







来源商业新知网,原标题:百闻不如一码!手把手教你用Python搭一个Transformer
与基于RNN的方法相比,Transformer 不需要循环,主要是由Attention 机制组成,因而可以充分利用python的高效线性代数函数库,大量节省训练时间。
可是,文摘菌却经常听到同学抱怨,Transformer学过就忘,总是不得要领。
怎么办?那就自己搭一个Transformer吧!
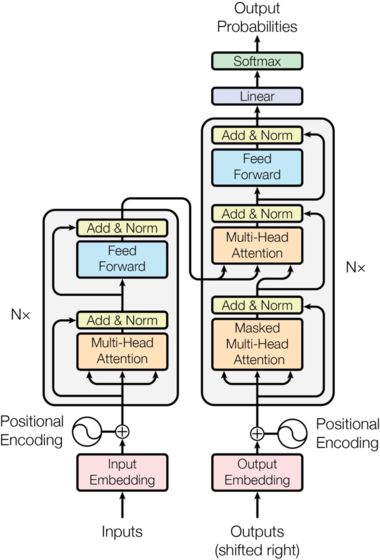
上图是谷歌提出的transformer 架构,其本质上是一个Encoder-Decoder的结构。把英文句子输入模型,模型会输出法文句子。
要搭建Transformer,我们必须要了解5个过程:
-
词向量层
-
位置编码
-
创建Masks
-
多头注意层(The Multi-Head Attention layer)
-
Feed Forward层
词向量
词向量是神经网络机器翻译(NMT)的标准训练方法,能够表达丰富的词义信息。
在pytorch里很容易实现词向量:
class Embedder(nn.Module):
def __init__(self, vocab_size, d_model): super().__init__() self.embed = nn.Embedding(vocab_size, d_model) def forward(self, x): return self.embed(x)
当每个单词进入后,代码就会查询和检索词向量。模型会把这些向量当作参数进行学习,并随着梯度下降的每次迭代而调整。
给单词赋予上下文语境:位置编程
模型理解一个句子有两个要素:一是单词的含义,二是单词在句中所处的位置。
每个单词的嵌入向量会学习单词的含义,所以我们需要输入一些信息,让神经网络知道单词在句中所处的位置。
Vasmari用下面的函数创建位置特异性常量来解决这类问题:
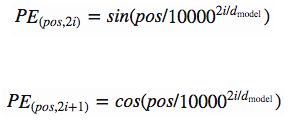
这个常量是一个2D矩阵。Pos代表了句子的顺序,i代表了嵌入向量所处的维度位置。在pos/i矩阵中的每一个值都可以通过上面的算式计算出来。
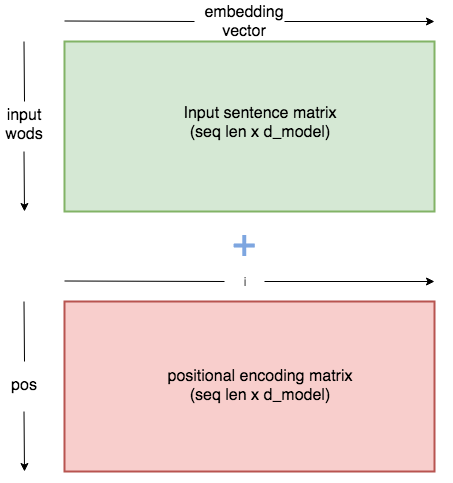
位置编码矩阵是一个常量,它的值可以用上面的算式计算出来。把常量嵌入矩阵,然后每个嵌入的单词会根据它所处的位置发生特定转变。
位置编辑器的代码如下所示:
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_seq_len = 80): super().__init__() self.d_model = d_model # create constant 'pe' matrix with values dependant on # pos and i pe = torch.zeros(max_seq_len, d_model) for pos in range(max_seq_len): for i in range(0, d_model, 2): pe[pos, i] = math.sin(pos / (10000 ** ((2 * i)/d_model))) pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * (i + 1))/d_model))) pe = pe.unsqueeze(0) self.register_buffer('pe', pe) def forward(self, x): # make embeddings relatively larger x = x * math.sqrt(self.d_model) #add constant to embedding seq_len = x.size(1) x = x + Variable(self.pe[:,:seq_len], requires_grad=False).cuda() return x
以上模块允许我们向嵌入向量添加位置编码(positional encoding),为模型架构提供信息。
在给词向量添加位置编码之前,我们要扩大词向量的数值,目的是让位置编码相对较小。这意味着向词向量添加位置编码时,词向量的原始含义不会丢失。
创建Masks
Masks在transformer模型中起重要作用,主要包括两个方面:
在编码器和解码器中:当输入为padding,注意力会是0。
在解码器中:预测下一个单词,避免解码器偷偷看到后面的翻译内容。
输入端生成一个mask很简单:
batch = next(iter(train_iter))
input_seq = batch.English.transpose(0,1)input_pad = EN_TEXT.vocab.stoi['']# creates mask with 0s wherever there is padding in the inputinput_msk = (input_seq != input_pad).unsqueeze(1)
同样的,Target_seq也可以生成一个mask,但是会额外增加一个步骤:
# create mask as before
target_seq = batch.French.transpose(0,1)target_pad = FR_TEXT.vocab.stoi['']target_msk = (target_seq != target_pad).unsqueeze(1)size = target_seq.size(1) # get seq_len for matrixnopeak_mask = np.triu(np.ones(1, size, size),k=1).astype('uint8')nopeak_mask = Variable(torch.from_numpy(nopeak_mask) == 0)target_msk = target_msk & nopeak_mask
目标语句(法语翻译内容)作为初始值输进解码器中。解码器通过编码器的全部输出,以及目前已翻译的单词来预测下一个单词。
因此,我们需要防止解码器偷看到还没预测的单词。为了达成这个目的,我们用到了nopeak_mask函数:
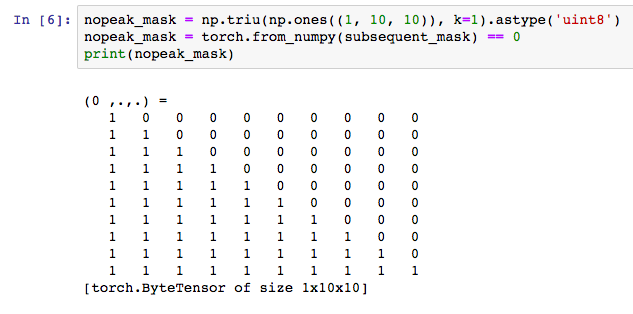
当在注意力函数中应用mask,每一次预测都只会用到这个词之前的句子。
多头注意力
一旦我们有了词向量(带有位置编码)和masks,我们就可以开始构建模型层了。
下图是多头注意力的结构:
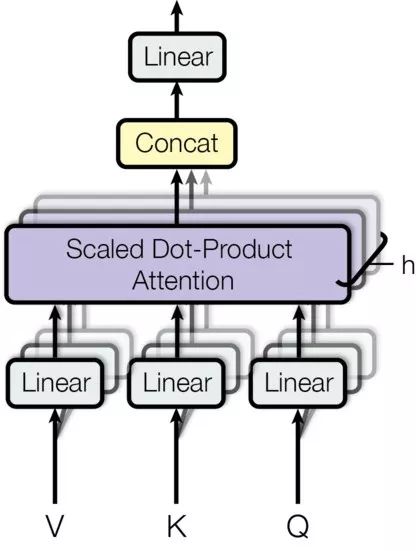
多头注意力层,每一个输入都会分成多头(multiple heads),从而让网络同时“注意”每一个词向量的不同部分。
V,K和Q分别代表“key”、“value”和“query”,这些是注意力函数的相关术语,但我不觉得解释这些术语会对理解这个模型有任何帮助。
在编码器中,V、K和G将作为词向量(加上位置编码)的相同拷贝。它们具有维度Batch_size * seq_len * d_model.
在多头注意力中,我们把嵌入向量分进N个头中,它们就有了维度(batch_size * N * seq_len * (d_model / N).
我们定义最终维度 (d_model / N )为d_k。
让我们来看看解码器模块的代码:
class MultiHeadAttention(nn.Module):
def __init__(self, heads, d_model, dropout = 0.1): super().__init__() self.d_model = d_model self.d_k = d_model // heads self.h = heads self.q_linear = nn.Linear(d_model, d_model) self.v_linear = nn.Linear(d_model, d_model) self.k_linear = nn.Linear(d_model, d_model) self.dropout = nn.Dropout(dropout)self.out = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









