







Redis学习
一:单机redis安装
首先需要安装Redis所需要的依赖:
yum install -y gcc tcl
然后准备redis安装包上传到服务器后解压
tar -xzf redis-6.2.4.tar.gz
进入redis目录:
cd redis-6.2.4
运行编译命令:
make && make install
如果没有出错,应该就安装成功了。
然后修改redis.conf文件中的一些配置:
# 绑定地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问
bind 0.0.0.0
# 保护模式,关闭保护模式让其他地方可以访问
protected-mode no
# 数据库数量,设置为1,将16个变成1个
databases 1
启动Redis:
redis-server redis.conf
停止redis服务:
redis-cli shutdown
二:主从集群
我们搭建的主从集群结构如图:

共包含三个节点,一个主节点,两个从节点。
这里我们会在同一台虚拟机中开启3个redis实例,模拟主从集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | slave |
| 192.168.150.101 | 7003 | slave |
1.准备实例和配置
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
1)创建目录
我们创建三个文件夹,名字分别叫7001、7002、7003:
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir 7001 7002 7003
2)拷贝配置文件到每个实例目录
然后将redis-6.2.4/redis.conf文件拷贝到三个目录中(在/tmp目录执行下列命令):
# 方式一:逐个拷贝
cp redis-6.2.4/redis.conf 7001
cp redis-6.2.4/redis.conf 7002
cp redis-6.2.4/redis.conf 7003
# 方式二:管道组合命令,一键拷贝
echo 7001 7002 7003 | xargs -t -n 1 cp redis-6.2.4/redis.conf
3)修改每个实例的端口、工作目录
修改每个文件夹内的配置文件,将端口分别修改为7001、7002、7003,将rdb文件保存位置都修改为自己所在目录(在/tmp目录执行下列命令):
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/7001\//g' 7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf
4)修改每个实例的声明IP
虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息,格式如下:
# redis实例的声明 IP
replica-announce-ip 192.168.150.101
每个目录都要改,我们一键完成修改(在/tmp目录执行下列命令):
# 逐一执行
sed -i '1a replica-announce-ip 192.168.150.101' 7001/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' 7002/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' 7003/redis.conf
# 或者一键修改
printf '%s\n' 7001 7002 7003 | xargs -I{} -t sed -i '1a replica-announce-ip 192.168.150.101' {}/redis.conf
2.启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个
redis-server 7001/redis.conf
# 第2个
redis-server 7002/redis.conf
# 第3个
redis-server 7003/redis.conf
启动后:

如果要一键停止,可以运行下面命令:
printf '%s\n' 7001 7002 7003 | xargs -I{} -t redis-cli -p {} shutdown
3.开启主从关系
现在三个实例还没有任何关系,要配置主从可以使用replicaof 或者slaveof(5.0以前)命令。
有临时和永久两种模式:
-
修改配置文件(永久生效)
- 在redis.conf中添加一行配置:
slaveof <masterip> <masterport>
- 在redis.conf中添加一行配置:
-
使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof <masterip> <masterport>
注意:在5.0以后新增命令replicaof,与salveof效果一致。
这里我们为了演示方便,使用方式二。
通过redis-cli命令连接7002,执行下面命令:
# 连接 7002
redis-cli -p 7002
# 执行slaveof
slaveof 192.168.150.101 7001
通过redis-cli命令连接7003,执行下面命令:
# 连接 7003
redis-cli -p 7003
# 执行slaveof
slaveof 192.168.150.101 7001
然后连接 7001节点,查看集群状态:
# 连接 7001
redis-cli -p 7001
# 查看状态
info replication
结果:

4.测试
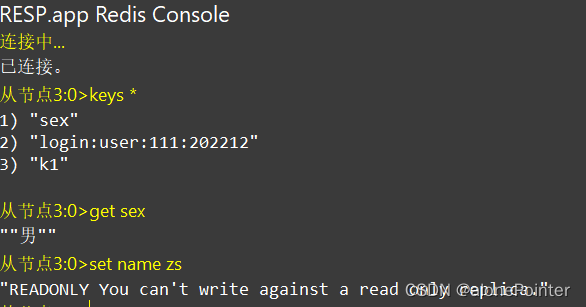
执行下列操作以测试:
-
利用redis-cli连接7001,执行
set num 123 -
利用redis-cli连接7002,执行
get num,再执行set num 666 -
利用redis-cli连接7003,执行
get num,再执行set num 888
可以发现,只有在7001这个master节点上可以执行写操作,7002和7003这两个slave节点只能执行读操作。
三.springboot 整合主从集群
1 添加基本依赖和自定义配置
pom.xml 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>3.0.1</version>
</dependency>
yml 添加redis正常配置和 自定义主从配置
spring:
redis:
database: 0
lettuce:
pool:
max-active: 8
max-wait: -1ms
min-idle: 0
# 保留这个使redis其他方法依旧可用
host: 192.168.0.160
port: 7001
# 自定义主从配置
redis:
ms:
redis-master:
host: 192.168.0.160
port: 7001
password:
redis-slaves:
- host: 192.168.0.160
port: 7002
password:
- host: 192.168.0.160
port: 7003
password:
2 读取配置
bean 创建用于接受redis配置参数的对象 和 读配置的对象
//从
@Data
public class RedisSlave {
private String host;
private Integer port;
private String password;
// 其它参数...
}
// 主
@Data
public class RedisMaster {
private String host;
private Integer port;
private String password;
// 其它参数...
}
//从 yml 当中读取具体配置
import com.***.RedisMaster;
import com.***.RedisSlave;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import java.util.List;
@ConfigurationProperties(prefix = "redis.ms")
@Data
public class RedisMasterSlavesProperties {
// 主机
private RedisMaster redisMaster;
// 从机
private List<RedisSlave> redisSlaves;
}
config 进行redis的配置
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.***.RedisMaster;
import com.***.RedisSlave;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.connection.RedisStandaloneConfiguration;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.util.ArrayList;
import java.util.List;
@Configuration
@EnableConfigurationProperties({RedisMasterSlavesProperties.class})
public class RedisZCConfig {
/**
* Master主机 template
*
* @param properties 配置
*/
@Bean("redisMasterTemplate")
public RedisTemplate<String, Object> redisMasterTemplate(RedisMasterSlavesProperties properties) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
// master
RedisMaster master = properties.getRedisMaster();
// 连接工厂
RedisConnectionFactory factory = connectionFactory(master.getHost(), master.getPort(), master.getPassword());
redisTemplate.setConnectionFactory(factory);
// 序列化
return serializerTemplate(redisTemplate);
}
/**
* Slaves从机 template
*
* @param properties
* @return
*/
@Bean("redisSlaveTemplateList")
public List<RedisTemplate<String, Object>> redisSlaveTemplateList(RedisMasterSlavesProperties properties) {
List<RedisTemplate<String, Object>> redisTemplates = new ArrayList<>();
for (RedisSlave slave : properties.getRedisSlaves()) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
// 连接工厂
RedisConnectionFactory factory = connectionFactory(slave.getHost(), slave.getPort(), slave.getPassword());
redisTemplate.setConnectionFactory(factory);
// 序列化并放置集合
redisTemplates.add(serializerTemplate(redisTemplate));
}
return redisTemplates;
}
/**
* 创建连接工厂
*
* @param host
* @param port
* @param password
*/
private RedisConnectionFactory connectionFactory(String host, Integer port, String password) {
RedisStandaloneConfiguration redisStandaloneConfig = new RedisStandaloneConfiguration(); // 设置标准配置信息
redisStandaloneConfig.setHostName(host); // 主机
redisStandaloneConfig.setPort(port); // 端口
if (password != null && !password.equals("")) // 密码
redisStandaloneConfig.setPassword(password);
// 这里自定义创建 LettuceConnectionFactory
LettuceConnectionFactory factory = new LettuceConnectionFactory(redisStandaloneConfig);
factory.afterPropertiesSet(); // 其它参数设置
return factory;
}
/**
* 序列化配置
*
* @param redisTemplate
* @return
*/
private RedisTemplate<String, Object> serializerTemplate(RedisTemplate<String, Object> redisTemplate) {
// Json序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
// String的序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key采用String的序列化方式
redisTemplate.setKeySerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
redisTemplate.setHashKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
// hash的value序列化方式采用jackson
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
3 工具类和使用
utlis 简单的读写分离工具类
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* 主机Master 只进行写操作, 从机Slave 只进行读操作
*
* @author xgk
* @date
*/
@Component
public class RedisUtils {
// 主机
@Autowired
@Qualifier("redisMasterTemplate")
public RedisTemplate<String, Object> redisMasterTemplate;
// 从机
@Autowired
@Qualifier("redisSlaveTemplateList")
public List<RedisTemplate<String, Object>> redisSlaveTemplateList;
private int slaveIndex = 0;
// 选择用那台从机(通过取余方式决定)
private int buildSlaveIndex() {
this.slaveIndex++;
return this.slaveIndex % 2;
}
// 定义的写操作方法 ------------------------------------------
public boolean set(String key, Object value) {
try {
redisMasterTemplate.opsForValue().set(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
// 定义的读操作方法 ------------------------------------------
public Object get(String key) {
return key == null ? null : redisSlaveTemplateList.get(buildSlaveIndex()).opsForValue().get(key);
}
}
service 使用
@Autowired
private RedisUtils redisUtils;
@GetMapping("/test")
public Object test(){
redisUtils.set("sex","男");
Object object = redisUtils.get("sex");
return object;
}
四: 灾难恢复
灾难恢复是指当我们的master挂掉了之后,这时我们需要先做的步骤如下:
1. 首先停掉从库的复制关系,slaveof no one
2. 重试重启主库,看看数据有没有丢失,如果有丢失的话,需要把从库的数据文件拷贝到主库中,然后再启动主库
3. 当主库启动完毕之后,看看主从数据是否一致,如果是一致的话,那么我们就可以在去从库中开启对主库的复制:slaveof host:port
五.主从数据同步原理
1.全量同步
主从第一次建立连接时,会执行全量同步,将master节点的所有数据都拷贝给slave节点,流程:

这里有一个问题,master如何得知salve是第一次来连接呢??
有几个概念,可以作为判断依据:
- Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据。
因为slave原本也是一个master,有自己的replid和offset,当第一次变成slave,与master建立连接时,发送的replid和offset是自己的replid和offset。
master判断发现slave发送来的replid与自己的不一致,说明这是一个全新的slave,就知道要做全量同步了。
master会将自己的replid和offset都发送给这个slave,slave保存这些信息。以后slave的replid就与master一致了。
因此,master判断一个节点是否是第一次同步的依据,就是看replid是否一致。
完整流程描述:
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
主节点判断从节点数据集id不一致,全量同步
2.增量同步
全量同步需要先做RDB,然后将RDB文件通过网络传输个slave,成本太高了。因此除了第一次做全量同步,其它大多数时候slave与master都是做增量同步。
什么是增量同步?就是只更新slave与master存在差异的部分数据。如图:

那么master怎么知道slave与自己的数据差异在哪里呢?
2.1.repl_backlog原理
master怎么知道slave与自己的数据差异在哪里呢?
这就要说到全量同步时的repl_baklog文件了。
这个文件是一个固定大小的数组,只不过数组是环形,也就是说角标到达数组末尾后,会再次从0开始读写,这样数组头部的数据就会被覆盖。
repl_baklog中会记录Redis处理过的命令日志及offset,包括master当前的offset,和slave已经拷贝到的offset:

slave与master的offset之间的差异,就是salve需要增量拷贝的数据了。
随着不断有数据写入,master的offset逐渐变大,slave也不断的拷贝,追赶master的offset:

直到数组被填满:

此时,如果有新的数据写入,就会覆盖数组中的旧数据。不过,旧的数据只要是绿色的,说明是已经被同步到slave的数据,即便被覆盖了也没什么影响。因为未同步的仅仅是红色部分。
但是,如果slave出现网络阻塞,导致master的offset远远超过了slave的offset: 
如果master继续写入新数据,其offset就会覆盖旧的数据,直到将slave现在的offset也覆盖:

棕色框中的红色部分,就是尚未同步,但是却已经被覆盖的数据。此时如果slave恢复,需要同步,却发现自己的offset都没有了,无法完成增量同步了。只能做全量同步。

3.主从同步优化
主从同步可以保证主从数据的一致性,非常重要。
可以从以下几个方面来优化Redis主从就集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
4.小结
简述全量同步和增量同步区别?
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
- 增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
- slave节点断开又恢复,并且在repl_baklog中能找到offset时















 1650
1650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









