






 本文介绍了如何在Hive中优化配置以处理大规模维度表数据,包括动态分区设置、压缩策略,以及如何将数据导出至PostgreSQL数据库。同时涉及了Zookeeper的分布式协调服务和数据模型,强调一致性保证在数据处理中的重要性。
本文介绍了如何在Hive中优化配置以处理大规模维度表数据,包括动态分区设置、压缩策略,以及如何将数据导出至PostgreSQL数据库。同时涉及了Zookeeper的分布式协调服务和数据模型,强调一致性保证在数据处理中的重要性。
一、处理维度表数据
hive的配置
-- 开启动态分区方案 -- 开启非严格模式 set hive.exec.dynamic.partition.mode=nonstrict; -- 开启动态分区支持(默认true) set hive.exec.dynamic.partition=true; -- 设置各个节点生成动态分区的最大数量: 默认为100个 (一般在生产环境中, 都需要调整更大) set hive.exec.max.dynamic.partitions.pernode=10000; -- 设置最大生成动态分区的数量: 默认为1000 (一般在生产环境中, 都需要调整更大) set hive.exec.max.dynamic.partitions=100000; -- hive一次性最大能够创建多少个文件: 默认为10w set hive.exec.max.created.files=150000; -- hive压缩 -- 开启中间结果压缩 set hive.exec.compress.intermediate=true; -- 开启最终结果压缩 set hive.exec.compress.output=true; -- 写入时压缩生效 set hive.exec.orc.compression.strategy=COMPRESSION;
分类表
分类表(
ods_dim_category_f)拉平处理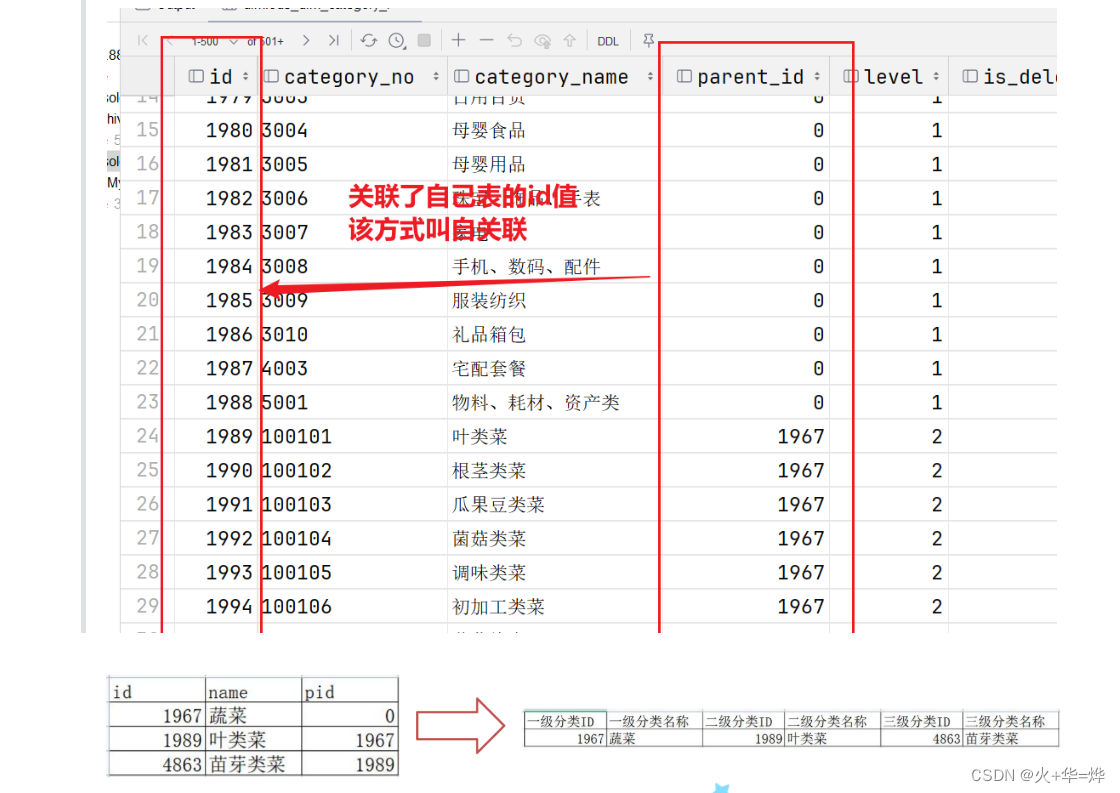
insert overwrite table dwd_dim_category_statistics_i partition(dt) select t1.id, t1.category_no, t1.category_name, t2.id, t2.category_no, t2.category_name, t3.id, t3.category_no, t3.category_name, 0 status, date_add(current_date,-1) dt from dim.ods_dim_category_f t1 join dim.ods_dim_category_f t2 on t1.id = t2.parent_id join dim.ods_dim_category_f t3 on t2.id = t3.parent_id
商品表
商品表(
ods_dim_goods_info_f)处理将分类编号替换为一二三级分类ID、编码和名称
关联分类表,将商品表中的category_no 对应的是分类表中的三级分类

insert into dwd_dim_goods_i partition (dt) select id, goods_no, goods_name, first_category_id, first_category_no, first_category_name, second_category_id, second_category_no, second_category_name, third_category_id, third_category_no, third_category_name, brand_no, spec, sale_unit, life_cycle_status, tax_rate_status, tax_rate, tax_value, order_multiple, pack_qty, split_type, is_sell_by_piece, is_self_support, is_variable_price, is_double_measurement, is_must_sell, is_seasonal, seasonal_start_time, seasonal_end_time, is_deleted, goods_type, create_time, update_time, date_add(current_date, -1) dt from ods_dim_goods_info_f t1 left join dwd_dim_category_statistics_i t2 on t1.category_no = t2.third_category_no;
门店商品表
门店商品表(
ods_dim_store_goods_f)处理将分类ID替换为对应一二三级分类ID、编码和名称
统商品表逻辑一样

insert overwrite table dwd_dim_store_goods_i partition(dt) select uid, store_no, goods_no, goods_name, first_category_no, first_category_name, second_category_no, second_category_name, third_category_no, third_category_name, is_clear, is_must_order, is_orderable, order_multiple, min_order_qty, vendor_no, vendor_name, group_no, group_name, dc_no, dc_name, tag, create_time, update_time, is_deleted, date_add(current_date, -1) dt from ods_dim_store_goods_f t1 left join dwd_dim_category_statistics_i t2 on t1.category_no = t2.third_category_no;
门店日清商品表处理
门店日清商品表处理
日清商品,不满足以下要求的商品需要清理掉不再入库,主要是一些生鲜类和现做的食物
一切以实物为标准,不允许变色、不新鲜产品入库。
骨类入库存放时间不得超过24小时。
上冰台的所有促销品当天尽量要做到日清,对于上冰台的当日未销售完的产品,未变色,不影响第二天销售的可以入库。
对于化冻的禽副产品当日必须销售完毕,猪副产品根据品相颜色以实物相论。
从门店商品表中进行条件过滤,过滤出日清商品,然后进行保存
insert into dwd_dim_store_clear_goods_i partition(dt) select * from dwd_dim_store_goods_i where is_clear=1;
门店表处理
需要使用的表,将如下三张表的数据关联在一起
分店信息表 ods_dim_store_f
需要表中的所有字段
分店面积明细表 ods_dim_store_area_info_f
store_no 门店编号
area_type_no 面积类型编号
area 面积类型名称
分店分组信息表 ods_dim_store_group_f
store_group_name 分组名称
1-门店面积信息可以从分店面积明细表中获取。先取实际经营面积,如果取不到(实际经营面积为空或0)再取经营面积。
2-区域名称信息从店组信息表中取,store_group_type_no = ‘04’即对应区域的编码和名称。
3-store_type_code和management_type_code 需要转换为整数类型
门店面面积获取逻辑讲解
create table tb_area_test( id int, store_no string, area_type_no int, area_type_name string, area int ); insert overwrite table tb_area_test values(1,'T065',1,'合同面积',120), (2,'T065',7,'经营面积',110), (3,'Y291',7,'经营面积',98), (4,'Y291',8,'实际经营面积',98), (5,'T057',8,'实际经营面积',111), (6,'T057',2,'外租面积',20), (7,'T038',1,'合同面积',100), (8,'T038',2,'外租面积',15);
完整的实际代码
with tb1 as ( -- 筛选出有7和8的店铺 select store_no, max(area_type_no) as max_data from ods_dim_store_area_info_f where area_type_no in (7, 8) group by store_no), tb2 as ( -- 获取对应面积信息 select t1.store_no, t1.area_type_no, t1.area from ods_dim_store_area_info_f t1 join tb1 on t1.store_no = tb1.store_no and t1.area_type_no = tb1.max_data) -- CTE语法的数据写入 insert into dwd_dim_store_i partition (dt) select ds.id, ds.store_no, store_name, cast(management_type_code as int) as store_sale_type, cast(store_type_code as int) as store_type_code, city_id, city_name, region_code, sg.store_group_name as region_name, worker_num, manager_name, telephone, opening_date, open_time, close_time, status, ds.is_deleted, ds.create_time, ds.update_time, area as store_area, decoration_code, if(flag = 16, 1, 0) as is_day_clear, date_add(current_date, -1) dt from ods_dim_store_f ds left join tb2 on ds.store_no = tb2.store_no left join ods_dim_store_group_f sg on ds.region_code = sg.store_group_no and store_group_type_no = '04';
交易类型表
不需要做任何处理
insert overwrite table dim.dwd_dim_source_type_map_i partition (dt) select company, original_source_type, original_source_type_name, source_type, source_type_name, is_online, date_sub(current_date(),1) as dt from dim.ods_dim_source_type_map_f ;
时间维度表
不需要做任何处理
insert overwrite table dim.dwd_dim_date_f select trade_date, year_code, month_code, day_code, quanter_code, quanter_name, week_trade_date, month_trade_date, week_end_date, month_end_date, last_week_trade_date, last_month_trade_date, last_week_end_date, last_month_end_date, year_week_code, week_day_code, day_year_num, month_days, is_weekend, days_after1, days_after2, days_after3, days_after4, days_after5, days_after6, days_after7 from dim.ods_dim_date_f;
二、PostGreSQL介绍
https://www.postgresql.org/

三、PostGreSQL基本使用
2-1 datagrip配置
账户:postgres 密码:itcast123
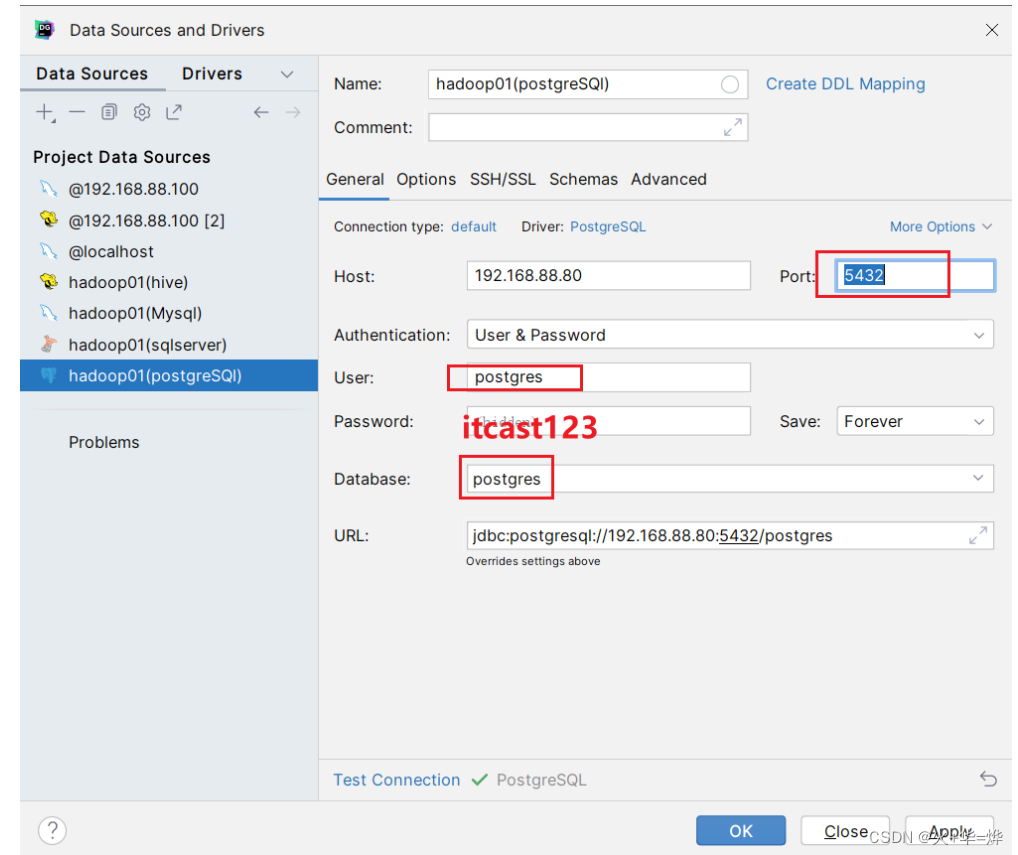
2-2 数据库操作
-- 创建数据库 create database itcast; -- 删除数据库 drop database itcast;
2-4 数据表操作
-- 数据表的创建 create table tb_user( id int, name varchar(20), age int, gender varchar(20) ); -- 数据表的写入 insert into tb_user values(1,'张三',20,'男'); -- 查询数据 select * from tb_user; select count(*) from tb_user; select gender,sum(age) from tb_user group by gender; select id,sum(age) over(order by id) from tb_user; with tb as( select * from tb_user ) select * from tb;
四、Hive表数据导出PostGreSQL
1-需要再postGreSQL中创建对应表保存数据
参考建表语句文档
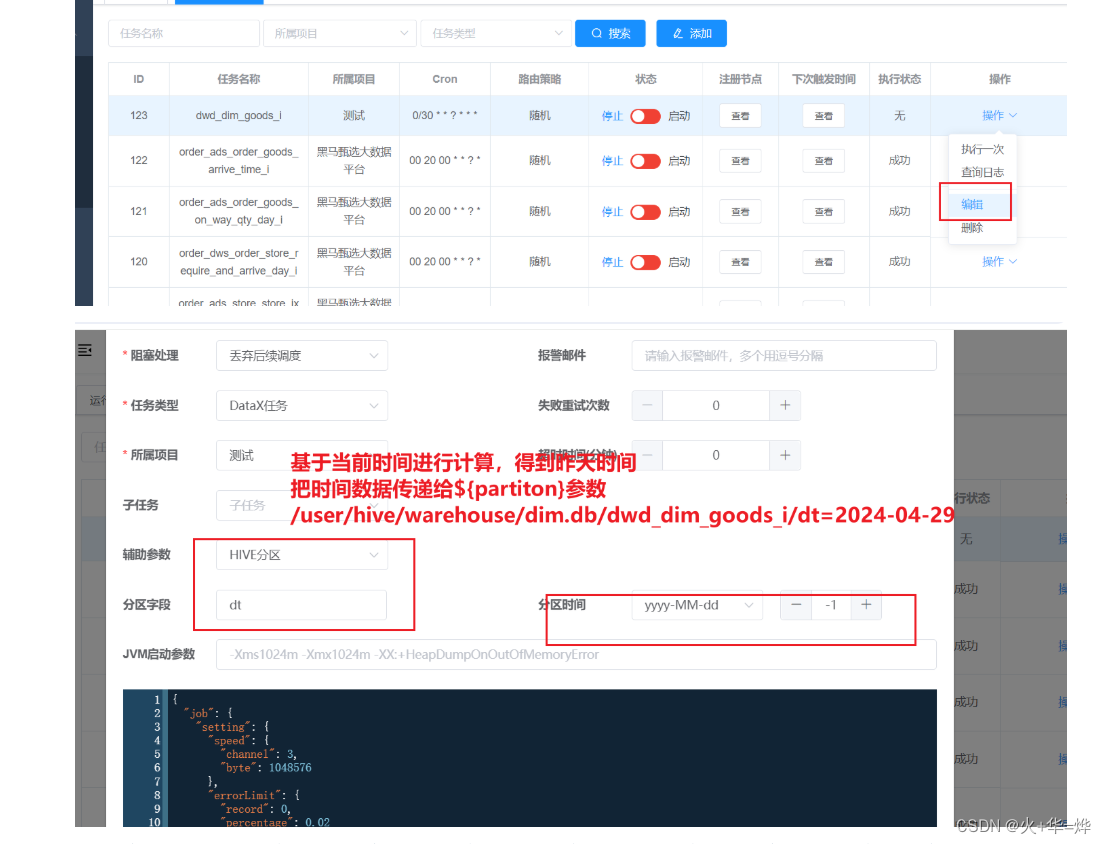
2-配置datax任务
启动datax-web服务 /export/server/datax-web-2.1.2/bin/start-all.sh

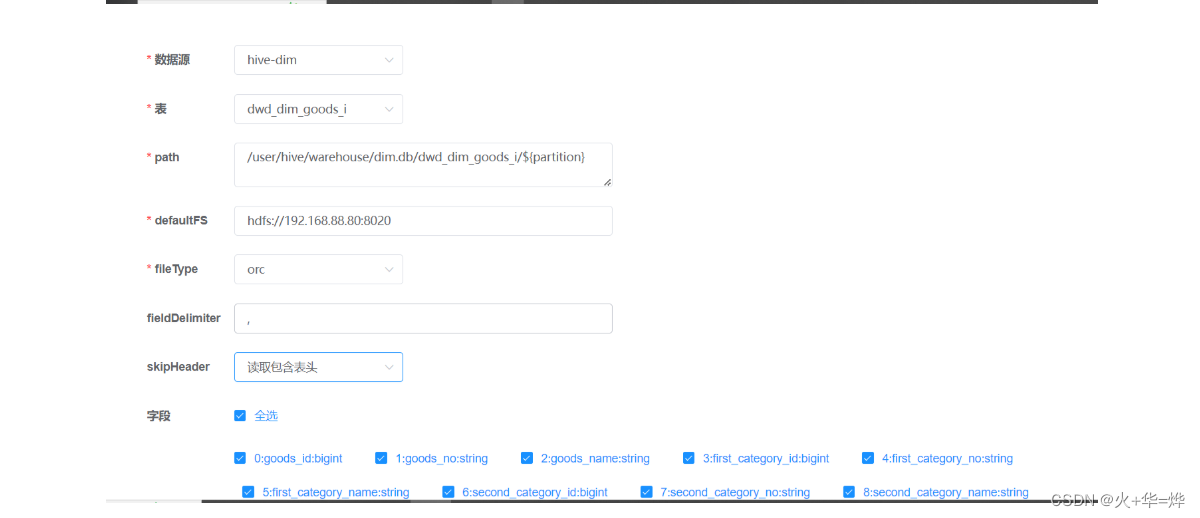
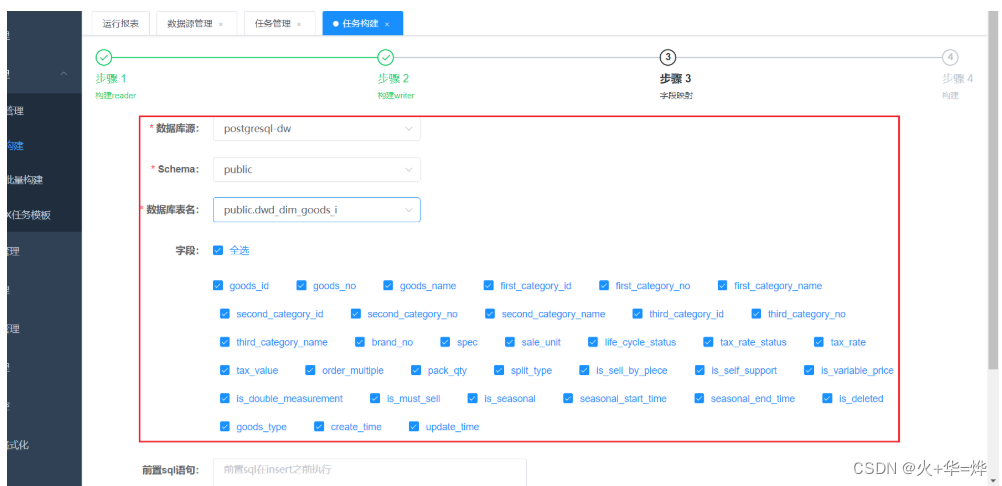

五、zookeeper介绍
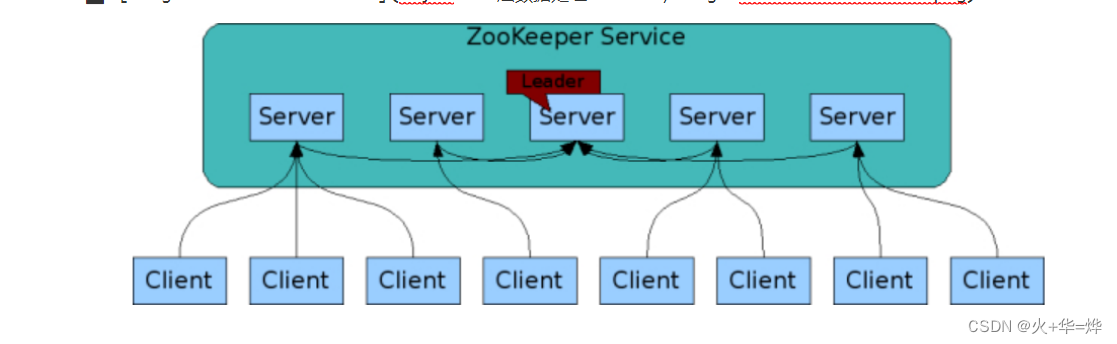
ZooKeeper是一个具有高可用性的高性能分布式协调服务。
官网 ZooKeeper: Because Coordinating Distributed Systems is a Zoo
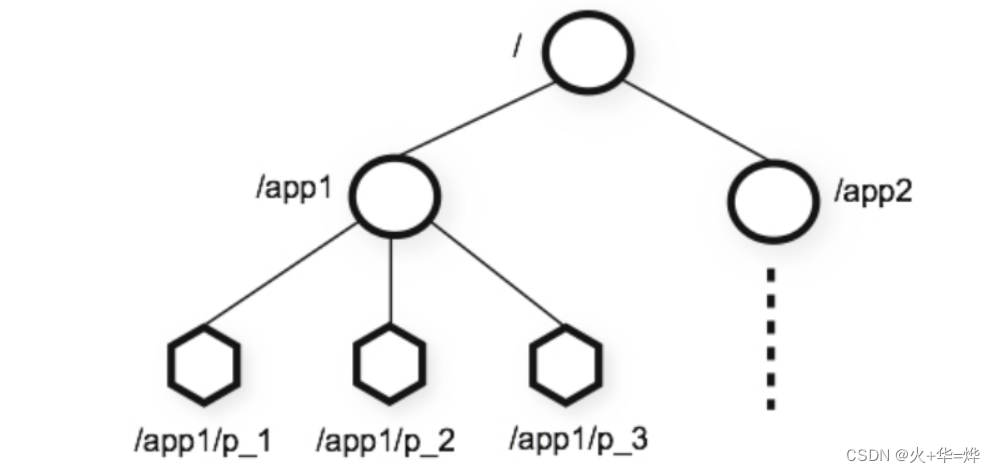
数据模型
zk可存储小文件数据,用来保存其他服务的信息,比如保存hdfs的namenode信息,ds的运行信息
ZooKeeper 维护着一个树形层次结构,树中的节点被称为 znode。znode 可以用于存储数据,并且有一个与之相关联的 ACL。ZooKeeper 被设计用来实现协调服务(这类服务通常使用小数据文件),而不是用于大容量数据存储,因此一个 znode 能存储的数据被限制在1MB以内
操作使用
1-登录客户端
/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/zookeeper/bin/zkCli.sh
查看根节点下子节点有哪些

创建新的节点并指定数据
create 节点名(从根节点开始) 数据

查看节点内的数据
get 节点名
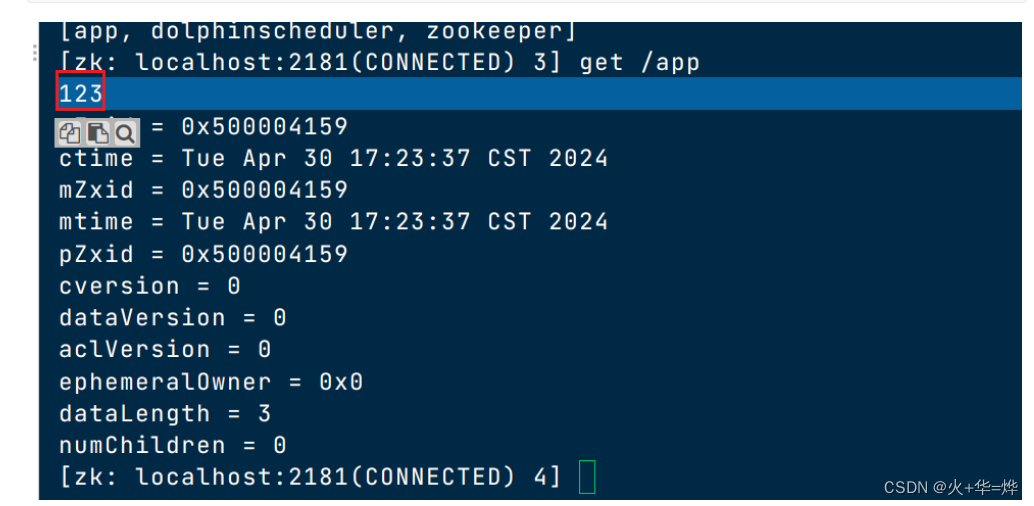
删除节点及数据

运行机制
第一阶段 启动服务,进行领导者选举
所有机器通过一个选择过程来选出一台被称为领导者(leader)的机器,其他的机器被称为跟随者(follower)。一旦半数以上(或指定数量)的跟随者已经将其状态与领导者同步,则表明这个阶段已经完成
第二阶段 原子广播进行数据读写
所有的写请求都会被转发给领导者,再由领导者将更新广播给跟随者。当半数以上的跟随者已经将修改持久化之后,领导者才会提交这个更新,然后客户端才会收到一个更新成功的响应。这个用来达成共识的协议被设计成具有原子性,因此每个修改要么成功要么失败。
如果领导者出现故障,其余的机器会选出另外一个领导者,并和新的领导者一起继续提供服务。随后,如果之前的领导者恢复正常,会成为一个跟随者。领导者选举的过程是非常快的,
一致性
一个跟随者可能滞后于领导者几个更新。这也表明在一个修改被提交之前,只需要集合中半数以上机器已经将该修改持久化则认为更新完成
对 ZooKeeper 来说,理想的情况就是将客户端都连接到与领导者状态一致的服务器上















 2727
2727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









