







其实这个霍夫曼编码本身不是一个很难的技巧(也是霍夫曼在期末考试的过程中想出来的方案:)),因为中间用到了贪心的思想,所以也在这里列举了出来。这个问题本身在计算机系的很多教材上都出现过。这里权且记录下来。
霍夫曼的编码是这样的。假设我有一组带压缩的文本,里面各个字符出现的频率不同,现在需要对他们进行压缩。比如
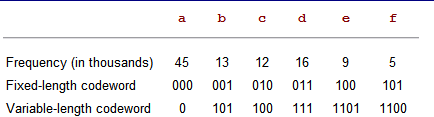
假设我们有100,000个字符的文本.最直观的压缩办法就是原来每个字符要8个bits。现在我一共只有6个字符,那我就把每个字符用3个二进制 位来表示,这样所有100,000个字符用300,000个bit就可以表示了。这种是最直观的方案。但是霍夫曼提出的方案更精妙一些。他提出,基于每个 字符出现的频率不同,可以让出现次数多的字符用更少的二进制位来描述,出现次数少的字符用多一些二进制来描述。比如上图显示的这个Variable- length codeword里面。a出现的频率最高,所以用一个二进制位0来表示。而f出现的频率很小,所以用4个二进制位来表示。这样总共 (45 · 1 + 13 · 3 + 12 · 3 + 16 · 3 + 9 · 4 + 5 · 4) · 1,000 = 224,000 bits。可以看到这个是比原来的方案更优化的解法。
我们一样的还是用一张图来描述霍夫曼编码的流程:
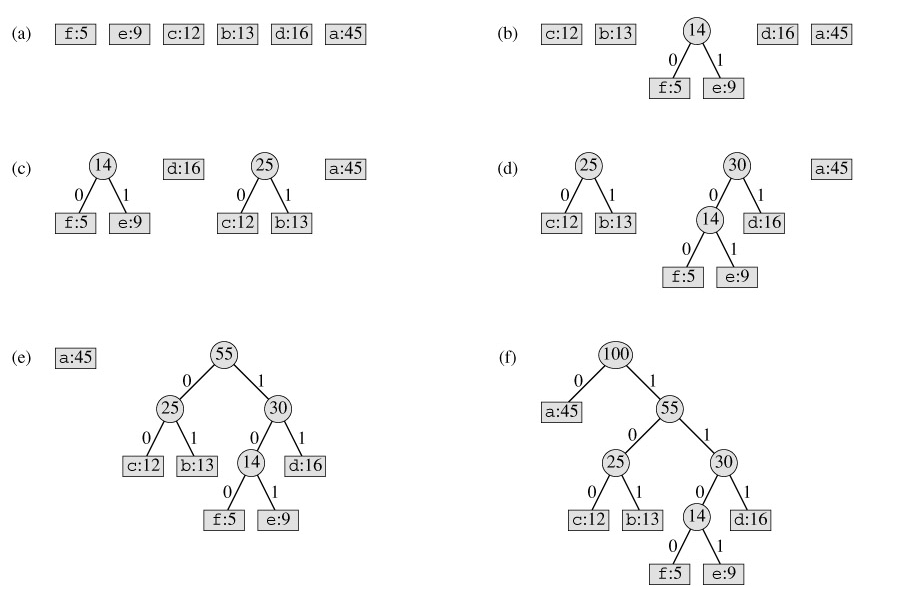
这个过程概括的说就是一个根据频率建立二叉树的过程。建完之后对应的编码也就完成了。
第一步a. 这个a就和之前的活动选择问题一样,把需要的所以字符按照频率排序。
第二部b. 选取出现频率最小的两个节点 f 和 e。组成一个新的节点,新的节点的频率就是e和f的和。原来的e和f分别成了新节点的左子节点和右子节点。(注意这里一个默认的规则就是频率小的是左子节 点,大的是右子节点。)然后把之前的两个节点从原来的组中删除,加新的节点加入排序。
第三部c. 其实和第二部雷同,就是一个循环的过程。这里再次去除队列中的最小频率的两项(这时是c和b)。组成新的节点加入队列排序。
如此循环往复,最后就形成了(f)这个二叉树。现在有了二叉树只有,我们把左子树这条边标记为0,右子树标记为1。这样就差生了对应的编码方式 a=0; b=101;....
下面是对应的代码:















 9189
9189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









