







温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
随着高校新生的增加,学生的数据也越来也多,怎么使用 好这些数据,对数据进行分析和挖掘成为了研究的热点,本次课题就是通过获取某学校的学生相关信息,利用 pandas + Matplotlib + seaborn 等工具包以可视化的方式从不同层面进行数据的分析。
基于大数据的高校生源可视化分析系统
2. 数据读取
df_2019 = pd.read_excel('数据/2019年_3200人.xlsx',sheet_name='mySheet')
df_2020 = pd.read_excel('数据/2020年_3200人.xlsm',sheet_name='mySheet (2)')
df_2021 = pd.read_excel('数据/2021年_2860人.xlsm',sheet_name='mySheet (3)')
3. 数据探索式可视化分析
3.1 各专业填报志愿人数分布情况

2019年和2020年的各专业填报分数分布箱型图可类比绘制出,篇幅限制暂省略。
3.2 各专业的投档成绩分布情况
xueyuan_6_dict = {k: 0 for k in set(df_2019['专业名称'])}
for xueyuan in xueyuan_6_dict:
xueyuan_df = df_2019[df_2019['专业名称'] == xueyuan]
if xueyuan_df.shape[0] == 0:
continue
defen = xueyuan_df['投档成绩'].values
defen = defen[defen > 0]
xueyuan_6_dict[xueyuan] = defen.tolist()
plt.figure(figsize=(16, 10))
plt.boxplot(xueyuan_6_dict.values(), labels = xueyuan_6_dict.keys())
plt.title('2019年各专业填报分数分布箱型图', fontdict={'weight':'normal','size': 20})
pl.xticks(rotation=90)
plt.show()
2019年和2020年的各专业填报分数分布箱型图可类比绘制出,篇幅限制暂省略。
3.3 报考学生户口所在地分布情况
plt.figure(figsize=(16, 6))
plt.subplot(121)
plt.pie(counts, labels = cities)
plt.title('2020年报考学生户口所在城市数量分布饼状图', fontdict={'weight':'normal','size': 12})
plt.subplot(122)
plt.bar(cities, counts, color='#FF5151')
plt.title('2020年报考专业是否需要外语口试数量分布柱状图', fontdict={'weight':'normal','size': 12})
pl.xticks(rotation=45)
plt.show()
3.4 报考学生的外语语种分布饼状图

3.5 需要考察外语口试的专业 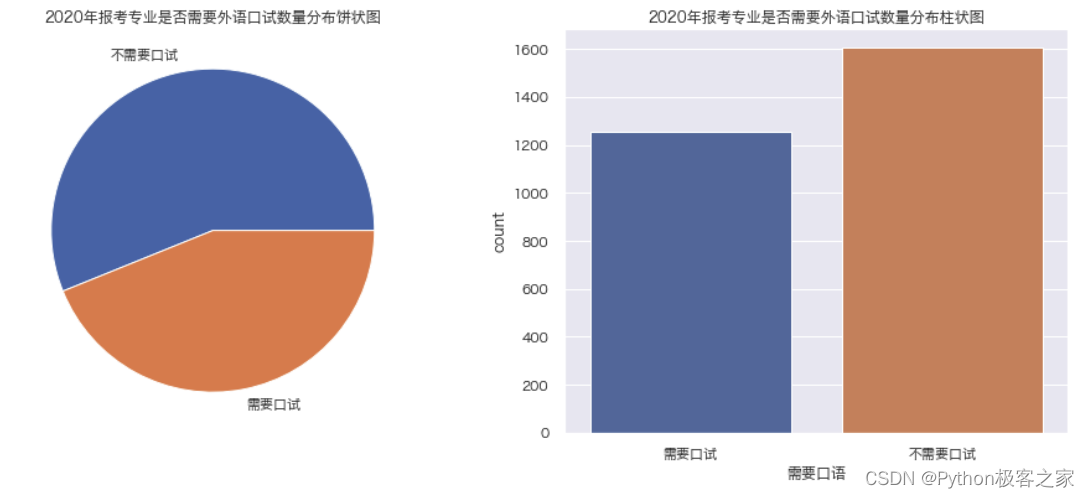
3.6 连续三年招生的专业总分分布情况
plt.figure(figsize=(16, 15))
pl.subplots_adjust(left=0.0,bottom=0.0,top=2,right=1)
xueyuan_count = len(zhuanye['专业名称'])
x = xueyuan_count // 2 + 1
for i, xueyuan in enumerate(zhuanye['专业名称']):
y = 2
z = i + 1
plt.subplot(x, y, z)
zf = df_2019[df_2019['专业名称'] == xueyuan]['投档成绩']
zf = zf[zf > 0]
sns.kdeplot(zf, label='2019年')
zf = df_2020[df_2020['专业名称'] == xueyuan]['投档成绩']
zf = zf[zf > 0]
sns.kdeplot(zf, label='2020年')
zf = df_2021[df_2021['专业名称'] == xueyuan]['投档成绩']
zf = zf[zf > 0]
sns.kdeplot(zf, label='2021年')
plt.title('2019年 ~ 2021年' + xueyuan + '招生总分分布情况', fontdict={'weight':'normal','size': 12})
plt.legend()
plt.show() 3.7 各省招生的录取平均分分布情况
3.7 各省招生的录取平均分分布情况
city_mean_score = df_2021[['户口所在省市', '投档成绩']].groupby('户口所在省市').mean().reset_index()
city_mean_score['热门户口所在地'] = city_mean_score['户口所在省市'].map(lambda x: x in cities)
city_mean_score = city_mean_score[city_mean_score['热门户口所在地'] == True]

plt.figure(figsize=(16, 6))
plt.bar(city_mean_score['户口所在省市'], city_mean_score['投档成绩'], color='#66B3FF')
plt.title('2021年热门城市报考学生平均成绩分布柱状图', fontdict={'weight':'normal','size': 12})
pl.xticks(rotation=45)
plt.show() 4. 总结
4. 总结
随着高校新生的增加,学生的数据也越来也多,怎么使用 好这些数据,对数据进行分析和挖掘成为了研究的热点,本次课题就是通过获取某学校的学生相关信息,利用 pandas + Matplotlib + seaborn 等工具包以可视化的方式从不同层面进行数据的分析。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











