






 麻省理工学院的研究人员提出了“彩票假设”,指出大型神经网络中存在小型子网络,这些子网络可以从初始状态训练到与原网络相当的准确度。这一理论挑战了传统神经网络训练方法,并提供了一种更高效训练模型的可能。
麻省理工学院的研究人员提出了“彩票假设”,指出大型神经网络中存在小型子网络,这些子网络可以从初始状态训练到与原网络相当的准确度。这一理论挑战了传统神经网络训练方法,并提供了一种更高效训练模型的可能。
来源商业新知网,原标题:重磅论文!颠覆你对神经网络训练的所有认知
现实生活中,机器学习模型训练是数据科学中难度最大和计算成本最高的一种。几十年以来,在单一公理假设训练会覆盖整个模型的影响下,人工智能领域已经开发出了许多技术来提高机器学习模型的训练。
最近,来自麻省理工学院的人工智能研究员发表了一篇名为“Lottery Ticket Hypothesis(彩票假设)”的论文,在人工智能领域备受关注。 该论文关注模型分支,挑战原先的假说并提出了一种更智能、更简便的方法来训练神经网络。
机器学习模型训练过程中,数据科学家往往需要在理论和现实解决措施的限制面前作出妥协。那些解决实际问题的神经网络架构看似为最佳方法,但是由于训练成本过高而不能充分执行下去。在起初训练时,神经网络一般需要大量数据集,同时需要昂贵的计算费用。而在此操作下,得出的是一张巨大的神经网络结构,其中神经层和隐藏层之间互相连接,从而需要通过技术优化来移除其中一些连接并调整模型的大小。
几十年来,有个问题一直困扰着人工智能研究员们,即在开始训练模型的时候,是否真的需要那些大型神经网络结构。当然,假使连接架构中每个神经元,也许可以实现完成最初任务的模型,但是 其中带来的成本耗费是无法想象的。 难道不能在一开始就组建更小更精简的神经网络架构吗?这正是“彩票假设“讨论的核心问题。
彩票假说
机器学习模型训练就像赌博游戏,通过购买所有可能中奖的彩票来博得大奖。但是如果我们知道如何中奖,难道就不能在挑选彩票的时候更加聪明一些吗?
在机器学习模型中,训练过程会产生与彩票同等大量的神经网络结构。在第一次训练后,模型需要进行技术优化,比如剪枝技术,在不损害神经网络性能的前提下删除神经网络中不必要的部分以缩小模型。这就像在彩票袋里搜寻那张中奖的彩票并且排除其他不会中奖的彩票一样。
通常情况下,剪枝技术能将神经网络结构的减少90%。自然而然,人们就会疑惑:如果可以减小神经网络的大小,为了使得训练更有效率,为什么不去训练更小的神经网络结构呢?
自相矛盾的是,机器学习方案的实践表明,修剪后的神经网络结构起初更难以训练,且训练的精度比起原神经网络更低。
麻省理工学院提出的“彩票假设“核心思想是大神经网络会包含一些较小的子网络,如果从起初就开始训练,子网络便可达到与原始网络比肩的准确率。 研究报告具体内容概括如下:
彩票假设理论: 随机初始化的密集神经网络包含一个被初始化的子网络。当单独训练该子网络时,它可以在训练之后,以最多相同的迭代次数匹配原始网络的测试精度。
在本论文中,子网络往往被指代为中奖彩票。
设定f(t, a, p) 形式的神经网络,其中t =训练时间,a =准确度,p =参数。现在考虑s是由修剪过程产生的原始结构的所有可训练神经网络的子集。“彩票假设”说明,某种 程度上,一个F”(T”,A”,P”)€s其中T” <= T,A”> = a和p” <= P。 简单来说,传统的剪枝训练技术揭示了比原始网络结构更小、更简单的 神经网络结构。
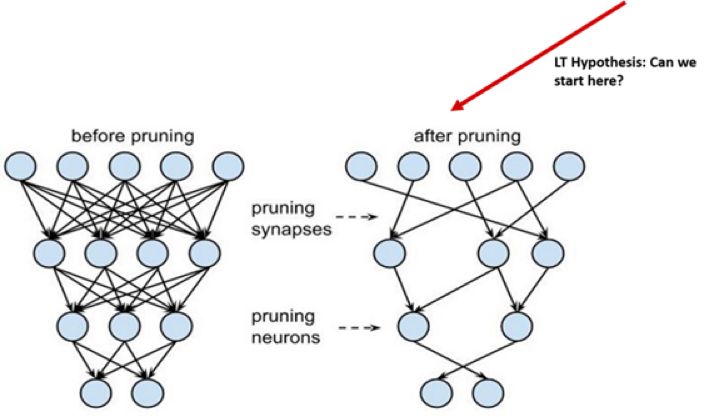
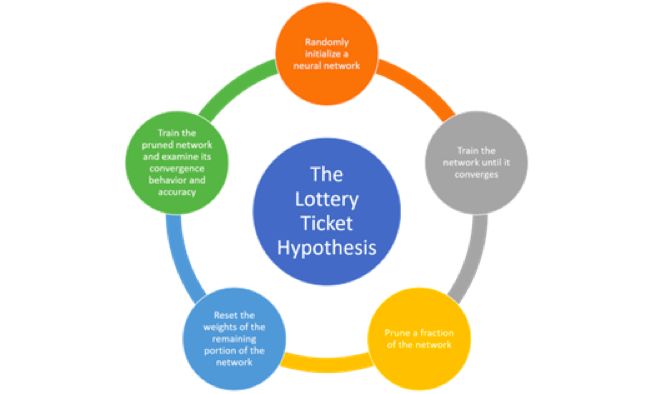
如果“彩票假设“为真,显而易见接下去需要找到确认中奖彩票的策略了。这个过程包含训练和修剪的迭代过程,总结为以下五个步骤:
1. 随机初始化一个神经网络。
2. 训练神经网络直到其形成汇聚。
3. 对神经网络进行剪枝训练。
4. 要提取中奖彩票,请将网络剩余部分的权重重置为步骤(1)所示 (训练开始前的初始值)。
5. 为了评估步骤(4)中产生的网络是否确实是中奖票,训练剪枝过且未经训练的网络并检查其汇聚行为和准确性。
整个流程可以进行一次或多次。在一次性剪枝训练中,神经网络训练为一次,对p%的神经网络进行修剪并且重置余留的权重。尽管一次性剪枝训练一定有效,但是在n轮中迭代时,“彩票假设“才能出现最好的结果;每轮剪枝训练在前一轮中余留p1 / n%的权重。然而,一次性剪枝训练通常产生非常可靠的结果,训练也不需要昂贵的计算成本。
麻省理工学院的团队在一组神经网络架构中检测了“彩票假设“理论,结果表明剪枝训练技术不仅仅可以优化架构本身,还可以找到中奖的彩票。
结果中有两点值得注意。中奖彩票没有广域网的剩余冗余,训练速度更快。事实上,在合理范围内,架构越小,训练速度越快。但是,如果现在随机重新初始化网络权重(控制),生成的网络比现在的完整网络训练速度更慢。因此,剪枝训练不仅要找到正确的架构,还应该找到那个特别幸运的初始化神经网络子组件——中奖彩票。
基于实验结果,麻省理工学院的团队对最初假设进行了扩展,提出彩票预测系统,表述如下:
彩票预测: 回到最初的问题,将假设扩展为一个未经实证的猜想,即使用随机梯度下降(SGD)寻找并训练一个初始状态良好的权重的自己。因为有更多可能的子网络可从训练中找到中奖票,密集、随机、初始化的网络比经过剪枝训练产生的稀疏网络更容易训练。
这个猜想在概念上是说得通的,也就是说,经过剪枝训练后的子网络越大,找到中奖彩票的几率也就越大。
“彩票假设”理论可能成为近年来机器学习研究最重要的研究论文之一, 因为它刷新了传统神经网络训练的观点。通常情况下,虽然我们采取的是通过训练原始网络,删除连接和进一步微调来进行修剪,但是彩票假设告诉我们可以从一开始就学习最佳神经网络结构。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









