






一.关于版本
1.python 3.9 (强烈建议使用3.9,因为3.11版本和3.8版本亲测不太好弄,3.11版本直接是失败了)
2.pytorch 最新版也行的
二.准备工作
1.在yolov5-master文件夹下新建文件夹test(可以自定义命名)

2.在test文件夹下新建三个文件夹,train,valid,test
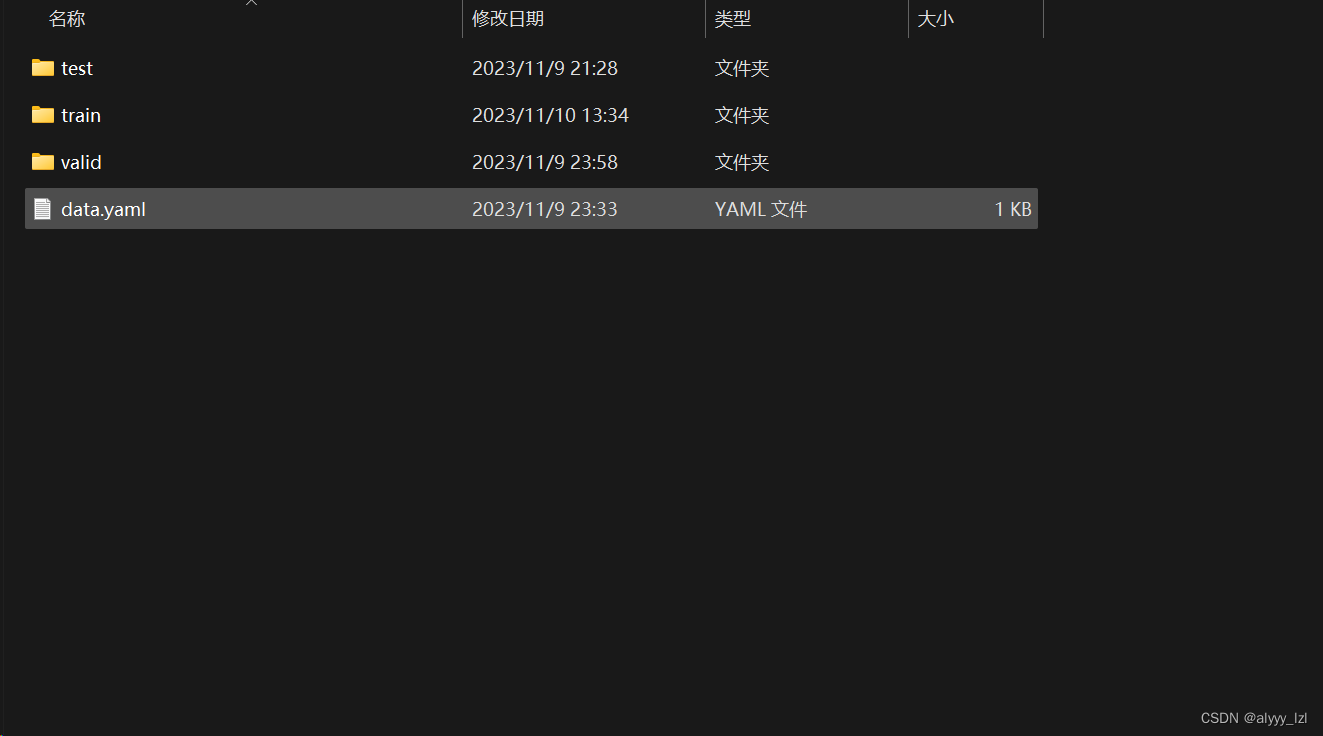
3.在这三个文件夹下分别建images和labels文件夹
-train文件夹用于存放训练图像
-valid文件夹用于存放测试图像
-test文件夹用于存放训练出的权重文件后,对一些未处理的图像进行操作
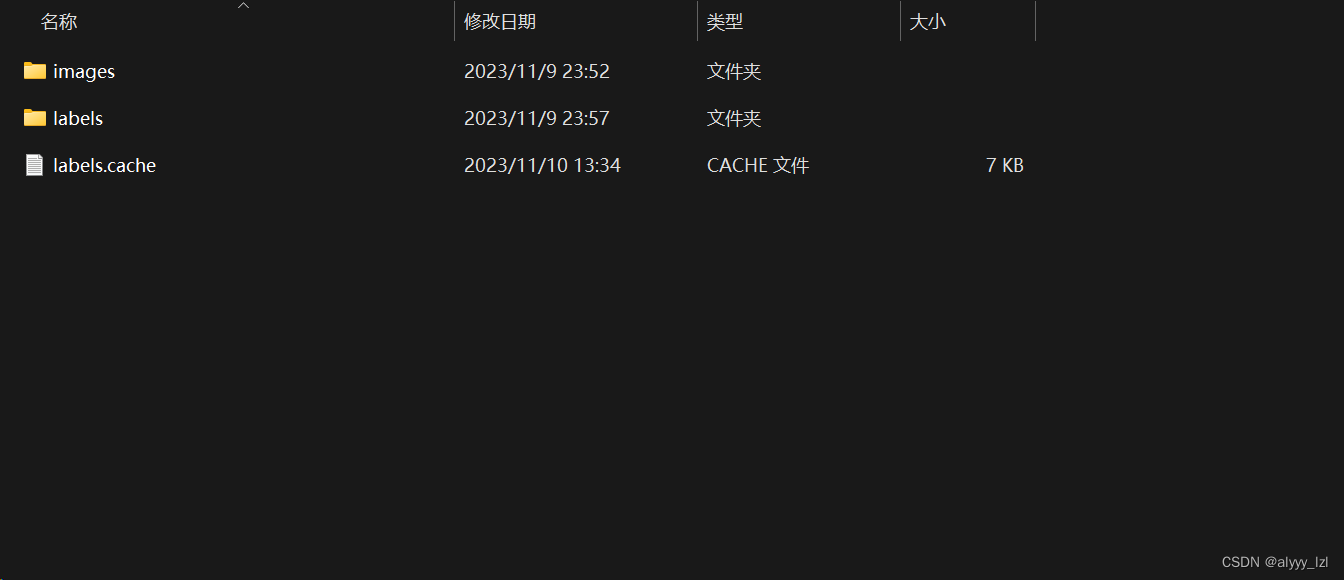
在这三个文件夹下,分别新建images和labels
-images用于存放未经处理的图像
-labels用于存放标记后的图像(下一步讲如何标记)
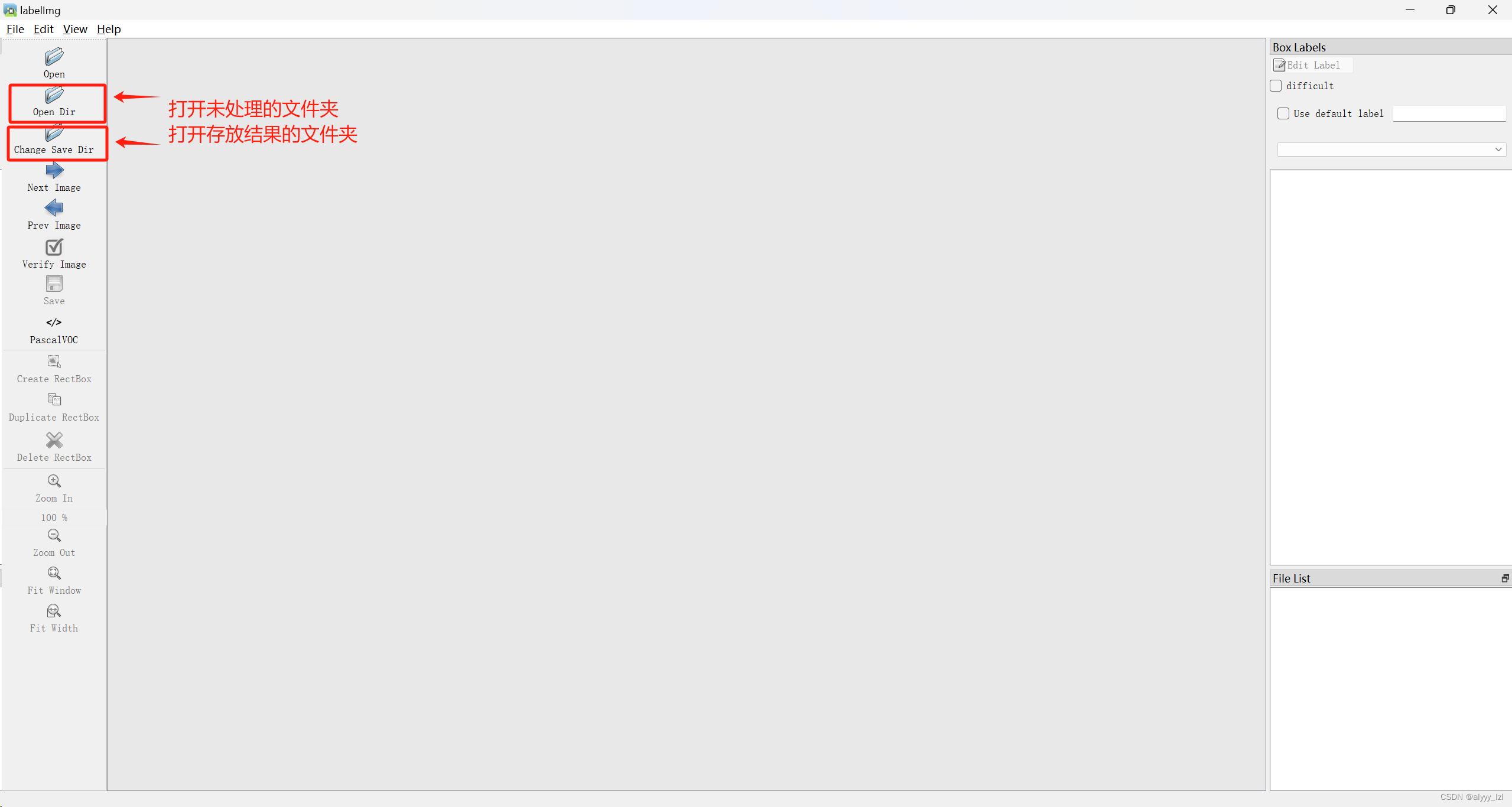
4.使用labelImg标记图像
1.安装labelImg
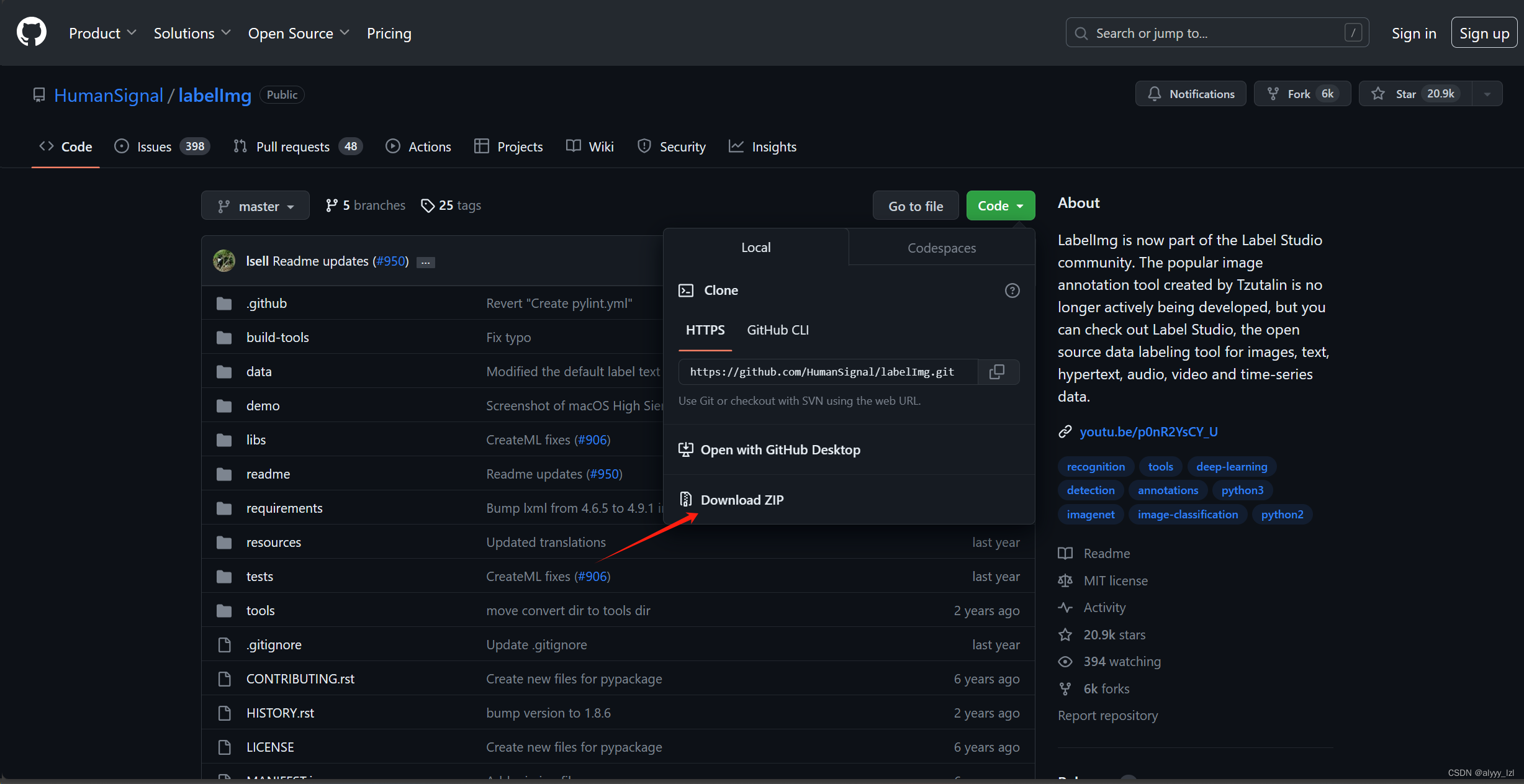
解压
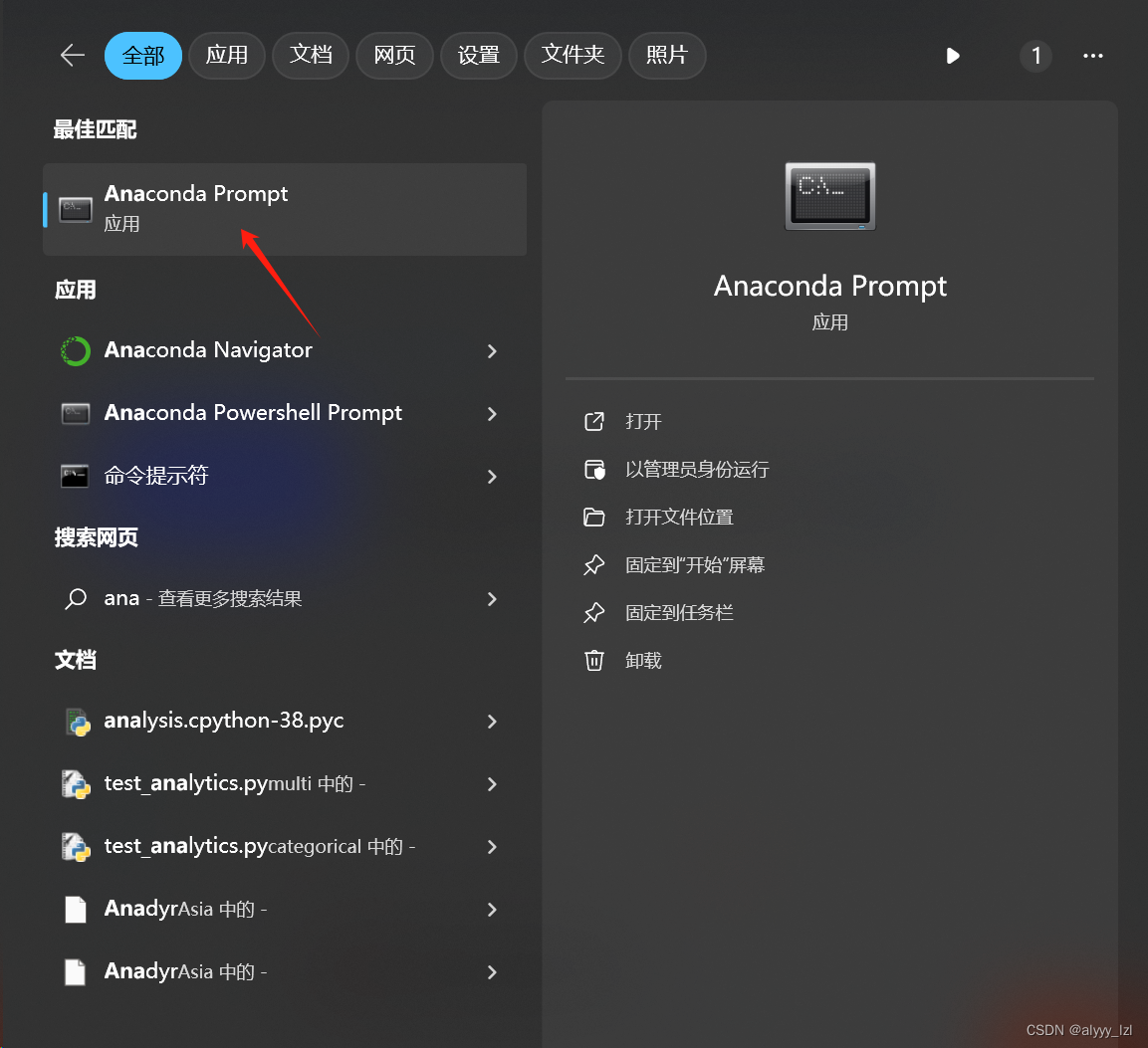 打开anaconda prompt
打开anaconda prompt
在命令行中输入以下指令
cd C:\labelImg-master
进入labelImg的文件夹
conda install pyqt=5
安装pyqt5
pyrcc5 -o libs/resources.py resources.qrc
运行此代码是没啥结果的,然后继续输入
python labelImg.py
就可以打开labelImg了
2.图像处理
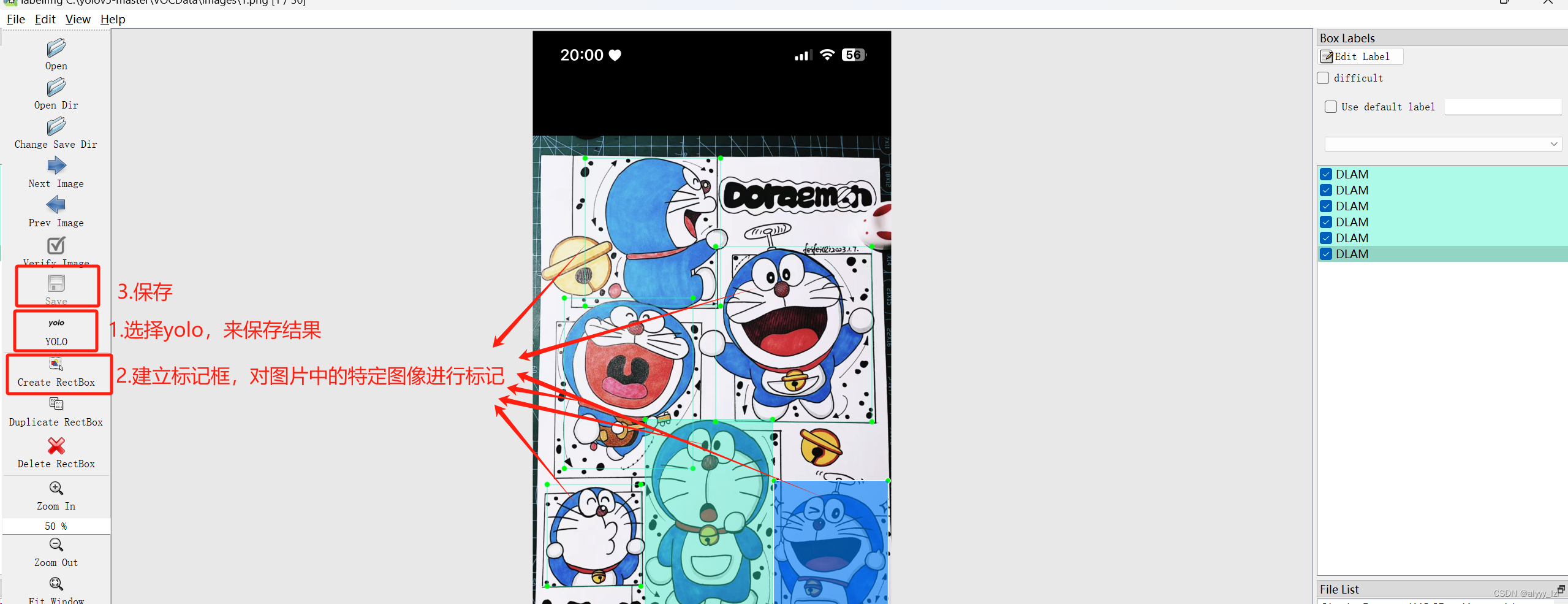
tips:
--在file目录下可选择自动保存,就很方便
--如果是多图像,切记右侧的命名要分开标
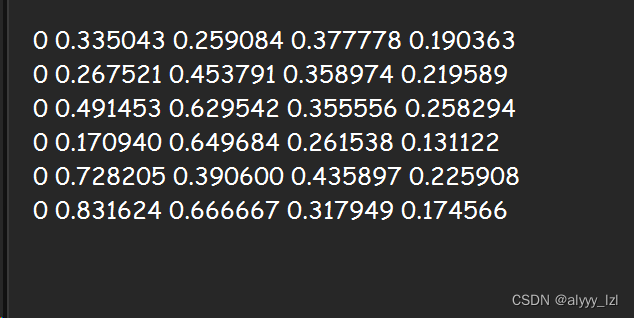
同时,只需要对train文件夹和valid文件夹下的图像进行处理,test不用,处理出来的是txt文件,具体如下图
3.配置文件的创建
在test文件夹下新建一个txt文件(填写完内容后要改成yaml文件的)
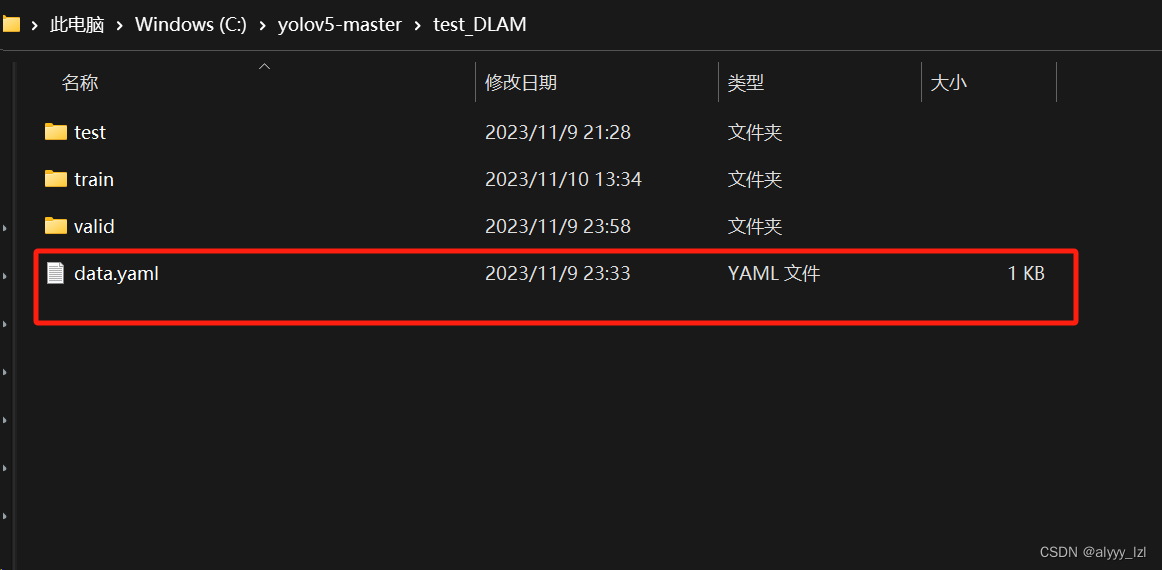
其中填写以下内容(记得要空格!!)
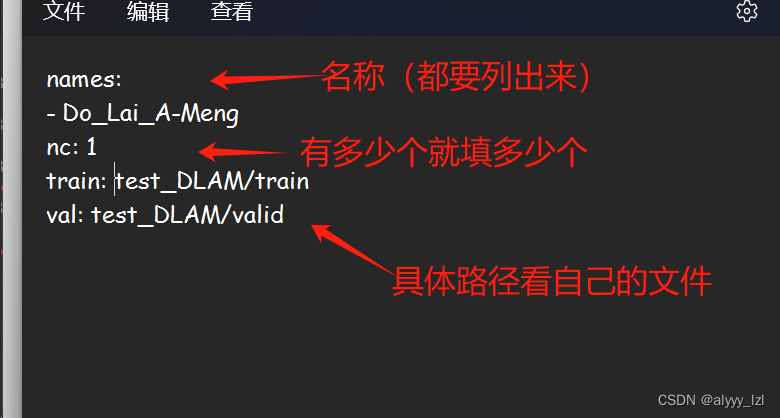
三.训练过程
打开spyder,打开train.py文件
在运行格下打开单文件配置选项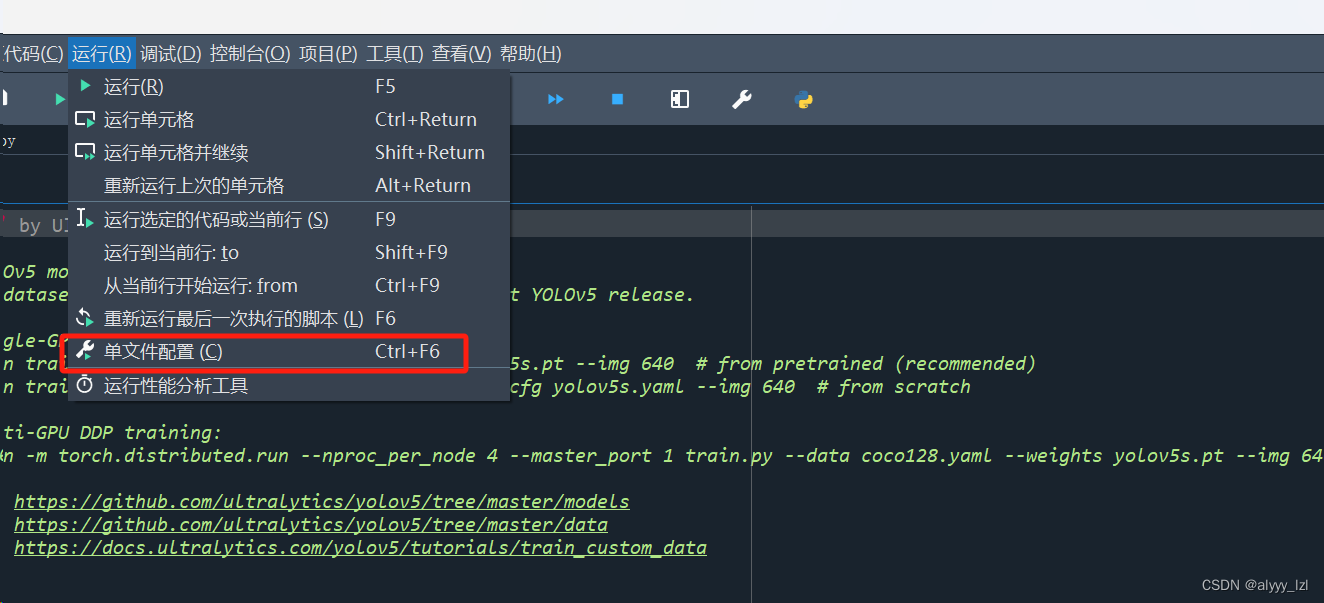
在这个格子里填上以下代码(具体路径要修改)
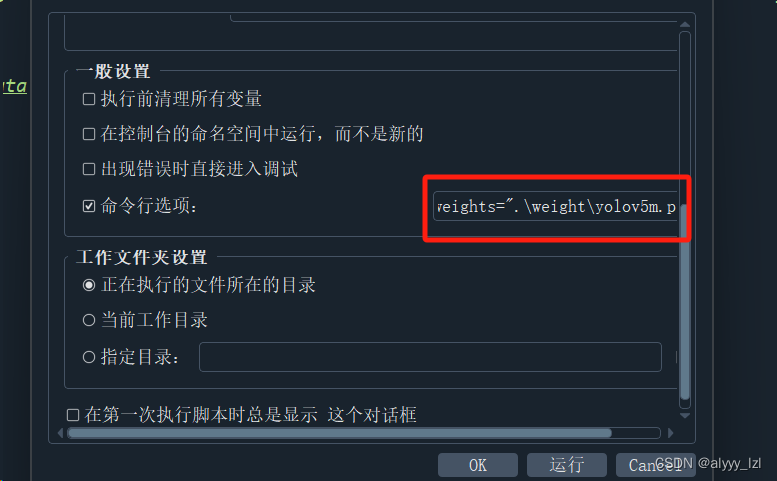
--batch-size="2" --epochs="200" --data="test_DLAM/data.yaml" --weights=".\weight\yolov5n.pt"处理好后点运行,等几个小时就可以弄出自己的权重文件辣!!!!
(后面会给出一些问题的解决方法)
四.自定权重文件的使用
到这里,基本就是成功了99%,接下来就是用用这个辛苦好久才训练出来的权重文件
1.打开detect.py文件,还是在运行框下,点击单文件配置,并输入以下命令
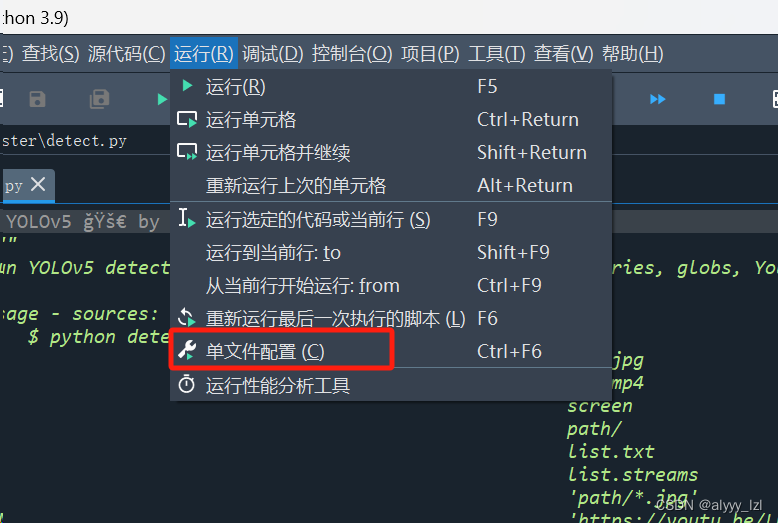
--source=".\test_DLAM\test" --weights=".\runs\train\exp\weights\best.pt"注意:这里的“exp”是假定你的train文件夹下只有一个测试结果,如果有多的结果,就以你的文件夹名为标准
等它顺利跑完
至此,已经成功!
恭喜你,完成了这项操作!
五.一些遇到的问题
其实,很多问题都没有办法只看我的博客解决,因为在完成此项任务的时候,我一直报错,折磨了我三天,所以我下了很多东西,很多我都不知道干啥用的,我估计,也有很多问题,是我瞎下的时候弄好的,现在给出一些我知道的问题的解决方法
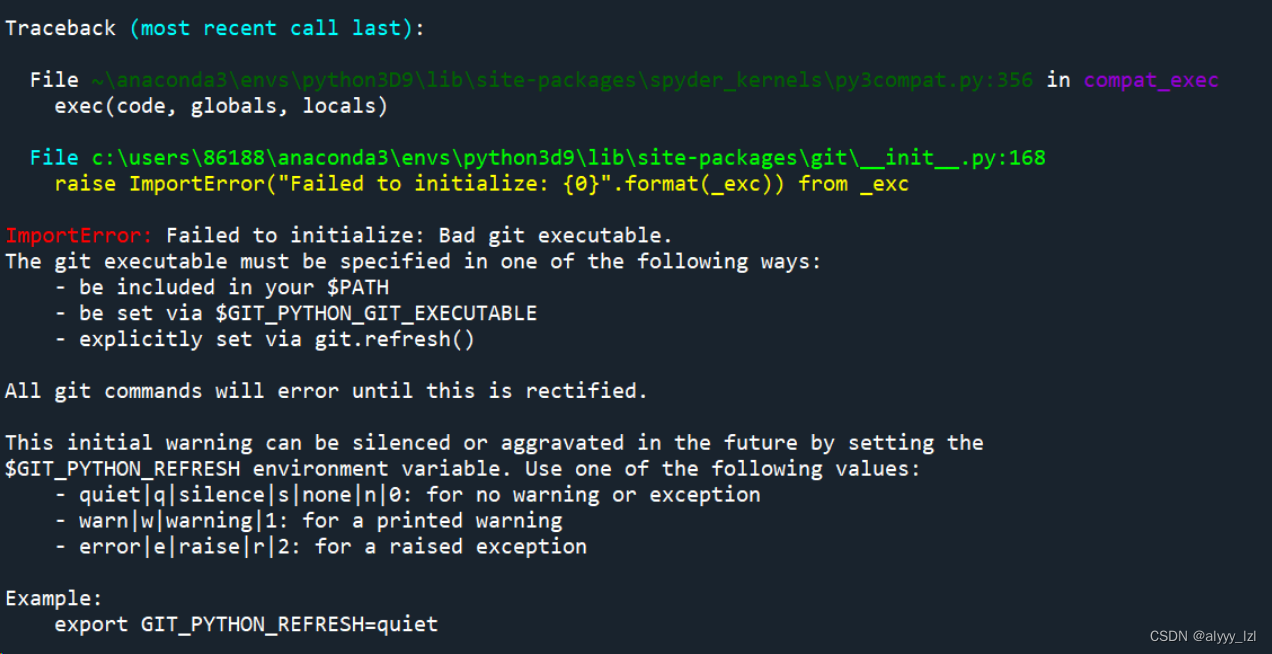
这里,应该是你的git没下载好,建议重下,同时,把那个example找个地方塞进去(我忘了放在哪了...)
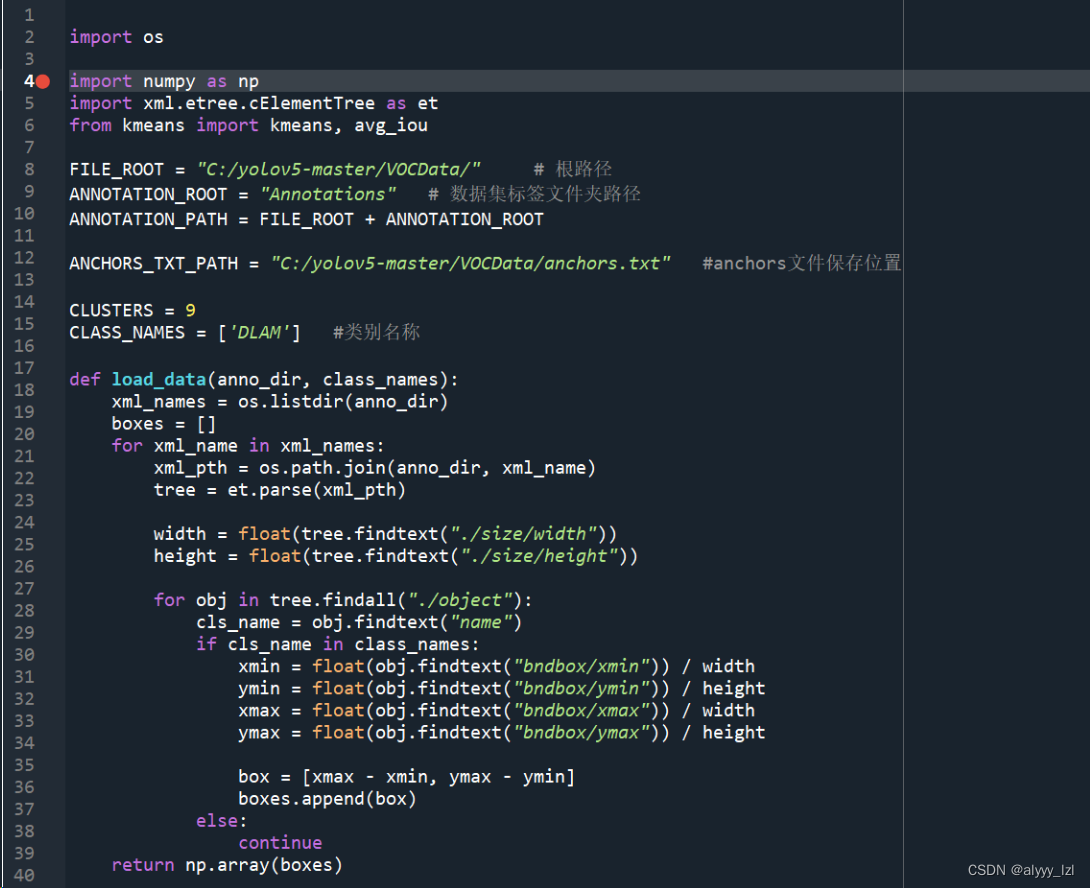
如果出现某一段很正常的语句报错,那就有可能下载出了问题(pip下载的话,是有概率下载不全的,因为如果你的磁盘空间不足,或者下载的时候断了网之类的,就会下载不全),这边建议删了重下,如果还不行,那你就比较倒霉了,我也经历过这个,我是重新弄了个虚拟环境,然后把那些要下的包全都再下了一次(所以我现在有四个python...)
还有,出现这种的
ImportError: cannot import name 'classproperty' from 'torch._utils可能是pytorch没下好,也有可能是版本没对上
如果是labelImg一直闪退,那很可能是python版本不行,我也试过,3.11版本的python环境打开的labelImg一直闪退,所以我开头就说用3.9的比较好,起码不闪退
还有一些问题,例如不断陷入内核重启啊,找不到指定模块啊,某个参数找不到之类的,我也没办法一一给出解决方法,具体可以去chat一下,挺不错的
完结撒花!!!
终于,我这三天完成任务的心路历程和一些遇到并解决了的问题都写了出来,还是不错的
怎么说呢,我这份任务完成的,绝对是顶级折磨,一开始下载的权重文件,是破损的,就被折磨了好久(所以一定要找个靠谱的地方下载,关于如何判断权重文件有没有破损,可以去找找视频,看看他们权重文件的文件大小和你的文件大小一不一样,不一样就是出问题了)
不管过程如何,结局突出的就是一个->
开心o(* ̄▽ ̄*)ブ


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









