







 超级会员免费看
超级会员免费看
 数据倾斜是指在并行处理中,某个task处理的数据量远超其他task,主要由shuffle操作引起。shuffle会将相同Key的数据拉取到同一节点聚合,可能导致内存不足或I/O瓶颈。通过Spark Web UI和task执行时间、数据量不均匀可判断倾斜。定位倾斜通常通过Web UI、Log日志、代码走读和数据分析。Spark的AQE能缓解但无法完全解决倾斜,实际应用需结合参数调整和特定策略。
数据倾斜是指在并行处理中,某个task处理的数据量远超其他task,主要由shuffle操作引起。shuffle会将相同Key的数据拉取到同一节点聚合,可能导致内存不足或I/O瓶颈。通过Spark Web UI和task执行时间、数据量不均匀可判断倾斜。定位倾斜通常通过Web UI、Log日志、代码走读和数据分析。Spark的AQE能缓解但无法完全解决倾斜,实际应用需结合参数调整和特定策略。

什么是数据倾斜
并行处理数据集的某个task处理的数据明显多于其他task。
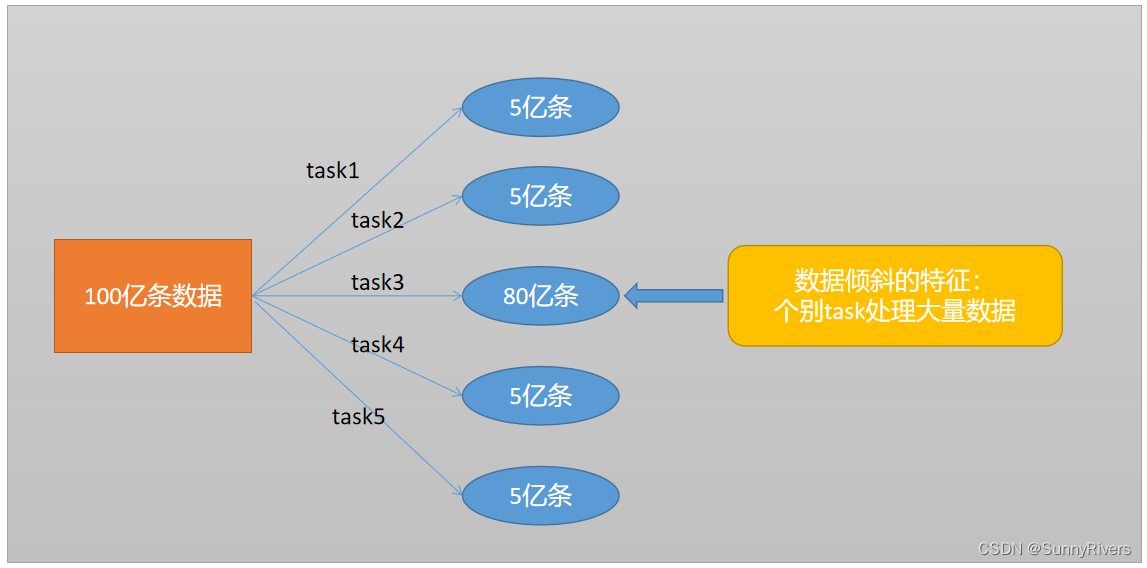
发生数据倾斜的原因
一个词概括:shuffle
在Shuffle的过程中,同样一个Key一般都会交给一个Task去处理,如果某个key特别多,如上图中task3的key有80亿,这样就会造成别的task很快算完,而task3却一直在计算中,对于spark来说下游的stage又必须得等上游stage全部计算完成后才能开始计算,这样task3就成了整个任务的性能瓶颈。
通俗理解shuffle
Shuffle过程,简单来说,就是将分布在集群中多个节点上的同一个Key,拉取到同一个节点上,进行聚合或Join等操作。例如,reduceByKey、joi

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











