






在建筑业,在建工程项目需要按规定备案许多人员在项目中,如果项目很多的话,那么备案人员的资料也就很庞大。劳务员需要制作这些备案人员的每月工资表,而查找并填写这些人员的银行账号是件费时费力的“体力活”。
在劳务员的求助下,我用Python帮她们写了一段填充项目备案人员的银行账号的代码,根据“工资表”上的人员清单,自动在“备案人员资料”中查找到他们对应的银行卡号,并填充到工资表中。
为简化模型,我将“工资表”简化成为一个只包含“姓名”列的清单,将“备案人员资料”简化为一个只包含“姓名”列和“银行账号”列的清单,并全部输出到文本文件中。
以下,就是清单示例:
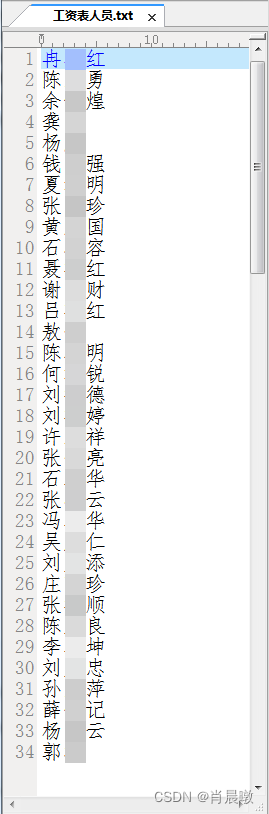 |  |
如上两表,现要根据左表的人员清单在右表中查询该人员对应的银行账号,没有的放空。
大家可能觉得这没几行,实际上,无论左表还是右表,清单要长得多,手工核对是非常费时费力的。
以下是我写的用于解决这件事情的Python代码。
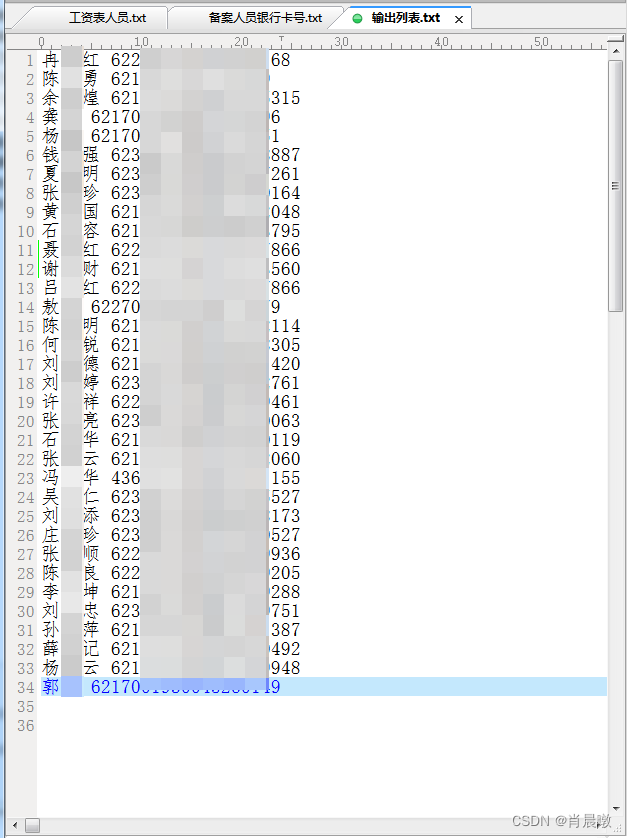
代码最终生成一个:按左表的顺序填充了右表中的银行账号的清单,以空格间隔,剔除了所有不必要的符号,以便导入EXCEL,供劳务员做进一步处理,并自动打开该文件:
'''劳务无法提供备案人员完整的工资表,故立此项目核对'''
import logging
#导入日志模块
#logging.disable(logging.CRITICAL)
#定义log的基本配置:
logging.basicConfig(level=logging.DEBUG,format='%(asctime)s-%(levelname)s:%(message)s')
#切换到工作目录,避免繁琐的路径描述
工作目录='G:\\Xct\\python\\劳务工资回单'
import os
os.chdir(工作目录)
#导入工资表人员
import os
姓名列表=[]
工资表人员文件 = '工资表人员.txt'
with open(工资表人员文件, 'r', encoding='utf-8-sig') as 文件:
工资表人员 = 文件.readlines()
logging.debug('工资表人员文件中的人员有:%s' %(工资表人员))
for 姓名 in 工资表人员:
姓名转列表=[姓名.strip()]
#将"工资表人员"列表的元素转为子列表,同时去除子列表元素首尾的制表符\t、回车符\r、换行符\n
姓名列表.append(姓名转列表)
#创建目标母列表
print(姓名列表)
#导入备案人员银行卡号
姓名账号=[]
备案人员银行卡号文件='备案人员银行卡号.txt'
with open(备案人员银行卡号文件, 'r', encoding='utf-8-sig') as 文件:
备案人员银行卡号= 文件.readlines()
logging.debug('备案人员银行卡号文件中的人员有:%s' % (备案人员银行卡号))
#将人员姓名与身份证号分割为列表
for 账号信息 in 备案人员银行卡号:
列表=账号信息.split()
#按空格(默认)分割字符串为列表
姓名账号.append(列表)
#创建数据母列表
print(姓名账号)
#按“姓名列表”的顺序,搜索“姓名账号”列表,将同名者的账号追加到“姓名列表”中
姓名=''
输出列表=[]
for 姓名 in 姓名列表:
logging.debug('姓名:%s' % (姓名))
for 户主账号 in 姓名账号:
logging.debug('户主:%s' % (户主账号[0]))
logging.debug('账号:%s' % (户主账号[1]))
if 姓名[0]==户主账号[0]:
姓名.append(户主账号[1])
logging.debug('追加了账号的姓名列表:%s' % (姓名))
输出列表.append(姓名)
print (输出列表)
#输出到文本文件
import sys
写入文件路径 = '临时转存列表.txt'
with open(写入文件路径, 'w', encoding='utf-8-sig') as 文件:
sys.stdout = 文件
for 变量 in 输出列表:
print(变量)
#打开该文本文件,删除所有不必要的符号
最终结果文件 = '输出列表.txt'
要删除的符号 = ["[", "]", ",", "'"]
with open(写入文件路径, 'a+', encoding='utf-8-sig') as 文件:
sys.stdout = 文件
with open(最终结果文件, 'w', encoding='utf-8-sig') as 结果:
sys.stdout = 结果
文件.seek(0)
内容 = 文件.read()
for 标点 in 要删除的符号:
内容 = 内容.replace(标点, '')
print(内容)
# 删除临时文件
os.remove(写入文件路径)
# 打开目录
os.startfile(工作目录)
# 用操作系统默认程序打开上述文件
os.startfile(最终结果文件)以下是运行结果,经核对,无误:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











