






击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识内存溢出是 Java 开发中最常见的问题之一,其原因通常是由于 Java 应用程序在分配对象和执行垃圾回收时使用了过多的内存而导致。在这篇文章中,我将介绍产生内存溢出的原因,以及在 Java 应用程序中如何定位和分析这些问题的方法。
一、产生内存溢出的原因
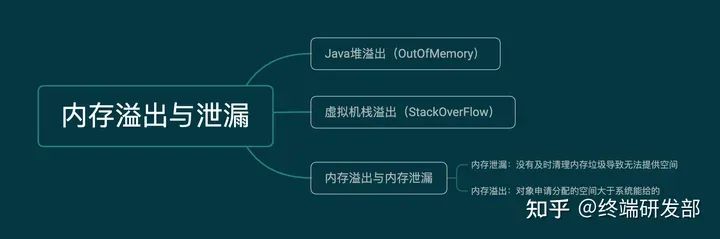
内存泄漏的定义
内存泄漏是一种常见的内存管理问题,它会导致内存逐渐耗尽并最终导致应用程序崩溃。内存泄漏通常发生在以下情况下:
没有正确释放对象的内存空间。在 Java 中,垃圾回收机制可以自动回收不再使用的对象,但是如果某个对象的引用没有被清除,那么它就会一直存在于内存中,占用内存空间。
缓存数据过多或者缓存数据不被清理。在开发过程中,我们经常需要使用缓存来提高应用程序的性能,但是如果缓存的数据过多或者不被清理,那么就会占用大量的内存空间。
对象生命周期过长
当对象的生命周期比应用程序所需的时间长时,它就会在内存中持续存在,从而导致内存溢出。这种情况通常发生在以下情况下:
某些对象的生命周期长于应用程序的生命周期。例如,在 Web 应用程序中,Servlet 和 Filter 的生命周期通常比请求的生命周期长,如果这些对象没有正确地销毁,它们就会一直存在于内存中,占用内存空间。
对象被错误地缓存或者保留。在某些情况下,我们可能需要保留某些对象以供以后使用,但是如果保留对象的方式不正确,它们就会占用内存空间,从而导致内存溢出。
堆内存设置不当
Java 应用程序在运行时会将对象存储在堆内存中,如果堆内存设置得不当,就会导致内存溢出。以下是堆内存设置不当的情况:
堆内存设置过小。如果堆内存设置过小,就会导致内存不足,从而导致内存溢出。
堆内存设置过大。如果堆内存设置过大,就会导致应用程序的性能下降,并且在垃圾回收时会耗费更多的时间。
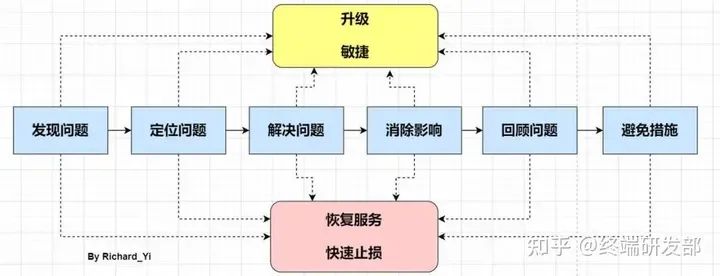
在大多数情况下,我们都是先优先恢复服务,保留下当时的异常信息(内存dump、线程dump、gc log等等,在紧急情况下甚至可以不用保留,等到事后去复现),等到服务正常,再去复盘问题。
二、如何定位和分析内存溢出问题
使用 Java 虚拟机的工具
Java 虚拟机提供了一些工具来帮助我们定位和分析内存溢出问题。以下是几个常用的工具:
jmap:用于生成 Java 堆转储文件,可以帮助我们查看 Java 堆中的对象信息。
jstat:用于监视 Java 虚拟机的各种统计信息,例如垃圾回收次数、堆内存使用情况等。
jconsole:一个图形化界面的工具,可以监视 Java 虚拟机的各种运行时信息,例如 CPU 使用率、堆内存使用情况等。
jvisualvm:一个基于图形化界面的工具,可以帮助我们分析 Java 应用程序的性能问题,例如内存泄漏和性能瓶颈。
使用内存分析工具
内存分析工具可以帮助我们更深入地分析内存溢出问题,并找到导致内存溢出的原因。以下是几个常用的内存分析工具:
Eclipse Memory Analyzer:一款开源的 Java 内存分析工具,可以帮助我们快速定位内存泄漏问题。
VisualVM Memory Analyzer:一个基于图形化界面的工具,可以帮助我们分析 Java 应用程序的内存使用情况。
JProfiler:一款商业的 Java 内存分析工具,可以帮助我们分析 Java 应用程序的性能问题和内存泄漏问题。
使用日志和调试信息
在代码中添加日志和调试信息可以帮助我们更好地了解应用程序的运行情况,并帮助我们定位和分析内存溢出问题。以下是几个常用的日志和调试工具:
Log4j:一个开源的日志框架,可以帮助我们生成详细的日志信息。
SLF4J:另一个开源的日志框架,可以帮助我们生成详细的日志信息。
Debug:Java 开发工具中的一个调试工具,可以帮助我们定位代码中的错误。
三、案例分析
假设我们有一个 Java 应用程序,它会读取大量的数据并进行计算。我们发现这个应用程序在运行一段时间后会导致内存溢出,我们需要找到导致内存溢出的原因。
首先,我们可以使用 jmap 工具生成 Java 堆转储文件,然后使用 jvisualvm 工具来分析 Java 堆转储文件。通过分析 Java 堆转储文件,我们可以发现应用程序中有大量的对象没有被垃圾回收,这很可能是由于内存泄漏导致的。
然后,我们可以使用 Eclipse Memory Analyzer 工具来进一步分析内存泄漏问题。Eclipse Memory Analyzer 可以帮助我们分析 Java 堆转储文件中的对象信息,并找到哪些对象正在被引用,以及哪些对象没有被垃圾回收。
通过分析内存泄漏的对象信息,我们发现有一个对象没有被垃圾回收,它持有大量的数据,而这些数据实际上是重复的,没有必要占用这么多的内存。我们可以通过优化这个对象来解决内存泄漏的问题。
此外,我们还可以通过日志和调试信息来分析问题。我们可以在代码中添加日志信息,记录应用程序运行时的状态和变量值,以便我们更好地了解应用程序的运行情况。同时,我们还可以使用调试工具来定位代码中的错误,例如空指针异常等。
CPU分析
当程序响应变慢的时候,首先使用top、vmstat、ps等命令查看系统的cpu使用率是否有异常,从而可以判断出是否是cpu繁忙造成的性能问题。其中,主要通过us(用户进程所占的%)这个数据来看异常的进程信息。当us接近100%甚至更高时,可以确定是cpu繁忙造成的响应缓慢。一般说来,cpu繁忙的原因有以下几个:
线程中有无限空循环、无阻塞、正则匹配或者单纯的计算
发生了频繁的gc
多线程的上下文切换
确定好cpu使用率最高的进程之后就可以使用jstack来打印出异常进程的堆栈信息:
jstack [pid]
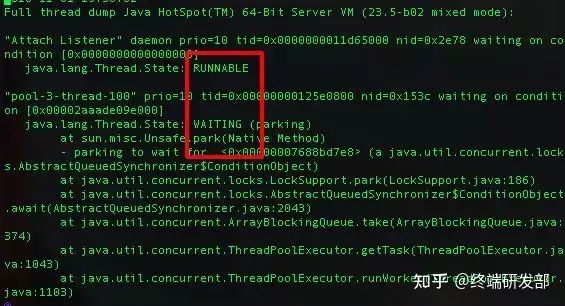
接下来需要注意的一点是,Linux下所有线程最终还是以轻量级进程的形式存在系统中的,而使用jstack只能打印出进程的信息,这些信息里面包含了此进程下面所有线程(轻量级进程-LWP)的堆栈信息。因此,进一步的需要确定是哪一个线程耗费了大量cpu,此时可以使用top -p [processId]来查看,也可以直接通过ps -Le来显示所有进程,包括LWP的资源耗费信息。最后,通过在jstack的输出文件中查找对应的lwp的id即可以定位到相应的堆栈信息。其中需要注意的是线程的状态:RUNNABLE、WAITING等。对于Runnable的进程需要注意是否有耗费cpu的计算。对于Waiting的线程一般是锁的等待操作。
也可以使用jstat来查看对应进程的gc信息,以判断是否是gc造成了cpu繁忙。
jstat -gcutil [pid]
还可以通过vmstat,通过观察内核状态的上下文切换(cs)次数,来判断是否是上下文切换造成的cpu繁忙。
vmstat 1 5

此外,有时候可能会由jit引起一些cpu飚高的情形,如大量方法编译等。这里可以使用-XX:+PrintCompilation这个参数输出jit编译情况,以排查jit编译引起的cpu问题。
top
在Linux内核的操作系统中,进程是根据虚拟运行时间(由进程优先级、nice值加上实际占用的CPU时间进行动态计算得出)进行动态调度的。在执行进程时,需要从用户态转换到内核态,用户空间不能直接操作内核空间的函数。通常要利用系统调用来完成进程调度,而用户空间到内核空间的转换通常是通过软中断来完成的。例如要进行磁盘操作,用户态需要通过系统调用内核的磁盘操作指令,所以CPU消耗的时间被切分成用户态CPU消耗、系统(内核) CPU 消耗,以及磁盘操作 CPU 消耗。执行进程时,需要经过一系列的操作,进程首先在用户态执行,在执行过程中会进行进程优先级的调整(nice),通过系统调用到内核,再通过内核调用,硬中断、软中断,让硬件执行任务。执行完成之后,再从内核态返回给系统调用,最后系统调用将结果返回给用户态的进程。
top可以查看CPU总体消耗,包括分项消耗,如User,System,Idle,nice等。Shift + H显示java线程;Shift + M按照内存使用排序;Shift + P按照CPU使用时间(使用率)排序;Shift + T按照CPU累积使用时间排序;多核CPU,进入top视图1,可以看到各各CPU的负载情况。
top - 15:24:11 up 8 days, 7:52, 1 user, load average: 5.73, 6.85, 7.33
Tasks: 17 total, 1 running, 16 sleeping, 0 stopped, 0 zombie
%Cpu(s): 13.9 us, 9.2 sy, 0.0 ni, 76.1 id, 0.1 wa, 0.0 hi, 0.1 si, 0.7 st
KiB Mem : 11962365+total, 50086832 free, 38312808 used, 31224016 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 75402760 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
300 ymmapp 20 0 17.242g 1.234g 14732 S 2.3 1.1 9:40.38 java
1 root 20 0 15376 1988 1392 S 0.0 0.0 0:00.06 sh
11 root 20 0 120660 11416 1132 S 0.0 0.0 0:04.94 python
54 root 20 0 85328 2240 1652 S 0.0 0.0 0:00.00 su
55 ymmapp 20 0 17432 1808 1232 S 0.0 0.0 0:00.00 bash
56 ymmapp 20 0 17556 2156 1460 S 0.0 0.0 0:00.03 control.sh
57 ymmapp 20 0 11880 740 576 S 0.0 0.0 0:00.00 tee
115 ymmapp 20 0 17556 2112 1464 S 0.0 0.0 0:00.02 control_new_war
133 root 20 0 106032 4240 3160 S 0.0 0.0 0:00.03 sshd
134 ymmapp 20 0 17080 6872 3180 S 0.0 0.0 0:01.82 ops-updater
147 ymmapp 20 0 17956 2636 1544 S 0.0 0.0 0:00.07 control.sh
6538 ymmapp 20 0 115656 10532 3408 S 0.0 0.0 0:00.46 beidou-agent
6785 ymmapp 20 0 2572996 22512 2788 S 0.0 0.0 0:03.44 gatherinfo4dock
29241 root 20 0 142148 5712 4340 S 0.0 0.0 0:00.04 sshd
29243 1014154 20 0 142148 2296 924 S 0.0 0.0 0:00.00 sshd
29244 1014154 20 0 15208 2020 1640 S 0.0 0.0 0:00.00 bash
32641 1014154 20 0 57364 2020 1480 R 0.0 0.0 0:00.00 top第一行:15:24:11 up 8 days, 7:52, 1 user, load average: 5.73, 6.85, 7.33:15:24:11 系统时间,up 8 days 运行时间,1 user 当前登录用户数,load average 负载均衡情况,分别表示1分钟,5分钟,15分钟负载情况。
第二行:Tasks: 17 total, 1 running, 16 sleeping, 0 stopped, 0 zombie:总进程数17,运行数1,休眠 16,停止0,僵尸进程0。
第三行:%Cpu(s): 13.9 us, 9.2 sy, 0.0 ni, 76.1 id, 0.1 wa, 0.0 hi, 0.1 si, 0.7 st:用户空间CPU占比13.9%,内核空间CPU占比9.2%,改变过优先级的进程CPU占比0%,空闲CPU占比76.1,IO等待占用CPU占比0.1%,硬中断占用CPU占比0%,软中断占用CPU占比0.1%,当前VM中的cpu 时钟被虚拟化偷走的比例0.7%。
第四和第五行表示内存和swap区域的使用情况。
第七行表示:
PID: 进程idUSER:进程所有者PR:进程优先级NI:nice值。负值表示高优先级,正值表示低优先级VIRT:虚拟内存,进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RESRES:常驻内存,进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATASHR:共享内存,共享内存大小,单位kbS:进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程%CPU:上次更新到现在的CPU时间占用百分比%MEM:进程使用的物理内存百分比TIME+:进程使用的CPU时间总计,单位1/100秒COMMAND:进程名称(命令名/命令行)
总结
定位和分析内存溢出问题需要我们掌握一些基本的工具和技能。我们可以使用 Java 虚拟机提供的工具来监视 Java 应用程序的运行情况,例如 jmap、jstat、jconsole 和 jvisualvm。同时,我们还可以使用内存分析工具来深入分析内存泄漏问题,例如 Eclipse Memory Analyzer、VisualVM Memory Analyzer 和 JProfiler。此外,我们还可以在代码中添加日志和调试信息,以便更好地了解应用程序的运行情况。
在解决内存溢出问题时,我们需要多方面思考,从不同的角度分析问题。通过使用各种工具和技能,我们可以快速定位和解决内存溢出问题,提高应用程序的稳定性和可靠性。
最后给大家的一个建议就是:
大家学习一定要找对圈子
我是于小二一个北漂者,原创不易,如果你觉得我说的很中肯, 最后也别忘记点赞收藏哦。关注我,每天分享更多的职场经验和面试技巧~
-END-
如果看到这里,说明你喜欢这篇文章,请 转发、点赞。同时 标星(置顶)本公众号可以第一时间接受到博文推送。

回复 【idea激活】即可获得idea的激活方式
回复 【Java】获取java相关的视频教程和资料
回复 【SpringCloud】获取SpringCloud相关多的学习资料
回复 【python】获取全套0基础Python知识手册
回复 【2020】获取2020java相关面试题教程
回复 【加群】即可加入终端研发部相关的技术交流群
阅读更多
用 Spring 的 BeanUtils 前,建议你先了解这几个坑!
在华为鸿蒙 OS 上尝鲜,我的第一个“hello world”,起飞!
一款vue编写的功能强大的swagger-ui,有点秀(附开源地址)
相信自己,没有做不到的,只有想不到的
在这里获得的不仅仅是技术!


喜欢就给个“在看”














 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









