







目录
-
概述
-
环境准备
-
认识中文分词器
- 常用的中文分词器
- IK Analyzer
- hanlp中文分词器
-
彩蛋
概述
上一篇博文记录了elasticsearch插件安装和管理, 在地大物博的祖国使用es,不得不考虑中文分词器,es内置的分词器对中文分词的支持用惨不忍睹来形容不为过,看这篇博文之前,建议先看一下博文elasticsearch分词器,对分词器有个初步理解。本文将记录一下项目中如何使用选用和使用中文分词器的,希望能够帮助到即将来踩坑的小伙伴们,欢迎批评指正
本文都是基于elasticsearch安装教程 中的elasticsearch安装目录(/opt/environment/elasticsearch-6.4.0)为范例
环境准备
- 全新最小化安装的centos 7.5
- elasticsearch 6.4.0
认识中文分词器
在博文elasticsearch分词器中提到elasticsearch能够快速的通过搜索词检索出对应的文章归功于倒排索引,下面通过中文举例看看倒排索引。
中文分词器作用以及效果
中文分词器是做什么的呢? what? 通过名字就知道了啊,为什么还要问。。。下面通过三个文档示例,看看它是如何分词的
文档1: 我爱伟大的祖国
文档2: 祝福祖国强大繁盛
文档3: 我爱蓝天白云
经过中文分词器,以上文档均会根据分词规则,将文档进行分词后的结果如下:
注意:不同的分词规则,分词结果不一样,选择根据分词器提供的分词规则找到适合的分词规则
文档1分词结果: [我,爱,伟大,的,祖国]
文档2分词结果: [祝福,祖国,强大,繁盛]
文档3分词结果: [我,爱,蓝天白云,蓝天,白云]
通过上面的分词结果,发现拆分的每个词都是我们熟知的词语, 但是如果不使用中文分词,就会发现上面的文档把每个字拆分成了一个词,对我们中文检索很不友好。
再看倒排索引
看到上面中文分词器结果,就会有新的疑问,使用中文分词器那样分词效果有什么好处呢? 答案就是根据分词建立词汇与文档关系的倒排索引。这步都是es帮我们做的,下面通过"我","爱","祖国"三个词看看倒排索引,如下图:
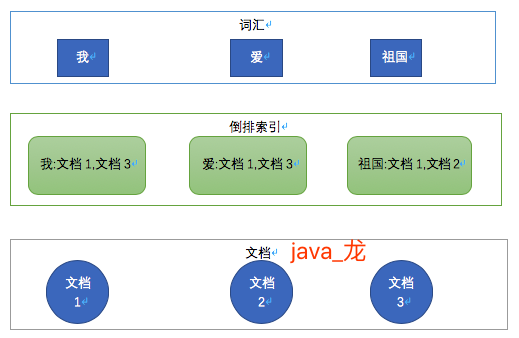
通过上图中的倒排索引,我们搜索"祖国"时,es通过倒排索引可以快速的检索出文档1和文档3。如果没有中文分词器,搜索"祖国"就会被拆分"祖""国"两个词的倒排索引, 就会把包含"祖"的文档都检索出来,很明显就会和我们想要的结果大相径庭。
常用的中文分词器
Smart Chinese Analysis: 官方提供的中文分词器,
IKAnalyzer: 免费开源的java分词器,目前比较流行的中文分词器之一,简单,稳定,想要特别好的效果,需要自行维护词库,支持自定义词典
结巴分词: 开源的python分词器,github有对应的java版本,有自行识别新词的功能,支持自定义词典
Ansj中文分词: 基于n-Gram+CRF+HMM的中文分词的java实现,免费开源,支持应用自然语言处理
hanlp: 免费开源,国人自然处理语言牛人无私风险的
个人对以上分词器进行了一个粗略对比,如下图:
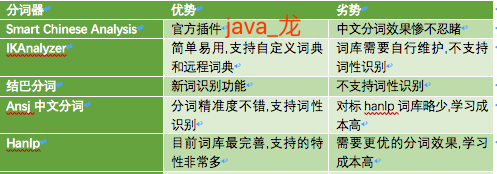
截止到目前为止,他们的分词准确性从高到低依次是:
hanlp> ansj >结巴>IK>Smart Chinese Analysis<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5669
5669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









