







引言
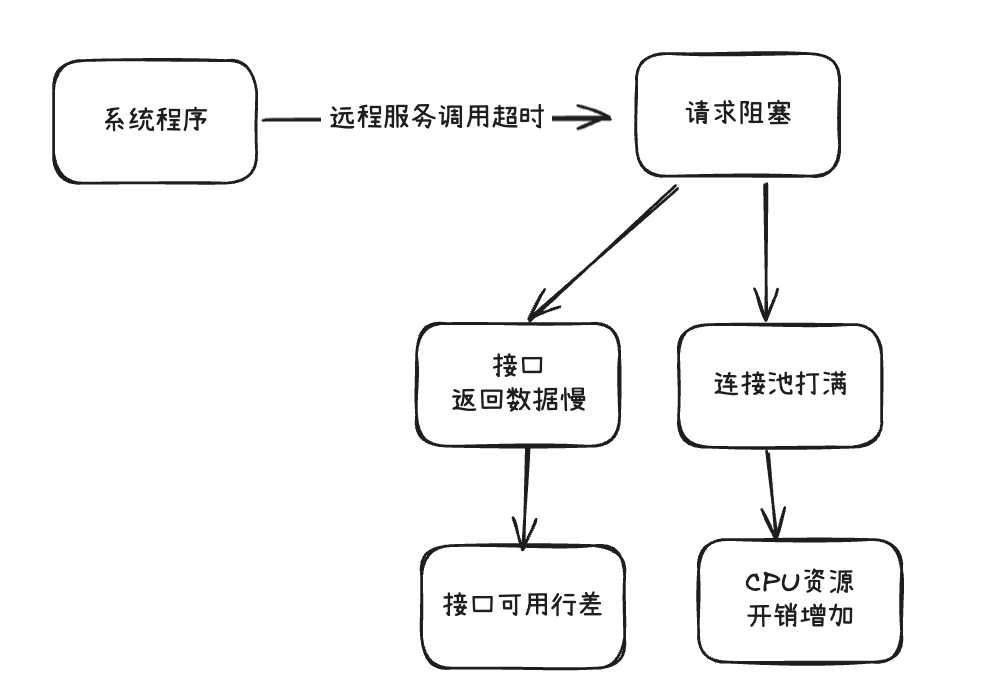
最近工作中,遇到了一些关于远程服务调用的问题,背景是调用三方接口获取某些特征数据,但由于调用出现了超时,导致业务本身的接口的可用行降低。因此整理一些远程服务调用时的注意事项,通过不同维度的考虑来提高系统稳定性。
什么是远程服务调用?
网络时代,系统通过网络请求调用另一个独立运行的服务以获取数据或执行特定操作的流程,就是网络调用。
进程间通信等不涉及网络传输等调用不在讨论范围。
超时
为了防止对方服务响应时间变长,导致拖慢我们自己的程序, 在调用远程服务的时候一定要配置超时时间或实现合适的超时机制;如果设置的超时时间不合理的话, 就会出现对方服务故障拖垮我们自己服务的尴尬情况。
常见的远程调用场景有
- 网络请求,请求外部接口获取数据或执行操作;
- 数据库查询,查询MySQL、Redis等数据库服务;
关于超时时间的设置,可以参考以下指标
超时时间 = 基础时间 × 波动系数 × 业务系数 × 网络系数
| 指标 | 作用 | 设置建议 |
|---|---|---|
| 平均响应时间 | 反映整体性能 | 超时时间 > 平均响应时间,但不宜过大 |
| P99延迟 | 反映极端情况 | 超时时间 ≈ 1.5-2倍P99延迟 |
| 业务特性 | 实时性、用户体验 | 高实时性业务超时时间短,低实时性业务超时时间长 |
容错机制
容错机制有两种,一种是针对单次调用的偶发情况:重试,在调用失败时,为了避免偶发情况的影响,可以考虑进行重试,再次请求看操作是否成功。还有针对全局情况,在失败情况过多时,快速失败,避免级联故障引起系统雪崩。
重试策略
- 重试间隔一般不要是固定间隔,比如重试三次,第一次300ms、第二次500ms、第三次1s;
- 一定要限制重试次数,防止出现雪崩效应,打垮对方服务。
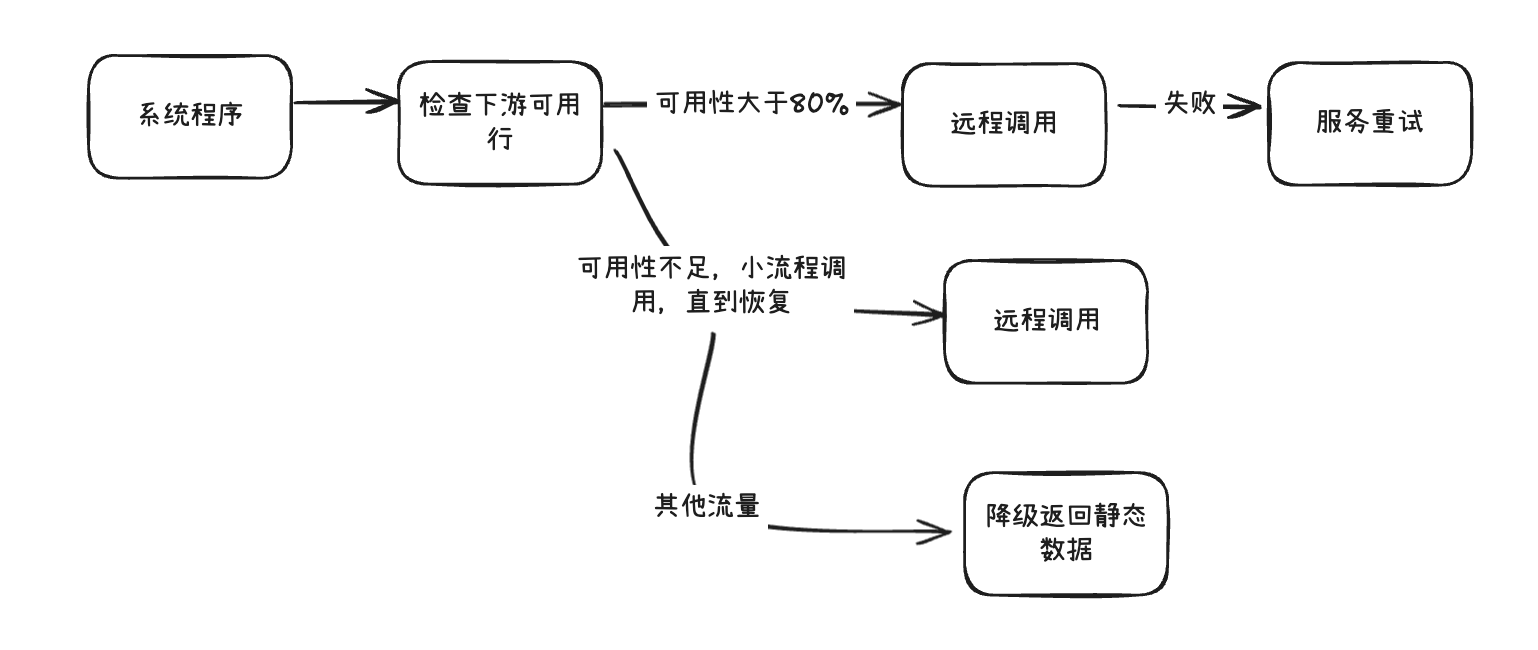
熔断机制
- 结合熔断器(如Hystrix),在下游服务可用性低于某个阈值时(如80%)快速失败,避免级联故障;
- 服务熔断后,调用前直接返回失败,少量请求试探服务是否可用,若试探成功(如请求成功率高于80%),恢复为关闭状态。
日志
当调用正常返回时,我们需要日志进行统计分析等操作;调用异常时,也需要记录错误描述方便定位排查,一般需要如下信息
- 调用的服务信息,比如请求的 url、ip、端口之类的;
- 请求参数,可以用于复现/debug 的相关请求参数;
- 失败原因,比如异常信息,根据需要区分不同的异常;
- 如果有响应返回的话,响应中包含的有用信息,比如 http 响应码、http response 中的有用信息等。
性能也要注意,使用连接池技术
对于远程服务调用,第一要考虑异常情况不会影响我们自己服务的稳定,另外就是要使用合适的技术来优化网络连接过程中的资源开销,比较有效的方式就是连接复用技术,即连接池。
通过复用连接,增加一些维护开销,减少连接创建、销毁对系统资源的浪费。
具体实现不赘述,这里列一些连接池的核心参数
| 参数 | 含义 | 设置建议 |
|---|---|---|
| 最大连接数 | 连接池允许的最大连接数量。 | - 高并发服务:根据服务器性能设置,如100-200。 - 低并发服务:50-100。 |
| 最小空闲连接数 | 保持的最小空闲连接数量。 | - 高并发服务:20-50。 - 低并发服务:5-10。 |
| 连接超时时间 | 获取连接的超时时间。 | - 核心服务:500ms-1s。 - 非核心服务:3s-5s。 |
| 空闲连接回收时间 | 空闲连接的最大存活时间。 | - 一般设置为30s-60s,避免长时间占用资源。 |
| 最大等待时间 | 等待可用连接的最大时间。 | - 避免长时间等待,建议设置为1-2秒。 |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











