







尽量使用列名来查询:
(在Oracle9I之前的版本,在其之后,Oracle对* 进行了优化,让的 功能跟列名一样。)在Oracle9I以前的版本,当读取到的时候,首先要在对应的表里面查 询有哪些列,然后再做查找,不管表包含列的多少,都需要时间
where语句中,使用逻辑运算符过滤的时候:
是从右往左解析的, 所以在面对and过滤的 时候,尽量把可能出错的放在右边。or过滤的时候,尽量把正确的放在右边,提高效率。
在能够使用where和having过滤数据的时候,尽量使用where
因为where语句在分组之前,比如说我们要处理一个含有一亿条数据的表,我们要得到的 数据只有20条,但是我们先分组,然后再过滤,这样效率会慢一点
如果我们使用过滤,在分组之前就把没关系的数据过滤掉,然后再分组,效率比较高
group by语句的增强:
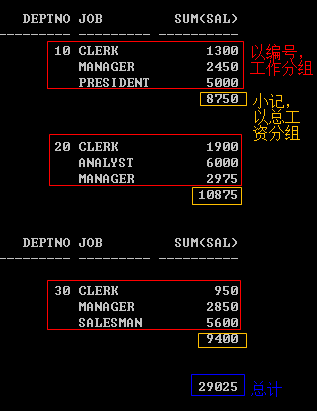
由上面的需求我们可以看到。首先通过deptno,job分组 group by deptno,job
然后再通过deptno分组 group by deptno
最后不分组 group by null
这三句相当于:group by rollip(deptno,job)
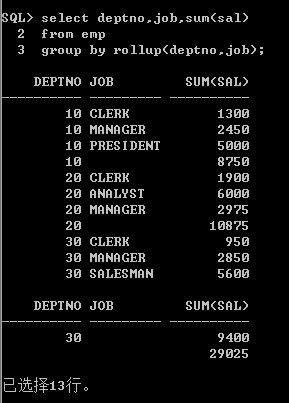
但是,这样分组得到的报表不是很美观,所以我们用到了
Break on deptno skip 2
在命令行输入如上语句的时候,break on deptno的意思就是相同的deptno只出现一次,并且不同的deptno分组之间,隔两行
如果我们想取消这个语句的作用,可以输入 break on null
层次查询:
当我们进行自连接查询数据的时候,比如说查询XXX的老板是XXX,我们要这样:
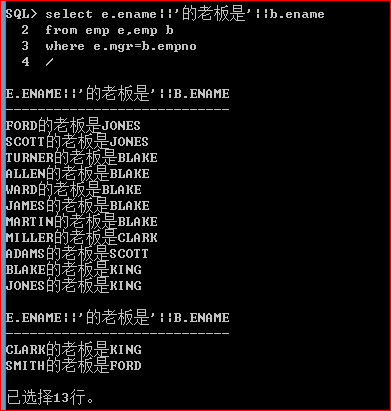
但是,这里是自连接,涉及到2张表或以上,肯定会产生笛卡儿积,如果是自连接的话,它的笛卡儿积是呈平方或者n次方增长。
这样,我们可以使用层次查询来查询,
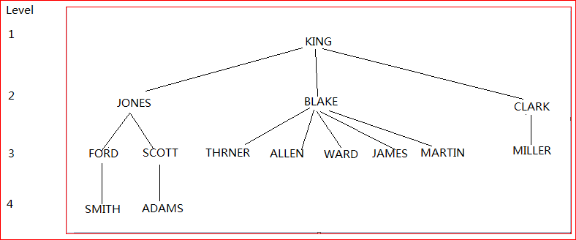
使用层次查询的时候,系统为我们增加了一个伪列:level,是指这颗树的深度
那么我们遍历这颗树的时候,就可这样来查询:
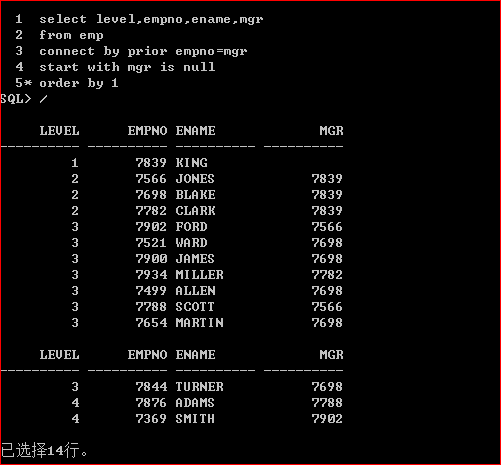
在层次查询中,数据库对表指操作一次,并且解决了笛卡儿积的问题。
Prior是指前一位的员工号等于下一个要查询的老板号,以king为例
Select * from emp where mgr=7839
然后得到员工的信息,然后再一直查下去。
Start with mgr is null 这条指令是为了得到第一个遍历的元素,如果知道king的员工编号也可以直接写start with empno=7839
在可以使用子查询和多表查询的情况下,理论上应使用多表查询
因为子查询进行2次查询,但是多表查询进行一次查询
尽量不要使用集合运算:
因为要执行多次。同时也可以使用set timming on 来查看集合运算与其他语句所执行的时间















 3691
3691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









