






一、杂碎问题整理(一)
①自定义比较器的方式:
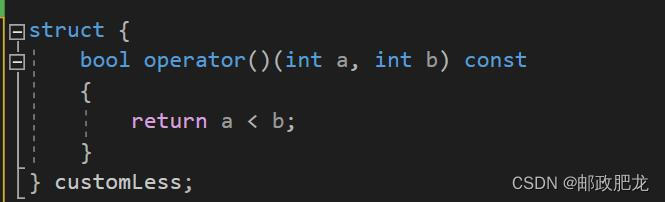
最后呈现在std::sort()中的方式:
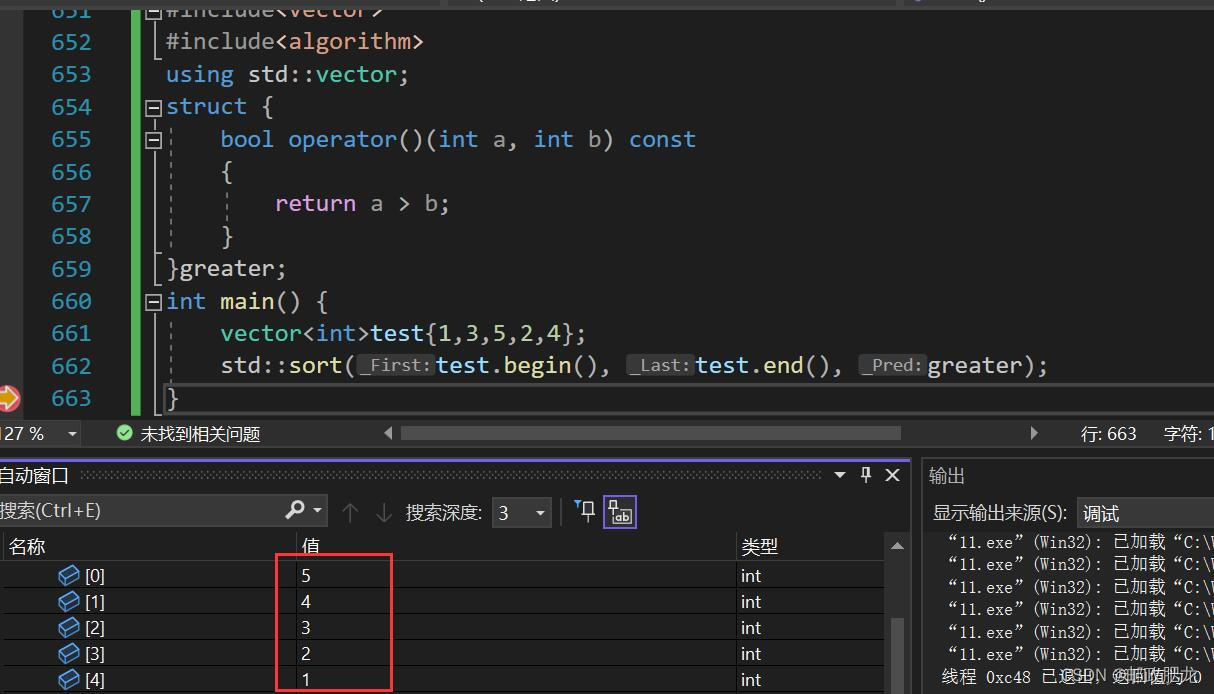
※由此引出的三种自定义比较器的方式:
一、重载结构体类型的operator:
这种做法实际上实现了比较的自动化,因为std::sort默认调用的就是operator<来作比较,只是一般的数据类型,像int等,都可以直接进行比较操作。
※两个元素经由operator处理之后,若返回值为true,那么前元素会排在后元素的前面,也就是默认升序排列。比如1<2,true,那么1就在前面
如图:
※注意这种类内方法的写法:
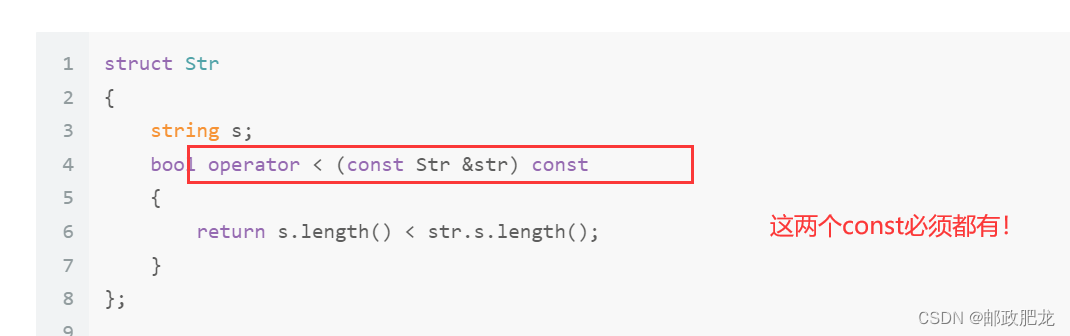
二、全局形式的比较器写法:
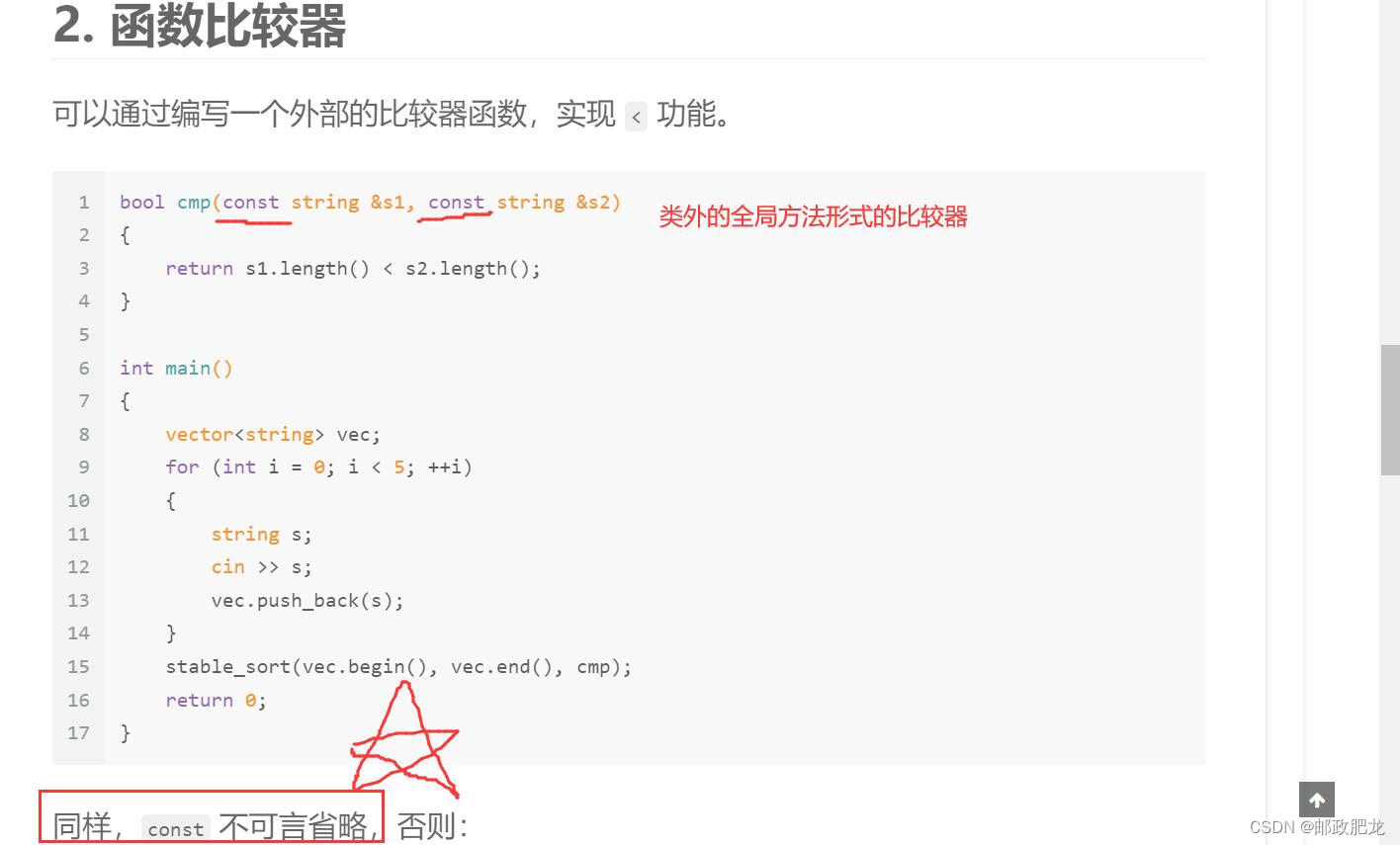
3. 函数对象比较器
所谓函数对象是指实现了 operator () 的类或者结构体。可以用这样的一个对象来代替函数作为比较器——
比如: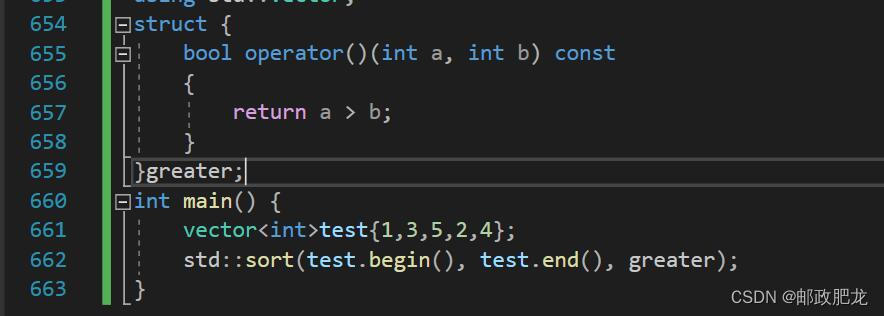
再如:
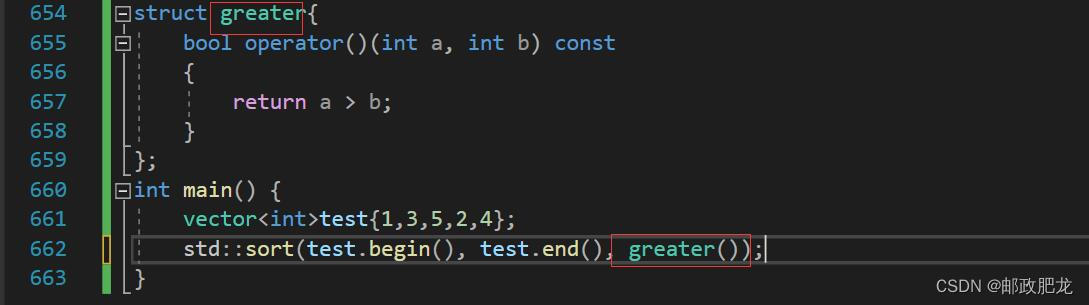
※注意:
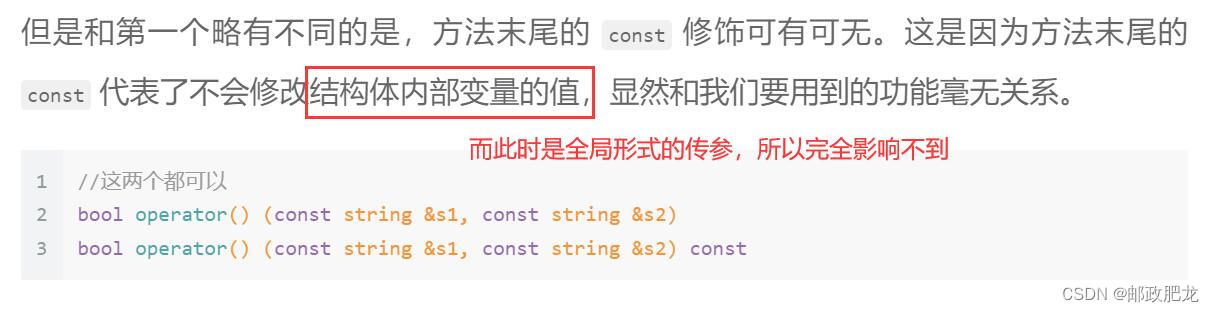
留个尾巴——这种写法能够成立的原因?
②层序遍历中对于“层”的处理:
核心思路就在于,用一个临时队列来保存一整层的结点,通过提前记录队列的size(防止在pop&push的过程中产生对于size大小的影响而使得循环次数不正确),保证每次都只pop掉一层的结点,并且push进去下一层的节点。处理完当前层的结点之后,将当前层加入到最终数组中即可
③一些适于排序的场景:
1、枚举可行的二叉搜索树的个数:由于二叉搜索树的左小右大的特性,可以先升序排序,再以某一结点为根节点,那么左边的就都属于它的左子树,右边的就都属于它的右子树

代码处理:
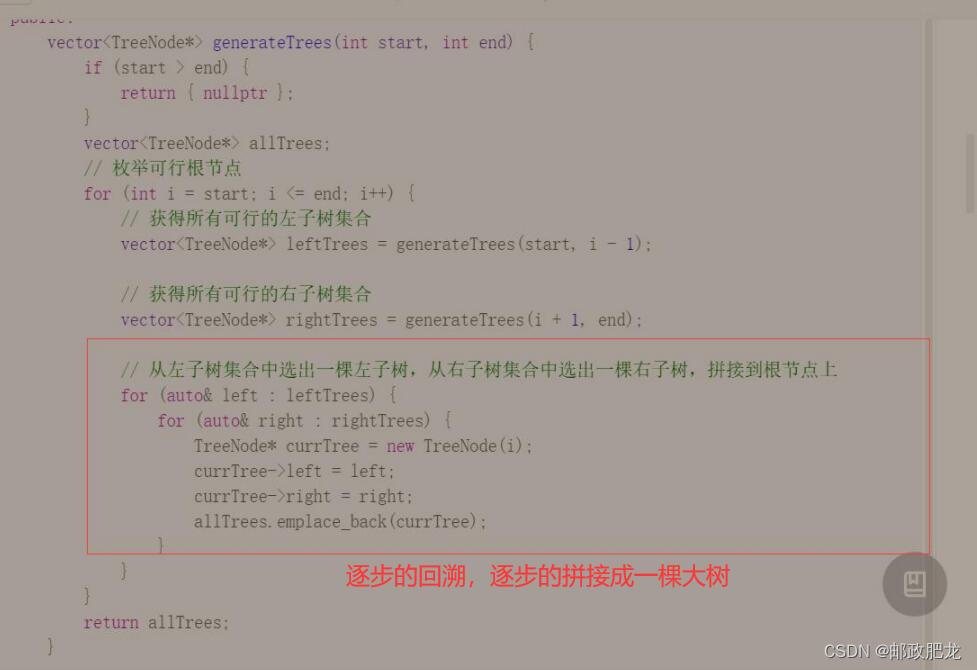
※补充一点:不要忘记普通数组也是可以排序的!sort的前两个参数传入数组的起始&终点即可
(常为数组名&数组名+元素个数)
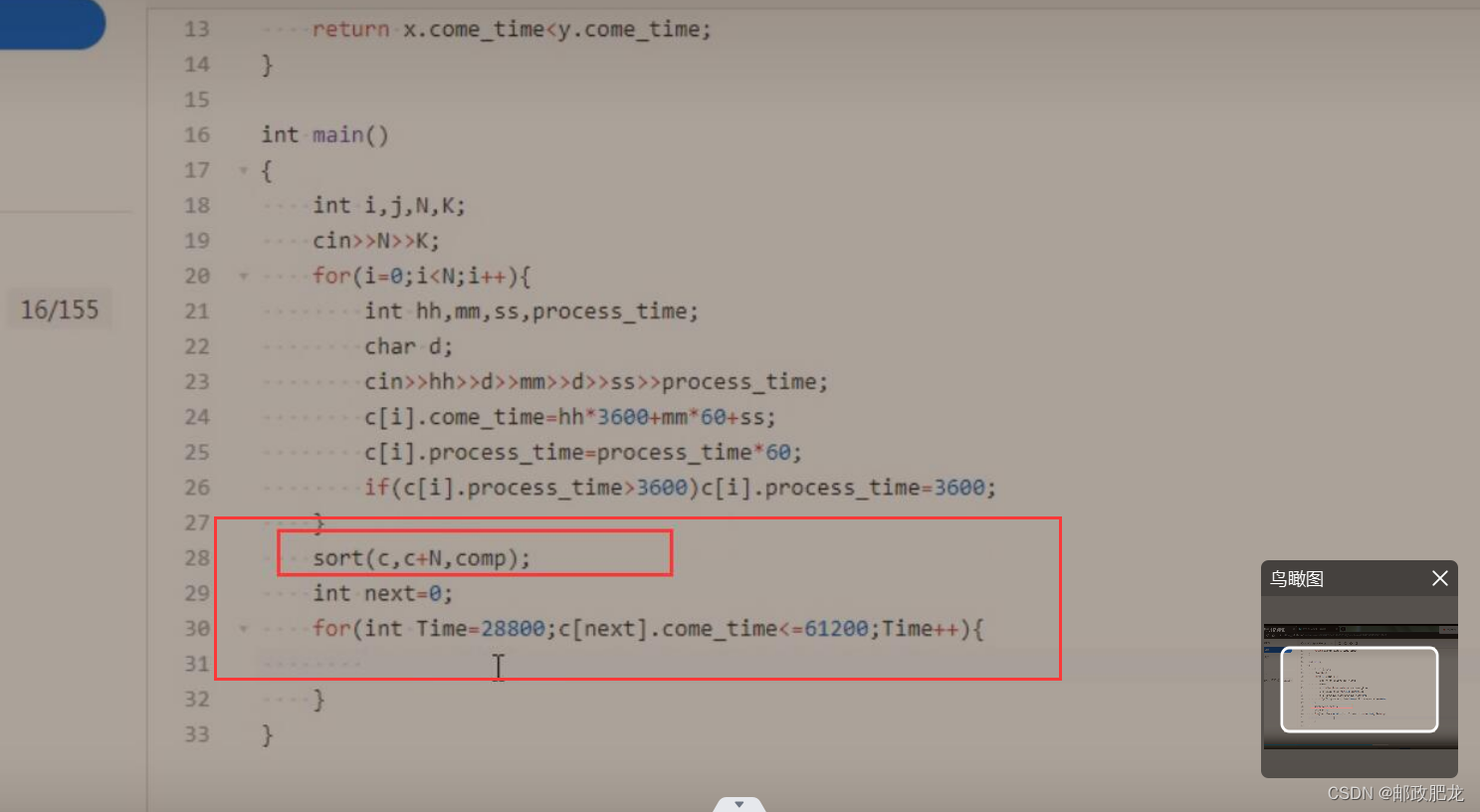
2、
④vector的一些容易忽略掉的初始化方式:
1、初始化为二维数组:
std::vector<std::vector<int>>VC;
for(int i=0;i<VC.size();i++)
{
for(int j=0;j<VC[0].size();j++)
{
//注意这里:内层循环可以通过VC[0].size()来获取内层应有的循环次数
}
}
2、列长度一定,行长度不定的二维数组——常用于简写邻接表:
vector<int>VC[501];//实际上就是开了个元素类型为vector<int>的一维数组
//这里作邻接表添加的操作就很简单了,直接VC[i].push_back()即可⑤对于要求“There must be no extra space(或者是箭头一类的东西) after the last one"的题目的输出的优化处理:

否则就得写成:
for(int i=0;i<final_ans.size();i++)
{
if(i)
cout<<"->"<<final_ans[i];
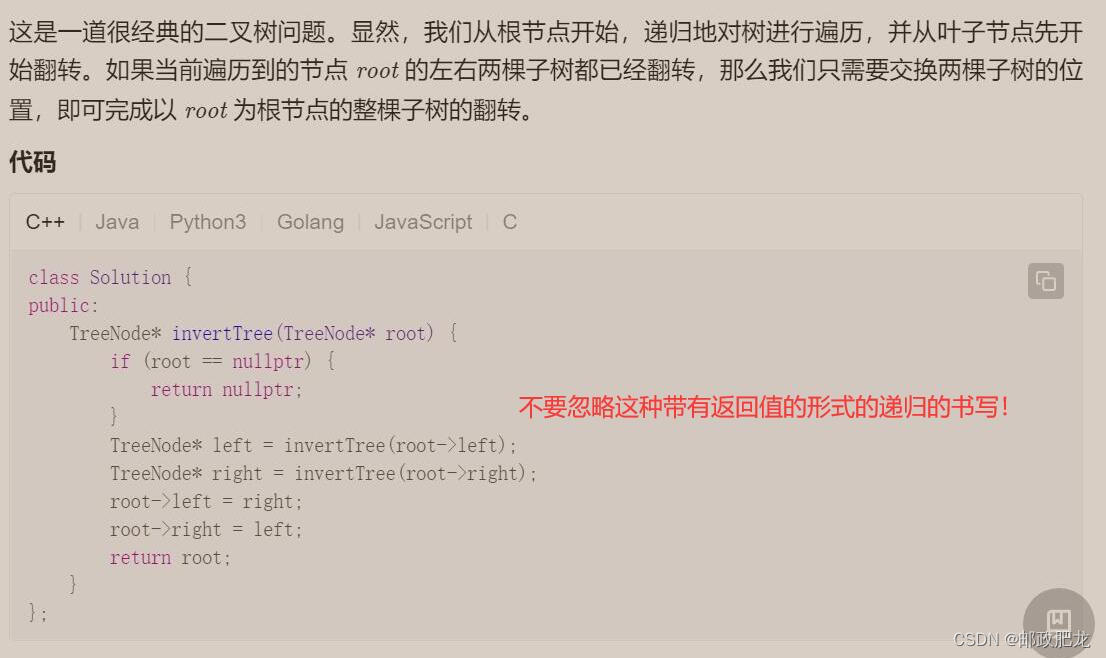
}⑥对于递归问题的再归纳:
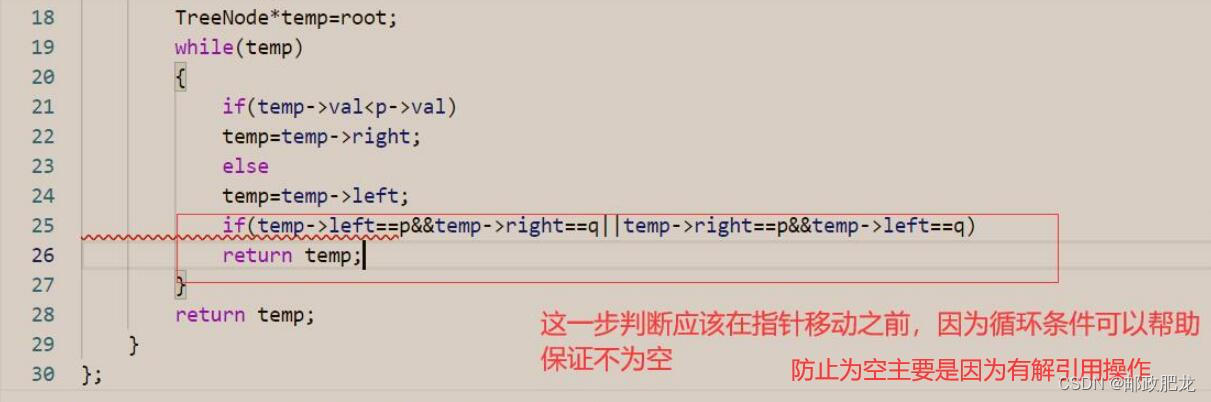
⑦判断条件的先后问题:
1、一个典型例子:
2、另外一种很重要的情况:
if(root!=NULL&&root->left==val) √
if(root->left==val&&root!=NULL) ×
程序会从左往右读,如果不先通过指针为空跳出这个判断,就会有解引用空指针的风险
⑧特定问题的一些处理技巧:
(1)避免定义结构体,通过下标作一一对应的处理:
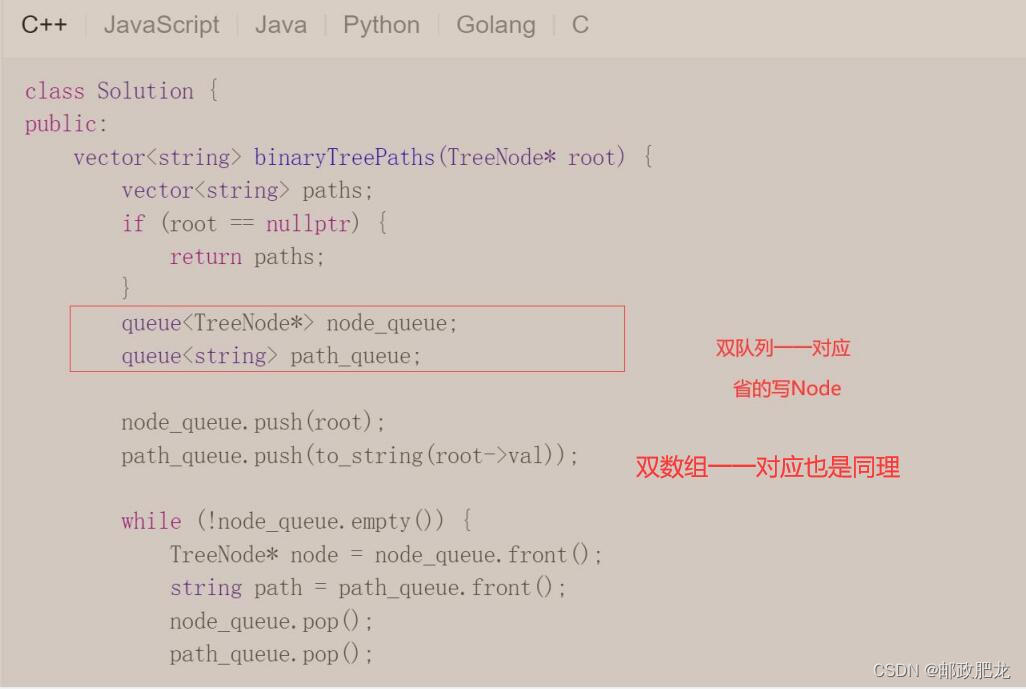
(2)比较大小&更新大小等问题,无脑三目运算符:
//尤其是这种:
if(cur_max>max_sum)
max_sum=cur_max;
//写成:
max_sum=max_sum>cur_max?max_sum:cur_max;
//能快很多它比用if快很多,也比C++的algorithm内置的std::max/std::min要快。而且std::max&std::min的运行时间好像还有一定的波动,但即使是它们的最快的情况也不如三目运算符
(3)数据量上了10w,基本不用考虑O(n2)的暴力解法了,一般无论怎么优化都会死
⑨DP的一些题目:
1、几种典型处理:
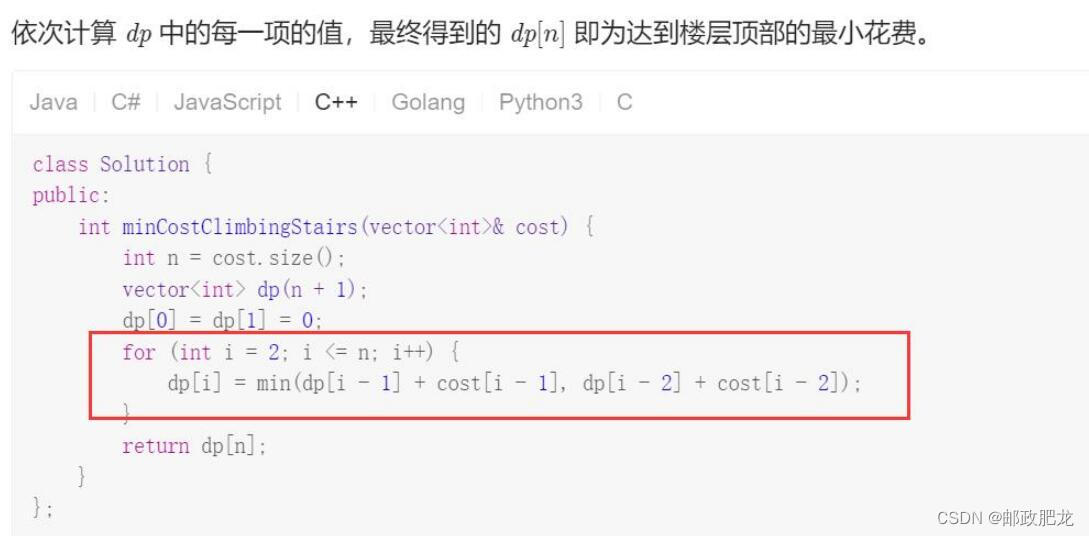
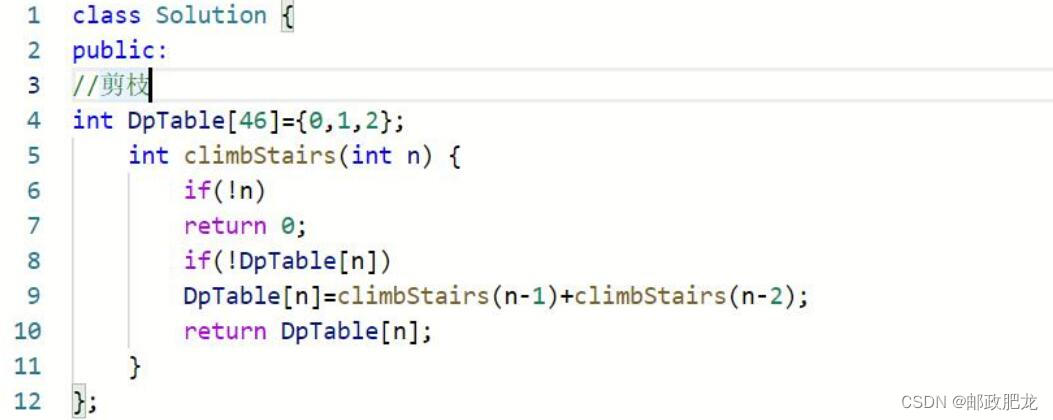
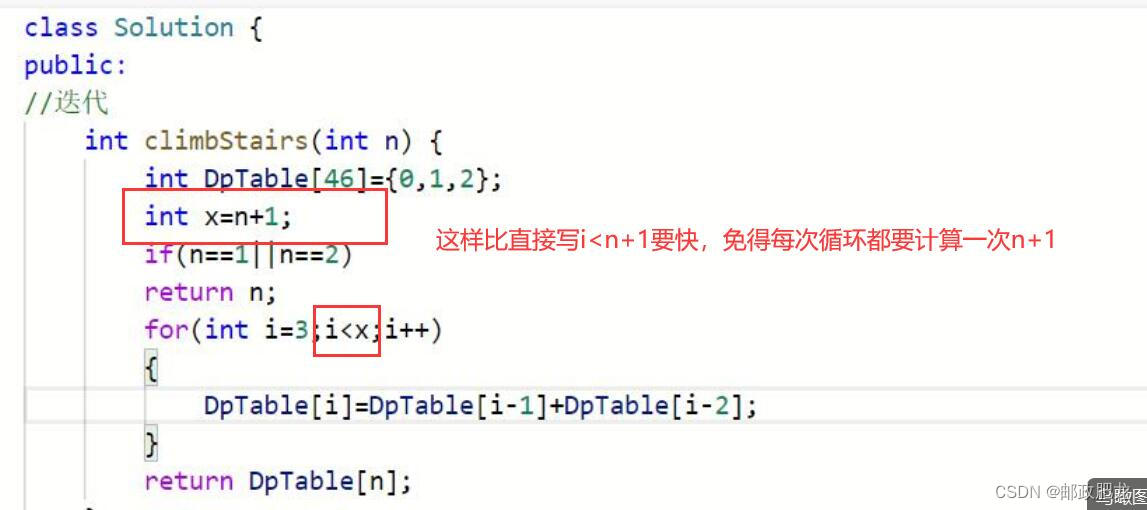
※迭代打表&递归剪枝之爬台阶问题:
※“常数次遍历,往往是两次遍历”:往往一次遍历不是那么好思考,可以先从常数次遍历开始考虑,再优化到一次遍历--“股票买卖问题”
Dptable[i]代表第i天之前的股票价格的最低点:
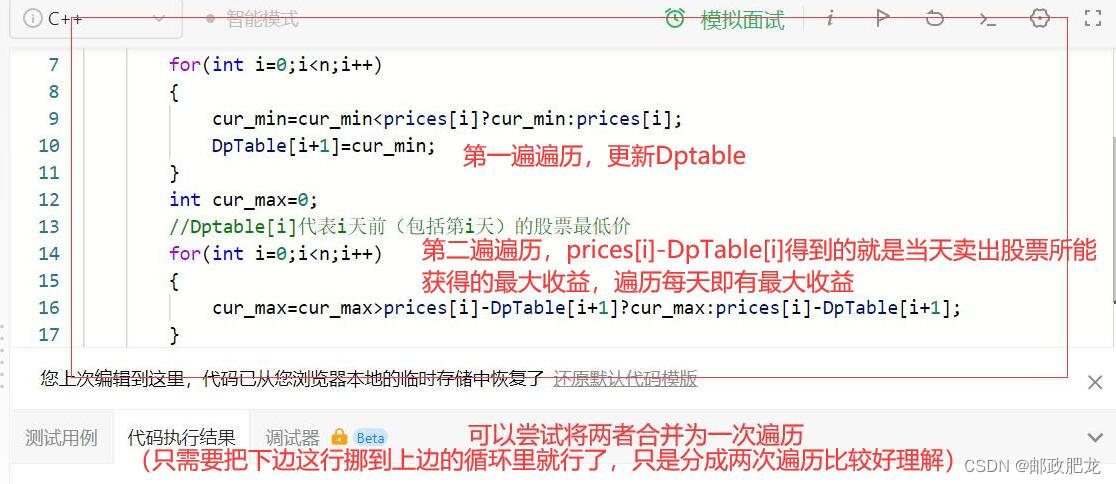
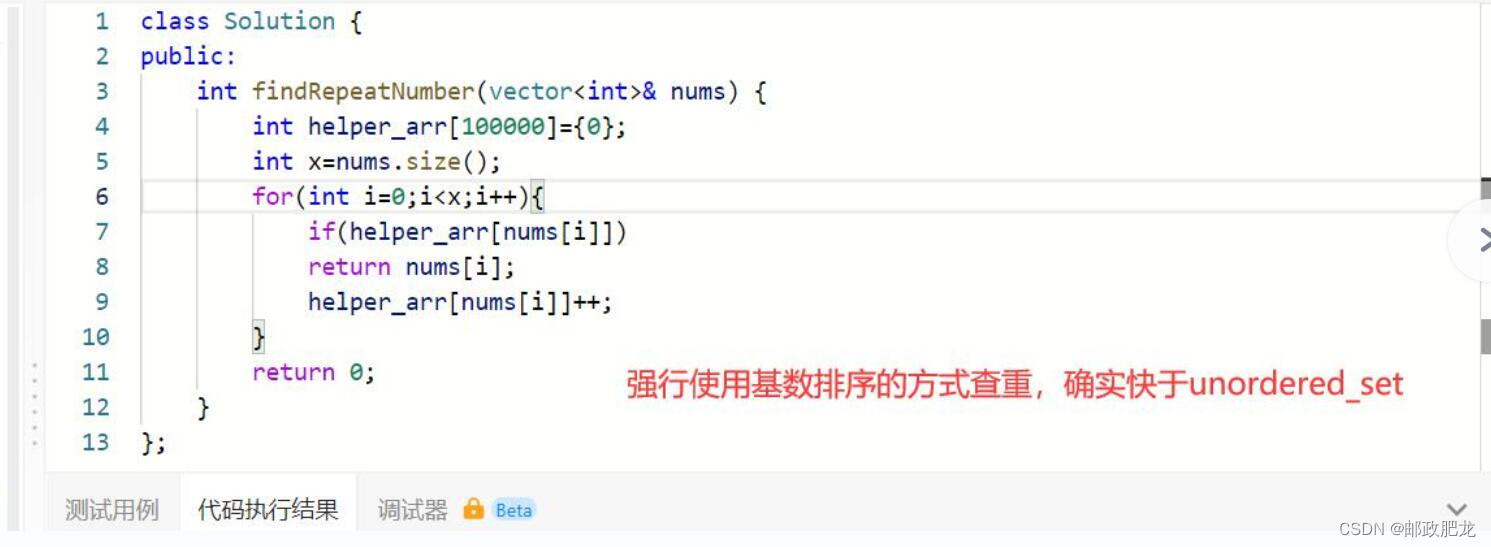
⑩暴力开数组的处理方法:
一、数组中的重复元素问题:要微快于使用unordered_set来不断insert&find的做法
二、※手动模拟vector型:尤其是在存储二叉树的遍历序列等时,除了开一个vector来不断地push_back以外,还可以根据题目的数据量来开辟一个足够大的数组,再使用index来记录元素个数,会比使用vector快不少














 1220
1220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









