









redis可以用于分布式爬取,就是可以同时使用多个进程(多个终端)运行同一个应用,redis可以自己调度每个进程的任务列表,共同完成相关任务。
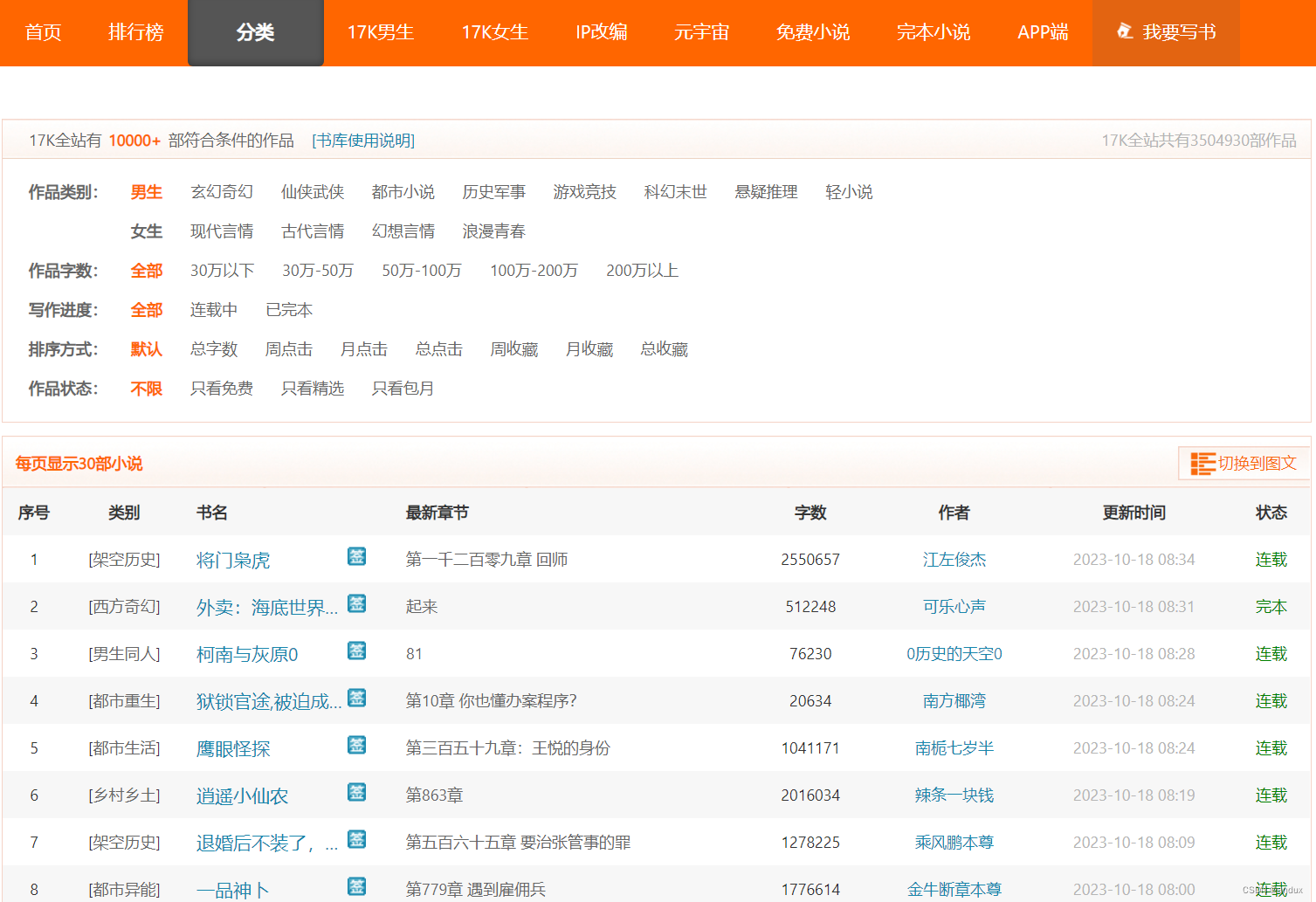
选取每页30条数据,爬取两页:
app.py
from typing import Iterable
import scrapy
from scrapy import Request
from ..items import Scrapy04Item
from scrapy_redis.spiders import RedisSpider
class AppSpider(RedisSpider):
name = "app"
# allowed_domains = ["www.17k.com"]
start_urls = ["https://www.17k.com/all/book/2_0_0_0_0_0_0_0_1.html"]
redis_key = "app"
def __init__(self, *args, **kwargs):
domain = kwargs.pop("domin", "")
self.allowed_domains = filter(None, domain.split(","))
super(AppSpider, self).__init__(*args, **kwargs)
def start_requests(self) -> Iterable[Request]:
max_page = 3
for i in range(1, max_page):
url = "https://www.17k.com/all/book/2_0_0_0_0_0_0_0_" + str(i) + ".html"
yield Request(url)
def parse(self, response):
links = response.xpath('//table//tr/td[4]/a/@href').extract()
for link in links:
link = "http:" + link
yield scrapy.Request(url=link, callback=self.parse_chapter, dont_filter=True)
def parse_chapter(self, response):
item = Scrapy04Item()
chapter = response.xpath('//*[@id="readArea"]/div[1]/h1/text()').get()
content = response.xpath('//*[@id="readArea"]/div[1]/div[2]/p[1]/text()').get()
book = response.xpath('/html/body/div[4]/div[1]/a[4]/text()').get()
if chapter is None:
chapter = response.xpath('/html/body/div[3]/div/h1/text()').get()
content = response.xpath('/html/body/div[3]/div/div[3]/p[1]/text()').get()
book = response.xpath('/html/body/div[3]/div/div[1]/div[2]/a[4]/text()').get()
item["book"] = book
item["chapter"] = chapter
item["content"] = content
yield item
因为17k小说网有的章节需要登录才能查看,xpath不一样,所以需要判断一下chapter的内容是否为None。
items.py
import scrapy
class Scrapy04Item(scrapy.Item):
book = scrapy.Field()
chapter = scrapy.Field()
content = scrapy.Field()
数据库实体类中的字段顺序,决定了最后存储到MongoDB数据库中的字段顺序。
pipelines.py
import json
import redis
import pymongo
class Scrapy04Pipeline:
def __init__(self):
print("-" * 10, "开始", "-" * 10)
self.db_redis = redis.Redis(host="127.0.0.1", port="6379", decode_responses=True)
self.client = pymongo.MongoClient("mongodb://localhost:27017")
self.db = self.client["17k"]
self.collection = self.db["newchapter"]
self.collection.delete_many({}) # 情况MongoDB
self.db_redis.flushdb() # 清空redis
def process_item(self, item, spider):
self.collection.insert_one(dict(item))
# for i in self.db_redis.lrange("app:items", 0, -1):
# print(json.loads(i)["title"])
# item["title"] = json.loads(i)["title"]
# print('-' * 10, index)
# print(item["title"])
def __del__(self):
print("-" * 10, "结束", "-" * 10)
这里需要注意,需要清空redis数据库,不然有数据它就不执行了,因为它认为已经执行过了。MongoDB数据库清空是为了看清楚数据变化。
settings.py
# Scrapy settings for scrapy_04 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "scrapy_04"
SPIDER_MODULES = ["scrapy_04.spiders"]
NEWSPIDER_MODULE = "scrapy_04.spiders"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = "ERROR"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
REDIS_URL = "redis://127.0.0.1:6379"
# DOWNLOAD_DELAY = 1
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
# DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
# }
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# "scrapy_04.middlewares.Scrapy04SpiderMiddleware": 543,
# }
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# "scrapy_04.middlewares.Scrapy04DownloaderMiddleware": 543,
# }
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
# }
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"scrapy_04.pipelines.Scrapy04Pipeline": 300,
"scrapy_redis.pipelines.RedisPipeline": 400,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = "httpcache"
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
settings.py文件里配置redis数据库连接,DOWNLOAD_DELAY = 1是间隔一秒再执行,网站没有反扒的时候,可以注释掉。
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
REDIS_URL = "redis://127.0.0.1:6379"
# DOWNLOAD_DELAY = 1可以对比一下在pipelines.py中的redis数据库连接方式:
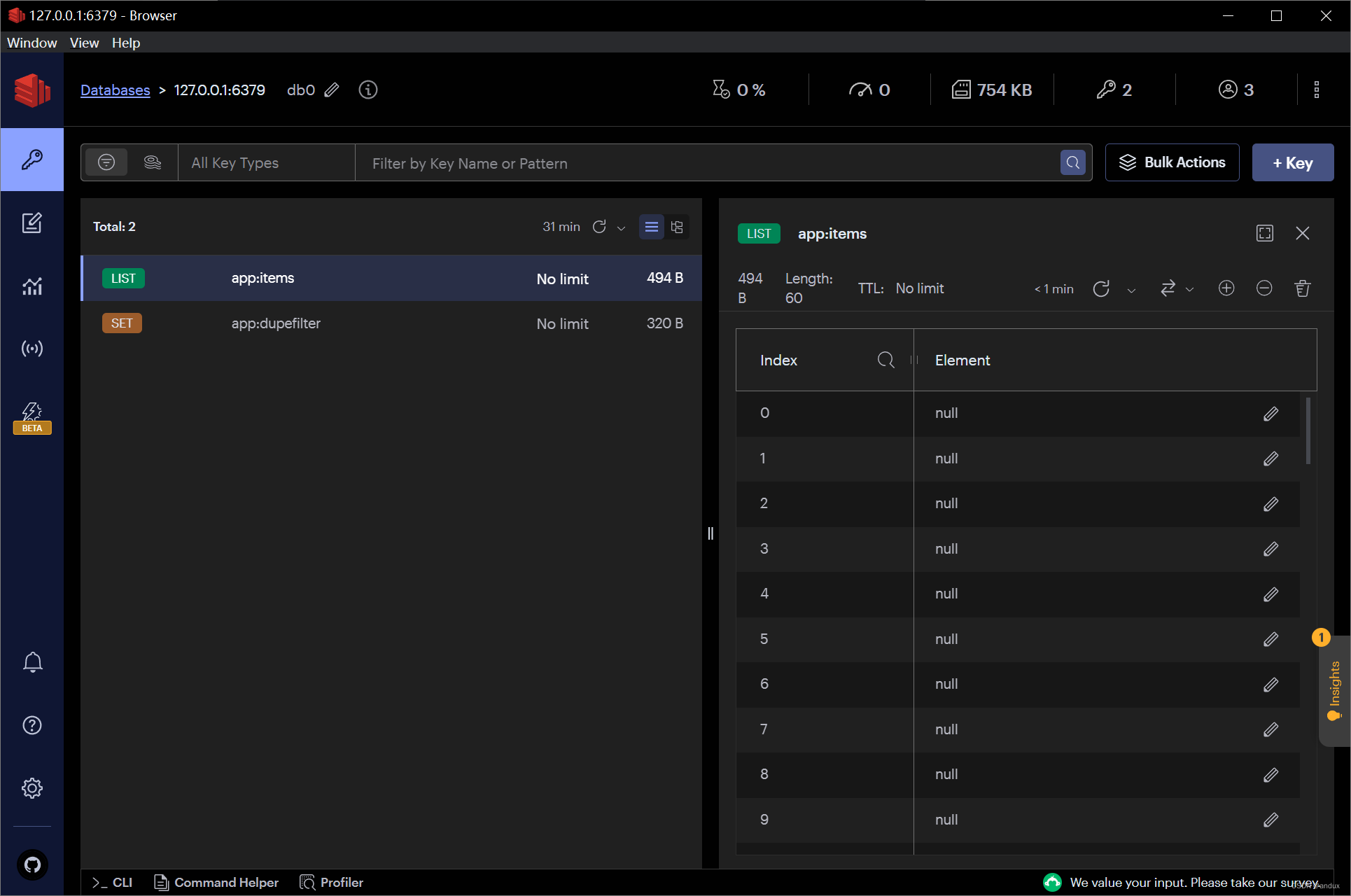
self.db_redis = redis.Redis(host="127.0.0.1", port="6379", decode_responses=True)redis数据库:
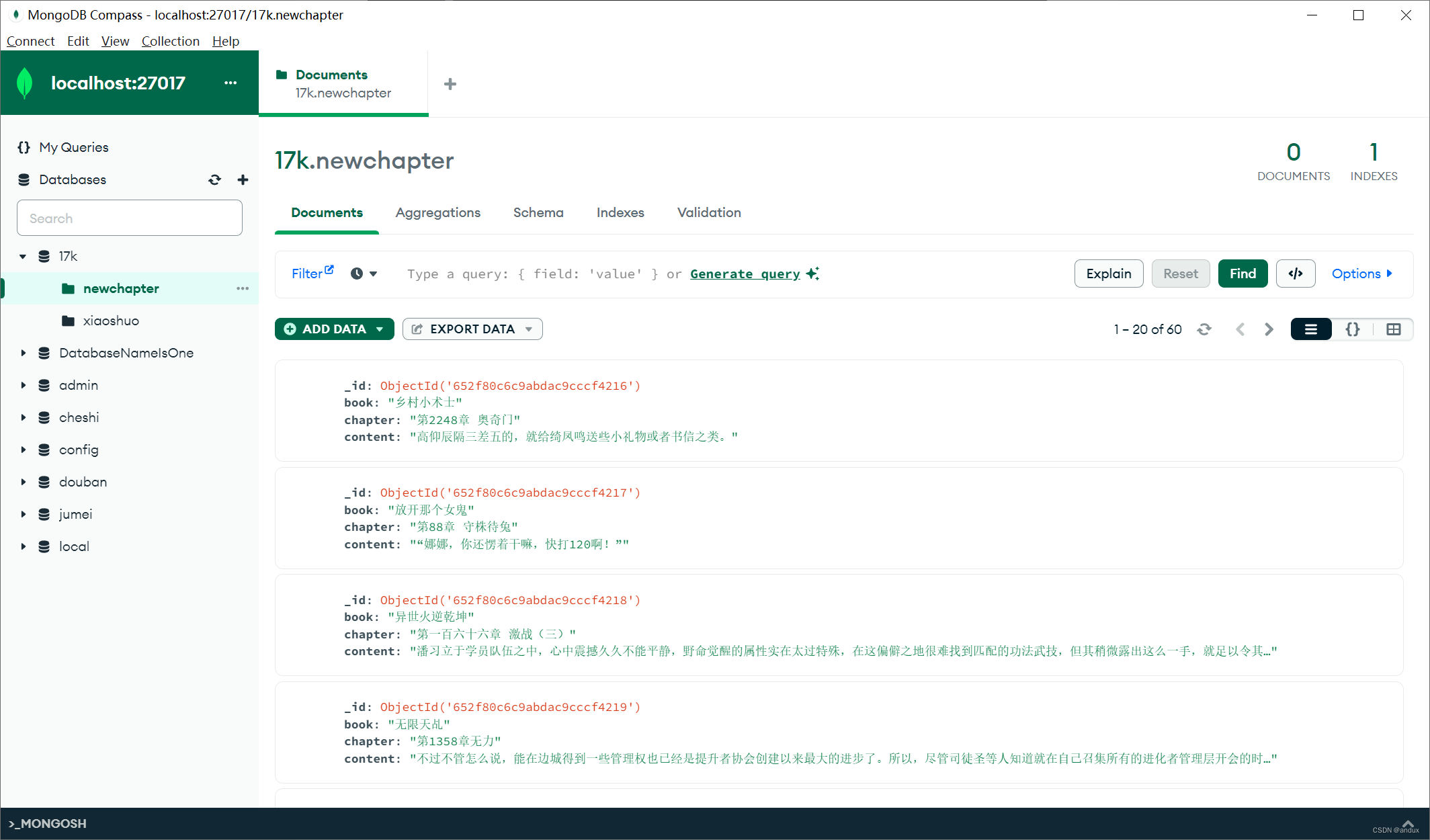
MongoDB数据库:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











