









要获取豆瓣读书书籍列表的数据,需要进行翻页、详细页内容的爬取。
豆瓣读书要爬取的链接是:豆瓣-新书速递
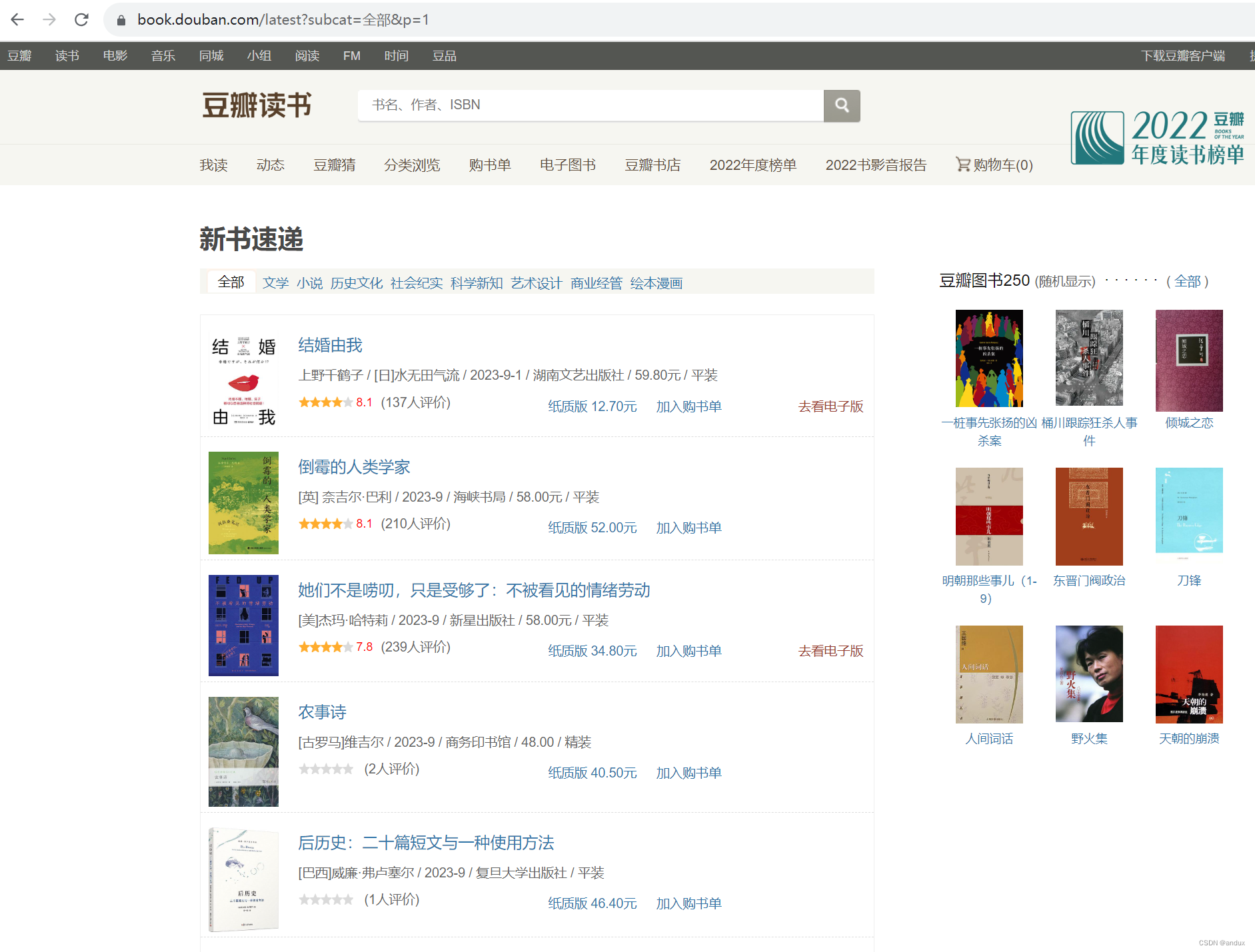
从链接:
https://book.douban.com/latest?subcat=%E5%85%A8%E9%83%A8&p=1可以看出,p=1就是翻页的参数,如果不使用scrapy框架,那就让p+1来进行翻页,使用下一页的href是否为空来判断是不是最后一页。
从书名的链接上获取书籍的详细信息,从详细信息页面获取书名、作者、出版社等数据,并存储到MongoDB数据库中。
app.py:
import scrapy
from ..items import Scrapy01Item
class AppSpider(scrapy.Spider):
name = "app"
allowed_domains = ["book.douban.com"]
start_urls = ["https://book.douban.com/latest"]
def parse(self, response):
books = response.xpath('//ul[@class="chart-dashed-list"]/li')
# print(len(books)) # 20条数据
for book in books:
link = book.xpath('.//h2/a/@href').get()
yield scrapy.Request(url=link, callback=self.parse_details)
next_url = response.xpath('//span[@class="next"]/a/@href').get()
if next_url is not None:
next_url = response.urljoin(next_url)
yield scrapy.Request(url=next_url, callback=self.parse)
def parse_details(self, response):
item = Scrapy01Item()
title = response.xpath('//*[@id="wrapper"]/h1/span/text()').get()
author = response.xpath('//*[@id="info"]/span[1]/span/text()').get()
publisher = response.xpath('//*[@id="info"]/a/text()').get()
item["title"] = title
item["author"] = author
item["publisher"] = publisher
yield item
pipelines.py:
from itemadapter import ItemAdapter
import pymongo
class Scrapy01Pipeline:
def __init__(self):
self.res = None
print("-" * 10, "开始", "-" * 10)
self.client = pymongo.MongoClient("mongodb://localhost:27017")
self.db = self.client["douban"]
self.collection = self.db["books"]
def process_item(self, item, spider):
self.res = self.collection.insert_one(dict(item))
print("self.res.inserted_id:", self.res.inserted_id)
return item
def __del__(self):
print("-" * 10, "结束", "-" * 10)
middlewares.py里的def process_request(self, request, spider): 函数里,不要进行user-agent的随机获取,不然容易掉,在settings.py里面把USER_AGENT设置好就可以,很稳定。
还有豆瓣有防爬机制,同一个ip访问过大,就需要登录才能打开页面,所以需要使用代理,来改变ip地址。
items.py:
import scrapy
class Scrapy01Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
publisher = scrapy.Field()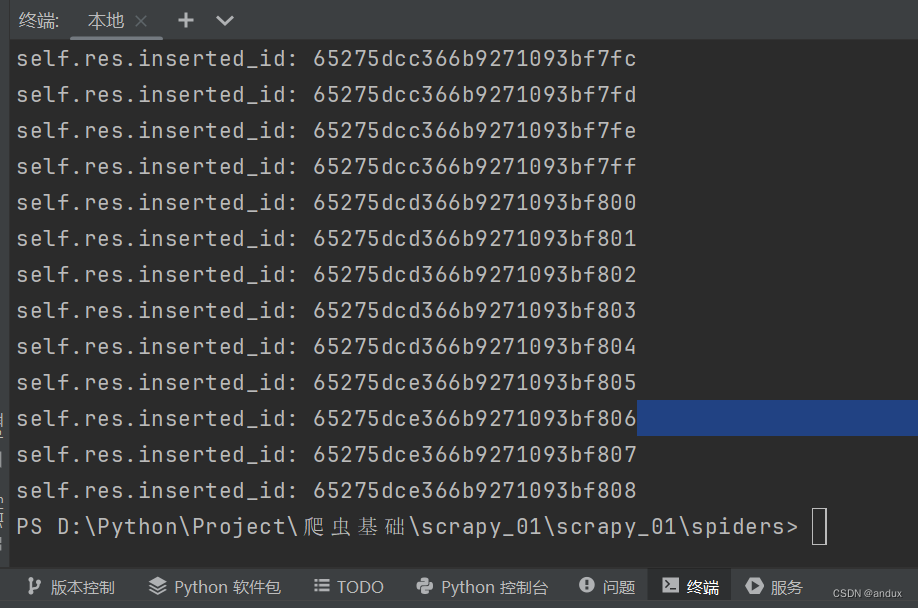
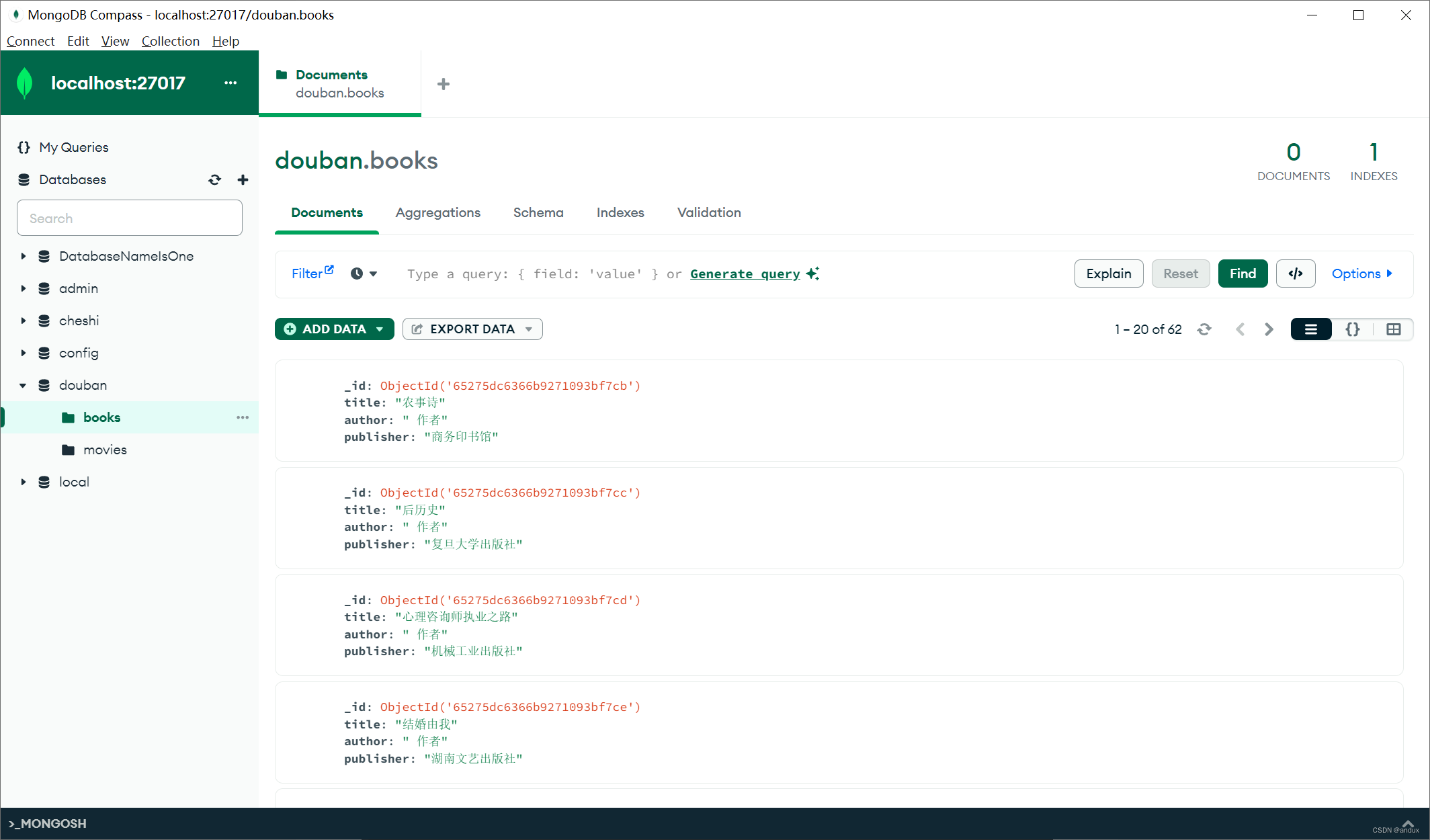
使用scrapy框架进行爬虫爬取页面内容,在settings里面可以把USER_AGENT设置好,在items里面把数据库实体类设置好,在middlewares里面把代理设置好,在pipelines里面把MongoDB数据库的写入操作写好,在app里把逻辑写好,就可以了,这样把功能分开写在对应的文件里,方便对代码进行管理。scrapy内置有比较好用的函数,比如拼接链接的response.urljoin(next_url)方法。不能递归函数,需要使用回调,
yield scrapy.Request(url=next_url, callback=self.parse)
这样进行处理,
yield item
对数据库实体也需要这样进行操作返回给框架。


















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











