







我们的毕设辅导团队由一群经验丰富、专业素质过硬的导师组成。他们来自于各个领域的专业人士,具备丰富的实践经验和深厚的学术背景。无论你的毕设是关于Python、Java、小程序、asp.net、PHP、nodejs还是其他领域,我们都能为你提供专业的指导和支持。
一、项目介绍:
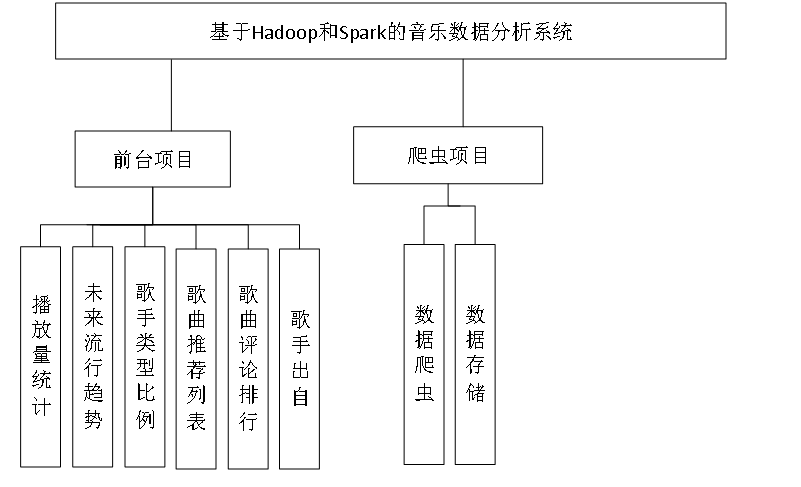
《[含文档+PPT+源码等]精品springboot基于Hadoop和Spark实现的音乐数据分析系统》该项目含有源码、文档、PPT、配套开发软件、软件安装教程、包运行成功以及课程答疑与微信售后交流群、送查重系统不限次数免费查重等福利!
数据库管理工具:phpstudy/Navicat或者phpstudy/sqlyog
后台管理系统涉及技术:
后台使用框架:Springboot
前端使用技术:Vue,HTML5,CSS3、JavaScript等
数据库:Mysql数据库
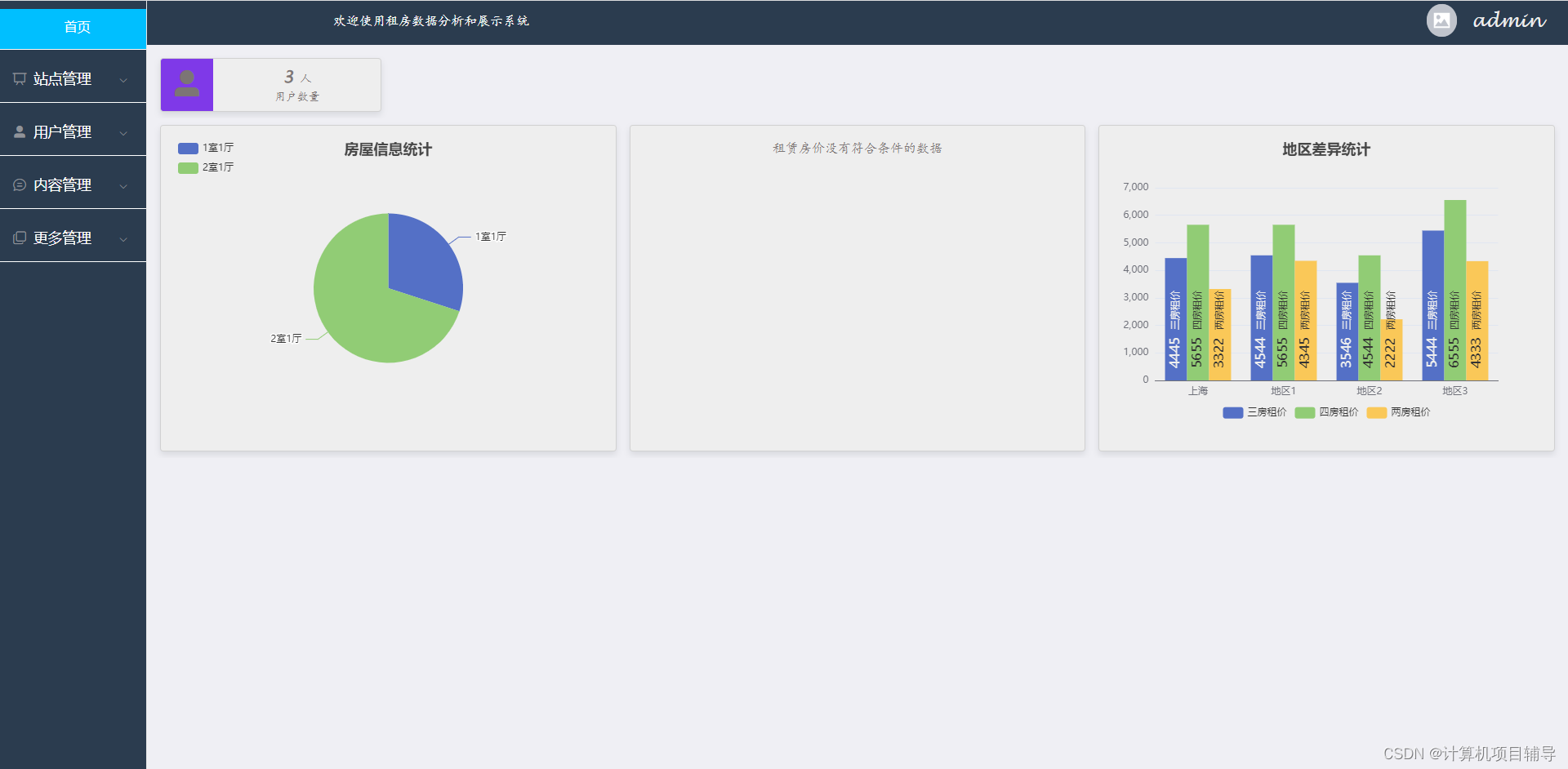
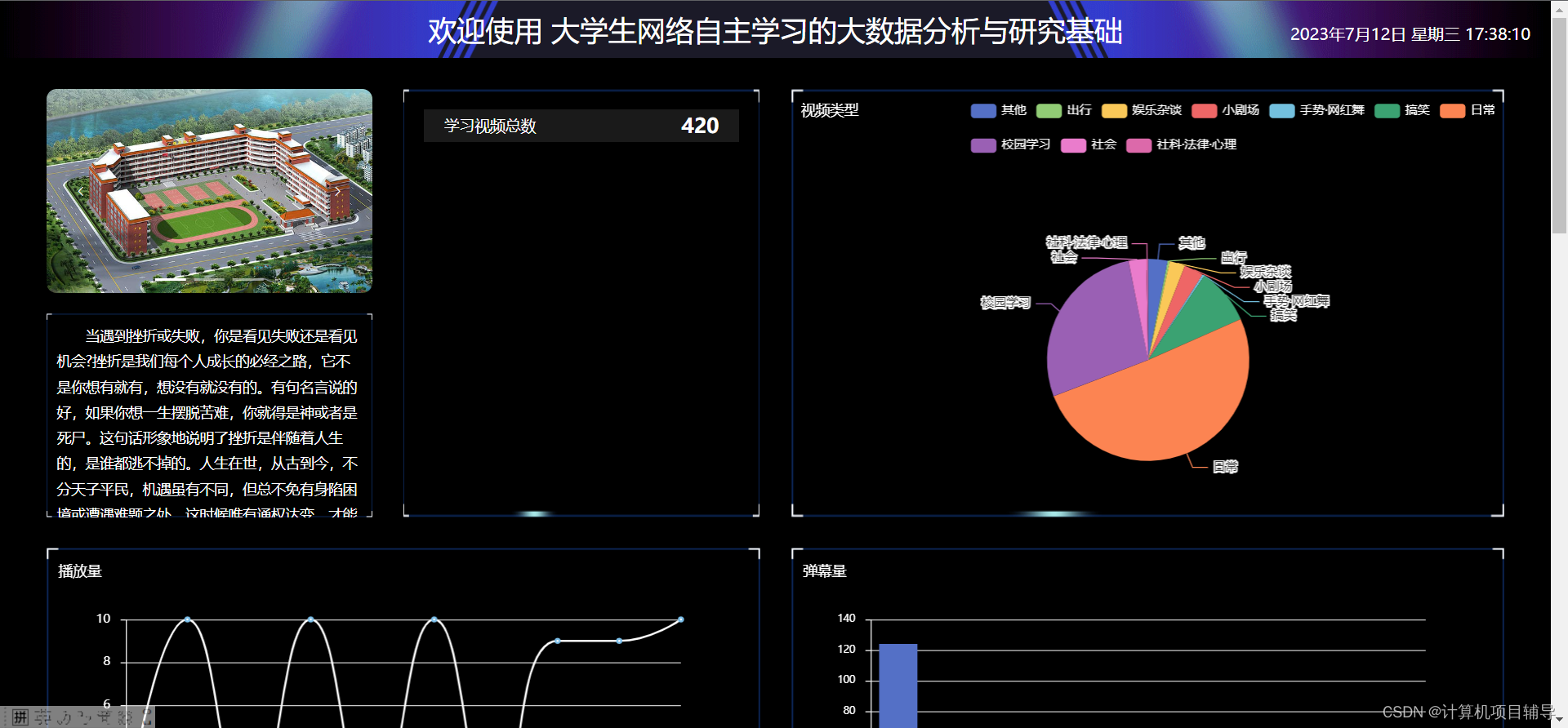
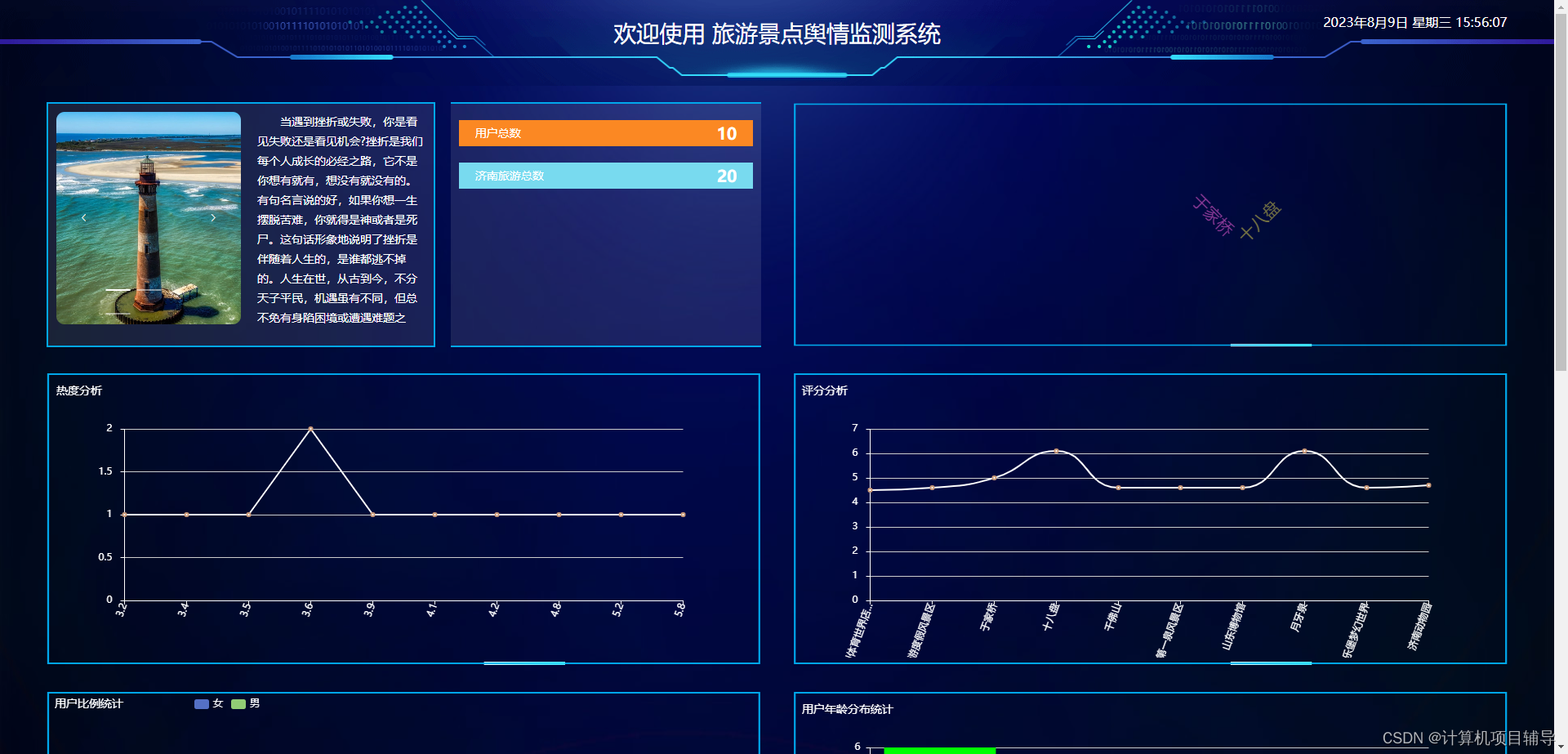
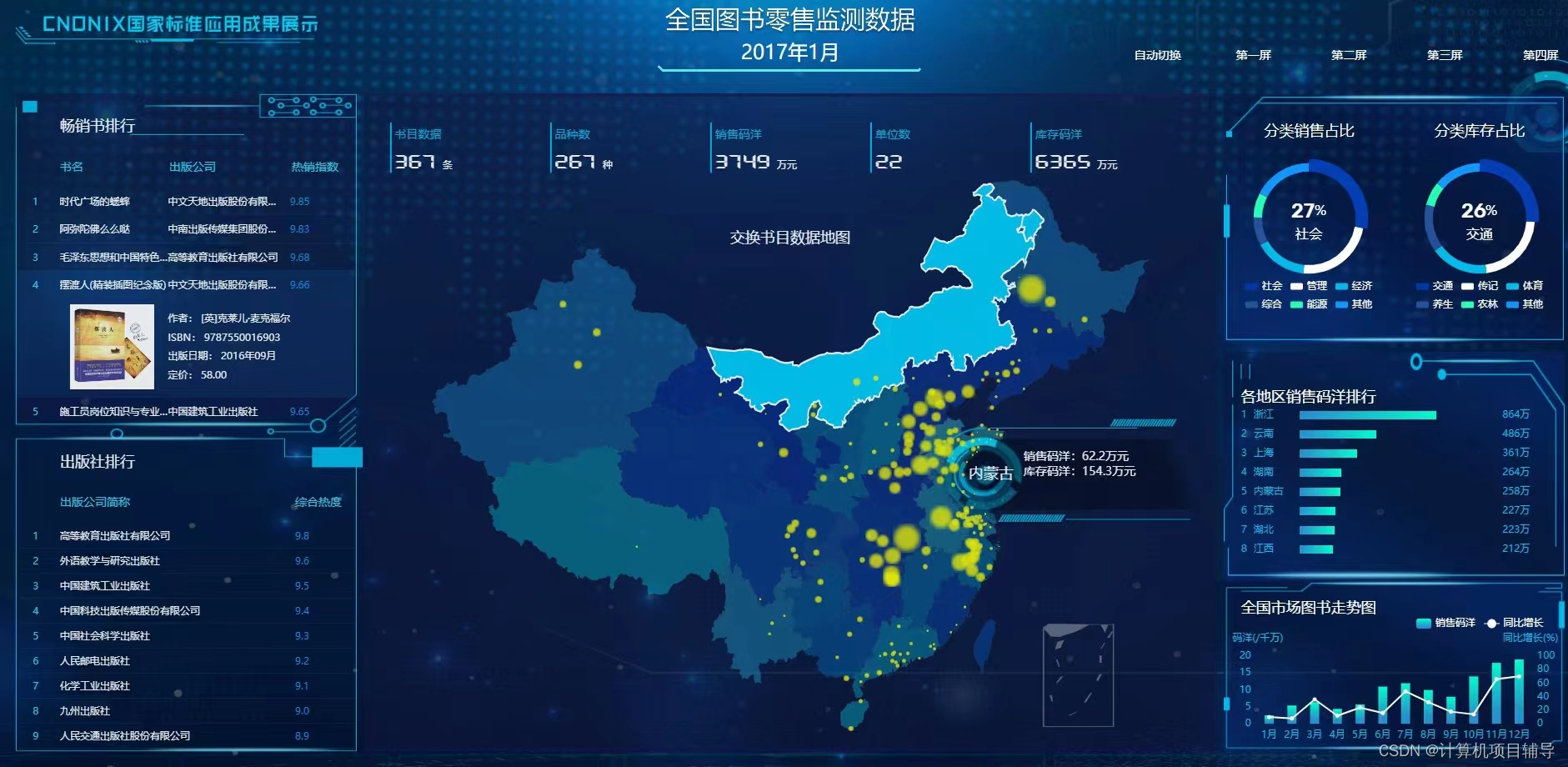
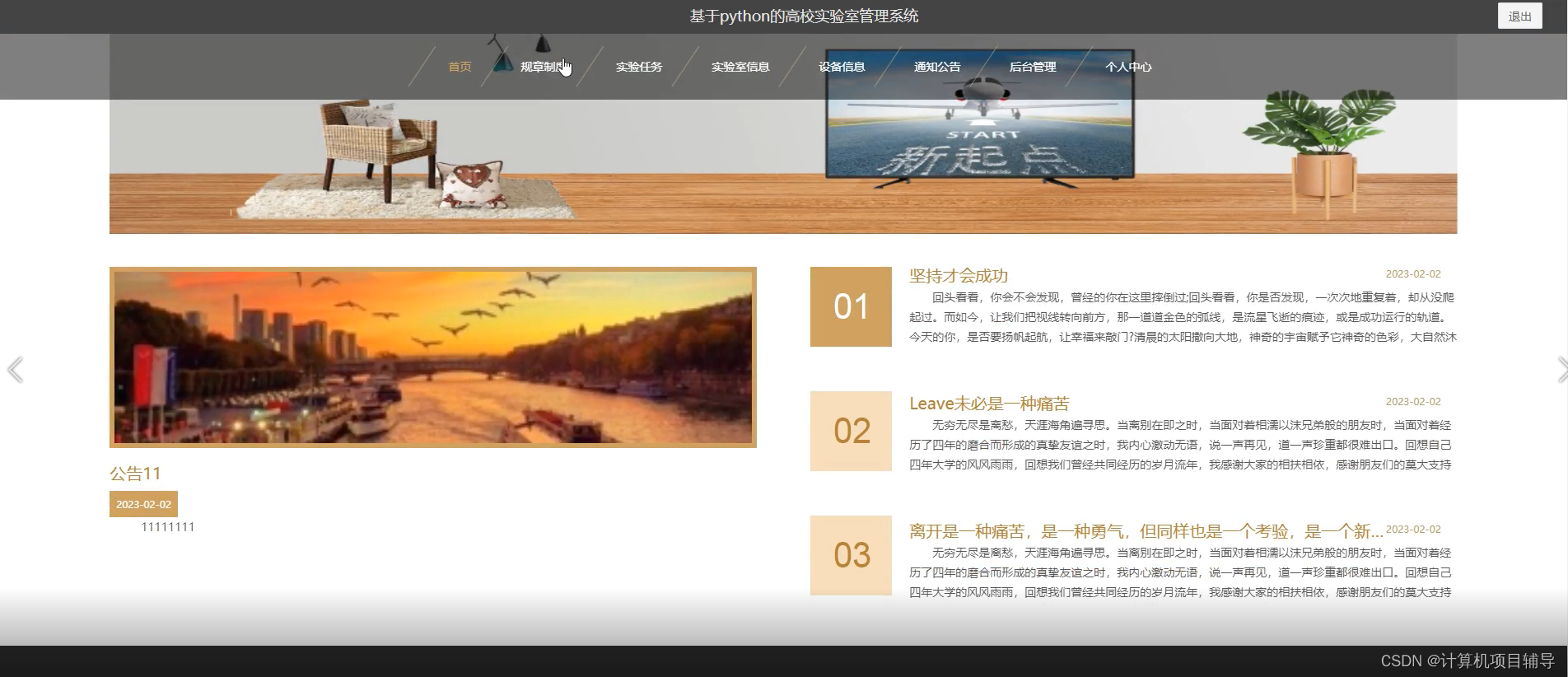
下面是系统运行起来后的一些截图:
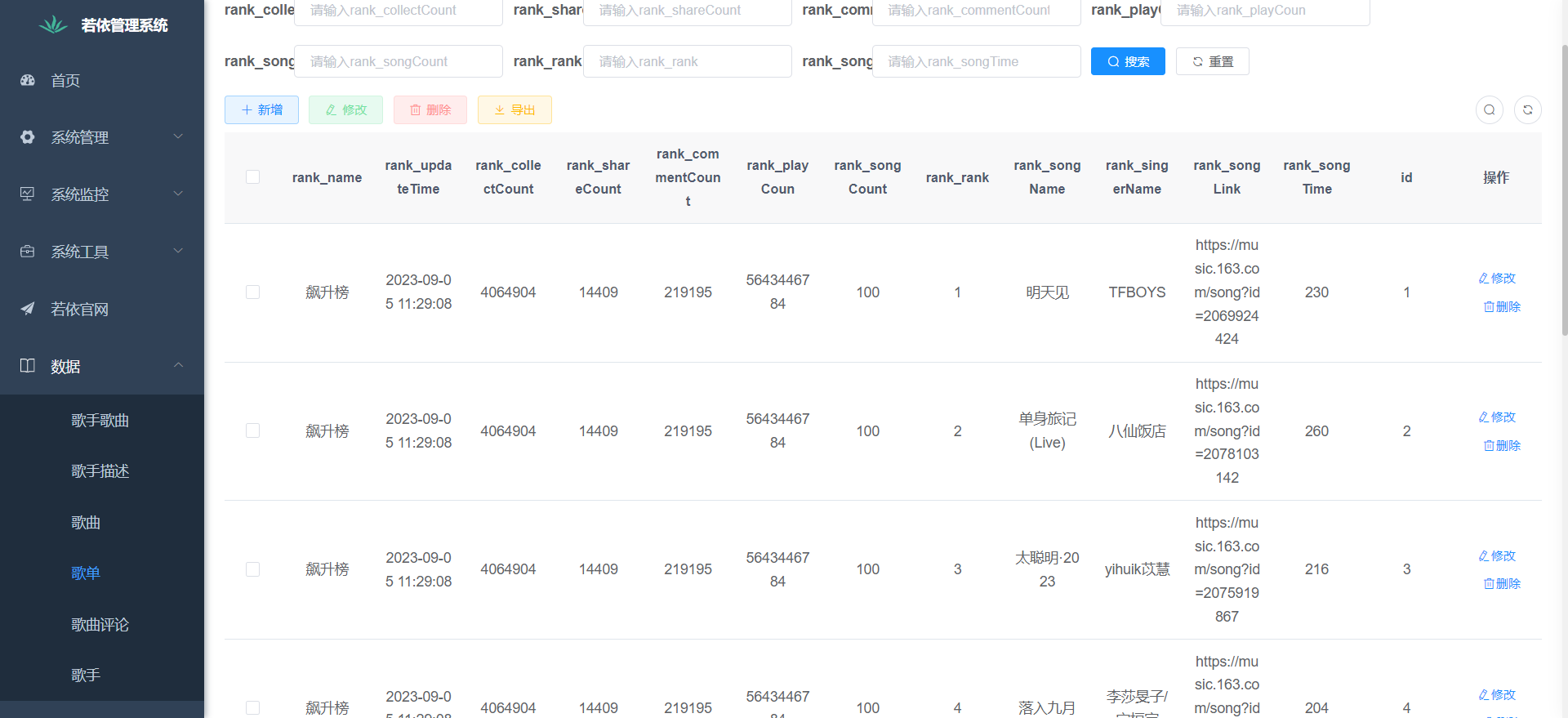

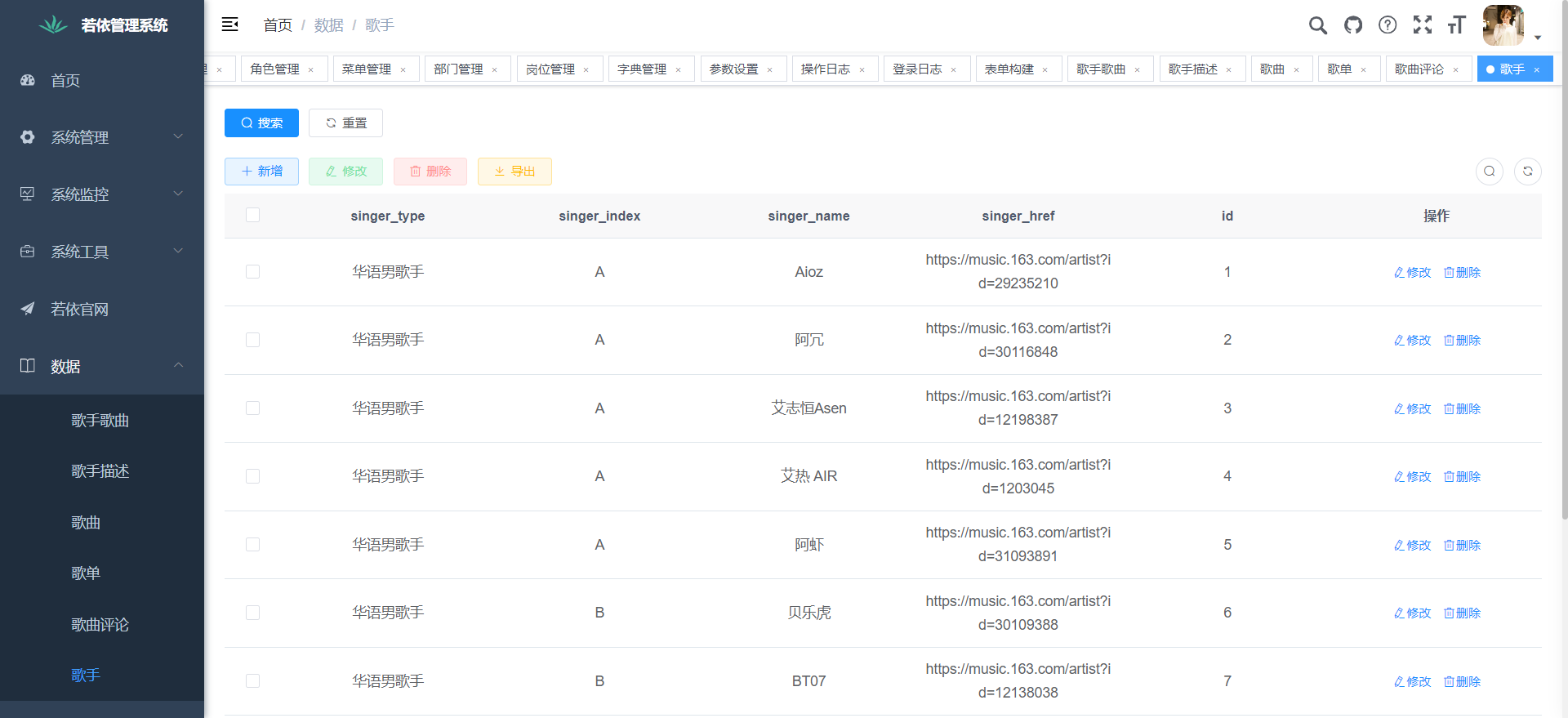
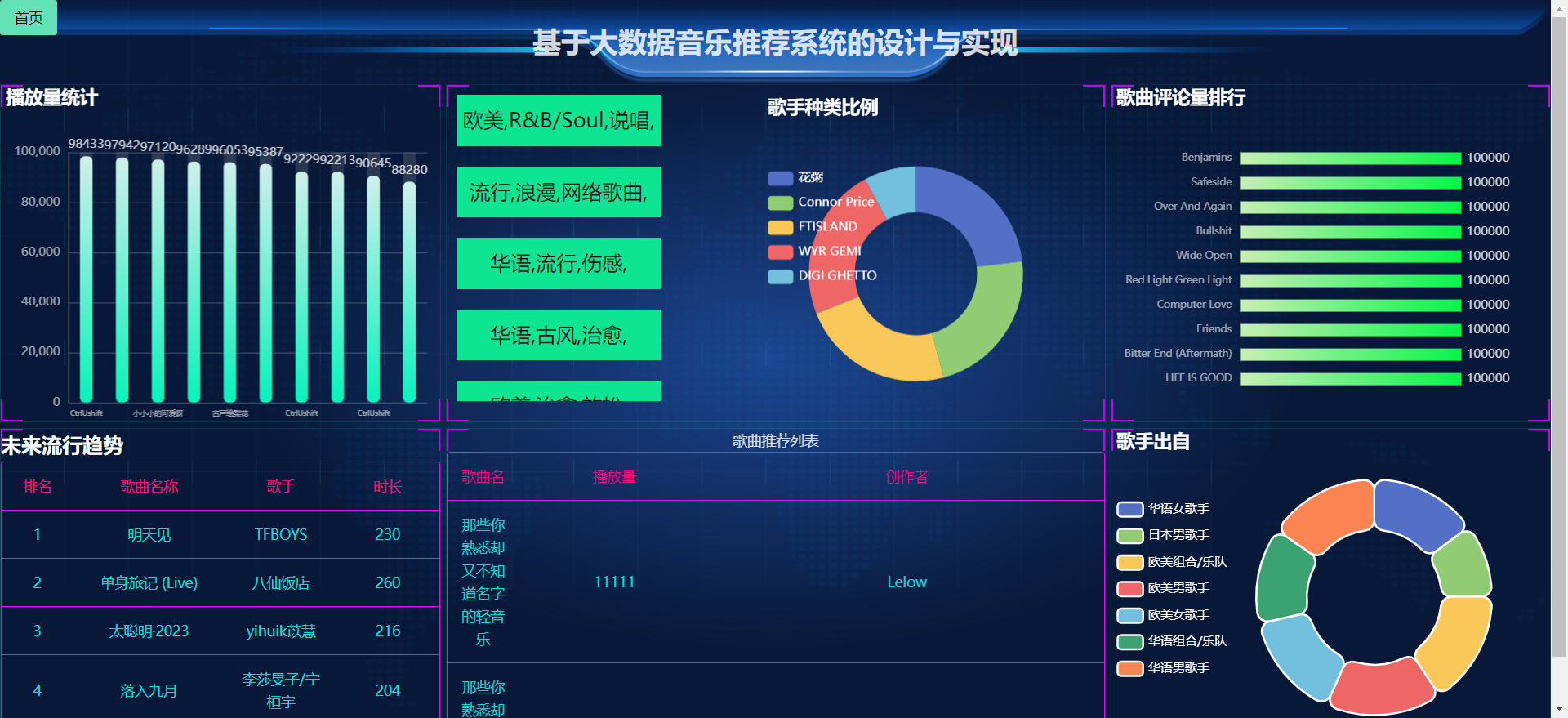
二、项目大数据核心代码
import findspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
findspark.init()
hadoop_url = 'hdfs://127.0.0.1:9000/{dir}/{file}'
spark = SparkSession.builder.appName("hr_job1").getOrCreate()
# 加载hr_data_extended
hr_data_extended = spark.read.option("quote", "\"").csv(hadoop_url.format(dir='hr/dataset', file='hr_data_extended.csv'), header=True)
# 数据清洗
# 字段为空时,填充为0
hr_data_extended = hr_data_extended.fillna(0)
# 某行格式不对时,删除该行
hr_data_extended = hr_data_extended.na.drop()
# 显示数据
hr_data_extended.show()
# 保存到hdfs
hr_data_extended.write.csv(hadoop_url.format(dir='hr/output', file='hr_data_extended'), header=True)
# 任务
firstname_count = hr_data_extended.groupBy('firstname').count().sort('count', ascending=False)
firstname_count.show()
# 修改列名
firstname_count = firstname_count.withColumnRenamed('firstname', 'name').withColumnRenamed('count', 'value1')
# 保存到hdfs
firstname_count.write.csv(hadoop_url.format(dir='hr/output', file='firstname_count'), header=True)
# 任务
lastname_count = hr_data_extended.groupBy('lastname').count().sort('count', ascending=False)
lastname_count.show()
# 修改列名
lastname_count = lastname_count.withColumnRenamed('lastname', 'name').withColumnRenamed('count', 'value1')
# 保存到hdfs
lastname_count.write.csv(hadoop_url.format(dir='hr/output', file='lastname_count'), header=True)
# 任务
department_count = hr_data_extended.groupBy('department').count().sort('count', ascending=False)
department_count.show()
# 修改列名
department_count = department_count.withColumnRenamed('department', 'name').withColumnRenamed('count', 'value1')
# 保存到hdfs
department_count.write.csv(hadoop_url.format(dir='hr/output', file='department_count'), header=True)
# 任务
jobtitle_count = hr_data_extended.groupBy('jobtitle').count().sort('count', ascending=False)
jobtitle_count.show()
# 修改列名
jobtitle_count = jobtitle_count.withColumnRenamed('jobtitle', 'name').withColumnRenamed('count', 'value1')
# 保存到hdfs
jobtitle_count.write.csv(hadoop_url.format(dir='hr/output', file='jobtitle_count'), header=True)
# 任务
projectsinvolved_count = hr_data_extended.groupBy('projectsinvolved').count().sort('count', ascending=False)
projectsinvolved_count.show()
# 修改列名
projectsinvolved_count = projectsinvolved_count.withColumnRenamed('projectsinvolved', 'name').withColumnRenamed('count', 'value1')
# 保存到hdfs
projectsinvolved_count.write.csv(hadoop_url.format(dir='hr/output', file='projectsinvolved_count'), header=True)
san 其他案例




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









