









在我们推出开源的 思通舆情系统后,在开源社区受到了广大用户的喜爱和关注,很多用户对我们的数据采集技术、后端海量数据运算非常感兴趣。
思通舆情 在线生产环境 使用了24个节点的 Elasticsearch集群存储,每天在互联网上采集的2亿多条数据,每个月下来抓取的数据量2TB左右。
思通舆情 开源项目地址:
https://gitee.com/stonedtx/yuqing
今天跟大家来聊聊 思通舆情 系统中重要的一个技术环节:基于ElasticSearch集群的海量数据架构。我们每天采集 2亿多条的互联网数据不可能把数据存储在一种存储服务器中。例如:需要检索数据我们就存储在ElasticSearch集群中存储。
BTW:不同类型的详情数据我们会分别存储在Mongodb和Cassandra里面,最早之前我们存储在HBase中,由于HBase对Hadoop的过度依赖,导致我们对HBase选择了放弃。
应用场景
在思通舆情系统中,每个用户设置不同的关键词,可以快速检索对应的舆情数据,对提及关键词的数据提供统计图表,包括舆情走势、词云图、情感分布、情绪走势等。
思通舆情对公开的信息进行结构化、自动分类、文本聚类、主题发现与跟踪等,提供信息检索、多维度统计、敏感信息预警、信息简报、自动化报告等功能,帮助用户及时发现危害品牌形象的观点,并为用户分析关注对象在网络中的形象提供依据。
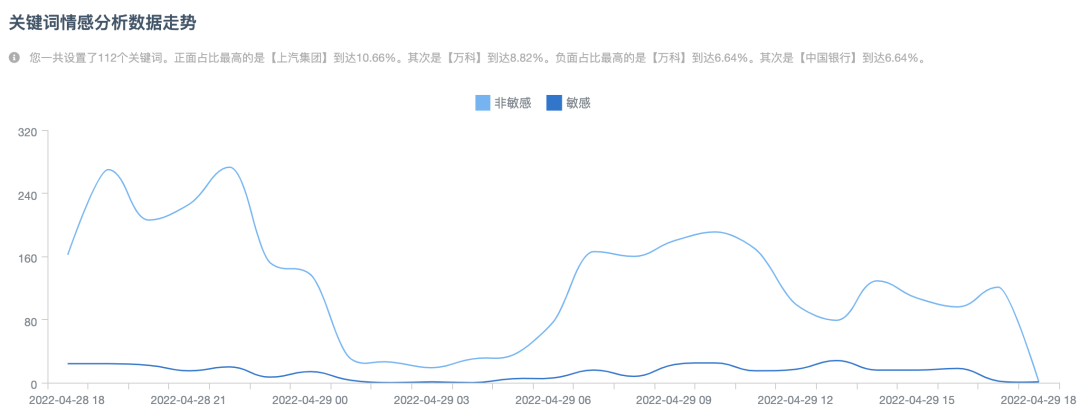
思通舆情系统的数据统计分析都是基于Elasticsearch强大的聚合统计能力,包括嵌套的统计能力实现的。由于我们提供给很多客户的是线上的SaaS服务,在同个页面会迸发请求查询或聚合多个接口等需求,这就对Elasticsearch聚合统计性能和内存使用率,提出了更高的要求。
技术场景
ElasticSearch 集群的上层是分布式的爬虫系统,每个爬虫应用会把网页内容实时写入Kafka队列,再由Kafka队列根据业务需要进行实时流入流计算引擎(Flink实时计算引擎),会持久化存储在Mongodb或者Cassandra中。
中间会利用自然语言处理处理技术,对不同的数据内容加工、打上各种标签,将非结构化网页内容转化为结构数据。例如:提取出网页的标题、URL地址、作者、摘要等,对正文和摘要内容进行分词,以及对文章中的上市公司、独角兽公司、人物、地点、政府机关 等内容提取和标注。

系统会把用户需要检索的信息存储到 分布式 ElasticSearch 集群中,这样用户就可以通过多个不同维度的筛选项对原来非结构化的数据快速检索了。这里的信息检索与计算,都离不开 Elasticsearch(以下简称:ES)的 Query 以及 aggregation功能。
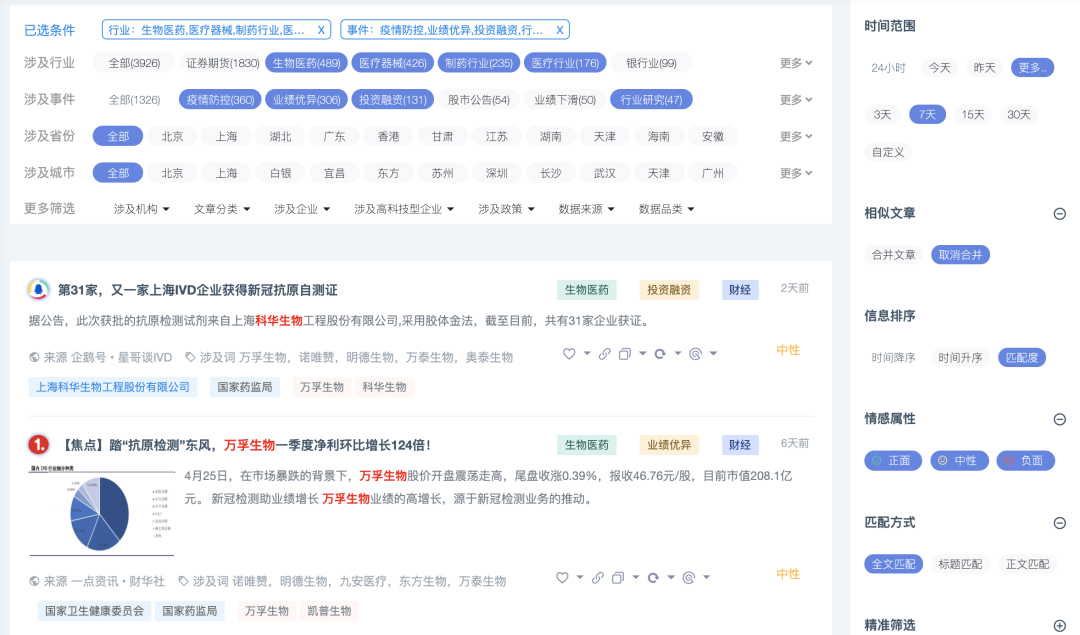
索引设计
采集的数据源包括抖音、小红书、微博、微信、新闻网页、论坛、自媒体、其他短视频等平台的数据,每天新增去重数据量在 1亿+,每条数据在经过结构化,以及经过 NLP(自然语言处理)之后,超过200 个字段,比如,文章标题、发布时间、发布作者、发布平台、新闻分类、新闻提及地域、高频词、机构/企业信息、涉及政策、新闻情绪等。
由于业务端需要对这些数据进行实时检索,对不同平台的数据实时聚合,各平台的数据量分布也有很大的差异,所以按照平台进行拆分,而不是把所有的数据放到一个大的索引里面。
一般每日社交媒体数据采集量占每日总采集量 60-70%,而新闻、自媒体平台相对较少。为了避免由于索引的大小不一样,导致每个shard的差异过大,最终导致落在不同节点上 shard 占用空间分布不均匀而出现数据倾斜。所以,在实现上对社交媒体的索引按照日期做了进一步拆分,社交媒体每日一个索引,而自媒体平台每月一个索引。
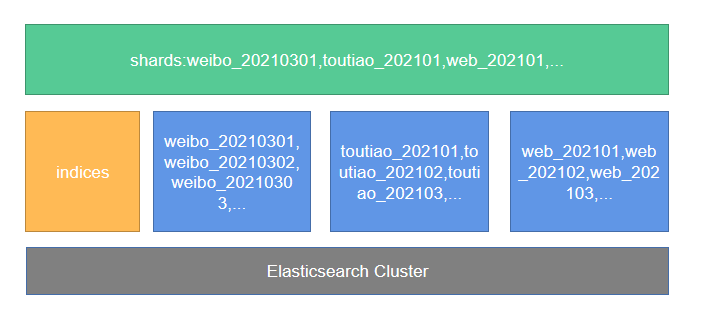
为了方便业务检索,对按天分索引的微博设置别名,比如 alias weibo_202101对应weibo_20210101,weibo_20210102,...,weibo_20210131而新闻网页、微信、自媒体平台的数据存储在一起按照月划分,设置别名postal_info对应:
postal_info202203,postal_info202204,postal_info202205 以此类推。
总之就是一个字:分!
要根据用户的业务场景需求,把超大的数据量“分”(设计)成完美的方案。
让每个用户能快速获取有价值的信息,是我们的追求!
索引分层
在系统中我们将 ElasticSearch 集群分为冷、热两个区域。按照业务特点以及成本综合考虑,分为近3个月的热数据集群,近21个月数据的冷数据集群,系统整个ElasticSearch 集群一共存储24个月的数据。
冷数据ElasticSearch集群,选择价格相对低廉的SAS盘作为存储介质,提供对响应时间不敏感,且时间周期跨度较长的检索、聚合统计等。热数据集群,选择SSD盘作为索引的存储介质,每个节点32 CPU、64G 内存。
为了降低运维成本,在索引设计方面,根据业务特点,经常要检索特定平台的数据,对索引按照文章发布平台,以及发布日期做了拆分,使每个索引不至于过大,提高磁盘的利用率与检索性能。
开源项目
上述技术内容已通过开源项目实践。思通舆情 是一款开源免费的舆情系统,支持本地化部署。支持对海量的舆情数据进行多维交叉分析和深度挖掘,为用户提供全面的舆情数据,专业的舆情分析,快速的舆情处理等服务,提升企业品牌价值和风控能力。
请关注我们发布的开源项目:
https://gitee.com/stonedtx/yuqing
欢迎对我们的项目 pull request 或者 留言对我们提出建议。您的支持和参与就是我们坚持开源的动力!请 star 或者 fork!
关于我们
思通数科 专注互联网开源数据智能处理,为用户提供“数据采集”、“数据标记”和“数据挖掘”三方面核心能力,以有效的方式使用互联网数据,提高生产力及决策能力。
了解更多关注微信公众号。

识别下方二维码访问 思通数科 StoneDT / 开源免费舆情监测网络监控系统。

















 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









