







 本文探讨了并发编程中常见的ABA问题,通过一个链表堆栈的例子详细解释了ABA问题的潜在风险,并介绍了三种解决方法:添加版本号使用AtomicStampedReference、使用AtomicMarkableReference以及HazardPointer算法。
本文探讨了并发编程中常见的ABA问题,通过一个链表堆栈的例子详细解释了ABA问题的潜在风险,并介绍了三种解决方法:添加版本号使用AtomicStampedReference、使用AtomicMarkableReference以及HazardPointer算法。
前面讲了很多次的CAS,但是CAS可能会出现一个问题,前面也说过,这篇文章具体讲讲,就是ABA的问题:
线程1准备用CAS将变量的值由A替换为B,在此之前,线程2将变量的值由A替换为C,又由C替换为A,然后线程1执行CAS时发现变量的值仍然为A,所以CAS成功。但实际上这时的现场已经和最初不同了,尽管CAS成功,但可能存在潜藏的问题。
What is ABA
有个经典的链表的例子可以来说明这种隐藏的问题:
现有一个用单向链表实现的堆栈,栈顶为A,因为是堆栈,所以A.next = B。
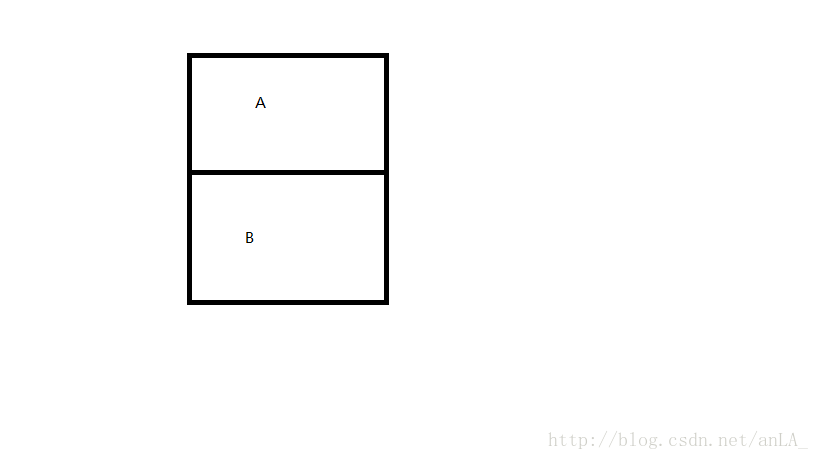
然后呢,当前时刻,t1线程现在想用B替换A,我想要的结果是B作为栈顶,最终栈里只有B。
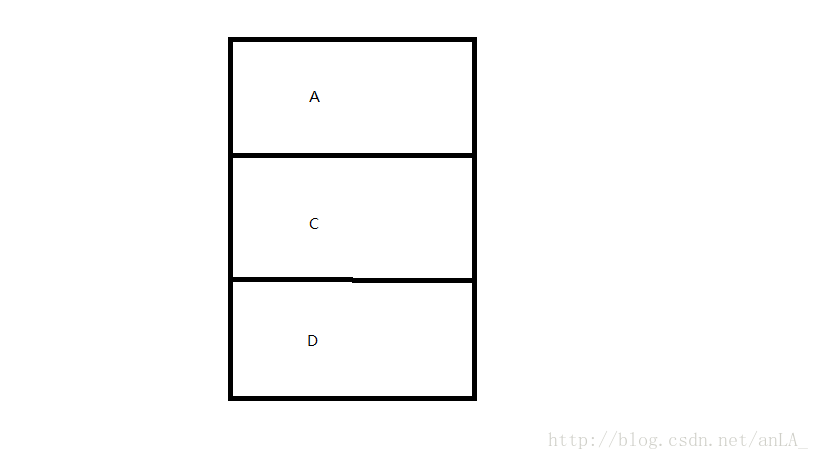
当t1打算开始时,此时t2获得cpu,将A、B出栈,再push D、C、A,此时堆栈结构如下图,而对象B此时处于游离状态:
然后此时t1获得了cpu,开始进行他的工作,把A替换为B,好t1替换成功了,栈顶为B了,结果呢?因为B是游离的,所以B.next=null了。此时结果图变为:
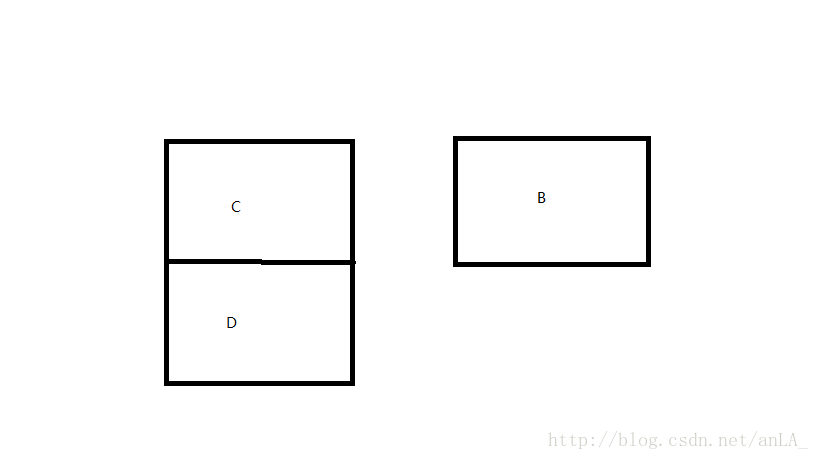
或许这里有个问题,就是在t1替换时,可以把B.next = A.next再进行替换,这样链表就不会断开了。
但是情景语义是ABA问题,t1的情景被破坏了,更好的解决方法就是,如果发现情景被破坏了,我就不进行操作了。
接下来说说几种解决ABA问题的方法:添加版本号
添加版本号
添加版本号,意思就是每个操作进行时,我首先需要对比,当前版本号是否和我期待的场景的版本号一致,如果一致就可以进行修改。结合Java语言来看,提供了AtomicStampedReference ,来作为实现。
AtomicStampedReference里面是把[reference,pair]看做一个pair,每次都对这个整体进行CAS操作。
首先看其基本内容:
private static class Pair<T> {
//定义为final,不可改变
final T reference;
final int stamp;
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static <T> Pair<T> of(T reference, int stamp) {
return new Pair<T>(reference, stamp);
}
}
//volatile类型,保证可见性。
private volatile Pair<V> pair;当然内部还是利用了Unsafe类的CAS方法,对pair进行更新操作,接下来看一个例子,简单理解下由于ABA问题,使得AtomicInteger和AtomicStampedReference出现不同的结果:
public class ABAProblem {
private static AtomicInteger atomicInt = new AtomicInteger(100);
private static AtomicStampedReference atomicStampedRef = new AtomicStampedReference(100, 0);
public static void main(String[] args) throws InterruptedException {
Thread intT1 = new Thread(new Runnable() {
@Override
public void run() {
// atomicInt先进行CAS操作
atomicInt.compareAndSet(100, 200);
atomicInt.compareAndSet(200, 100);
}
});
Thread intT2 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 休眠1s,等待intT1进行完CAS操作
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
boolean c3 = atomicInt.compareAndSet(100, 200);
System.out.println(c3); // 结果为true
}
});
intT1.start();
intT2.start();
intT1.join();
intT2.join();
Thread refT1 = new Thread(new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
// 进行CAS操作,同时版本号加1
atomicStampedRef.compareAndSet(100, 200, atomicStampedRef.getStamp(), atomicStampedRef.getStamp() + 1);
atomicStampedRef.compareAndSet(200, 100, atomicStampedRef.getStamp(), atomicStampedRef.getStamp() + 1);
}
});
Thread refT2 = new Thread(new Runnable() {
@Override
public void run() {
// 获取最初版本号
int stamp = atomicStampedRef.getStamp();
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
}
// 由于版本号已经由refT1增加了,所以预期版本号失败导致更新失败。
boolean c3 = atomicStampedRef.compareAndSet(100, 200, stamp, stamp + 1);
System.out.println(c3); // 结果为false
}
});
refT1.start();
refT2.start();
}
}上述代码说明了AtomicInteger的ABA问题和AtomicStampedReference解决ABA问题。
AtomicMarkableReference
AtomicMarkableReference和AtomicStampedReference 类似,AtomicStampedReference是使用pair的int stamp作为计数器使用,AtomicMarkableReference的pair使用的是boolean mark。
比如一张纸,AtomicStampedReference可能关心的是折过几次,AtomicMarkableReference关心的是有没有被人折过,同样,AtomicMarkableReference也是利用CAS进行pair的更新操作。。
Hazard Pointer 算法
其实主要的思路就是无锁地去解决并发问题,Hazard Pointer也是一种无锁算法的思路,他有两个特点:
- 保证了关键节点的访问是合法的,不会导致程序尝试去读取已经释放了的内存。
- 保证了 ABA 问题不会出现,程序逻辑正确的前提。
也就是,这种算法的思路就是从根本上杜绝了ABA情况的出现。
简单的说下Hazard Pointer算法的思路:
- 建立一个全局数组 假设为 hp[N],数组中的元素为线程的指针,称为 Hazard pointer,数组的大小为线程的数目,即每个线程在数组有份指针假设为HP。
- 每个线程只能修改自己的 HP,而不允许修改别的线程的内容,但可以去读别的线程的内容即访问HP。
- 当线程尝试去访问一个关键数据节点时,它得先把该节点的指针赋给自己的 HP,即告诉别人不要释放这个节点。
- 每个线程维护一个私有链表(free list),当该线程准备释放一个节点时,把该节点放入自己的链表中,当链表数目达到一个设定数目 R 后,遍历该链表把能释放的节点通通释放,如果此时某个节点被其他线程访问,则交给下一个线程去释放。
- 当一个线程要释放某个节点时,它需要检查全局的 HP 数组,确定如果没有任何一个线程的 HP 值与当前节点的指针相同,则释放之,否则不释放,仍旧把该节点放回自己的链表中。
HP 算法主要用在实现无锁的队列上,因此前面的具体步骤其实基于以下几个假设:
- 队列上的元素任何时候,只可能被其中一个线程成功地从队列上取下来,因此每个线程的 free list 中的元素肯定是唯一的。
- 当出现竞争时,对于某个节点来说,多个线程同时持有该节点的指针这个现象,在时间上是非常短暂有限的,只有当这几个线程同时尝试去取下该节点,它们才可能同时持有该节点的指针,一旦某个线程成功地将节点取下,其它线程很快就会发现,并尝试继续去操作下一下节点,而后续再来取节点的线程则不再可能获得已经不在无琐队列上的节点的指针,因此:当某个线程尝试去检查其它线程的 HP 时,它只需要将 HP 数组遍历一遍就够了,不用担心各线程 HP 值的变化。
实现思路并不难理解,保证每次某一个线程访问时候,不能被其他线程打断,也就是原子性的,怎样去保证原子性呢?
就是如果有线程正在访问这个节点,那我这个线程发现了,我就不去访问你,我去尝试访问其他线程。
这种思路有点类似于网络传输里面的载波监听多点检测 保证了不发生冲突下,每个线程并发执行。
所以从根源上满足了上面的两个特点。
但是这种算法感觉只是提供了一种思路,具体在执行时,如果对于高并发下,每次去清除节点,每次去遍历hp数组,耗时非常大。
对于无锁并发来说,就是为了减少不必要的系统状态切换而耗时的问题,所以Hazard Pointer本质类似于给每个线程加了一把锁。
参考资料:
https://www.cnblogs.com/catch/p/5129586.html
http://blog.hesey.net/2011/09/resolve-aba-by-atomicstampedreference.html

















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









