







在前面的文章“Mongodb的主从模式搭建实例”中,我们对如何搭建一个主从结构的Mongodb服务器环境进行了简单的介绍。但是对于主从结构,Mongodb官方并不推荐我们使用了,可能是因为主从模式存在以下两个缺点:
(1)主节点不可用之后,无法自动切换到从节点,无法确保业务访问的不间断性;
(2)所有的读写操作都是对主节点的,造成主节点的访问压力较大;
因此,Mongodb为我们提供了另外一种推荐的使用方法,那就是使用副本集ReplicaSets。在这篇文章中简单描述一下副本集是如何实现的,又是如何解决以上两个问题的。
首先我们先来搭建一个副本集(因为没有那么多服务器机器,这里采用在一台机器上,使用不同的端口号模拟不同的机器上的Mongodb实例)。
第一步:我们在本机的1111、2222和3333三个端口上启动三个不同的Mongodb实例;
mongod --port 1111 --dbpath F:/mongodb1/data/db --logpath F:/mongodb1/data/log/mongodb.log --replSet test --logappend
mongod --port 2222 --dbpath F:/mongodb2/data/db --logpath F:/mongodb2/data/log/mongodb.log --replSet test --logappend
mongod --port 3333 --dbpath F:/mongodb3/data/db --logpath F:/mongodb3/data/log/mongodb.log --replSet test --logappend
在这里我们启动了三个Mongodb实例,并指定了相应的数据目录和日志目录,需要说明的是,这里需要使用--replSet说明该Mongodb实例是副本集中的节点,而该副本集的名称是test。
第二步:登录到一个实例上,编写指令,将三个不同的Mongodb实例结合在一起形成一个完整的副本集;
config_test={"_id":"test",members:[
{_id:0,host:"127.0.0.1:1111"},
{_id:1,host:"127.0.0.1:2222"},
{_id:2,host:"127.0.0.1:3333"},
]};
这里,members中可以包含多个值,这里列举的就是刚才启动的三个Mongodb实例,并且通过_id字段给副本集起了名字test。
第三步:通过执行下面的命令初始化副本集。
rs.initiate(config_test);
这里使用上面的配置初始化Mongodb副本集。
通过上面的三步,便可以简单的搭建起一个由三个Mongodb实例构成的名称为test的副本集了。如果想查看副本集的状态,可以使用rs.status()命令来进行查看。
副本集现在搭建起来了,那么这个副本集能不能解决我们上面主从模式的两个问题呢?
我们首先从第一个问题开始看,我们将1111端口的Mongodb服务器给关闭,然后我们使用rs.status()命令来查看下,如下所示:
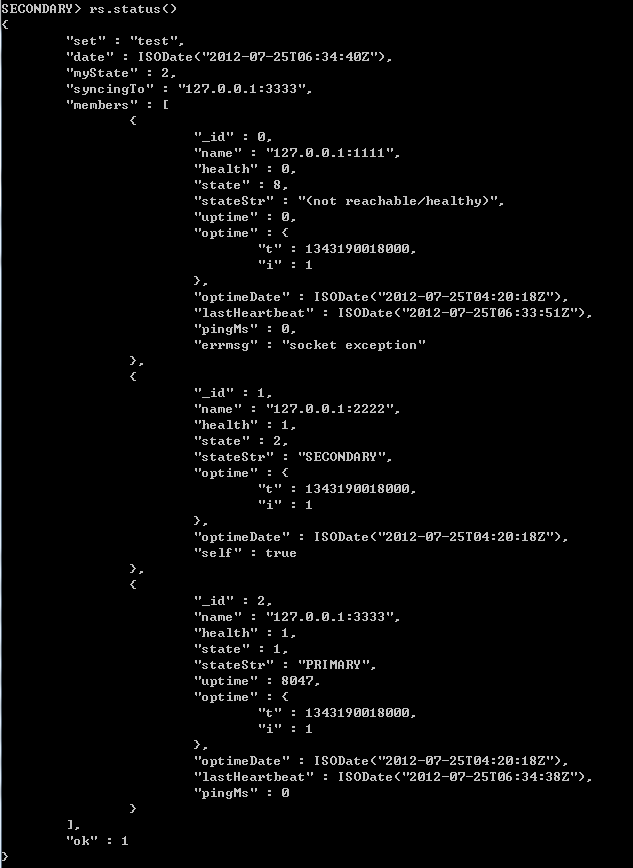
在这里,需要对返回信息中的个别字段进行简单说明,health表示副本集中该节点是否正常,0表示不正常,1表示正常;state表示节点的身份,0表示非主节点,1表示主节点;stateStr用于对节点身份进行字符描述,PRIMARY表示主节点,SECONDARY表示副节点;name是副本集节点的ip和端口信息,等等。
从返回包信息中,可以看到关闭1111端口后,在副本集节点的状态中该节点是不可达的,重新选取产生的主节点是3333端口上启动的Mongodb实例,至于选取的流程在后面的文章中将会讲到,这里简单讲一点,当主节点挂掉之后,其他节点可以发起选举行为,只要在选举过程中某个节点得到副本集节点数一半以上的选票并且没有节点投反对票,那么该节点就可以成为主节点。
在1111端口上的Mongodb实例挂掉之后,3333成为了新的主节点,可以实现自动切换,因此解决了第一个问题。
至于第二个问题,那就是主节点负责所有的读写操作造成主节点压力较大,那么在副本集中如何解决这个问题了呢?正常情况下,我们在Java中访问副本集是这样的,如下所示:
<span style="font-family:KaiTi_GB2312;font-size:18px;">public class TestMongoDBReplSet {
public static void main(String[] args) {
try {
List<ServerAddress> addresses = new ArrayList<ServerAddress>();
ServerAddress address1 = new ServerAddress("127.0.0.1" , 1111);
ServerAddress address2 = new ServerAddress("127.0.0.1" , 2222);
ServerAddress address3 = new ServerAddress("127.0.0.1" , 3333);
addresses.add(address1);
addresses.add(address2);
addresses.add(address3);
MongoClient client = new MongoClient(addresses);
DB db = client.getDB( "test");
DBCollection coll = db.getCollection( "test");
// 插入
BasicDBObject object = new BasicDBObject();
object.append( "key1", "value1" );
coll.insert(object);
DBCursor dbCursor = coll.find();
while (dbCursor.hasNext()) {
DBObject dbObject = dbCursor.next();
System. out.println(dbObject.toString());
}
} catch (Exception e) {
e.printStackTrace();
}
}
} </span>但是,上面不能做到在副本集中读写压力分散,其实在代码层面,我们可以设置再访问副本集的时候只从副节点上读取数据。副本集读写分离结构如下图所示:
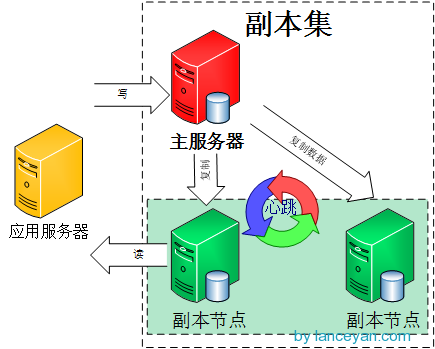
为了在副本集上实现读写分离,我们需要实现以下两步:
(1)在副本节点上设置setSlaveOk;
(2)代码层面,在读操作过程中设置从副本节点读取数据,如下所示:
<span style="font-family:KaiTi_GB2312;font-size:18px;">public class TestMongoDBReplSet {
public static void main(String[] args) {
try {
List<ServerAddress> addresses = new ArrayList<ServerAddress>();
ServerAddress address1 = new ServerAddress("127.0.0.1" , 1111);
ServerAddress address2 = new ServerAddress("127.0.0.1" , 2222);
ServerAddress address3 = new ServerAddress("127.0.0.1" , 3333);
addresses.add(address1);
addresses.add(address2);
addresses.add(address3);
MongoClient client = new MongoClient(addresses);
DB db = client.getDB( "test");
DBCollection coll = db.getCollection( "test");
BasicDBObject object = new BasicDBObject();
object.append( "key1", "value1" );
ReadPreference preference = ReadPreference.secondary();
DBObject dbObject = coll.findOne(object, null , preference);
System. out .println(dbObject);
} catch (Exception e) {
e.printStackTrace();
}
}
} </span>
读参数除了secondary以外,还有其他几个参数可以使用,他们的含义分别如下所示:
primary:默认参数,只从主节点上进行读取操作;
primaryPreferred:大部分从主节点上读取数据,只有主节点不可用时从secondary节点读取数据。
secondary:只从secondary节点上进行读取操作,存在的问题是secondary节点的数据会比primary节点数据“旧”。
secondaryPreferred:优先从secondary节点进行读取操作,secondary节点不可用时从主节点读取数据;
nearest:不管是主节点、secondary节点,从网络延迟最低的节点上读取数据。
这样便实现了在副本集上的读写分离了,也就解决了文章最上面所说的第二个问题了。至于副本集中另一个比较重要的地方,主从数据如何同步?如何选举产生新的主节点?副本集中的各个节点如何信息同步?这些问题,将另起一篇文章进行描述,如敢兴趣,可以关注我的博客,谢谢。^_^















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









