







举个栗子:对于一张图片的处理
数据输入
假设我有一个图像数据,大小是64 * 64个像素一个像素就是一个颜色点,一个颜色点由红绿蓝三个值来表示,例如,红绿蓝为255,255,255,那么这个颜色点就是白色)。
首先计算机存储图像有三个独立矩阵分别存储R G B。
为了更加方便后面的处理,我们一般把上面那3个矩阵转化成1个向量x(向量可以理解成1 * n或n * 1的数组,前者为行向量,后者为列向量,)。那么这个向量x的总维数就是64 * 64 * 3,结果是12288。在人工智能领域中,每一个输入到神经网络的数据都被叫做一个特征,那么上面的这张图像中就有12288个特征。这个12288维的向量也被叫做特征向量。神经网络接收这个特征向量x作为输入,并进行预测,然后给出相应的结果。
对于不同的应用,需要识别的对象不同,有些是语音有些是图像有些是传感器数据,但是它们在计算机中都有对应的数字表示形式,通常我们会把它们转化成一个特征向量,然后将其输入到神经网络中。
预测
现在我们已经知道了如何将数据输入到神经网络中。那么神经网络是如何根据这些数据进行预测的呢?我们将一张图片输入到神经网络中,神经网络是如何预测这张图中是否有猫的呢??
这个预测的过程其实只是基于一个简单的公式:z = dot(w,x) + b。
上面公式中的x代表着输入特征向量,假设只有3个特征,那么x就可以用(x1,x2,x3)来表示。如下图所示。w表示权重,它对应于每个输入特征,代表了每个特征的重要程度。b表示阈值[yù zhí],用来影响预测结果。z就是预测结果。公式中的dot()函数表示将w和x进行向量相乘。

上面的公式展开后就变成了z = (x1 * w1 + x2 * w2 + x3 * w3) + b。
那么神经网络到底是如何利用这个公式来进行预测的呢?再举个栗子
假设周末即将到来,你听说在你的城市将会有一个音乐节。我们要预测你是否会决定去参加。音乐节离地铁挺远,而且你想宅在家里打游戏,但是天气预报说音乐节那天天气特别好。也就是说有3个因素会影响你的决定,这3个因素就可以看作是3个输入特征。那你到底会不会去呢?你的个人喜好——你对上面3个因素的重视程度——会影响你的决定。这3个重视程度就是3个权重。
如果你觉得地铁远近无所谓,并且已经不太想打游戏了,而且你很喜欢蓝天白云,那么我们将预测你会去音乐节。这个预测过程可以用我们的公式来表示。我们假设结果z大于0的话就表示会去,小于0表示不去。又设阈值b是-5。又设3个特征(x1,x2,x3)为(0,0,1),最后一个是1,它代表了好天气。又设三个权重(w1,w2,w3)是(2,2,7),最后一个是7表示你很喜欢好天气。那么就有z = (x1 * w1 + x2 * w2 + x3 * w3) + b = (0 * 2 + 0 * 2 + 1 * 7) + (-5) = 2。预测结果z是2,2大于0,所以预测你会去音乐节。
如果你最近非常想打游戏,并且对其它两个因素并不在意,那么我们预测你将不会去音乐节。这同样可以用我们的公式来表示。设三个权重(w1,w2,w3)是(2,7,2),w2是7表示你有上王者的欲望。那么就有z = (x1 * w1 + x2 * w2 + x3 * w3) + b = (0 * 2 + 0 * 7 + 1 * 2) + (-5) = -3。预测结果z是-3,-3小于0,所以预测你不会去,会呆在家里上王者。
预测图片里有没有猫也是通过上面的公式。经过训练的神经网络会得到一组与猫相关的权重。当我们把一张图片输入到神经网络中,图片数据会与这组权重以及阈值进行运算,结果大于0就是有猫,小于0就是没有猫。
上面那个用于预测的公式我们称之为逻辑回归。
最后再稍微提一下激活函数。在实际的神经网络中,我们不能直接用逻辑回归。必须要在逻辑回归外面再套上一个函数。这个函数我们就称它为激活函数。激活函数非常非常重要,如果没有它,那么神经网络的智商永远高不起来。
为什么需要激活函数?如果没有激活函数,神经网络的层次再多都没用,因为都相当于一层;如果没有激活函数,神经网络只能解决简单的线性问题;加入了激活函数,只要层次足够多,那么神经网络就可以解决一切问题。神经网络没有它就等于没有被激活,所以说激活函数是神经网络必须的!
Y= WX + b是一个线性函数
线性函数套用在多层,也还是一个线性函数
这里简单介绍一种叫做sigmoid的激活函数。它的公式和图像如下。
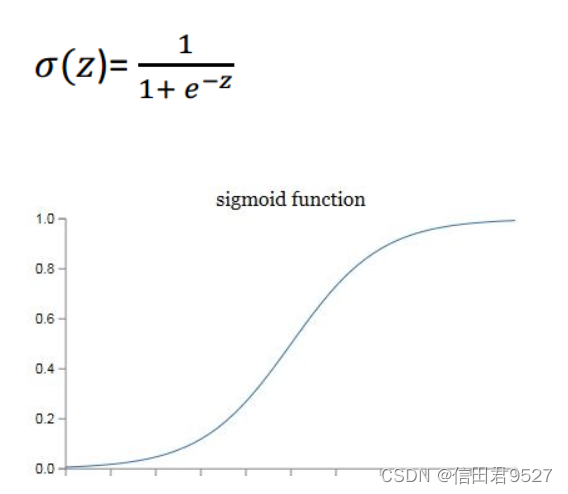
激活函数的一个用途——把z映射到[0,1]之间。上图中的横坐标是z,纵坐标我们用y’来表示,y’就代表了我们最终的预测结果。从图像可以看出,z越大那么y’就越靠近1,z越小那么y’就越靠近0。那为什么要把预测结果映射到[0,1]之间呢?因为这样不仅便于神经网络进行计算,也便于我们人类进行理解。例如在预测是否有猫的例子中,如果y’是0.8,就说明有80%的概率是有猫的。
常见的激活函数还有tanh, relu(隐藏层使用的很多),softmax
结果验证
要验证学习成果,就是要判断预测结果是否准确,这就要靠损失函数了。
我们通常定义一个目标函数,并希望优化它到最低点。 因为越低越好,所以这些函数有时被称为损失函数(loss function,或cost function)。
努力使损失函数的值越小就是努力让预测的结果越准确。损失函数的作用就是衡量模型预测的好坏。通常损失函数是根据模型参数定义的,并取决于数据集。 在一个数据集上,我们通过最小化总损失来学习模型参数的最佳值。 该数据集由一些为训练而收集的样本组成,称为训练数据集(training dataset,或称为训练集(training set))。 然而,在训练数据上表现良好的模型,并不一定在“新数据集”上有同样的效能,这里的“新数据集”通常称为测试数据集(test dataset,或称为测试集(test set))。
算法优化
一旦我们获得了一些数据源及其表示、一个模型和一个合适的损失函数,我们接下来就需要一种算法,它能够搜索出最佳参数,以最小化损失函数。 大多流行的优化算法通常基于一种基本方法–梯度下降(gradient descent)。 简而言之,在每个步骤中,梯度下降法都会检查每个参数,看看如果你仅对该参数进行少量变动,训练集损失会朝哪个方向移动。 然后,它在可以减少损失的方向上优化参数。梯度下降会一步步的改变w和b的值,从而让损失函数的输出结果更小。
所以说机器学习的学习或者说训练神经网络,就是找到一组w和b,让损失函数最小,也就是预测结果更准确。














 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









