






点击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识
什么概念?在AMD的MI300X上跑FP8满血R1,性能全面超越了英伟达H200——
相同延迟下吞吐量最高可达H200的5倍,相同并发下则比H200高出75%。

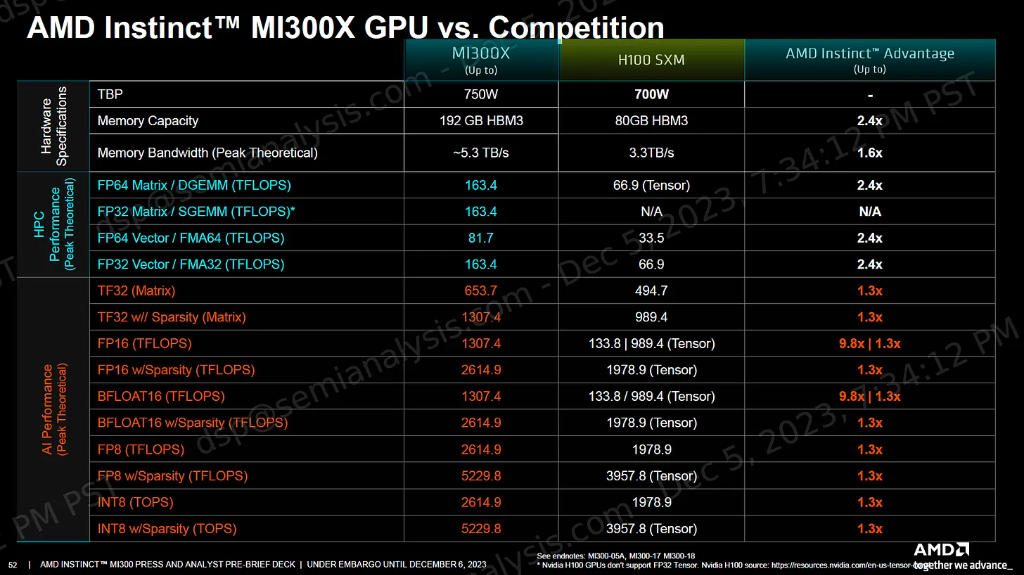
据介绍,新的AMD芯片拥有超过1,500亿个晶体管,其内存是英伟达H100的2.4倍。 具有1.6倍的内存带宽,进一步提高了性能。
MI300系列中有两款新型AI数据中心芯片:一款专注于生成式AI应用,另一款则面向超级计算机。用于生成人工智能的处理器版本MI300X包含可提高性能的先进高带宽内存。
这款被戏称为"液氮级内卷王"的GPU,不仅把并发吞吐量飙到H200的五倍,还顺手给延迟做了个光子嫩肤——128个请求排队等AI翻牌子的时间不超过50毫秒,比H200快了40%
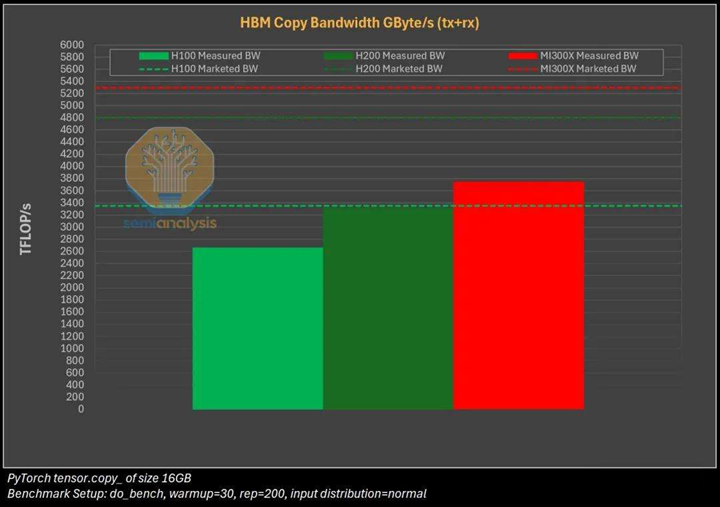
SemiAnalysis 通过GEMM (通用矩阵乘法) 性能、HBM内存带宽性能、单节点训练性能、多节点训练性能以及网络性能等多种测试,来比较两家厂商的 GPU 产品的表现。
当H200还在用"绿皮火车"的速度处理Token时,MI300X已经开着曲率引擎玩起了星际穿越。其Token间延迟压到50毫秒内,相当于让AI推理过程进入了子弹时间。更离谱的是8v8服务器对决中,面对Bloom 176B这样的模型怪兽,MI300X的性能优势居然拉到60%,活像重量级拳手跑赢了百米飞人。
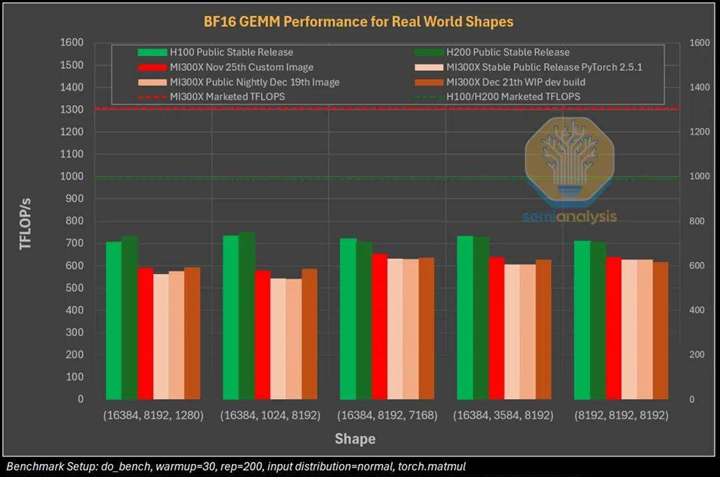
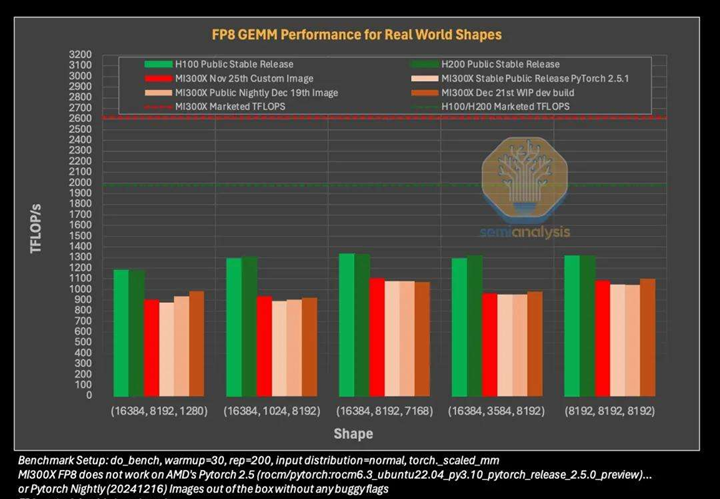
GEMM 性能是衡量硬件训练大型 Transformer 模型(如 ChatGPT、Llama)性能的重要指标。
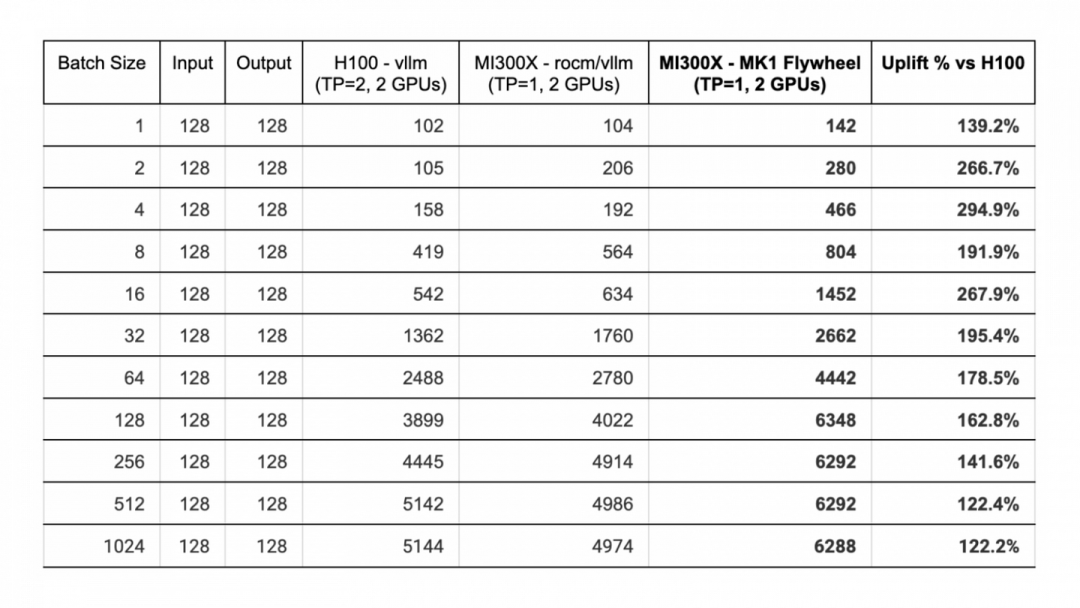
Tensorwave在其博文中详细介绍了测试过程。他们使用了Mixtral 8x7B模型,在AMD和NVIDIA的硬件上进行了在线和离线测试。测试环境包括8个MI300X加速器和8个NVIDIA H100 SXM5加速器。测试结果显示,无论是在离线性能还是在模拟真实聊天应用的在线性能上,MI300X均显著优于H100。

业内人士也对AMD在AI领域的发展前景持乐观态度,Transformer作者及Cohere公司创始人之一艾丹·戈麦斯表示,他相信AMD和Tranium等平台将很快进入主流市场。

就基础规格而言,MI300X的浮点运算速度比H100高30%,内存带宽比H100高60%,内存容量更是H100的两倍以上。
当然,MI300X对标的更多是英伟达最新的GPU H200,虽然规格上同样领先,但MI300X对H200的优势就没那么大了,内存带宽仅比后者多出个位数,容量比后者大近40%。
如今看来,AMD这波操作宛如给AI芯片界放了把"三昧真火":用开源框架破CUDA护城河,拿硬件堆料轰碎算力天花板,再祭出价格屠刀收割市场。
唯一受伤的可能是英伟达的PR团队——得连夜给H200写悼词了。不过对于开发者来说,这场"算力诸神黄昏"倒是喜闻乐见:毕竟当AMD都能用SGLang把吞吐量玩出花,谁还甘心当CUDA的"数字佃农"呢?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











