









HDFS读取数据流程详解
hdfs数据读取的流程和写入流程是相对应的。读取的目标存储在datanode block中,那么要搞清楚hdfs读取的流程,理解hdfs写入流程是前提。
另外理解HDFS的数据读取流程除了理解hdfs交互过程外,还需要知道下面两个知识点:
(1)机架感知-副本存储机制
(2)网络拓扑-节点距离计算
本文包含的主要内容:
1.hdfs读取数据流程
2.hdfs读取数据过程中的两个重要问题
下面以300m文件读取为例,详细讲解HDFS数据写入的详细过程。
示例:默认hdfs副本数为3,文件切片3个,4个datanode用于存储该文件3个切片的3个副本(具体副本存储的方式由机架感知特性决定)。
1.hdfs读数据流程
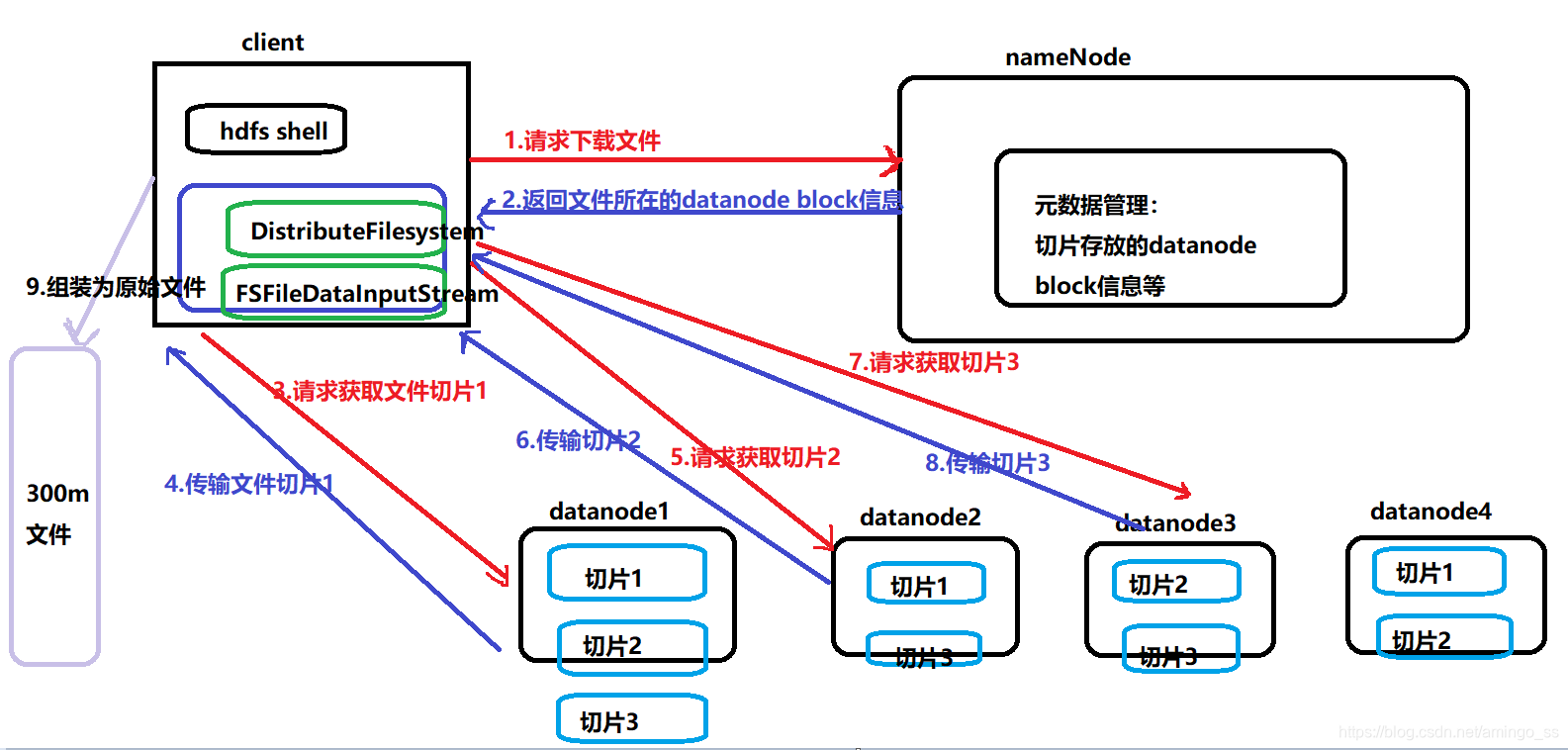
读数据流程详解:
(1)客户端给namenode发起文件下载请求
(2)nameNode返回文件存储所在的datanode block块信息。
(3)客户端根据拿到的block信息与距离最近的切片所在datanode建立通信通道,获取文件切片。
(4)Datanode将该节点上的切片信息传输给客户端。
(5)如果没有获取到所有的切片信息,再与距离最近其他切片副本所在的datanode建立通信通道,获取该节点的切片。如此重复,直到获取到所有的切片信息。
(6)客户端拿到所有切片后,将切片组装为完整的文件。
注:如上图副本存储方式,假设datanode1距离client最近,client从datanode1上读取了所有切片副本后,就不会再去其他datanode建立通信,获取切片副本了。也就是5,6,7,8都不会执行。
2.两个重要的问题:
(1)文件切片如何在datanode存储,具体存储在几个datanode上,每个datanode存储几个副本?
该问题涉及到hdfs的一个重要知识点:机架感知。
机架感知副本存储基本原则:
第一个副本在 client 所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点。
(2)hdfs如何控制去哪个datanode上读取文件切片?
最近原则:客户端距离哪个副本数据最近,HDFS就让哪个节点把数据给客户端。
这里涉及到 网络拓扑-节点距离计算的知识点。
节点距离计算的基本公式是:距离=两个节点到相同的公共点的距离之和。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









