






问题
在写入 csv 文件的行时,writerow() 方法报错:
csv_writer.writerow(head)
UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\u2022’ in position 0: illegal multibyte sequence
解决过程记录了一些弯路,可直接跳到解决方法
解决过程
把这个无法读取的 ‘\u2022’ 单独拎出来试了一下,果然是 writerow() 不能读取所有的 unicode 编码:
import csv
with open('test_csv.csv', 'w', newline='') as file:
csv_writer = csv.writer(file)
head = ['\u2022']
csv_writer.writerow(head)
查了一下,’\u2022’ 是特殊字符:间隔号
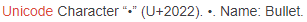
上网搜了下,说要把 csv 包改成 unicodecsv
import unicodecsv as csv
改完之后美滋滋地等着,结果又报错!
TypeError: write() argument must be str, not bytes
原来 unicodecsv 只能读字符串
于是用 ‘•’ 替换 ‘\u2022’
head = ['•']
还是报错。。
TypeError: write() argument must be str, not bytes
解决方法
继续上网搜索,发现其实只用把解码方式改成 utf-8 就可以了:
encoding=‘utf_8_sig’
代码:
import csv
with open('test_csv.csv', 'w', newline='', encoding='utf_8_sig') as file:
csv_writer = csv.writer(file)
head = ['\u2022']
# head = ['•']
csv_writer.writerow(head)
head = [’\u2022’] 和 head = [’•’] 都能运行出来
疑问
拿之前查到的 unicodecsv 试了一下
就算把编码方式改成了 utf-8 或者 utf_8_sig,还是报错:TypeError,不管用 head = [’\u2022’] 还是 head = [’•’] 都不行。。。















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









