







 共享内存系统中,UMA(Uniform Memory Access)和NUMA(Nonuniform Memory Access)是两种不同的架构。UMA系统中,所有处理器直接连接到同一内存,访问时间一致,提供快速的数据存取。而NUMA系统中,每个处理器可能连接到不同的内存,导致跨节点访问会有额外延迟,适合需要更大内存扩展性的场景。对于性能敏感的程序,通常需要绑定到特定NUMA节点以减少跨节点交互。
共享内存系统中,UMA(Uniform Memory Access)和NUMA(Nonuniform Memory Access)是两种不同的架构。UMA系统中,所有处理器直接连接到同一内存,访问时间一致,提供快速的数据存取。而NUMA系统中,每个处理器可能连接到不同的内存,导致跨节点访问会有额外延迟,适合需要更大内存扩展性的场景。对于性能敏感的程序,通常需要绑定到特定NUMA节点以减少跨节点交互。
共享内存系统中使用一个或者多个多核处理器,这些核之间每个核有自己的L1Cache,其他的Cache可以在核之间进行共享,也可以不进行共享。
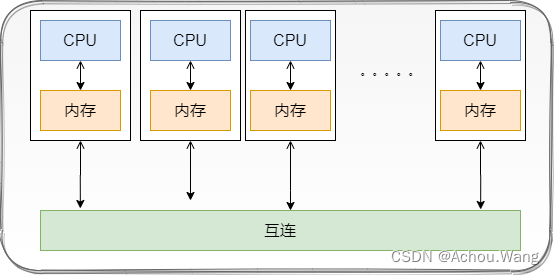
在拥有多个多核处理器的共享内存系统中,互联网络可以将所有的处理器直接连接到主存上,或者将每个处理器直接连接到一块内存,通过处理器内置的特殊的硬件使得各个处理器可以访问内存中的其他块。
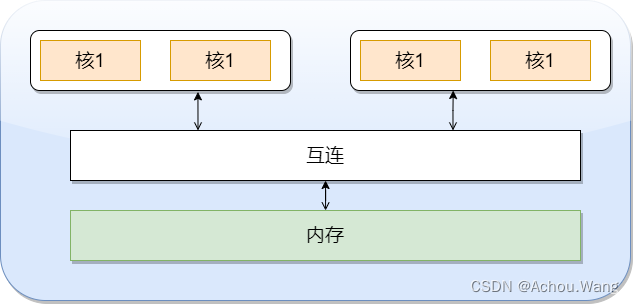
当所有核都链接到一块内存上时,访问内存中任何一个区域的时间都相同,因此又被称为一致内存访问系统UMA(Uniform Memory Access)。
.UMA系统
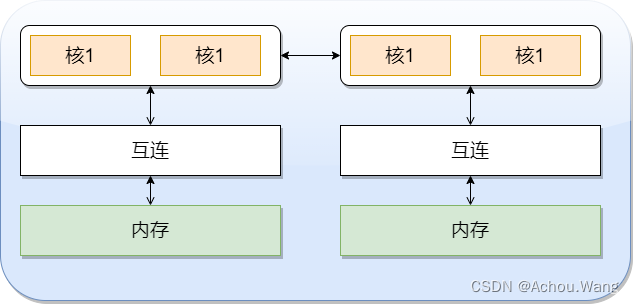
核访问与自己直接相连的内存区域,比访问其它区域快的多,因为访问其它区域需要通过另外一个芯片,因此被称为非一致性内存访问系统NUMA(Nonuniform Memory Access).
.NUMA系统
通过上述两张图可以看出,UMA系统中因为核直接和内存相连,任意一个核都能访问内存中的任何地址,因此当数据存储在内存中不同位置时,UMA系统存取指令和数据更快。NUMA系统中因为内存可以连接到不同的内存上,因此具有更好的内存扩展性。
因为在NUMA系统中想要存取不同内存上的数据时,需要核心直接交互才能实现,跨NUMA会导致几纳秒的时间浪费,因此如果程序对性能比较敏感需要将程序绑定到指定的NUMA上,以此来避免不同NUMA之间核的交互



















 283
283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











