







drf学习第三天
- 我们今天再加一个字段校验
-
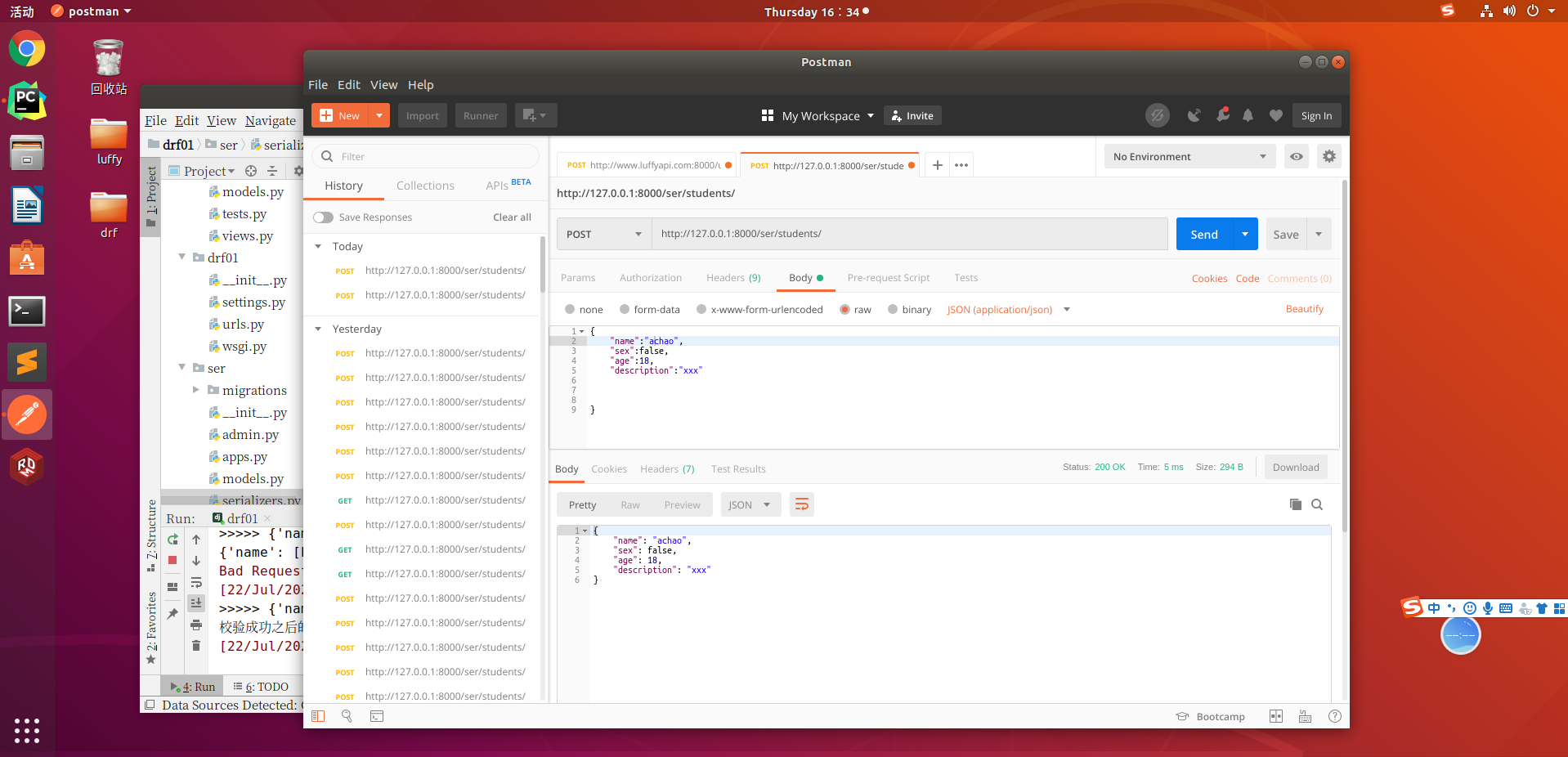
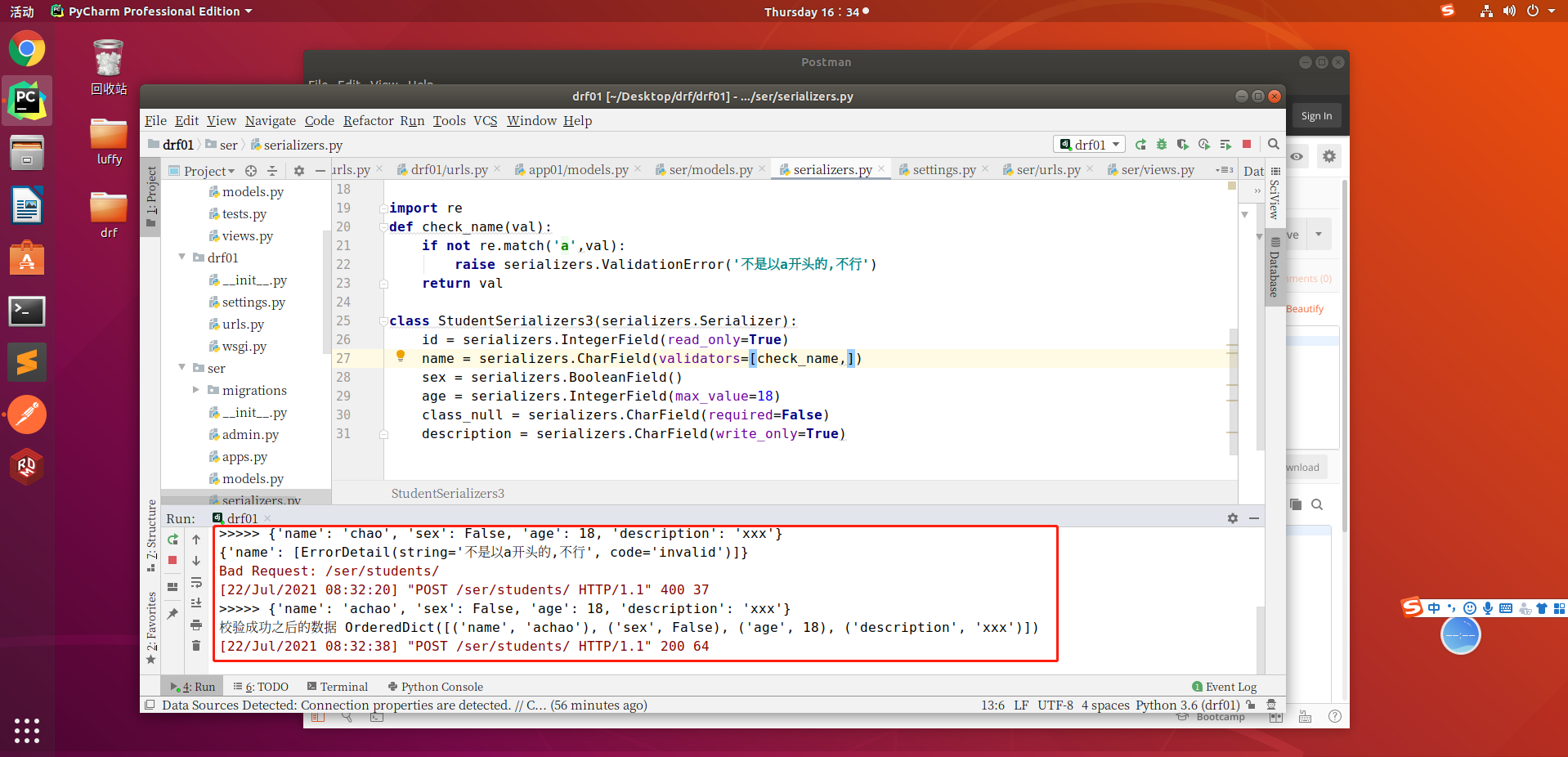
- 访问接口发送post请求,name字段不是以a开头的就通过不了验证
-
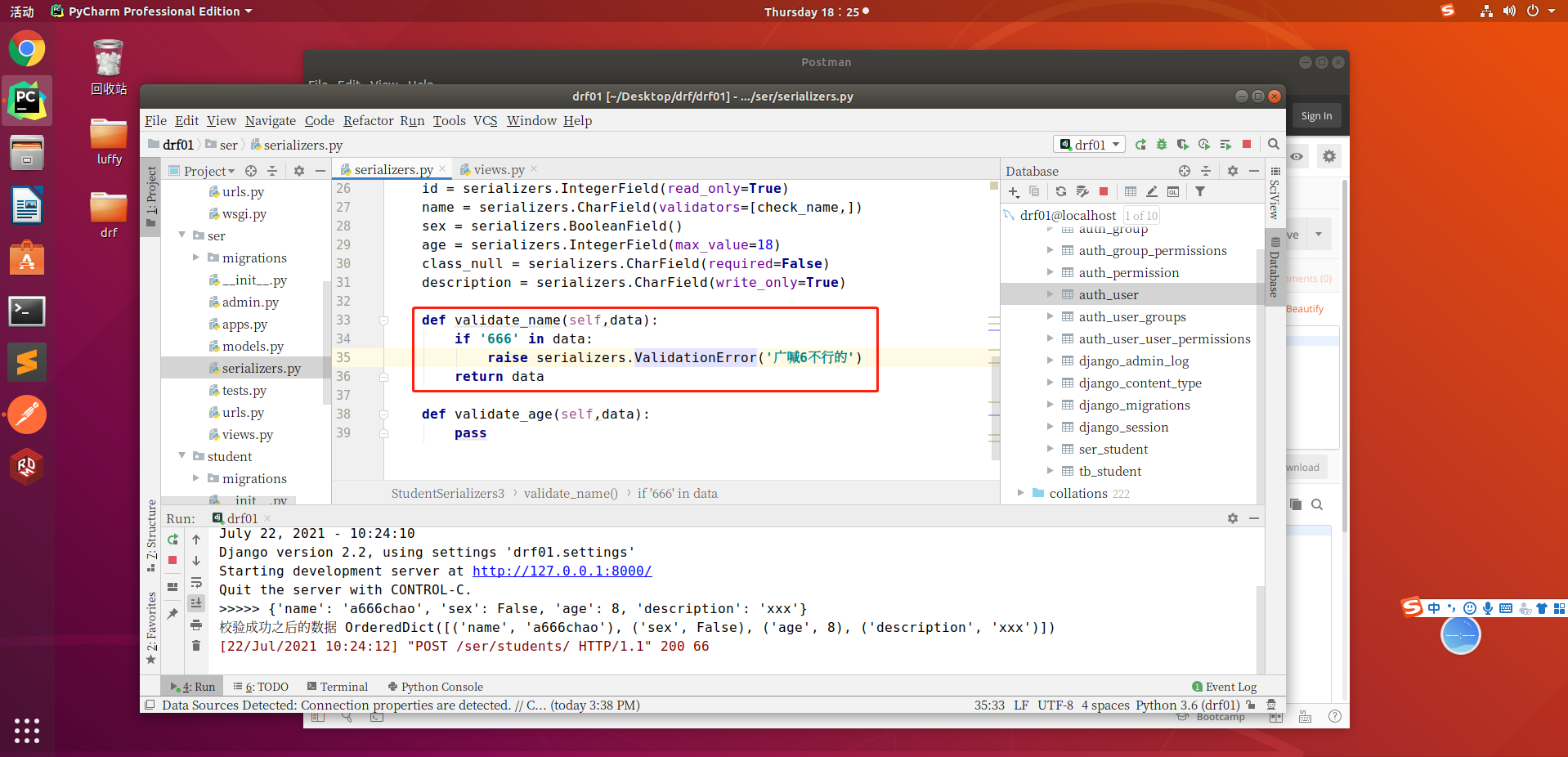
- 也可以写一个局部钩子函数,局部钩子函数执行时间是在参数校验之后
- 接下来写一下全局钩子,全局钩子函数触发时间是在所有字段和局部钩子校验完成之后触发
- 然后我们p1和p2输入的值不一致
- is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True参数开启,REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应。
- 给序列化器加context属性
- 打印一下,self指向当前类的实例化对象
- 打印一下path,看看是不是当前类请求路径
- 校验没问题了接下来要开始保存数据了,保存数据应该携带一个id值,所以我们再序列化一遍
- 把这两个注了
- 发送POST请求,返回的数据里是不是有id值
- 看看数据库里有没有保存我们刚才提交的数据了
- 第二种方式保存
- save保存触发create方法,create方法返回模型类对象,模型类对象再拿到序列化器里序列化,给前端返回jsonresponse响应
- 打印一下create方法validated_data
- 接下来做更新数据
- 先写一个put方法
- partial=True进行部分字段校验,也就是说,传递过来那个字段数据,就校验哪个字段数据,没有传递过来的不校验,在更新的时候我们要加上这个参数
- validated_data拿到的是校验过后的数据
- 由于id值有read_only属性在反序列化时不需要校验,所以在validated_data里没有id值,所以我们通过request.data拿id值
- 成功返回数据了,我们再看看数据库有没有更新,也更新了
- 更新方式二
- save方法更新数据,实例化序列化器类的对象时,传递的参数里加上instance=模型类对象,如果不加这个参数,save方法触发的是create方法
- 序列化器的实例对象.data属性能拿到序列化出来的数据,也就是前端的json数据,也是字典
- 刚才我们接触的都是基础序列化器,接下来我们玩玩模型序列化器
- 先创建一个应用
- 创建序列化器
- 也可以指定字段提取
- 也可以用排除
- 给字段设置属性
- 添加数据试试
- 有同学会问,不要写create方法吗,不需要了,Modelserializer已经给咱们做了
- 还可以定制校验失败返回的错误信息
- exclude 排除字段
- extra_kwargs 自定义属性参数
- ModelSerializer还有一个强大的功能,就是校验的数据如果不是本表的,它也给你校验,不过不存在数据库里
- 在校验成功后的数据里删除password
- 测试接口
- 可以看到校验过后的数据里有password了,不过由于本表里没有password字段,且在序列化器字段属性里设置了write_only=True,所以校验通过了就删了,不保存
我们今天再加一个字段校验
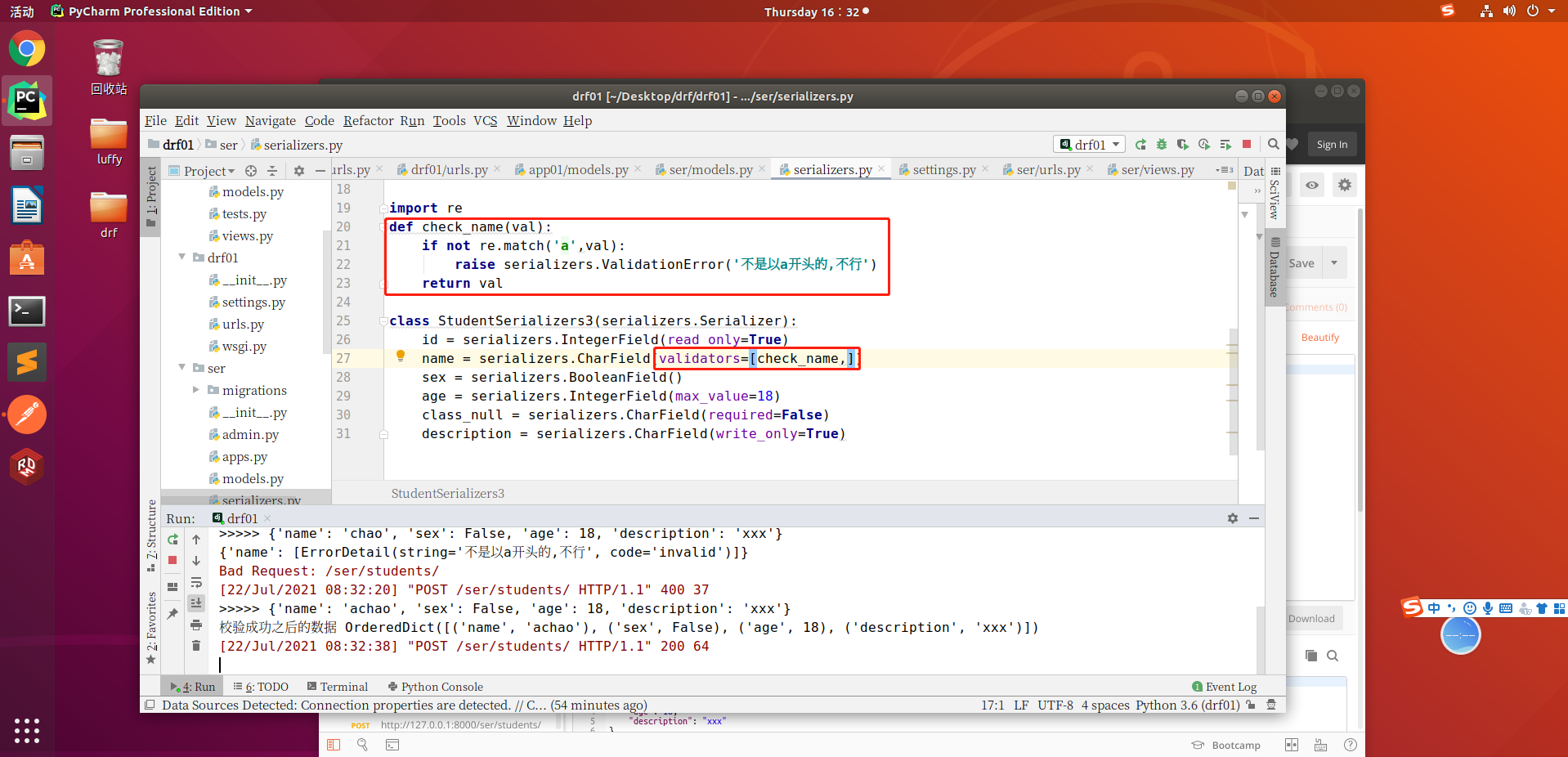
访问接口发送post请求,name字段不是以a开头的就通过不了验证
也可以写一个局部钩子函数,局部钩子函数执行时间是在参数校验之后



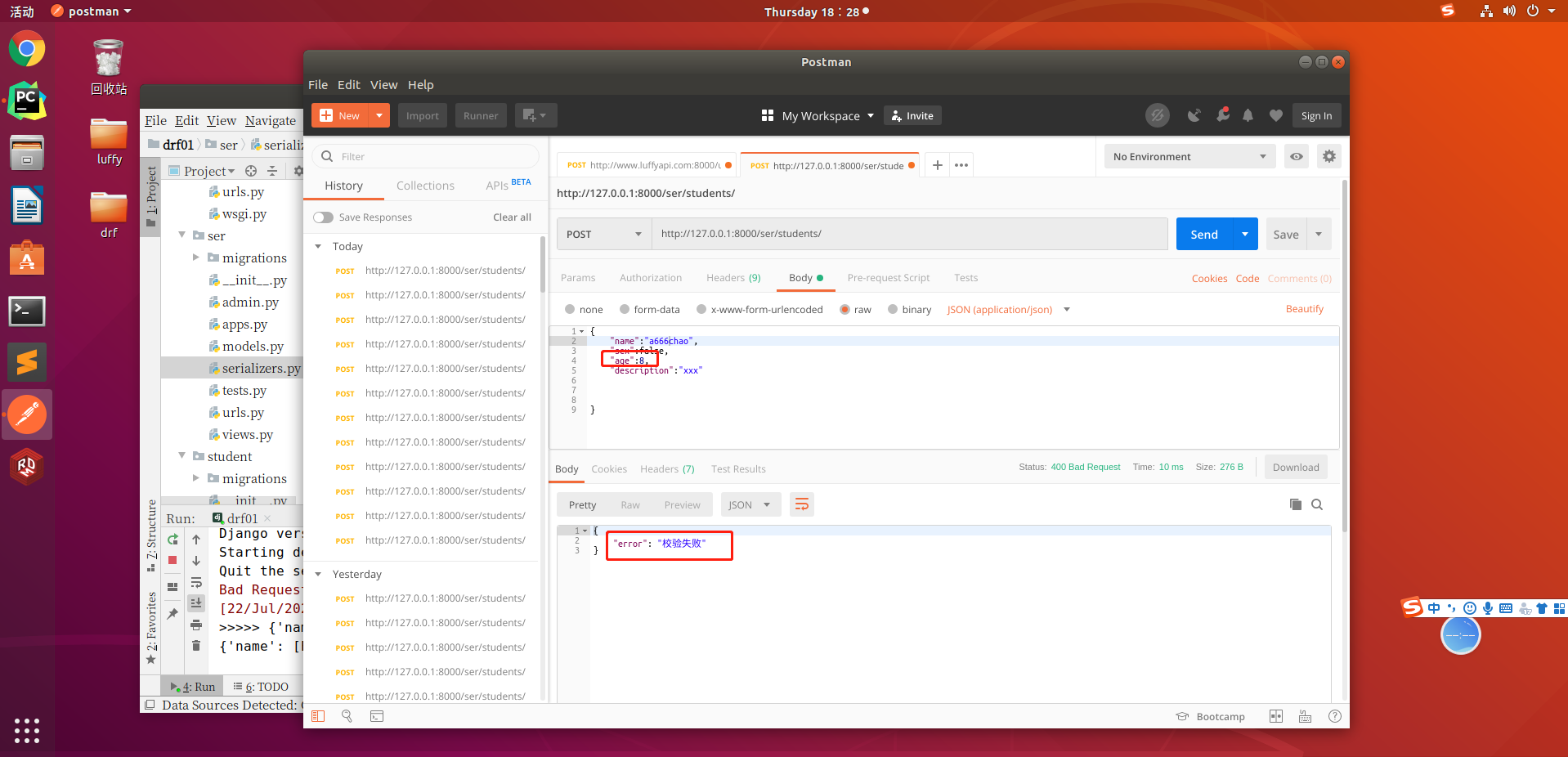
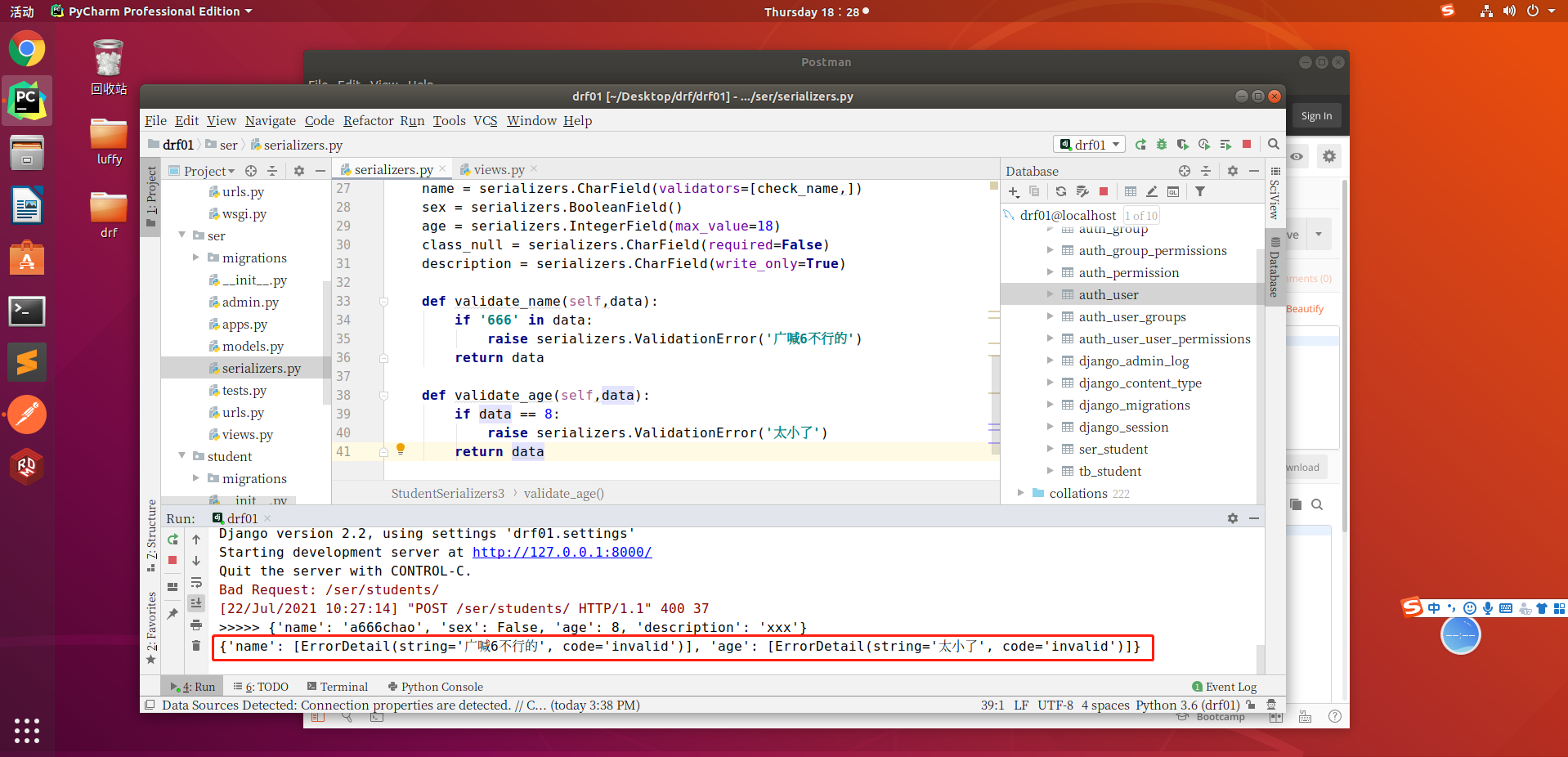
接下来写一下全局钩子,全局钩子函数触发时间是在所有字段和局部钩子校验完成之后触发
def validate(self,data):
p1 = data.get('p1')
p2 = data.get('p2')
if p1 != p2:
raise serializers.ValidationError('两次密码输入不一致')
return data
然后我们p1和p2输入的值不一致


is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True参数开启,REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应。


给序列化器加context属性

打印一下,self指向当前类的实例化对象

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2512
2512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









