






本系统(程序+源码+数据库+调试部署+开发环境)带文档lw万字以上,文末可获取源码
系统程序文件列表
开题报告内容
一、选题背景
关于个性化电影推荐系统的研究,现有研究多集中在利用用户的部分行为数据(如观看历史、评分等)构建推荐模型,专门针对基于Web的多源用户上网数据(包括浏览历史、搜索记录等)来构建个性化电影推荐系统的研究较少。在国内外的研究成果中,部分推荐系统存在推荐结果准确性不高、无法充分挖掘用户潜在兴趣等问题。目前存在的争论焦点在于如何在复杂的Web环境下,全面且准确地获取用户兴趣以提高推荐的精准度。本选题将以Web环境为研究情景,重点分析和研究如何利用Web中的多种用户数据构建精准的个性化电影推荐系统,以期探寻提高电影推荐精准度的问题原因,提出相应的对策建议,为后续更加深入的研究提供基础。这一研究是有价值的,旨在提升电影推荐系统的性能,满足用户个性化的电影需求。
二、研究意义
本选题针对基于Web的个性化电影推荐系统等问题的研究具有重要的理论意义和现实意义。
- 理论意义:本选题研究将对个性化推荐系统的相关理论基础进行深入的剖析。例如完善用户兴趣模型的构建理论,通过深入研究Web环境下用户的多种行为数据与电影推荐之间的关系,进一步丰富个性化推荐算法的理论体系。
- 现实意义:随着网络电影资源的爆炸式增长,用户在海量电影中找到自己感兴趣的电影变得困难。本研究可以构建出更精准的个性化电影推荐系统,提高用户体验,帮助电影平台更好地满足用户需求,增加用户粘性,同时也有助于电影产业的发展,例如促进小众电影的推广等。
三、研究方法
本研究将采用多种研究方法相结合的方式:
- 文献分析法:通过查阅大量国内外关于个性化推荐系统、电影推荐系统以及Web数据挖掘的文献资料,了解目前的研究现状、成果以及存在的问题,为本研究提供理论基础和研究思路的借鉴。例如参考[1]中的基于用户上网数据构建电影知识图谱的方法,以及[3]中利用Web日志构建个性化推荐系统的思路。
- 软件工程方法:按照软件工程的规范流程进行系统的开发。包括需求分析、系统设计、编码实现、测试等阶段,确保系统的质量和可靠性。
- 功能分析法:针对系统的用户、电影分类、电影信息等功能进行详细分析。明确各功能的需求和相互关系,为系统的设计和实现提供依据。
四、研究内容
- 用户模块:深入研究用户在Web环境下的行为数据,包括浏览历史、搜索记录、收藏等。分析如何通过这些数据准确地构建用户兴趣模型,例如如何从杂乱的浏览历史中提取出与电影相关的有效信息,以及如何根据不同的用户行为确定其对电影的兴趣权重。
- 电影分类模块:研究电影分类的标准和方法,如何根据电影的类型、年代、地域、导演、演员等多维度信息进行合理分类。同时考虑如何在推荐过程中利用电影分类信息,提高推荐的准确性和多样性。例如,对于喜欢科幻电影的用户,不仅推荐热门科幻电影,还能挖掘出小众但高质量的科幻电影。
- 电影信息模块:探讨如何获取全面的电影信息,包括电影的剧情简介、评分、评论等。研究如何利用这些信息来完善电影的特征表示,以便更好地与用户兴趣模型进行匹配。例如,分析电影评论中的情感倾向,作为电影推荐的一个参考因素。
五、拟解决的主要问题
- 在基于Web的环境下,如何有效地收集和整合各种用户数据,以准确地把握用户的电影兴趣偏好,解决目前电影推荐系统中推荐结果与用户实际兴趣不符的问题。
- 如何利用电影的多维度信息(如分类、评论等)构建高效的推荐算法,提高推荐系统的准确性和多样性,避免推荐结果的单一性和局限性。
六、研究方案
- 可能遇到的困难和问题
- 数据获取与整合方面:Web环境中的用户数据来源广泛且格式多样,获取和整合这些数据可能面临技术难题,例如不同网站的数据格式不一致,可能存在数据隐私和安全问题等。
- 算法构建方面:构建一个准确且高效的个性化电影推荐算法是具有挑战性的。需要考虑如何平衡推荐的准确性和多样性,以及如何处理新用户和冷启动问题(新用户没有足够的行为数据时如何进行推荐)。
- 电影信息的更新与维护:电影信息是动态变化的,如电影的评分、评论等会随着时间不断更新,如何及时获取和更新这些信息,并将其反映到推荐系统中是一个问题。
- 解决的初步设想
- 数据获取与整合方面:采用数据爬虫技术和数据清洗工具,按照统一的标准对获取的数据进行格式化处理。同时,遵守相关法律法规和数据使用规范,确保数据的隐私和安全。
- 算法构建方面:参考已有的优秀推荐算法,如基于协同过滤和内容推荐的算法,并根据本研究的特点进行改进。对于新用户,可以采用基于热门电影或者用户注册时选择的基本电影偏好进行初步推荐,随着用户行为数据的增加,逐渐优化推荐结果。
- 电影信息的更新与维护方面:建立数据更新机制,定期获取电影的最新信息。利用自动化脚本和数据更新接口,及时更新电影数据库中的相关信息,并调整推荐算法中的相关参数以适应新的信息。
七、预期成果
- 完成一个基于Web的个性化电影推荐系统的设计与实现,系统能够有效地收集用户在Web环境下的行为数据,准确地分析用户的电影兴趣偏好。
- 通过对电影分类、电影信息等多方面的研究和处理,构建出高效的推荐算法,使系统的推荐结果具有较高的准确性和多样性。
- 撰写一篇完整的毕业设计论文,详细阐述基于Web的个性化电影推荐系统的研究背景、意义、方法、内容以及成果等方面的内容。
进度安排:
|
阶段 |
工作内容 |
起止时间 |
备注 |
|
一 |
收集资料规划大纲,完成论文一稿 |
2024-08-05至2024-09-05 | |
|
二 |
完善论文结构和内容,完成论文二稿 |
2024-09-05至2024-10-05 | |
|
三 |
修改论文格式排版,完成论文三稿 |
2024-10-05至2024-10-25 | |
|
四 |
细节完善,完成论文定稿 |
2024-10-25至2024-10-30 |
参考文献:
[1] 张浩洋,顾丹鹏,陈肖勇. 基于 Vue 的数据管理平台实践与应用 [J]. 计算机时代,2022(07): 66-67+72.
[2] 方生. 基于 Vue.js 前端框架技术的研究[J]. 电脑知识与技术,2021,17(19): 59-60.
[3] 张钊源, 刘晓瑜, 鞠玉霞. Node.js后端技术初探[J]. 中小企业管理与科技(上旬刊), 2020, (08): 193-194.
[4] 李骞. 基于Node.js的高性能应用服务平台构建[J]. 中国传媒科技, 2018, (10): 48-49+56.
[5] 谢征. 官方微信及其在报刊媒体中的运用 [J]. 出版发行研究,2013(09): 72-76.
[6] 唐榜. 基于 Node.js 的 Web 服务端框架研究与实现[D]. 西南科技大学,2021.
[7] 高玉民,翟浩然. 基于 Node.js 的分布式爬虫系统[J]. 电子技术与软件工程,2019, (20): 16-17.
[8] 熊俊雄, 陆海洪, 周志文, 兰伟发, 朱师琳, 徐元中. 基于express的内容发布系统[J]. 电子世界, 2019, (11): 14-16.
[9] 和凌志. iOS企业级应用开发技术[M]. 电子工业出版社: 201710. 261.
[10] 兰天, 张荣庆, 梁乾. Excel协同汇总的Nodejs算法解决方案[J]. 数码世界, 2020, (02): 39.
[11] 胡扬帆. 使用Node.js技术,建设灵活高效的企业级Web系统[J]. 中国传媒科技, 2018, (04): 15-18.
[12] 蔡洁锐. 基于 Web 页面的大规模数据可视化系统研究 [J]. 机电工程技术,2017, 46(06): 107-108.
[13] 李骞. 基于 Node.js 的高性能应用服务平台构建[J]. 中国传媒科技,2018, (10): 48-49+56.
[14] 黄可. 基于 Vue 的信息融合界面开发方案的设计与实现[J]. 信息技术与标准化,2022(03): 79-82.
[15] 明博文. 基于混合分析的 Node.js 平台注入漏洞攻击检测与自动修复[D]. 华中科技大学,2022.
以上是开题是根据本选题撰写,是项目程序开发之前开题报告内容,后期程序可能存在大改动。最终成品以下面运行环境+技术+界面为准,可以酌情参考使用开题的内容。要本源码参考请在文末进行获取!!
系统环境搭建步骤:
1.访问Node.js官网下载并安装适用于Windows的Node.js版本,确保安装过程中包含NPM。安装完成后,通过命令提示符验证Node.js和NPM的安装情况。
2.搭建Vue.js前端开发环境,使用npm或Vue CLI安装Vue.js,并创建Vue项目进行前端开发与本地测试。接着,从MySQL官网下载并安装MySQL Server,设置root用户密码,并可选安装Navicat作为数据库管理工具。
3.配置Navicat连接到本地MySQL数据库。
4.开发Node.js后端,创建项目并安装如Express等所需的npm包,编写后端代码,前端利用Vue.js等前端技术栈实现用户界面和用户交互逻辑;同时,后端使用Node.js等技术实现业务逻辑、数据处理以及与前端的数据交互。并实现与MySQL数据库的连接。
技术栈:
前端:Vue.js、npm、Vue CLI
后端:Node.js、NPM、Express、MySQL
开发工具:Vscode、mysql5.7、Navicat 11
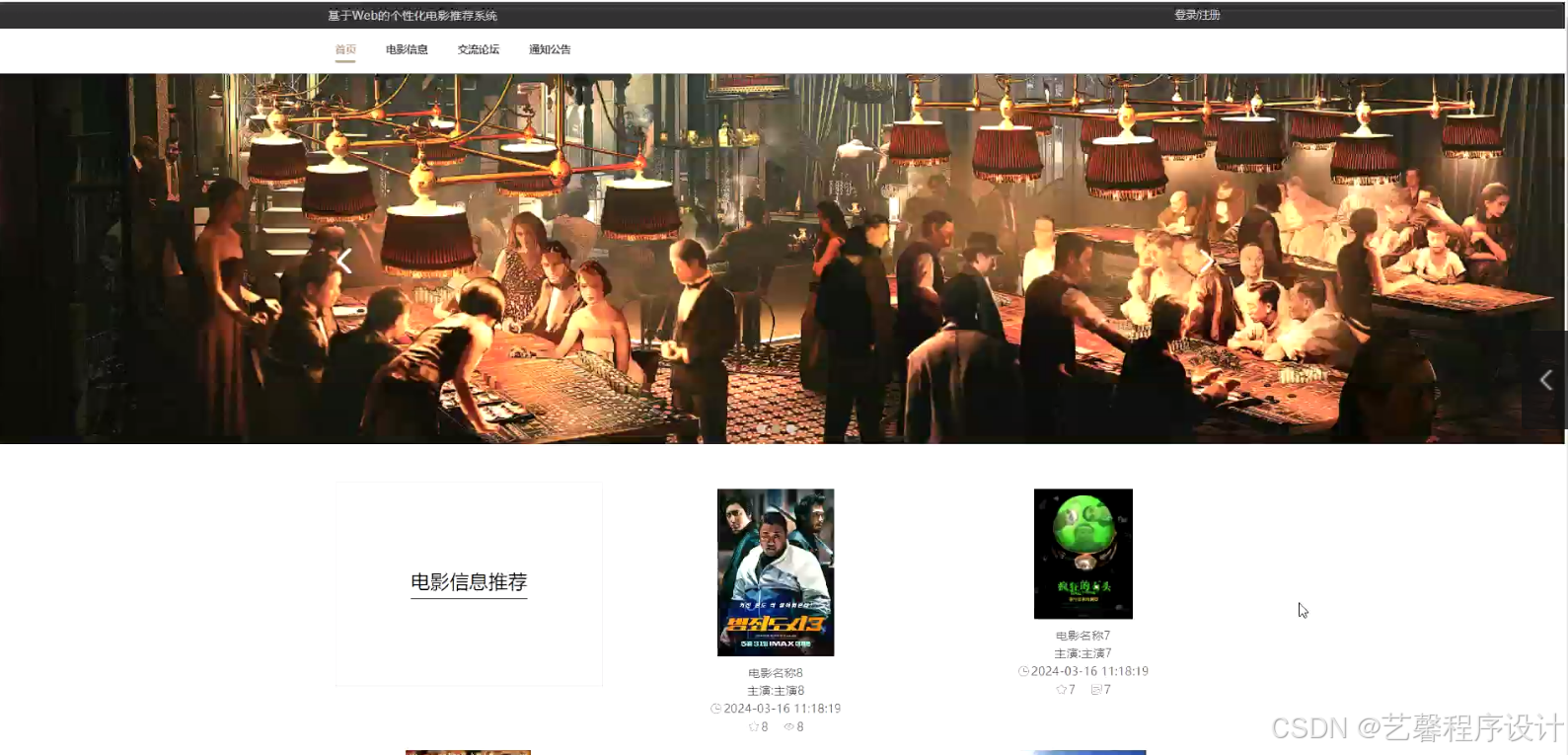
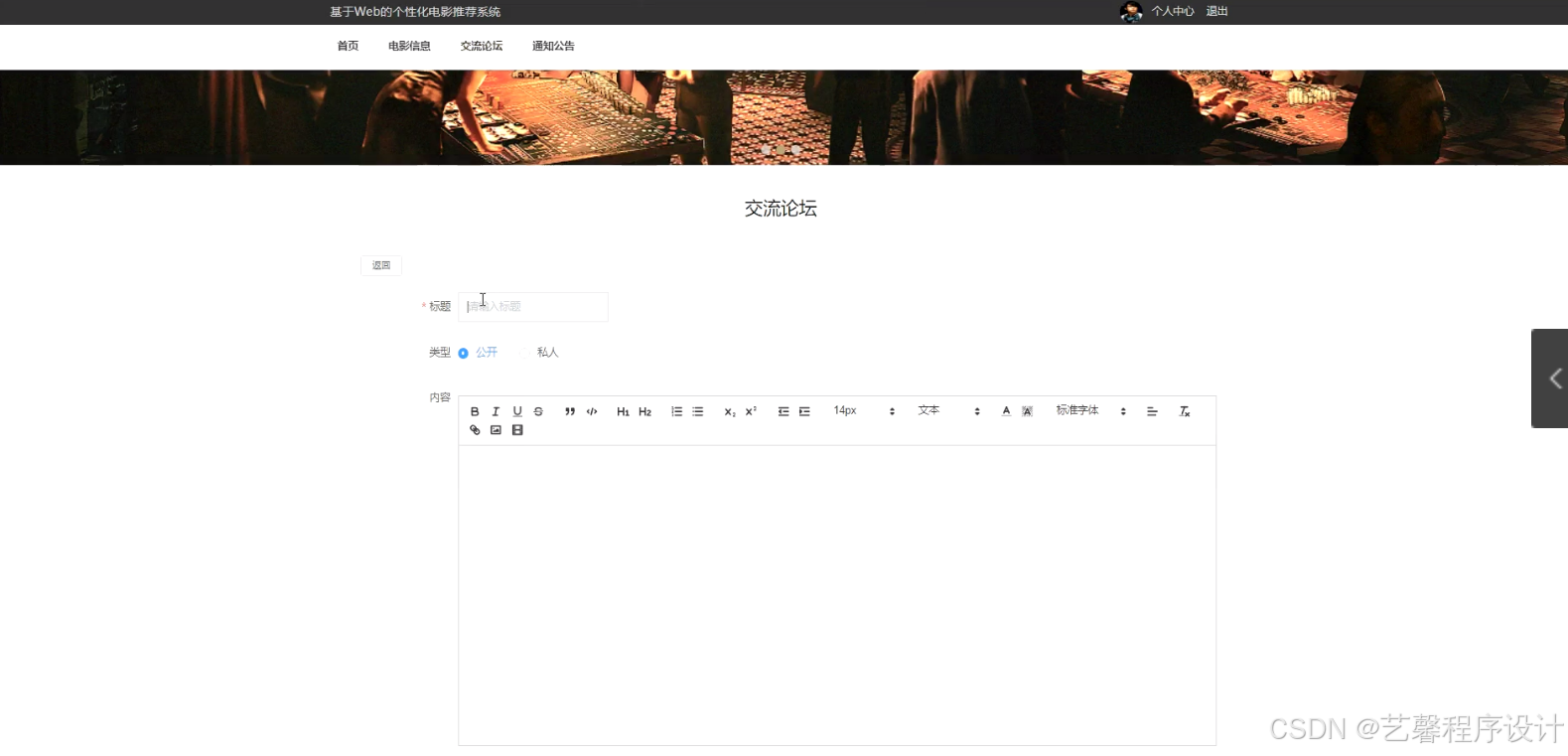
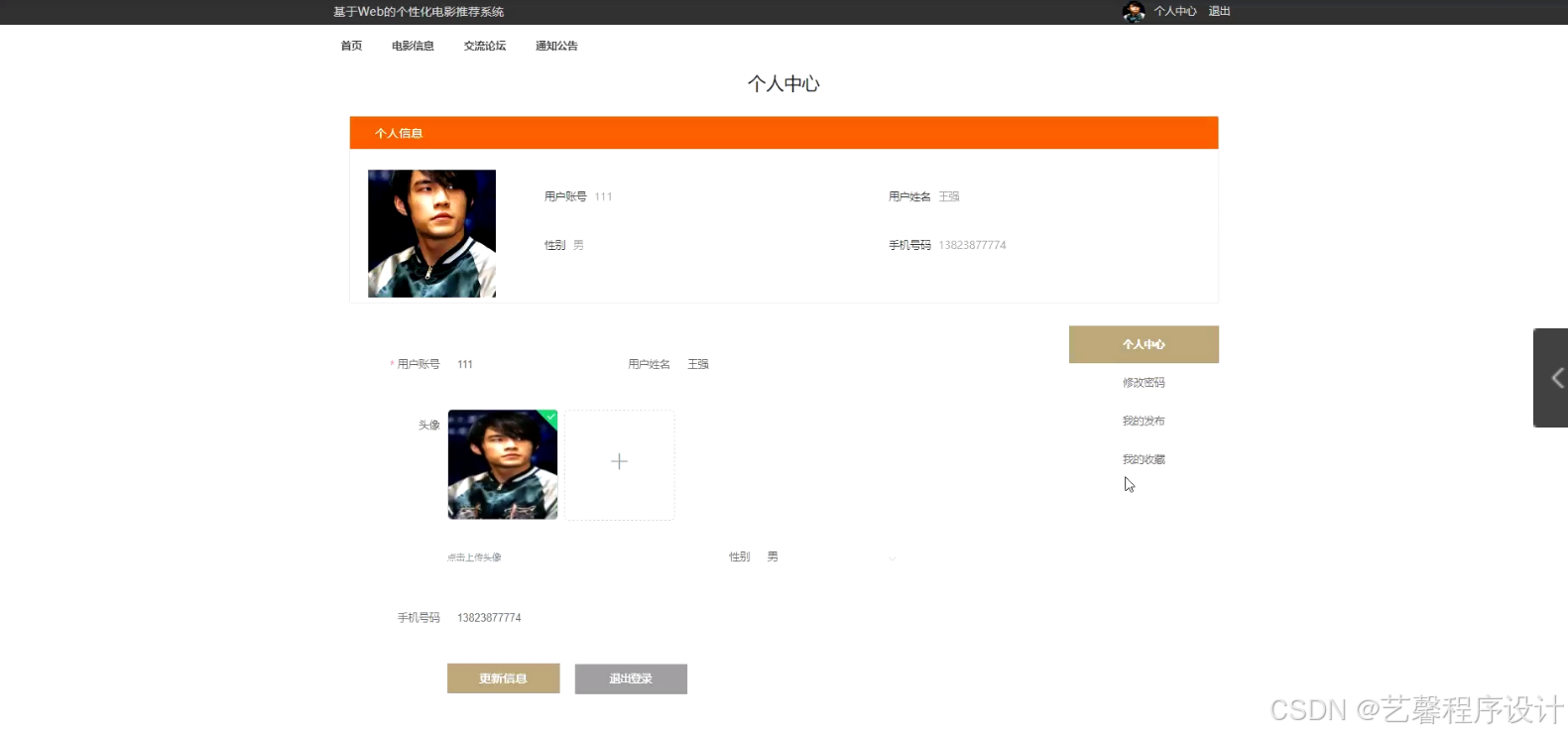
毕设程序界面:
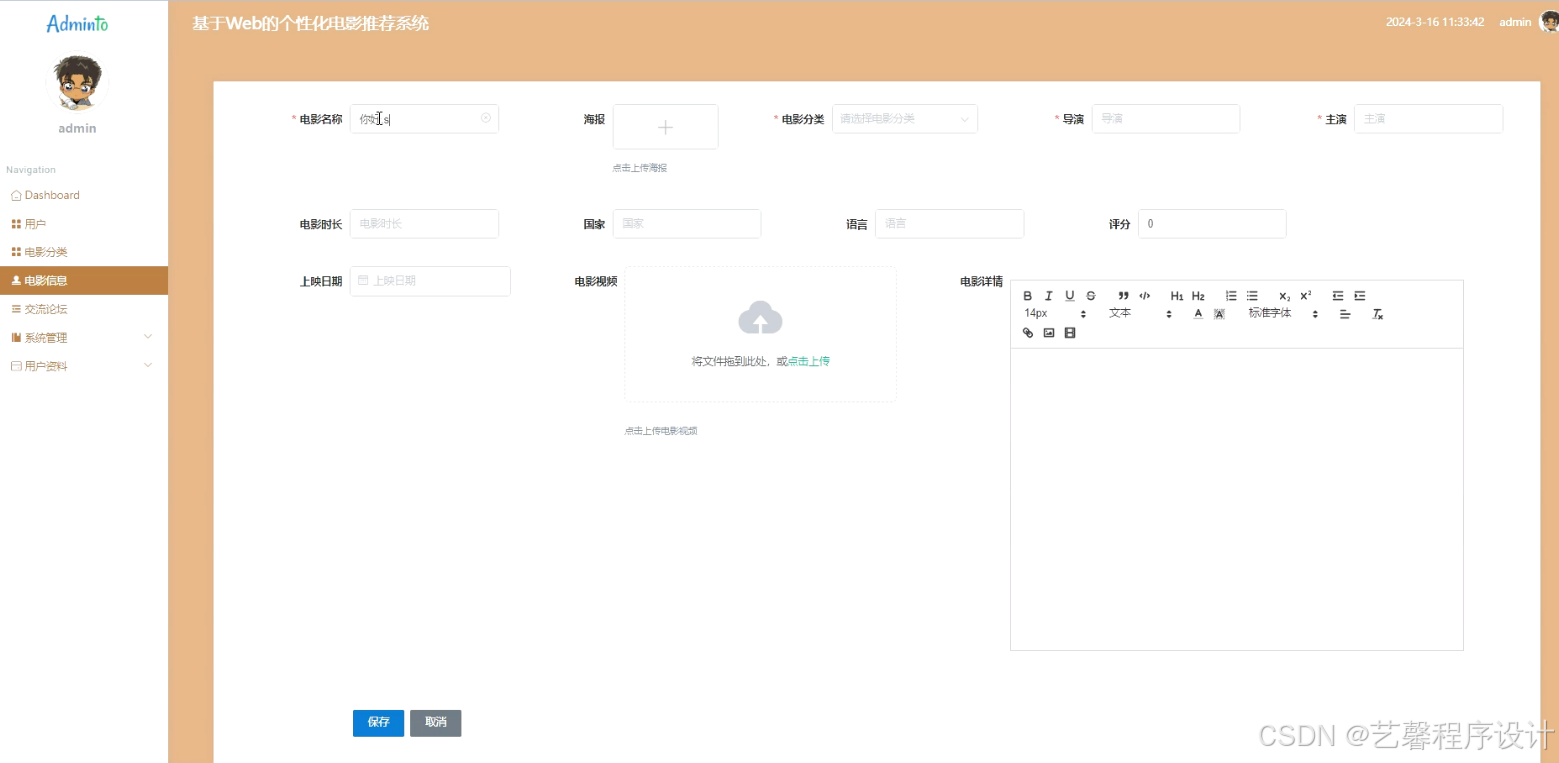
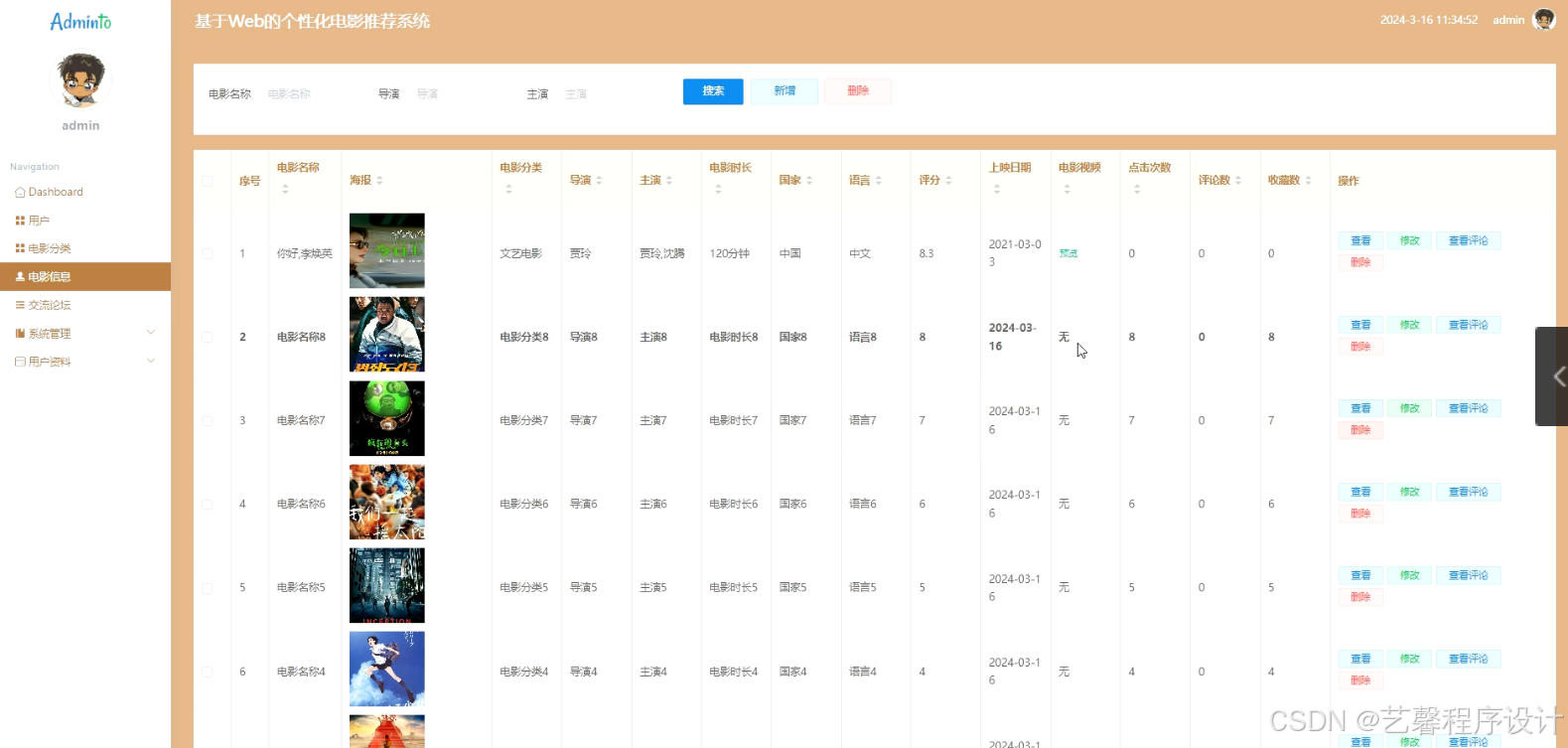
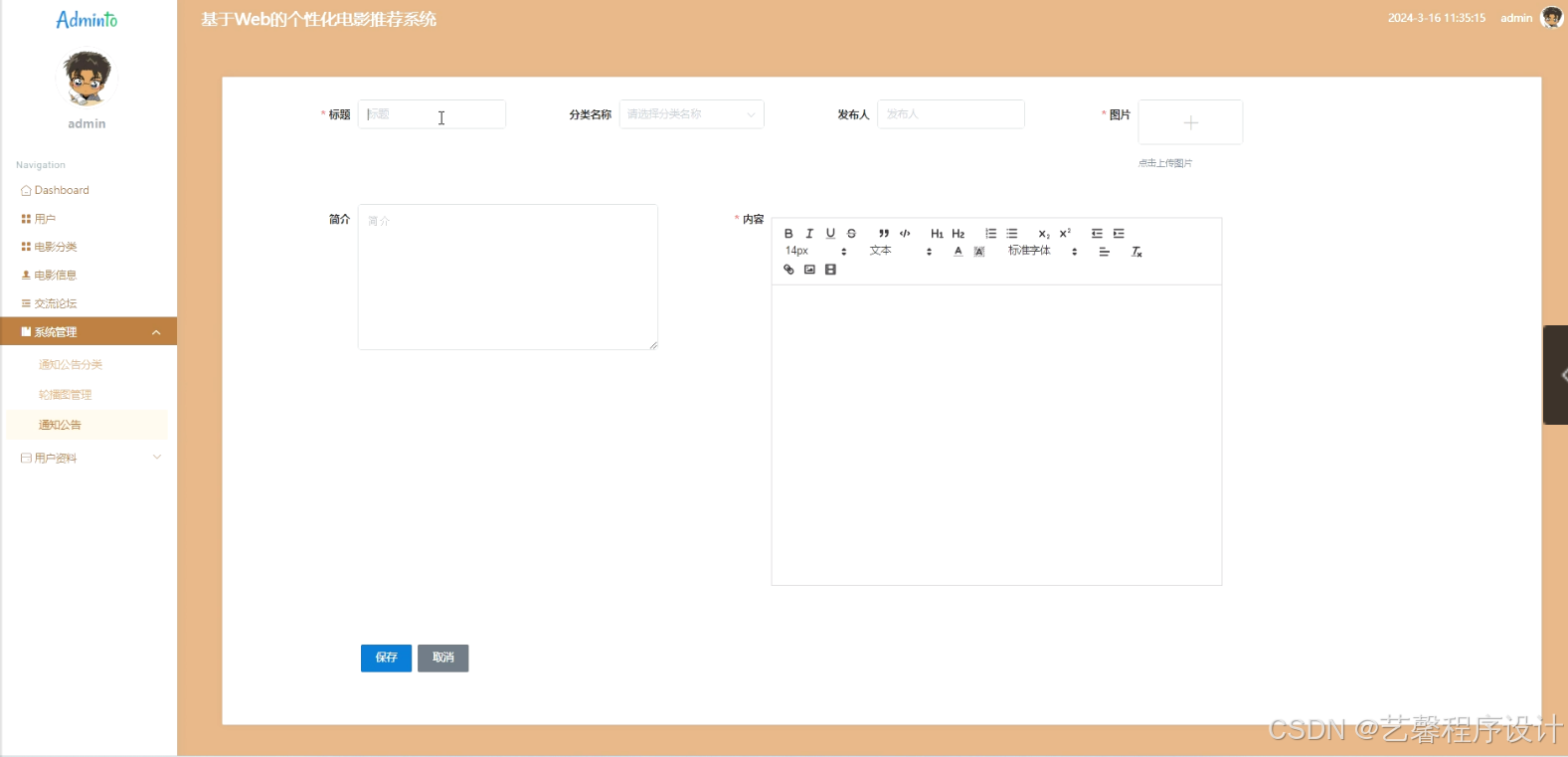
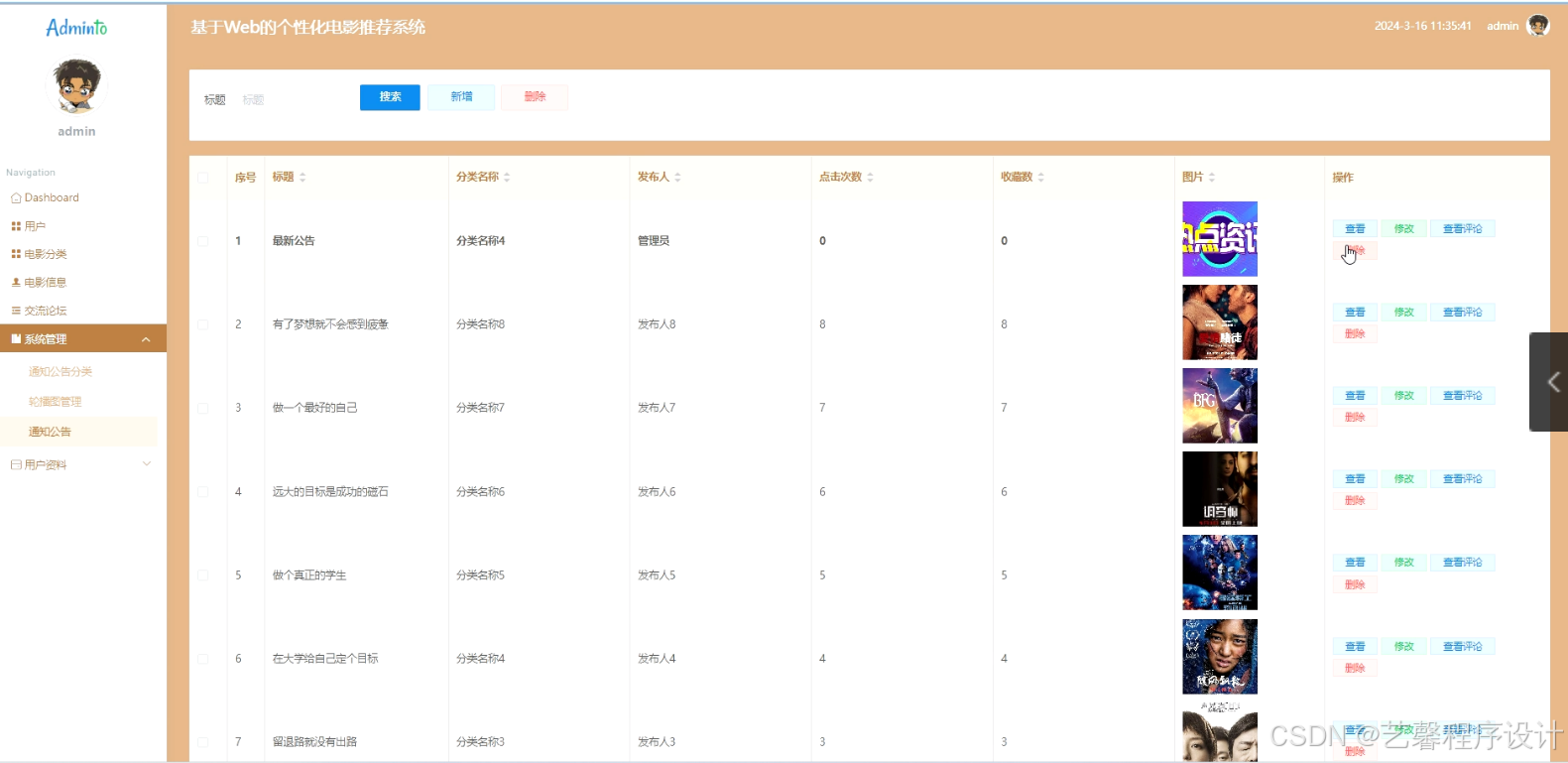
源码、数据库获取↓↓↓↓


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









