







飞卢小说网的青春校园排行榜链接是:青春校园小说排行榜_飞卢小说网
使用selenium集成化爬虫工具,它的xpath跟scrapy等有一定区别,scrapy等需要使用get()或者extract()等函数来获取dom节点,而selenium就不需要了。
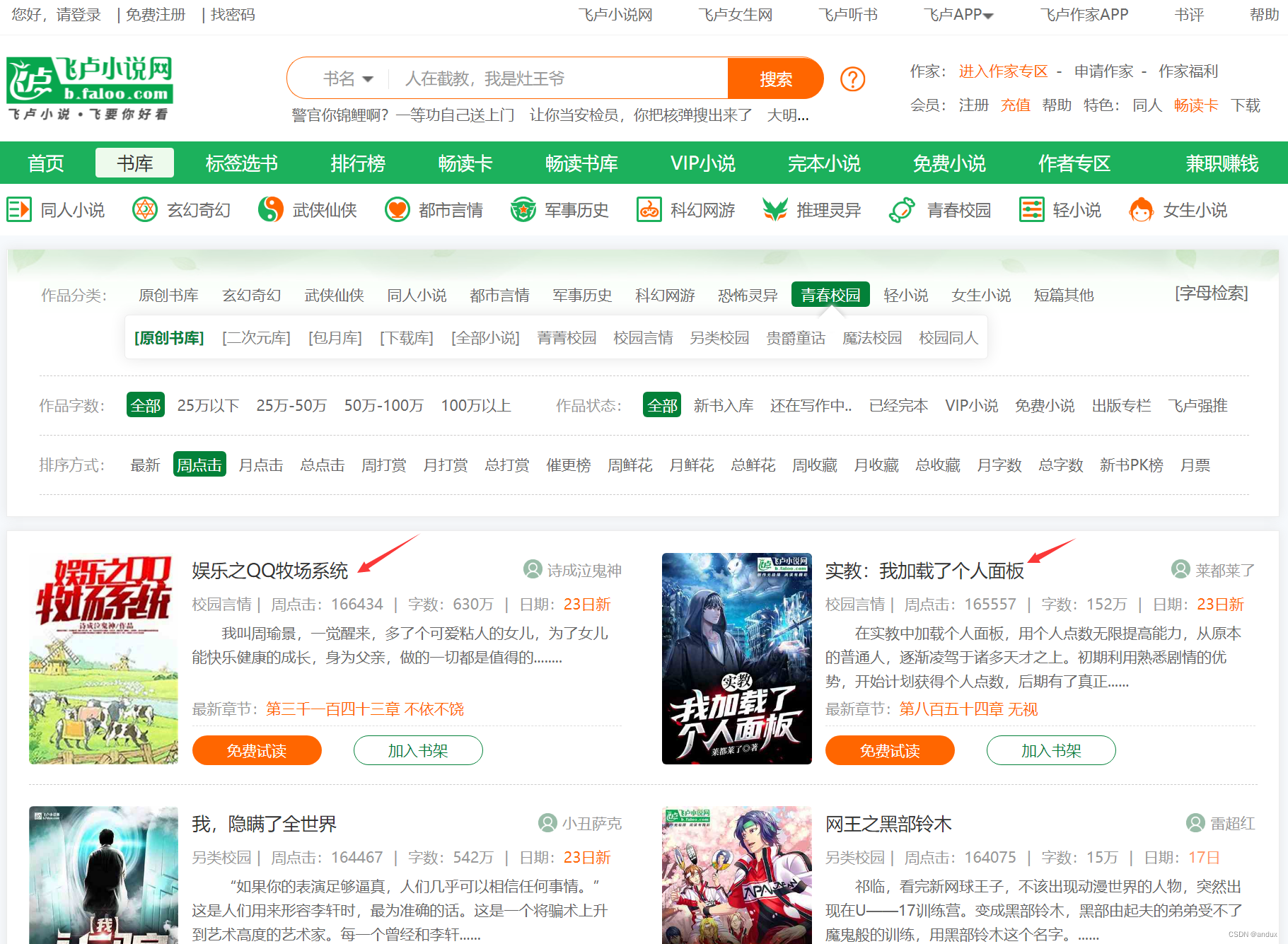
飞卢小说网的排行榜中,每个小说块的class都是一样的,这样获取整页的div块的xpath就很好写了。
app.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
service = Service(executable_path="./driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)
url = "https://b.faloo.com/y_7_0_0_0_0_1_1.html"
driver.get(url=url)
try:
boxs = driver.find_elements(By.XPATH, '//div[@class="TwoBox02_02"]')
for box in boxs:
h1 = box.find_element(By.XPATH, './/h1[@class="fontSize17andHei"]')
title = h1.get_attribute("title")
print(title)
except Exception as e:
print(e)
time.sleep(2)
driver.quit()
把爬取代码放到try里面,是为了出错时程序不会中断,继续执行下去。
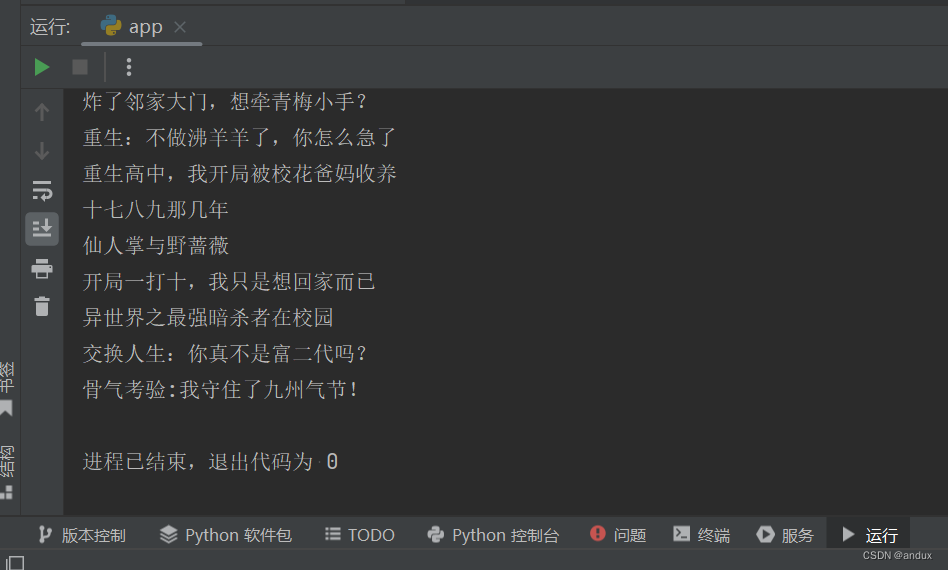
需要注意获取飞卢小说网小说标题的xpath是:
h1 = box.find_element(By.XPATH, './/h1[@class="fontSize17andHei"]')而不是:
h1 = box.find_element(By.XPATH, '//h1[@class="fontSize17andHei"]')一个点(.)是指当前子目录中,没有点的话,就是直接从根目录开始了。
1. Example syntax using a single attribute (relative XPath type): // a [@href=’http://www.google.com’] //input[@id=’name’] //input[@name=’username’] //img[@alt=’sometext’] 2. Example syntax using multiple attributes (relative XPath type): //tagname[@attribute1=’value1’] [attribute2=’value2’] //a[@id=’id1’] [@name=’namevalue1’] //img[@src=’’] [@href=’’] 3. Example syntax of a search using “contains” (here, to create an account): //tagname[contains(@attribute,’value1’)] //input[contains(@id,’’)] //input[contains(@name,’’)] //a[contains(@href,’’)] //img[contains(@src,’’)] //div[contains(@id,’’)] 4. Example syntax of a search using “starts-with:”: //tagname[starts-with(@attribute-name,’’)] //id[starts-with(@id,’’)] //a[starts-with(@href=’’)] //img[starts-with(@src=’’)] //div[starts-with(@id=’’)] //input[starts-with(@id=’’)] //button[starts-with(@id,’’)] 5. Example syntax for using the following node: Xpath/following::again-ur-regular-path //input[@id=’’]/following::input[1] //a[@href=’’]/following::a[1] //img[@src=’’]/following::img[1] 6. Example syntax for using the preceding node: Xpath/preceding::again-ur-regular-path //input[@id=’’]/ preceding::input[1] //a[@href=’’]/ preceding::a[1] //img[@src=’’]/ preceding::img[1] 7. Example syntax for using the absolute XPath type: 1-/html/head/body/div/input 8. Example syntax for text search in XPath: Syntax- tagname[text()=’text which is visible on page’] 9. Example syntax for text search with ‘contains’: /*[contains(text(),’Employee Distribution by Subunit’)]



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











