







 本文介绍了递归查询在SQL中的应用,区分了线性递归和非线性递归,探讨了OLAP的概念与星型模式,以及NoSQL数据库的种类和特性,重点讲解了MapReduce框架、键值数据库、文档数据库和图数据库在大数据处理中的作用。
本文介绍了递归查询在SQL中的应用,区分了线性递归和非线性递归,探讨了OLAP的概念与星型模式,以及NoSQL数据库的种类和特性,重点讲解了MapReduce框架、键值数据库、文档数据库和图数据库在大数据处理中的作用。
前言
好耶!终于刷完了。看到进阶课程CS245还挺有意思的,就是找不到公开课,啥时候再去啃啃pdf。
本文是作者学习standford CS145 Introduction to Databases系列视频的第五篇笔记辣,估计是最后一篇,主要包括了第十五章到第十七章的内容:
- 递归查询
- OLAP
- NoSQL
相关参考资料:
OLTP和OLAP的区别:OLAP和OLTP的区别是什么? - 知乎 (zhihu.com)
With Cude 和 With Rollup:Hive中with cube、with rollup、grouping sets用法 - 简书 (jianshu.com)
NoSQL数据库的代表:一文打尽,主流 NoSQL 及应用场景详解~ - 知乎 (zhihu.com)
一、递归查询
1. 基本介绍
1.1 WITH AS语句
利用WITH AS语句为查询语句指定一个标识符,方便其他查询去调用
With RI As (query_1)
R2 As (query_2)
Rn As (query_n)
<query involving Rl, ..., Rn (and other tables)>
指定为RECURSIVE表示允许语句自身递归调用以及语句之间相互递归
With Recursive
RI As (query_1)
R2 As (query_2)
Rn As (query_n)
<query involving Rl, ..., Rn (and other tables)>
一般来说,使用RECURSIVE时,查询语句应该满足以下形式
With Recursive
R As (base query
Union
recursive query)
<query involving R (and other tables)>
在这里使用Union而不是Union All是为了避免不断加入重复值,使递归得以终止
1.2 线性递归(Linear Recursion)
在recursive query中只递归调用自身一次的,叫做线性递归
常用于表中每个元组指定了直接的上下级关系,要求找到所有的无论直接或间接的上下级关系
示例如下:
(1) 已有表ParentOf(parent, child),给定一个名字,找到他所有的祖先
with recursive
Ancestor(a,d) as (select parent as a, child as d from ParentOf
union
select Ancestor.a, Parentof.child as d
from Ancestor, ParentOf
where Ancestor.d = Parentof.parent)
select a from Ancestor where d = 'Mary'
(2) 已有表
Project(name, mgrID) 包含项目的名字及其项目负责人(警觉)
Manager(mID, eID) 表示上下级关系,mID为上级的ID,eID为下级的ID
Emplyee(ID, salary) 表示员工的薪水
现求:给定一个项目的名字,求这个项目之下所有人的薪水总和
--思路:先找到项目之下的所有人的ID,再与Employee表联合查询薪水总和
with recursive
ProjectEmps as ( select mgrID as ID from Project where name = 'ProjectName'
union
select distinct eID as ID
from Manager M, Project P
where M.mID = P.eID )
select sum(salary)
from ProjectEmps
where ID in (select ID from ProjectEmps)
(3) 已有表
Flight(orig, dest, cost) 表示从地点orig直达地点dest的航班需要的消费cost
现求:给定出发地和目的地,求从出发地到目的地的最小消费
--思路:先找到所有直接或间接的路径及其消费,再根据出发地和目的地聚合查询
with recursive
Route(orig, dest, total) as
( select orig, dest, cost as total from Flight
union
select R.orig, F.dest, (cost + total) as total
fromn Route R, Flight F
where R.dest = F.orig )
select min(total) from Route
where orig = 'origName' and dest = 'destName'
但是,当航班出现环时,会引起无限递归,需要限制递归次数,有两种方案:
- 在最后的查询语句中使用limit:直接限制得到的结果数量,缺点是不能聚合查询
- 在递归语句中引入计数变量
--使用limit
with recursive
Route(orig, dest, total) as
( select orig, dest, cost as total from Flight
union
select R.orig, F.dest, (cost + total) as total
fromn Route R, Flight F
where R.dest = F.orig )
select * from Route --不能使用 select min(total),因为这意味着查询期待20个最小值(没有意义)
where orig = 'origName' and dest = 'destName' limit 20 --限制结果只能有20条
--引入计数变量,计算路径的长度并加以限制
with recursive
Route(orig, dest, total, length) as
( select orig, dest, cost, 1 as total from Flight --直达航班路径长度为1
union
select R.orig, F.dest, (cost + total) as total, (R.length + 1) as length
fromn Route R, Flight F
where R.dest = F.orig and R.length < 10) --限制路径长度不能超过10
select min(total) from Route
where orig = 'origName' and dest = 'destName'
2. 非线性递归和互相递归
2.1 非线性递归(Non-linear Recursion)
与线性递归相对地,非线性递归在递归语句中会多次引用自身。
通过以下示例,让我们思考非线性递归有什么特点:
with recursive
Ancestor(a,d) as (select parent as a, child as d from ParentOf
union
select A1.a, A2.d
from Ancesror A1, Ancestor A2
where A1.d = A2.a)
select a from Ancestor where d = 'Mary'
在该示例中,我们连接两个Ancestor,而不是像前面一样用一个Ancestor连接原始的ParentOf。不难发现,这种连接方式能用更少的次数收敛到结果
但是由于非线性递归较难实现,SQL标准不要求非线性递归,现有的数据库系统也未实现非线性递归
2.2 互相递归(Mutual Recursion)
相互递归是指多个被标识的递归语句成环地互相调用
(1) Hub and Authority 示例
现有表
Link(src, dest) 表示src到dest存在一条有向边
我们定义
被三个Hub所指的节点称作Authority
指向了三个Authority的节点称作Hub
初始给定两表HubStart(node)包含部分Hub, AuthStart(node)包含部分Authority
现求所有的Hub和Authority
with revursive
Hub as ( select node from HubStart
union
select src as node from Link
where dest in (select node from Auth) --指向Auth
group by src having count(*) >= 3) --按src分组,找到指向Auth大于3的src就是Hub
Auth as ( select node from AuthStart
union
select dest as node from Link
where src in (selcet node from Hub) --被Hub所指
group by dest having count(*) >= 3 --按dest分组,被超过3个Hub所指的dest就是Auth
select * from Hub;
(2) 两种不被允许的情况(在递归语句中)
不允许负依赖(Negative Dependence)的子查询,示例如下:
with revursive
Hub as ( select node from HubStart
union
select src as node from Link
where src not in (select node from Auth) --Hub不能同时为Hub
dest in (select node from Auth)
group by src having count(*) >= 3)
Auth as ( select node from AuthStart
union
select dest as node from Link
where dest not in (select node from Hub) --Auth不能同时为Hub
src in (selcet node from Hub)
group by dest having count(*) >= 3
select * from Hub;
当我们有一个节点同时为Hub和Authority时,它出现在哪个表中取决于我们创建Hub和Auth的顺序。SQL标准觉得这很反人类,于是不允许负依赖
不允许聚合查询
with recursive
R(x) as ( select x from P
union
select sum(x) as x from R )
select * from R
假设P为{1, 2}
那么第一轮R为{1, 2, 3}
第二轮R为{1, 2, 6}
第三轮R为{1, 2, 9}…
视频的解释是:对于R没有很好的定义,于是就不被SQL标准允许了(what?
2.3 小结
SQL标准允许线性递归以及相互递归,未要求非线性递归。
不允许带负依赖的子查询,或者聚合查询的递归语句。
现有数据库系统只有实现了线性递归
Extends expressiveness of SQL
- Basic functionality: linear recursion
- Extended functionality: nonlinear recursion, mutual recursion
- Disallowed: recursive subqueries (negative), aggregation
二、OLAP(Online Analytical Processing)
1. 基本介绍
这几集刷下来就像学了一堆行业黑话,其实说到底OLAP就是用来分析大规模的数据,而不是对小部分的数据做增删改查,后者是传统关系型数据库的主要应用,称为OLTP(Online Transaction Processing)。
两者的对比如下:
| 事务 | 处理的数据规模 | 查询复杂程度 | 更新频率 | |
|---|---|---|---|---|
| OLTP | 短 | 小 | 低 | 频繁 |
| OLAP | 长 | 大 | 高 | 不频繁 |
2. 星型模式(Star Schema)
OLTP组织数据使用的是ER模型,突出实体的特征和实体之间的连接。
OLAP组织数据的模式则是Star Schema,由一个不常更新维度表引用多个经常更新事实表组成:
- 维度表(Dimensions Table):属性一般为各事实表的主键(维度属性)以及其他值(依赖属性),更新不频繁且规模较小。
- 事实表(Fact Table):记录发生的事,更新频繁且规模很大,通常只允许插入
一堆黑话我真的服了,我尽量讲人话吧:
维度表包含三个维度和一个值时,我们给数据建一个三维坐标系,将所有数据看作一个立方体,称作数据立方体(Data Cube)。多个维度和多个值时也可以这么去抽象。
只取坐标系上的一个面,也就是不考虑其中一个维度时,就是对特定维度做聚合操作,称作切片(Slice),给这个维度加限制条件,即对特定维度下特定区间做聚合操作时,称作切块(Dice)
假设我们现在对两个维度分组,现在想更精确地去分析数据,所以要多对一个维度分组,称作钻取(Drill-down)。相反地,我们觉得现在太精细了,想从更高层次对数据分析,所以要少对一个维度分组,称作上卷(Roll-up)。示例如下:
--现在只对两个维度分组
select state, brand, sum(qty*price)
From Sales F, Store S, Item I
Where F.storeID = S.storeID And F.itemID = I.itemID
Group By state, brand
--再加一个维度叫做Drill-down
select state, brand, category, sum(qty*price)
From Sales F, Store S, Item I
Where F.storeID = S.storeID And F.itemID = I.itemID
Group By state, brand, category
--少一个叫做Roll-up
select brand, sum(qty*price)
From Sales F, Store S, Item I
Where F.storeID = S.storeID And F.itemID = I.itemID
Group By brand
3. SQL中的OLAP
SQL标准中,在Group By之后使用With Cude 和 With Rollup以便执行OLAP查询:
- With Cude:查询结果包含各个维度的笛卡尔组合(包括NULL),值为NULL代表对该维度聚合
- With Rollup:一层一层向前Roll-up,即满足前一维度为NULL时,后一维度必定为NULL。适用于有层次结构的数据,比如统计省、市、县的人口
MySQL支持With Rollup,Postgre和SQLite都不支持
然而,With Cude可以由各个维度的With Rollup 做并操作得到,示例如下:
--MySQL不支持with cube
select storeID, itemID, custID,sum(price) from Sales
group by storeID, itemID, custID with cube
--上式可以等价于
select storeID, itemID, custID,sum(price) from Sales
group by storeID, itemID, custID with rollup
union
select storeID, itemID, custID, sum(price) from Sales
group by itemID, custID, storeID with rollup
union
select storeID, itemID, custID, sum(price) from Sales
group by custID, storeID, itemID with rollup;
三、NoSQL
1. 基本介绍
NoSQL中的SQL不是指SQL这种查询语言,而是相对于传统的关系型数据库。No也不是没有的意思,而是Not Only
所以NoSQL就是用其他的关系模式去组织数据,使其能够解决传统关系型数据库不容易甚至不能解决的问题。通常具有以下特点:
- 更灵活的数据组织模式
- 更快地、更少消耗的搭建
- 面向大规模的数据
- 牺牲部分的一致性,允许近似解,去换取更高的性能
+表示优点、-表示缺点
+Flexible schema
+Quicker/cheaper to set up
+Massive scalability
+Relaxed consistency->higher performance & availability
-No declarative querylanguage->more programming
-Relaxed consistency->fewer guarantees
常见的NoSQL数据库包括以下几个类型:
- MapReduce框架(MapReduce framework)
- 键值数据库(Key-Values stores)
- 文档数据库(Document stores)
- 图数据库(Graph database systems)
- 列存储数据库(Column stores)
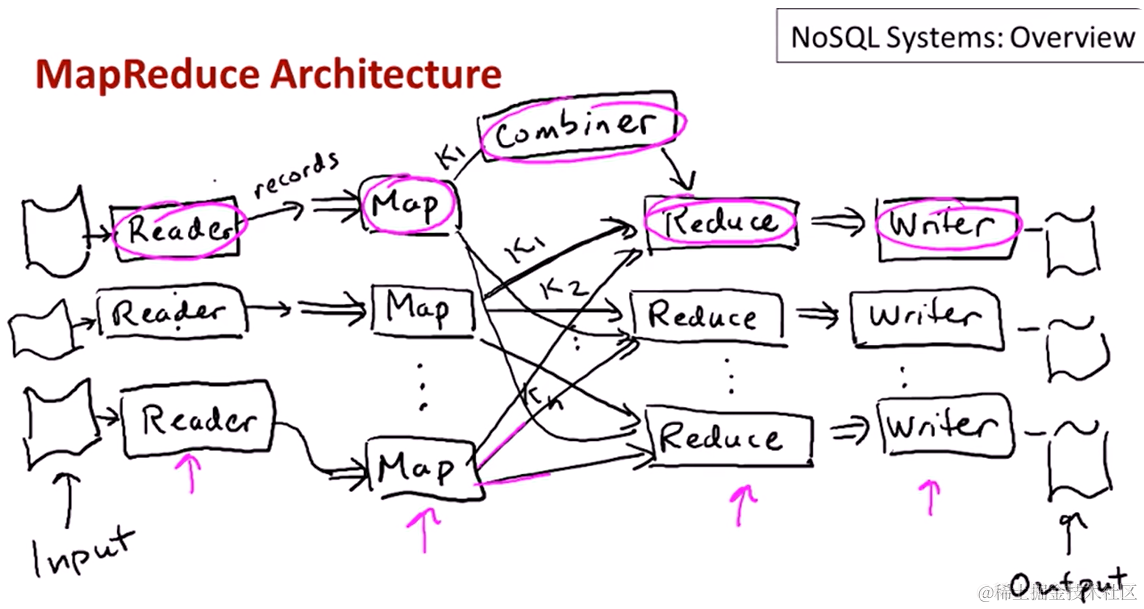
2. MapReduce框架
MapReduce起源于Google,代表为Hadoop
MapReduce框架中
- 没有数据模型,直接从文件输入再输出到文件中
- 由用户提供一系列函数:map(), reduce(), reader(), writer(), combiner()
- 由系统将这些功能粘合(glue)在一起,同时提供容错(fault tolerance)和扩展性(scalability)
其中,
reader()从文件中读取数据,
writer()将结果输出到文件中,
map()提供将问题分解为子问题的方法,
reduce()求解子问题然后合并为结果,
combiner()为可选功能,它位于map()和reduce()之间,对子问题预合并,以提高效率。
3. 键值数据库
键值数据库的代表有Riak、Redis、Memcached、Amazon’s Dynamo、Project Voldemort
键值数据库应用于OLTP,即小部分数据的频繁增删改查
- 数据模型:(key, values) pairs 即键值对
- 操作:
- Insert(key, values) :插入键值对
- Fetch(key):根据键查询值
- Update(key):根据键更新值
- Delete(key):根据键删除键值对
- 有些数据库允许value中有更复杂的结构
- 有些数据库允许在一定范围的查询
4. 文档数据库
文档数据库的代表有MongoDB、CouchDB、RavenDB
文档数据库的数据模型和操作跟键值数据库很像,只不过存储的文档有特定的类型
- 数据模型:(key, document) pairs
- 文档类型:JSON、XML等
- 操作:
- Insert(key, document) :插入键和文档的对
- Fetch(key):根据键查询文档
- Update(key):根据键更新文档
- Delete(key):根据键删除文档
- 可以根据文档类型做查询
5. 图数据库
图数据库的代表有Neo4J、Infinite Graph、OrientDB
不同的图数据库之间实现差别很大
- 数据模型:点集 和 边集
- 节点包含有属性(包括节点的ID)
- 边包含标签(表示节点之间的关系)
















 3484
3484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









