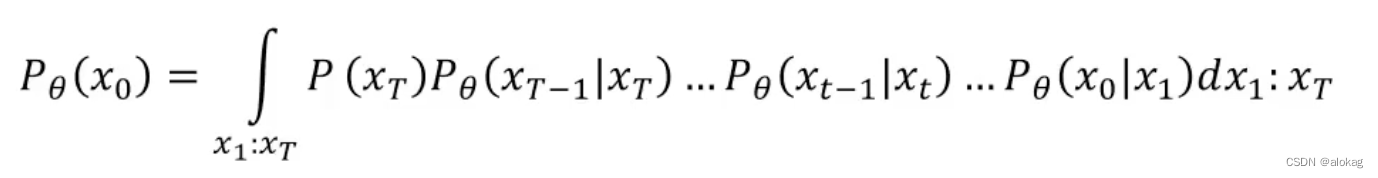
同样的DDPM也有证据下界为:
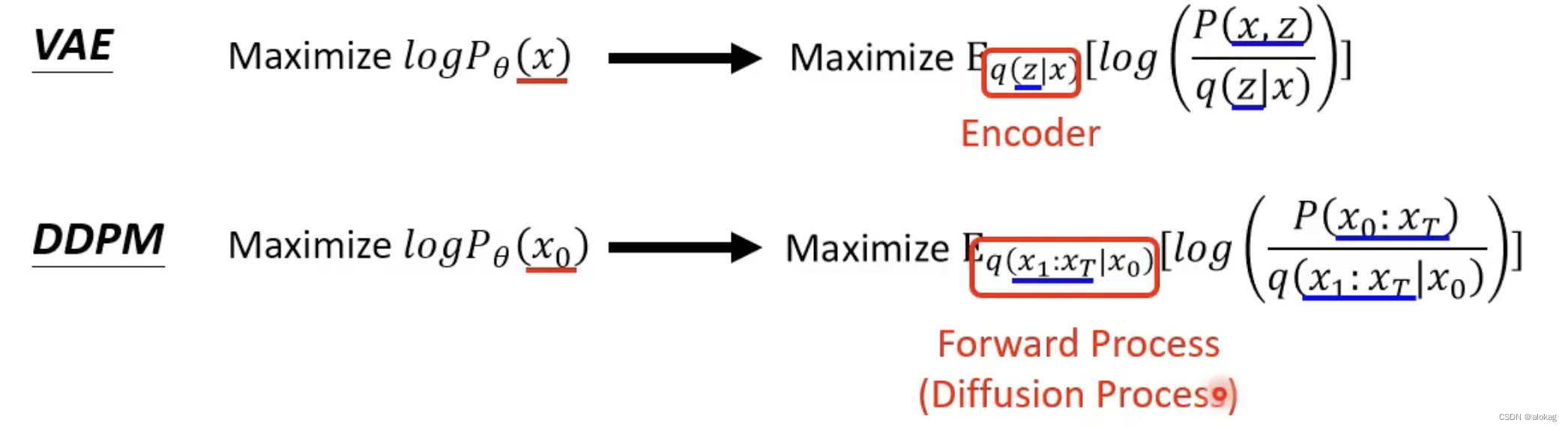
其中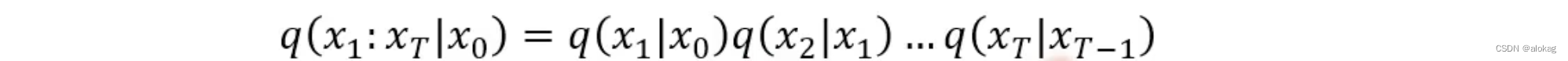
扩散阶段
本身的diffusion(扩散阶段)过程:

这里的
β
\beta
β系数和
α
\alpha
α一样也是认为设定的,随着t增大,
β
t
\beta_t
βt逐渐增大(一种思路是,越往后加噪声,需要加更多的噪声才能显得变化更显著),且有关系
β
t
=
1
−
α
t
\beta_t=1-\alpha_t
βt=1−αt。如果把两个步骤和在一起,噪声就可以直接看做是一个采样得到的(利用正态分布可加性,系数使得方差一样,这个系数我感觉是直接自己提出来的),最后可以叠加为
x
t
=
1
−
β
1
…
1
−
β
t
x
0
+
1
−
(
1
−
β
1
)
…
(
1
−
β
t
)
⋅
z
x_t=\sqrt{1-\beta_1}\dots\sqrt{1-\beta_t}x_0+\sqrt{1-(1-\beta_1)\dots(1-\beta_t)}\cdot\bf z
xt=1−β1…1−βtx0+1−(1−β1)…(1−βt)⋅z(还有一种写法是
x
t
=
α
t
‾
x
0
+
1
−
α
t
‾
⋅
z
x_t=\sqrt{\overline{\alpha_t}}x_0+\sqrt{1-\overline{\alpha_t}}\cdot\bf z
xt=αtx0+1−αt⋅z)
即

具体到训练过程,再对diffusion部份的训练进行一个直观的解释,这里参考了B站一个手推公式的大佬的视频中的解释过程,链接:https://www.bilibili.com/video/BV1NS4y1E7ki
- 假设在batchsize为4的条件下学习,每次输入都有4张real image a 0 , b 0 , c 0 , d 0 a_0,b_0,c_0,d_0 a0,b0,c0,d0
- 训练过程中,首先在[1,2000]中,采样出四个不同的t(假设为50,200,1000,1500)
- 这样基于公式,可以分别的生成四个图像对应的四个退化图 a 50 , b 200 , c 1000 , d 1500 a_{50}, b_{200},c_{1000},d_{1500} a50,b200,c1000,d1500
- 训练时,这四个noise image,再投入到UNet中,UNet对其进行去噪,学习到加上去的噪声的预测 z ~ \tilde{\bf z} z~,和原本的噪声做l1或l2损失。实际上,每一个 x t x_t xt都能够接一个UNet来学一个 z ~ \tilde{\bf z} z~。理想的情况下,就可以用这个 z ~ \tilde{\bf z} z~一步直接再复原回去,但这样做效果并不好
重建过程
一步步的向前推的效果更好。向前推的基本框架如下图
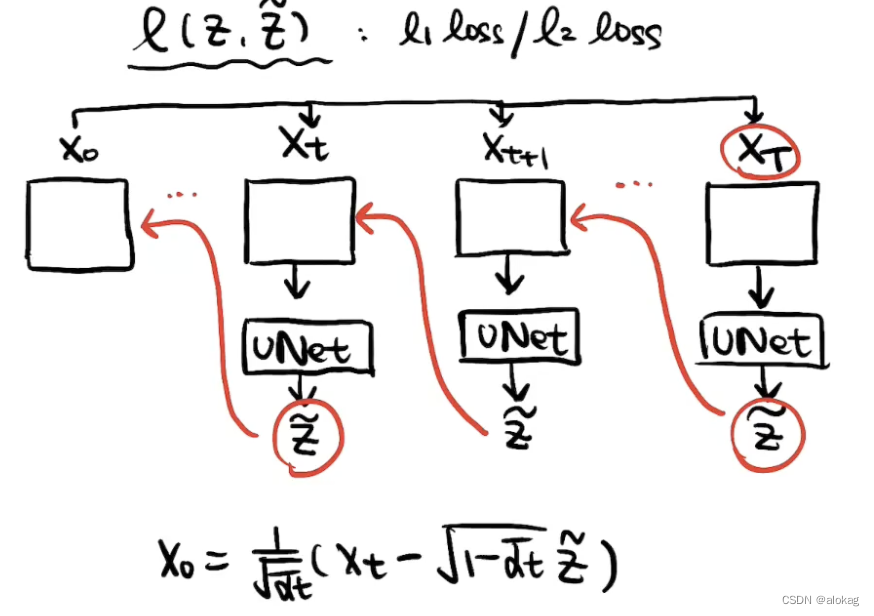
这样的话,重建的过程学习的任务就是找到每一步推理的一个关系:
z
~
=
U
N
e
t
(
x
t
,
t
)
x
t
−
1
=
f
(
x
t
,
z
~
)
\tilde z=UNet(x_t,t)\\x_{t-1}=f(x_t,\tilde z)
z~=UNet(xt,t)xt−1=f(xt,z~)
经过一轮公式推导后,原本前文中,DDPM的下界优化目标,可以转换为:
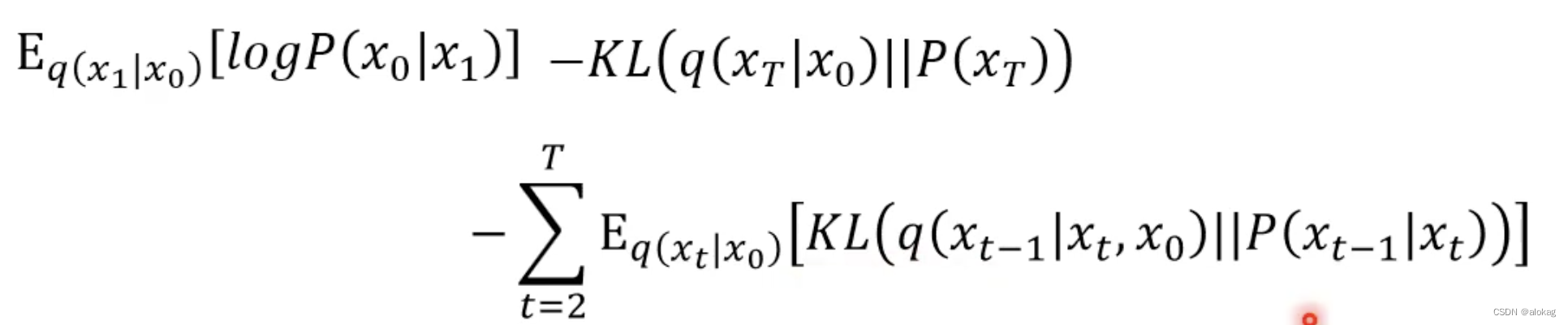
其中,第二项的KL散度是一个无关项,主要的优化目标就是第一项和第三项(这两个的形式实际上是类似的)第三项中,
P
(
x
t
−
1
∣
x
t
)
P(x_{t-1}|x_t)
P(xt−1∣xt)是神经网络操控的,
q
(
x
t
−
1
∣
x
t
,
x
0
)
q(x_{t-1}|x_t,x_0)
q(xt−1∣xt,x0)是需要想办法计算的。
第三项的推理过程
首先先看看 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0),这是什么意思?假设已经有 x 0 x_0 x0和已经加过t次噪声的样本 x t x_t xt,要基于此推测出 x t − 1 x_{t-1} xt−1的概率分布。
已知的内容: q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x t − 1 ) q(x_t|x_0)\\q(x_{t-1}|x_0)\\q(x_t|x_{t-1}) q(xt∣x0)q(xt−1∣x0)q(xt∣xt−1)
来对上式进行求解,有
q ( x t − 1 , x t , x 0 ) q ( x t , x 0 ) = q ( x t ∣ x t − 1 ) q ( x t − 1 ∣ x 0 ) q ( x 0 ) q ( x t ∣ x 0 ) q ( x 0 ) = q ( x t ∣ x t − 1 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) \frac {q(x_{t-1},x_t,x_0)}{q(x_t,x_0)}=\frac{q(x_t|x_{t-1})q(x_{t-1}|x_0)q(x_0)}{q(x_t|x_0)q(x_0)}=\frac{q(x_t|x_{t-1})q(x_{t-1}|x_0)}{q(x_t|x_0)} q(xt,x0)q(xt−1,xt,x0)=q(xt∣x0)q(x0)q(xt∣xt−1)q(xt−1∣x0)q(x0)=q(xt∣x0)q(xt∣xt−1)q(xt−1∣x0)
根据前面的学习,这三个项都是已经知道的高斯分布,根据一系列很长很长的推导,这个计算结果依旧是一个高斯分布,它的均值是 α ‾ t − 1 β t x 0 + α t ( 1 − α ‾ t − 1 ) x t 1 − α ‾ t \frac{\sqrt{\overline{\alpha}_{t-1}}\beta_tx_0+\sqrt{\alpha_t}(1-\overline\alpha_{t-1})x_t}{1-\overline\alpha_t} 1−αtαt−1βtx0+αt(1−αt−1)xt方差为 1 − α ‾ t − 1 1 − α ‾ t β t I \frac{1-\overline\alpha_{t-1}}{1-\overline\alpha_t}\beta_tI 1−αt1−αt−1βtI
其中 α ‾ t = ∏ s = 1 t α s \overline\alpha_t=\prod\limits_{s=1}^t\alpha_s αt=s=1∏tαs
注意:原文中作者提到,这个方差可以直接设为 β t \beta_t βt,在文中直接用 σ t \sigma_t σt来表示这个方差
优化这个KL散度, q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)的均值和方差是已知的了,而神经网络会决定 P ( x t − 1 ∣ x t ) P(x_{t-1}|x_t) P(xt−1∣xt),这也是一个正态分布,理论上可以直接用正态分布间KL散度的解析解来求,但是更直观的,后者的方差也是固定的,优化的方法直接让 P ( x t − 1 ∣ x t ) P(x_{t-1}|x_t) P(xt−1∣xt)的均值更接近 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)就行。
这里重新整理一下重建的过程:
首先先有一个 x T x_T xT是从标准正态分布中随机采样出来的noise map
把它送到UNet估计出一个 z ~ \tilde z z~(在原论文中,直接表示为 ϵ θ \epsilon_\theta ϵθ)
然后根据
可以计算出 x T − 1 x_{T-1} xT−1,同样的可以基于此和UNet再进行一个预测。
一直向前推,直到推到 x 0 x_0 x0
问题:为什么重建的过程中还要加噪声 z \bf z z?这是为了增加不确定性(模拟热运动),注意,在最后一步生成 x 0 x_0 x0的过程中,是不用加这个噪声的。
李宏毅的课堂解释:生成过程中需要一个“Sampling”的过程!如在NLP中,如果一直选择最优的概率密度的位置,会出现“跳针”即不断循环重复的现象,声音合成也是。他的团队进行了一个实验,发现生成过程中如果不加噪声,生成结果是非常差的:
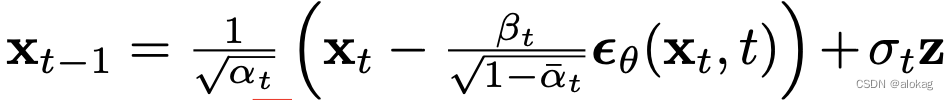
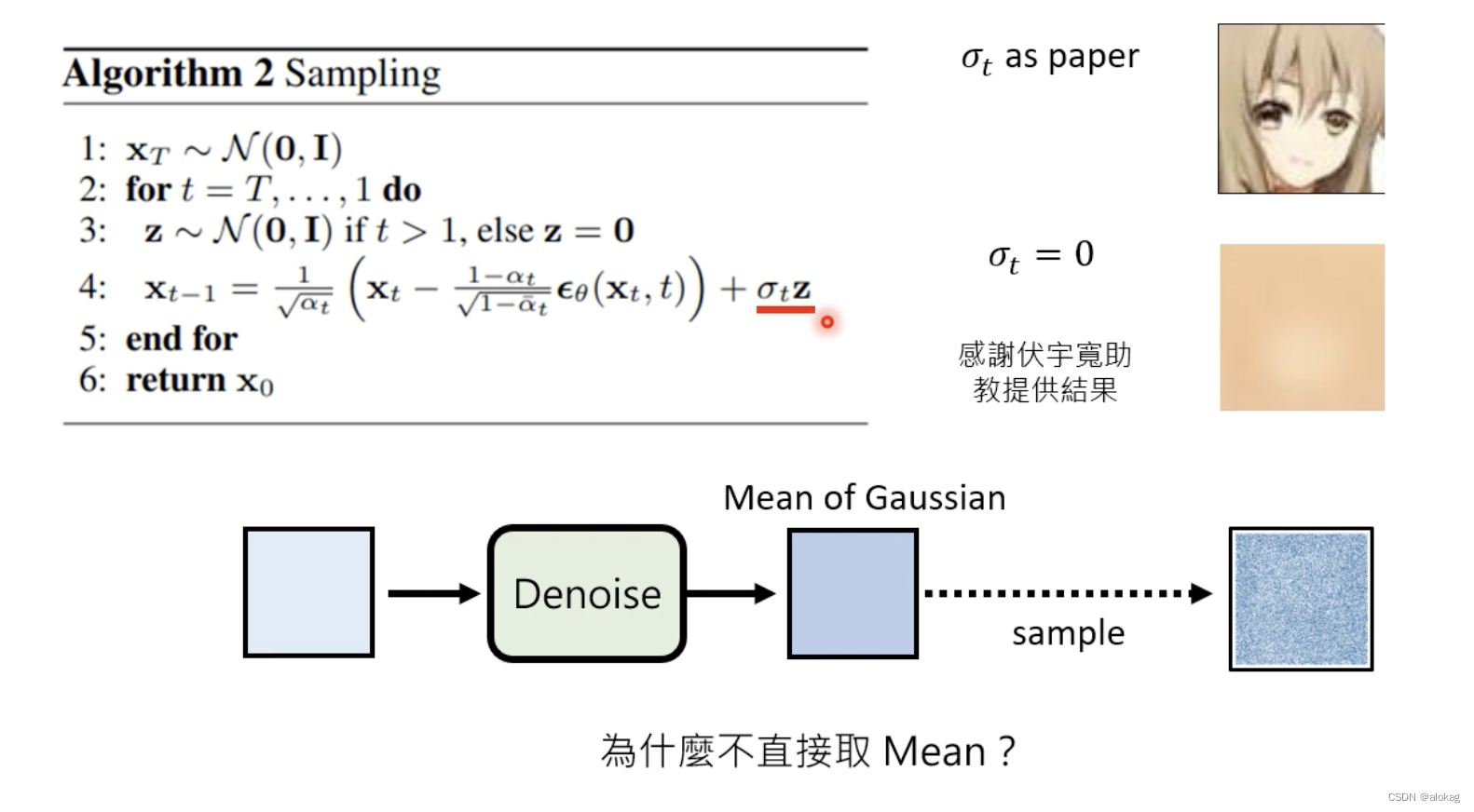
最后整理一下
- 扩散的过程:可以一步到位直接从 x 0 x_0 x0退化到 x t x_t xt,但是也有从 x t − 1 x_{t-1} xt−1到 x t x_t xt的单步退化公式。这个公式也可以用正态分布的均值和方差进行表示。
- 重建过程:每一步的过程可以视为 x t − 1 = f ( x t , UNet ( x t , t ) ) x_{t-1}=f(x_t,\text{UNet}(x_t,t)) xt−1=f(xt,UNet(xt,t)),将 x t − 1 x_{t-1} xt−1也当作一个分布,可以根据条件概率公式,推导出来一个基于 x t x_t xt的估计(先估计一个从UNet出来的yi)
- 训练过程:训练的过程其实就是训练这个UNet,基于本身的 x t , t x_t,t xt,t和原本采样的 z z z或 ϵ \epsilon ϵ来做l2-loss。
代码阅读与实现(坑)
这部份参考的代码是https://github.com/abarankab/DDPM
预定义参数
# diffusion.py,定义每个部份
alphas = 1.0 - betas
alphas_cumprod = np.cumprod(alphas)
to_torch = partial(torch.tensor, dtype=torch.float32)
self.register_buffer("betas", to_torch(betas)) # beta序列
self.register_buffer("alphas", to_torch(alphas)) # alpha序列
self.register_buffer("alphas_cumprod", to_torch(alphas_cumprod)) # 累积积
self.register_buffer("sqrt_alphas_cumprod", to_torch(np.sqrt(alphas_cumprod)))
self.register_buffer("sqrt_one_minus_alphas_cumprod", to_torch(np.sqrt(1 - alphas_cumprod)))
self.register_buffer("reciprocal_sqrt_alphas", to_torch(np.sqrt(1 / alphas)))
self.register_buffer("remove_noise_coeff", to_torch(betas / np.sqrt(1 - alphas_cumprod)))
self.register_buffer("sigma", to_torch(np.sqrt(betas)))
# diffusion.py beta生成策略(cosine策略不做解释)
def generate_linear_schedule(T, low, high):
return np.linspace(low, high, T)
前向传播过程
# 损失函数
def get_losses(self, x, t, y):
noise = torch.randn_like(x) # 采样一个z
# 计算基于此的退化的x_t
perturbed_x = self.perturb_x(x, t, noise)
estimated_noise = self.model(perturbed_x, t, y) # self.model 就是UNet,根据输入的x_t和t来进行噪声预测
if self.loss_type == "l1":
loss = F.l1_loss(estimated_noise, noise)
elif self.loss_type == "l2":
loss = F.mse_loss(estimated_noise, noise)
# 基于不同范数进行损失计算
return loss
# 前向传播(从x_0到x_t)
def forward(self, x, y=None):
b, c, h, w = x.shape
device = x.device
# 判断合法性,可以忽略
if h != self.img_size[0]:
raise ValueError("image height does not match diffusion parameters")
if w != self.img_size[0]:
raise ValueError("image width does not match diffusion parameters")
# 任选一组t,然后调用getlosses
t = torch.randint(0, self.num_timesteps, (b,), device=device)
return self.get_losses(x, t, y)
推理过程
整个过程是从一个完全噪声图,推理到初始的 x 0 x_0 x0。整个过程是不需要梯度而是直接用模型进行推理的
@torch.no_grad()
def remove_noise(self, x, t, y, use_ema=True): # 去噪过程
if use_ema:
return (
(x - extract(self.remove_noise_coeff, t, x.shape) * self.ema_model(x, t, y)) *
extract(self.reciprocal_sqrt_alphas, t, x.shape)
)
else: # 用UNet进行去噪
return (
(x - extract(self.remove_noise_coeff, t, x.shape) * self.model(x, t, y)) *
extract(self.reciprocal_sqrt_alphas, t, x.shape)
)
@torch.no_grad()
def sample(self, batch_size, device, y=None, use_ema=True):
if y is not None and batch_size != len(y):
raise ValueError("sample batch size different from length of given y")
x = torch.randn(batch_size, self.img_channels, *self.img_size, device=device)
for t in range(self.num_timesteps - 1, -1, -1):
t_batch = torch.tensor([t], device=device).repeat(batch_size)
x = self.remove_noise(x, t_batch, y, use_ema)
# 最后加一个随机噪声
if t > 0:
x += extract(self.sigma, t_batch, x.shape) * torch.randn_like(x)
return x.cpu().detach()
UNet
从上面的步骤很容易能看出来,本质上训练的核心就是这一个model,网络的结构其实也只有这一个model,剩下的其实都是“推理过程”,这并不是网络结构,而训练的网络就是一个条件去噪网络,用来辅助进行图像复原的推理。但UNet整个的实现是很长的,这里直接从Forward函数来进行理解.
def forward(self, x, time=None, y=None):
# **time_emb**:如何做条件去噪的关键。time embedding是如何得到的?
ip = self.initial_pad
if ip != 0:
x = F.pad(x, (ip,) * 4)
if self.time_mlp is not None:
if time is None:
raise ValueError("time conditioning was specified but tim is not passed")
# time是本身的时间,time_mlp是一个定义的网络
# time_mlp{PositionalEmbedding查找-->Linear-->SiLU-->Linear}
# Positional Embedding 略
time_emb = self.time_mlp(time)
else:
time_emb = None
if self.num_classes is not None and y is None:
raise ValueError("class conditioning was specified but y is not passed")
x = self.init_conv(x) # 原始的卷积层
skips = [x]
for layer in self.downs: # 降采样
x = layer(x, time_emb, y)
skips.append(x) # 中间连接
for layer in self.mid: # 低分辨率层
x = layer(x, time_emb, y)
for layer in self.ups: # 上采样
if isinstance(layer, ResidualBlock):
x = torch.cat([x, skips.pop()], dim=1) # 连接
x = layer(x, time_emb, y)
x = self.activation(self.out_norm(x)) # 转化为输出
x = self.out_conv(x)
if self.initial_pad != 0:
return x[:, :, ip:-ip, ip:-ip]
else:
return x
一点实验结果
我自己在4090上花了4个小时训练了一个cifar10的推理模型(80000次迭代)
最后改了一下推理的可视化,将其每一步的推理可视化,最后成图如下:

太神奇了!
VQGAN: Taming transformers for high-resolution image synthesis(CVPR 2021)
紧急在LDM前插播一个VQGAN,因为LDM用到了VQ GAN进行图像压缩。这篇工作不细讲原理和理论推导,主要讲讲思想,以及怎么用和实验效果。
motivation & contribution
首先从图像生成方面来看。本文的想法是结合卷积神经网络更关注局部关联性以及transformer能够生成高精度图像的优势,来设计一个强有力的神经网络。
卷积网络:具有平移不变形和局部性(卷积网络的归纳偏置),更好的能够表示局部关系
transformer:没有这种归纳偏置,自注意力机制让transformer 直接进行全局建模和学习,带来了很大的计算负担。
于是在模型结构层面,提出了问题:能否在保留Transformer的灵活性的同时,可以有效的编码图像的偏置?
VQ-GAN的做法是,首先采用一个CNN,基于GAN来构建一个词典,然后基于Transformer来学习视觉词典的组合。最终的方法既能够超过CNN的方法,也能超过VQ-VAE。
还有一个思路产生的点是从VQ-VAE来的,VQ-VAE可以看做VQGAN的前作。作者在VQVAE这种纯CNN的方法基础上进行了两个改进:1. 图像压缩算法改进,原本VQVAE的图像压缩复原采用的是一个简单的均方误差,本工作中改为了GAN对抗损失;2. 在生成任务本身上,Transformer的全局感知能力使其在像素级生成上的表现比CNN更好(PixelCNN呢?)
方法设计
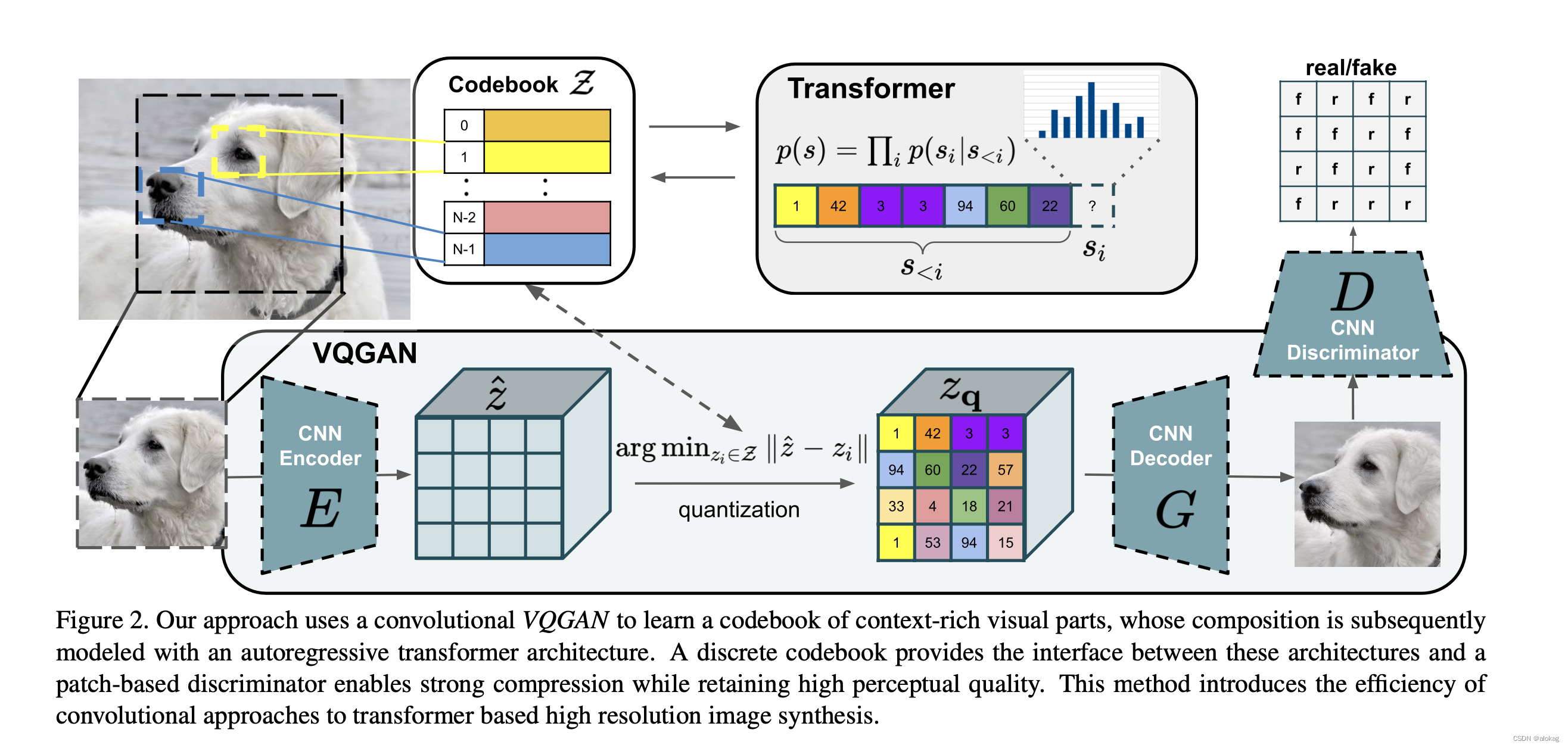
codebook学习
要利用Transformer进行学习,首先需要做的就是序列化,也就是需要将图像用序列进行表示。而为了降低复杂度,采用了codebook的方法。这样可以将原本
x
∈
R
H
×
W
×
3
x\in \mathbb R^{H\times W\times 3}
x∈RH×W×3降维到
z
q
∈
R
h
×
w
×
n
z
z_{\bf q}\in \mathbb R^{h\times w\times n_z}
zq∈Rh×w×nz,这部份和VQ-VAE说一样的。
注意这里Decoder用的是
G
G
G进行表示:VQGAN采用了GAN的方法来学习codebook(codebook内的结构并没有变,前向过程也是argmin的过程,反向传播也是用了梯度连接的方法,可以看我之前的VQVAE的文章)。回到上面的框架图中,经过了编码器,vq结构和解码器,有重构的图像
x
^
=
G
(
z
q
)
=
G
(
q
(
E
(
x
)
)
)
\hat x=G(z_{\bf q})=G(q(E(x)))
x^=G(zq)=G(q(E(x)))。而VQGAN在此基础上,提出了需要训练判别器
D
D
D,从而在原本VQ-VAE的重构损失+codebook的两个损失的基础上,引入了一个adversarial loss:
L
GAN
(
{
E
,
G
,
Z
}
,
D
)
=
[
log
D
(
x
)
+
log
(
1
−
D
(
x
^
)
)
]
L_{\text {GAN}}(\{E,G,Z\},D)=[\log D(x)+\log(1-D(\hat x))]
LGAN({E,G,Z},D)=[logD(x)+log(1−D(x^))]
最终的损失函数是综合了两个loss:
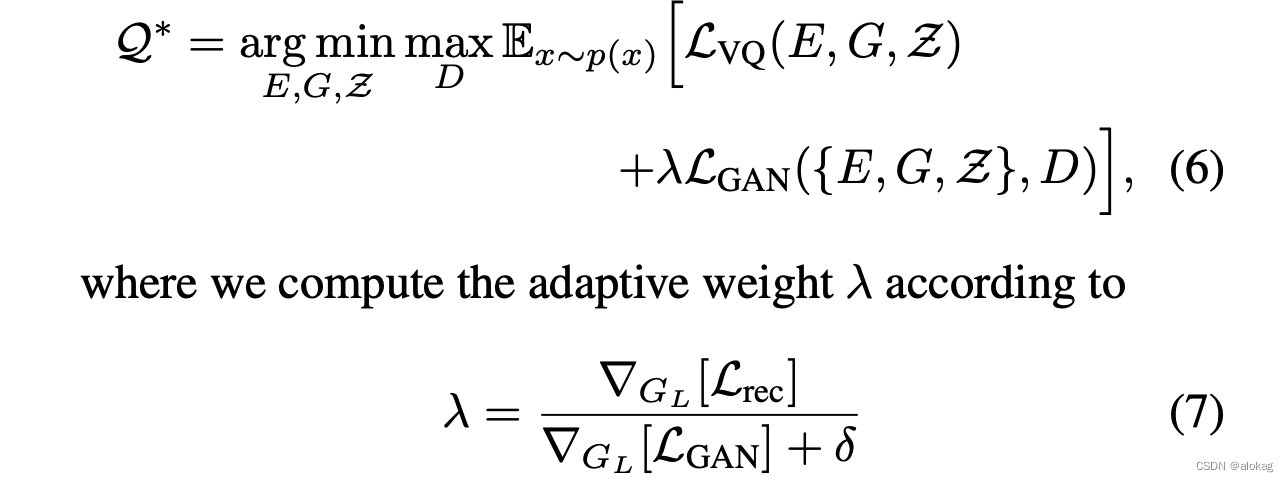
其中的适应性参数是基于重构损失和GAN损失的梯度进行计算的。
这里很多的文章都没怎么讲:其实上述公式中的 L rec \mathcal L_{\text {rec}} Lrec是感知损失(perceptual loss),这是利用LPIPS感知损失来计算原本的图像和decode出的图像的差别,然后用做lambda的放缩因子。
lambda最后会进行梯度裁剪后作为无梯度常数存在,也就是说这个损失并不是很直接的作用在学习过程中,主要的影响还是对抗损失。
具体的,VQGAN中的Encoder和Decoder是拆分的UNET结构,UNET有较好的像素级生成能力,所以这样的设计也很合理。
Latent Transformer
这个在原本的基础上,和VQ-VAE一样,这个训练也是一个两阶段的训练过程,即先训练一个VQ和AE结构,再基于VQ的模型生成一个生成模型(VQ- VAE中采用了自回归模型中的pixel CNN,通过特殊的卷积核实现像素级的推理)。而VQGAN采用的是更新的Transformer结构来实现自回归的预测。
这里就需要学习之前一直都在纠结的一个问题:如何用transformer来进行图像生成呢?这里现从NLP的方面来进行考虑,在NLP中,单词会被tokenize,然后Transformer通过生成词token就可以生成句子。那图像的话,自然可以将单词变成像素序列,VQGAN就是直接将图像自左到右自上而下的平整化然后一个个进行生成,每次生成依靠前面所有像素的全局来进行生成。
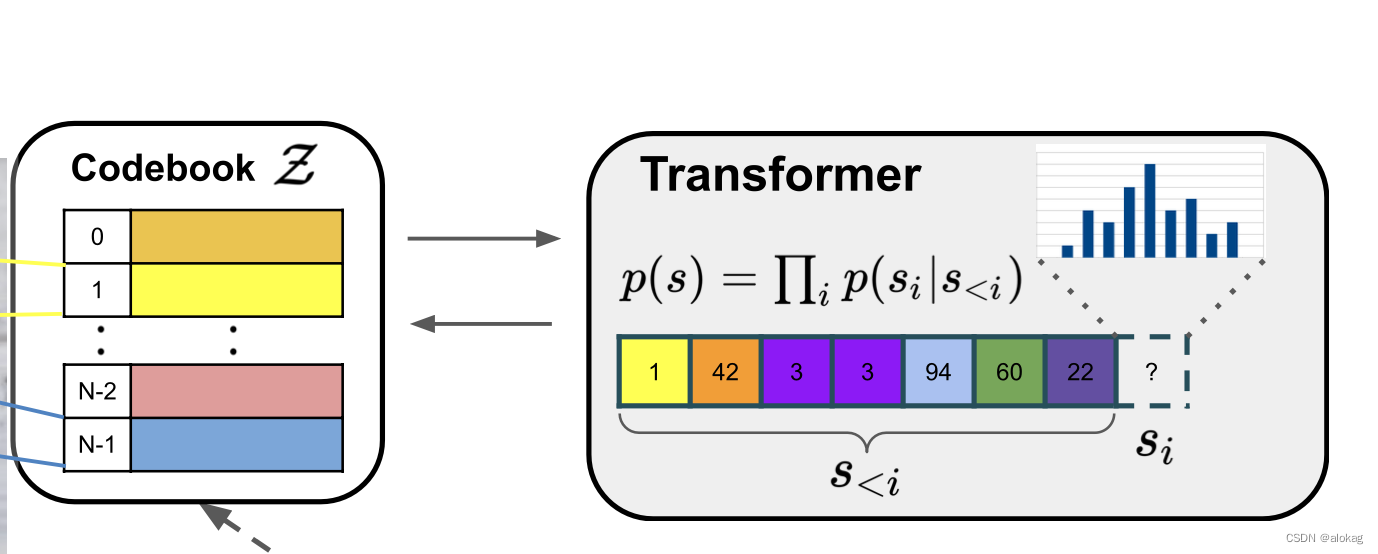
基于约束的生成
此部分略
高清图像生成
Transformer固然能够生成高清图像,但是很明显的是,高清图像如果直接按照原本分辨率进行生成的话,会有很大的开销,所以就如上图所示的,本文中的Transformer是在VQ的序列上进行生成的。经过本身VQGAN的encoder后,会变成 16 × 16 × n z 16\times 16\times n_z 16×16×nz的词化的图。假设边长压缩了 f f f倍,则最终生成的图像大小为 16 f × 16 f 16f\times 16f 16f×16f。在实验中 f = 16 f=16 f=16的效果比较好,但是仅仅生成256*256的图像完全不够。
作者的做法是先训练一个256*256的VQGAN和Transformer的组合,然后再用一个滑动窗口Transformer的采样机制来生成更大的图像。
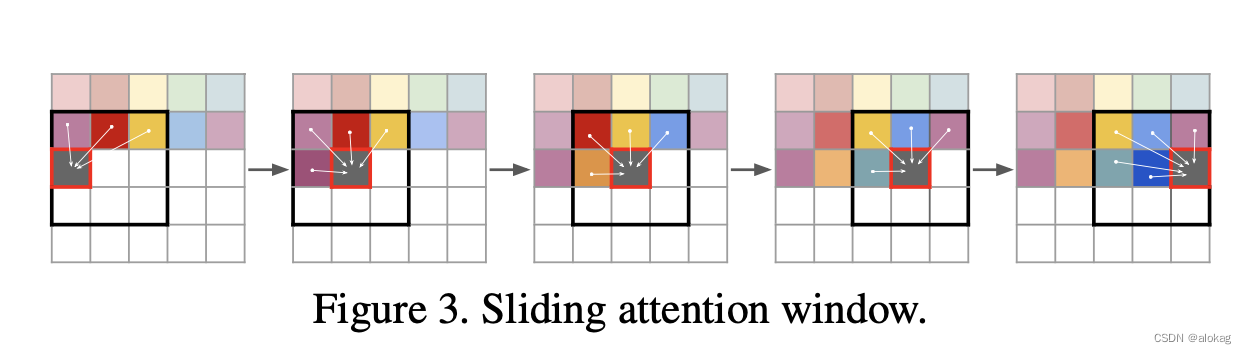
如上图,依靠框起来的3*3的窗口,在窗口内依靠窗口内已有的像素对新的像素进行推理。而实际实现时,是将待生成图片划分为若干16*16像素对图块,而每个图块对应压缩图像的一个像素。用于生成的Transformer,本文采用了GPT2模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









