一个HDFS系统一般由一个namenode和多个datanode构成,可能还有一个secondary namenode。其中namenode负责管理目录和文件的元信息,对于文件夹来说,包含的信息有“复制级别”、修改时间和访问时间、访问许可、块大小、组成一个文件的块等;对于目录来说,包含的信息有修改时间、访问许可和配额元数据等信息。datanode负责管理块数据及其元信息(generation stamp和checksum),当datanode加入集群时,namenode根据datanode报告的块列表建立块映射关系,在datanode运行期间,会定时向namenode报告数据块的信息,以维护最新的块映射。
当datanode加入集群后,每隔一段时间会向namenode发送心跳,namenode会返回一些命令,比如发送块到另一datanode、删除或恢复块等。namenode与datanode是服务端/客户端结构,datanode通过RPC来向namenode发送请求;而datanode之间是对等结构,相互之间可以通过socket来进行通信、发送数据。
以下将简单介绍namenode和datanode的存储目录结构。
1. namenode的目录结构
namenode的存储目录由dfs.name.dir属性设置,目录的结构如下所示:
${dfs.name.dir}/current/VERSION
/edits
/fsimage
/fstime
VERSION文件是一个Java属性文件,其中包含正在运行的HDFS的版本信息。属性layoutVersion是一个负整数,描述HDFS永久性数据结构(也称布局)的版本。只要布局变更,版本号便会递减,HDFS也需要升级。
edits、fsimage和fstime等二进制文件使用Hadoop的Writable对象作为其序列化格式。
namenode每隔一小时(由fs.checkpoint.period属性设置)创建检查点;当编辑日志的大小达到64MB(由fs.checkpoint.size属性设置)时,也会创建检查点。
2. Secondary Namenode的目录结构
辅助Namenode的存储目录由fs.checkpoint.dir属性设置,目录的结构如下所示:
$(fs.checkpoint.dir}/current/VERSION
/edits
/fsimage
/fstime
/previous.checkpoint/VERSION
/edits
/fsimage
/fstime
3. Datanode的目录结构
datanode的存储目录由dfs.data.dir属性设置,该目录是datanode启动时自动创建的,不需要进行格式化,目录的结构如下所示:
${dfs.data.dir}/current/VERSION
/blk_<id_1>
/blk_<id_1>.meta
/blk_<id_1>
/blk_<id_1>.meta
/...
/blk_<id_64>
/blk_<id_64>.meta
/subdir0/
/subdir1/
/...
/subdir63/
/previous/
/detach/
/tmp/
/in_use.lock
/storage
current是当前的工作目录,previous是升级HDFS之前的工作目录,在升级时,HDFS并不会将文件从previous拷贝到current目录中,而是遍历previous中的所有文件,在current目录中创建硬链接。
detach目录保存用于copy-on-write的文件,在Datanode重启时需要恢复。
tmp目录保存一些临时数据。
in_use.lock文件用于对datanode加锁,storage文件保存了布局版本及升级版本提示信息。
下面来看current目录的结构,目录中的文件都有blk_前缀,有两类文件:块文件和块元数据文件(.meta后缀)。当目录中数据块的数量增加到64个(由dfs.datanode.numblocks属性设置,子目录的数量也是由该属性设置),datanode会创建一个子目录来存放新的数据。采用树状结构的组织方式,datanode可以有效管理各个目录中的文件,避免将很多文件放在一个目录之中。
4. HDFS配置
HDFS的配置在core-site.xml和hdfs-site.xml两个配置文件中,也可以通过命令行参数或在程序中进行设置,以下列出了两个文件中的重要配置。
core-size.xml
- fs.default.name: Hadoop的默认文件系统,默认值是“file:///”
- hadoop.tmp.dir: 临时目录的路径,默认值是“/tmp/hadoop-${user.name}”
- io.file.buffer.size: IO操作的缓冲区大小
hdfs-site.xml
- dfs.block.size: 数据块的大小,默认值是64MB
- dfs.replication: 数据块副本的数量,默认值是3
- dfs.name.dir: namenode存储目录的路径,默认值是“${hadoop.tmp.dir}/dfs/name”
- dfs.data.dir: datanode存储目录的路径,默认值是“${hadoop.tmp.dir}/dfs/data”
- dfs.checkpoint.dir: secondary namenode存储目录的路径,默认值是“${hadoop.tmp.dir}/dfs/namesecondary”
- dfs.datanode.ipc.address: datanode的RPC服务器地址和端口,默认值是0.0.0.0:50020
- dfs.http.address: namenode的HTTP服务器地址和端口,默认值是0.0.0.0:50070
- dfs.datanode.http.address: datanode的HTTP服务器地址和端口,默认值是0.0.0.0:50075
- dfs.secondary.http.address: secondary namenode的HTTP服务器地址和端口,默认值是0.0.0.0:50090
5. HDFS工具
5.1. 命令行接口
可以使用调用hadoop fs来使用文件系统,大多数命令与Unix命令相似,主要的命令如下表所示:
| 命令 | 说明 |
|---|
| -help | 获取所有命令的详细帮助文件 |
| -ls | 列举文件 |
| -df | 显示文件系统的容量、已用和可用空间 |
| -du | 显示文件的空间使用情况 |
| -cp | 复制文件或目录 |
| -mv | 移动文件或目录 |
| -mkdir | 创建目录 |
| -rm | 删除文件 |
| -rmr | 删除目录 |
| -put | 将本地文件复制到HDFS |
| -get | 将HDFS上的文件复制到本地 |
| -cat | 取出文件内容并显示到标准输出 |
5.2. Web接口
访问http://namenode:50070页面,可以查看HDFS文件系统的使用情况、各datanode的状态以及浏览文件系统。
5.3. dfsadmin工具
dfsadmin工具是多用途的,既可查找HDFS状态信息,又可以HDFS上执行管理操作,调用形式是hadoop dfsadmin,仅当用户具有超级用户权限,才可以使用这个工具修改HDFS的状态,下表列举了dfsadmin的一些命令:
| 命令 | 说明 |
|---|
| -help | 获取所有命令的详细帮助文件 |
| -report | 显示文件系统的统计信息,以及连接的各个datanode的信息 |
| -metasave | 将某些信息存储到Hadoop日志目录中的一个文件中 |
| -savemode | 改变或查询安全模式 |
| -saveNamespace | 将内存中的文件系统映像保存为一个新的fsimage文件,重置edits文件 |
| -refreshNodes | 更新允许连接到namenode的datanode列表 |
| -upgradeProgress | 获取有关HDFS升级的进度信息,或强制升级 |
| -finalizeUpgrade | 移除datanode和namenode的存储目录上的旧版本数据 |
| -setQuota | 设置目录的配额,即设置以该目录为根的整个目录树最多包含多少个文件和目录 |
| -clrQuota | 清理指定目录的配额 |
| -setSpaceQuota | 设置目录的空间配额,以限制存储在目录树中的所有文件的总规模 |
| -clrSpaceQuota | 清理指定的空间配额 |
| -refreshServiceAcl | 刷新namenode的服务器授权策略文件 |
前提
Hadoop版本:hadoop-0.20.2
概况
HDFS(Hadoop Distributed File System)是一个复杂的项目,大体上分为namenode、datanode、client三部分。namenode是核心部分,管理着文件的信息、数据块的映射关系、checkpoint、编辑日志等,处理HDFS的主要逻辑,作为服务端接收datanode、client的请求并进行处理。datanode主要管理文件的数据块,datanode与namenode是客户端/服务端结构,每隔一段时间会向namenode发送心跳,namenode会返回一些命令;datanode之间是对等结构,相互之间可以通过socket来进行通信、发送数据;datanode与client之间是服务端/客户端结构,接受client的读、写请求。
client读数据如下图所示:

client写数据如下图所示:

由datanode直接与操作系统的文件系统打交道,处理文件的操作,因而自底向上,先从datanode的源码开始分析。
datanode源码结构
在hadoop-0.20.2中,datanode相关的代码大约1万行左右,主要代码在以下几个包中:
- org.apache.hadoop.hdfs.protocol
- org.apache.hadoop.hdfs.server.common
- org.apache.hadoop.hdfs.server.datanode
- org.apache.hadoop.hdfs.server.protocol
后续将会对datanode的数据结构、协议、存储、数据、行为等进行分析。
前提
Hadoop版本:hadoop-0.20.2
概述
datanode协议包括基本的数据结构、调用接口以及通信的内容,本文中将简单分析这几部分内容,所涉及到的类的包结构如下所示:
- org.apache.hadoop.hdfs.protocol
- Block
- ClientDatanodeProtocol
- DatanodeID
- DatanodeInfo
- LocatedBlock
- org.apache.hadoop.hdfs.server.protocol
- BlockCommand
- BlockMetaDataInfo
- DatanodeCommand
- DatanodeProtocol
- DatanodeRegistration
- InterDatanodeProtocol
- UpgradeCommand
数据结构
datanode涉及的数据结构包括datanode信息、块、块元数据、datanode命令等,这些结构均实现Writable接口,可进行序列化。
与datanode信息相关的类图如下所示:

DatanodeInfo保存着datanode的详细信息,如名字、ID、端口、容量、已使用空间、剩余空间、DataXceiver的个数、位置、状态等,namenode、balancer和管理工具都会使用到这些信息。
DatanodeRegistration包含标识datanode的所有信息,datanode在启动时,向namenode进行注册,之后在与namenode通信时会发送这些信息验证datanode的身份。
StorageInfo是关于存储的,后继会介绍。
与块相关的类图如下所示:

与块相关的类主要有块、块元数据以及带位置信息的块。
Block保存块的信息,有块ID、块文件大小以及由namenode生成的时间戳,由ID和时间戳唯一确定一个块。
BlockMetaDataInfo保存块元数据的信息,比块多了一个最后扫描时间。
LocatedBlock的主要属性有块信息、该块在文件中的偏移量以及存储该块的datanode节点的信息,主要用在HDFS客户端,它告诉客户端去哪找到块文件。
与datanode命令相关的类图如下所示:

DatanodeCommand是datanode向namenode发送心跳、报告块后会返回的结构,datanode会对收到的命令进行相应的操作,该结构的主要属性是action,是命令对应的操作,这些操作在DatanodeProtocol中定义:
- DNA_UNKNOWN = 0:未知操作
- DNA_TRANSFER = 1:传输块到另一个datanode
- DNA_INVALIDATE = 2:不合法的块
- DNA_SHUTDOWN = 3:停止datanode
- DNA_REGISTER = 4:重新注册
- DNA_FINALIZE = 5:完成前一次更新
- DNA_RECOVERBLOCK = 6:请求块恢复
Register、Finalize、BlockCommand和UpgradeCommand是DatanodeCommand的子类。
BlockCommand额外保存了块和datanode的信息,用于通知datanode错误的块或将指定的块发送到另一个datanode。
UpgradeCommand用于升级HDFS。
接口
这部分主要分析通信过程中需要遵守的一些协议,主要是几个接口,如下类图所示:

VersionedProtocol是所有使用Hadoop RPC的协议的父类,该接口定义了获得协议版本的方法。
DatanodeProtocol是datanode用来和namenode通信的协议,用于上传当前的负载信息和块报告,namenode只能通过该接口定义的方法的返回值与datanode通信,主要方法有注册、发送心跳、报告块信息、通知已接收到的块、报告错误、报告坏块和获得时间戳等。
InterDatanodeProtocol是一个datanode之间的协议,用于更新时间戳。
ClientDatanodeProtocol是一个client-datanode之间的协议,用于恢复块。
前提
Hadoop版本:hadoop-0.20.2
概述
datanode的存储结构如下所示:
${dfs.data.dir}/current/VERSION
/blk_<id_1>
/blk_<id_1>.meta
/blk_<id_1>
/blk_<id_1>.meta
/...
/blk_<id_64>
/blk_<id_64>.meta
/subdir0/
/subdir1/
/...
/subdir63/
/previous/
/detach/
/tmp/
/in_use.lock
/storage
datanode的存储大体上可以分为两部分:与Storage相关的类从宏观上刻画了每个存储目录的组织结构,管理由HDFS属性dfs.data.dir指定的目录,如current、previous、detach、tmp、storage等目录和文件,并定义了对整个存储的相关操作;与Dataset相关的类描述了块文件及其元数据文件的组织方式,如current目录中的文件组织结构,以及对块文件的相关操作。因为namenode也会用到Storage,而namenode并不存储块文件,因而将存储分成这两部分。
本文中将简单分析这两部分内容,所涉及到的类的包结构如下所示:
- org.apache.hadoop.hdfs.protocol
- org.apache.hadoop.hdfs.server.common
- org.apache.hadoop.hdfs.server.datanode
- DataStorage
- FSDataset
- FSDatasetInterface
- DatanodeBlockInfo
Storage
与Storage相关的类描述了存储的信息、类型、状态、目录,类图如下所示:

存储的信息由类StorageInfo来表示,该类有3个属性:
- layoutVersion: 从storage文件中读出,是HDFS文件结构布局
- namespaceID: 存储的namespace id
- cTime: 创建的时间戳
Storage类管理着所有的存储目录,存储目录由StorageDirectory类来表示,通过DirIterator这个类来遍历存储目录,主要有两个属性:
- storageType: 存储类型,可以是NAME_NODE或DATA_NODE
- storageDirs: 存储目录
StorageDirectory是一个重要的类,描述了存储目录的组织结构及其状态,首先,我们来看看存储目录的状态。
StorageState表示存储的状态,与存储目录的结构、升级、回滚、做checkpoint息息相关,存储目录的所有状态如下:
- NON_EXISTENT: 目录不存在
- NOT_FORMATTED: 目录未格式化
- COMPLETE_UPGRADE: 升级完成
- RECOVER_UPGRADE: 撤销升级
- COMPLETE_FINALIZE: 提交完成
- COMPLETE_ROLLBACK: 回滚完成
- RECOVER_ROLLBACK: 撤销回滚
- COMPLETE_CHECKPOINT: checkpoint完成
- RECOVER_CHECKPOINT: 撤销checkpoint
- NORMAL: 正常
存储目录的结构如下所示:
- current:保存当前版本的文件
- current/VERSION:包含正在运行的HDFS的版本信息
- previous:升级后,保存前一版本的文件
- previous/VERSION:前一版本的HDFS的版本信息
- previous.tmp:升级过程中,保存当前版本的文件
- removed.tmp:回滚过程中,保存当前版本的文件
- finalized.tmp:提交过程中,保存文件
- lastcheckpoint.tmp:用于导入一个checkpoint
- previous.checkpoint:前一个checkpoint
- in_use.lock:对目录加锁
VERSION文件的例子如下所示:
#Tue Mar 13 17:22:19 CST 2012
namespaceID=1845340702
storageID=DS-641781551-*.*.*.*-50010-1330961440921
cTime=0
storageType=DATA_NODE
layoutVersion=-19
StorageDirectory与状态和目录结构相关的方法是doRecover,用于恢复系统状态,根据系统当前的状态,完成的操作如下:
- COMPLETE_UPGRADE: previous.tmp -> previous
- RECOVER_UPGRADE: 删除current,previous.tmp -> current
- COMPLETE_FINALIZE: 删除finalized.tmp
- COMPLETE_ROLLBACK: 删除removed.tmp
- RECOVER_ROLLBACK: removed.tmp -> current
- COMPLETE_CHECKPOINT: 删除previous.checkpoint,lastcheckpoint.tmp -> previous.checkpoint
- RECOVER_CHECKPOINT: 删除current,lastcheckpoint.tmp -> current
StorageDirectory还有一个重要的方法是analyzeStorage,用于在启动namenode或datanode时检查存储目录的一致性,并返回系统当前的状态
DataStorage是与datanode相关的存储类,定义了几种文件的前缀和datanode的几个操作,linkBlocks方法用于创建硬链接,recoverTransitionRead方法用于将系统恢复到正常状态,在有必要时升级系统。
3种文件前缀:
- subdir:子目录前缀
- blk_:块文件前缀
- dncp_:拷贝文件前缀
4种操作:
- format:创建VERSION文件
- doUpgrade:升级系统
- 删除previous
- current -> previous.tmp
- previous.tmp做硬链接到current
- 写VERSION文件
- previous.tmp -> previous
- doRollback:回滚
- current -> removed.tmp
- previous -> current
- 删除removed.tmp
- doFinalize:提交存储目录升级
- previous -> finalized.tmp
- 删除finalized.tmp
Dataset
与块相关的操作由Dataset相关的类处理,存储结构由大到小是卷(FSVolume)、目录(FSDir)和文件(Block和元数据等),类图如下所示:

Block是datanode的基本数据结构,表示一个数据块的信息,每个Block都有1个数据文件和1个元数据文件。与Block相关的类有DatanodeBlockInfo,该类有3个属性:volume是块所属的卷;file是块对应的数据文件;detached表示块是否完成copy-on-write。DatanodeBlockInfo有一个重要方法detachFile用于分离文件,先将指定文件拷贝到临时目录,再将临时文件替换原来的文件,这样使得所有到原文件的硬链接被删除。
FSDir用来表示文件的组织结构,默认情况下,每个目录下最多有64个子目录,最多能存储64个块。在初始化一个目录时,会递归扫描该目录下的目录和文件,从而形成一个树状结构。addBlock方法用来添加块到当前目录,如果当前目录不能容纳更多的块,那么将块添加到一个子目录中,如果没有子目录,则创建子目录。getBlockInfo和getVolumeMap方法用于递归扫描当前目录下所有块的信息。clearPath方法用于删除文件时,更新文件路径中所有目录的信息。
FSVolume用来管理块文件,统计存储目录的使用情况,有如下6个属性:
- dataDir:数据目录,current
- tmpDir:临时目录,tmp
- detachDir:detach,使用于实现块的写时复制
- usage:已使用的空间
- dfsUsage:dfs使用的空间
- reserved:保留的空间
FSVolume在初始化时会恢复detach和tmp目录中的文件,如果detach或tmp不存在,则创建目录。createTmpFile方法用于创建临时文件。createDetachFile方法创建用于copy-on-write的文件。addBlock方法用于在当前卷中添加块。
FSVolumeSet类封装了多个FSVolume,提供获得所有容量、剩余空间、dfs使用空间和块信息的方法。getNextVolume方法采用round-robin策略选择下一个FSVolume,达到负载均衡的效果,将IO负载分到多个磁盘上,提高IO处理能力。
FSDataset类封装了FSVolumeSet,实现FSDatasetInterface接口,向外提供获得DFS使用情况及操作块的方法。
FSDatasetInterface接口应实现的方法如下:
- getMetaDataLength(Block b):获得块元数据文件大小
- getMetaDataInputStream(Block b):获得块元数据文件输入流
- metaFileExists(Block b):检查元数据文件是否存在
- getLength(Block b):获得块数据文件大小
- getStoredBlock(Block b):根据块ID得到块信息
- getBlockInputStream(long blkid):获得块数据文件输入流
- getBlockInputStream(Block b, long seekOffset):获得位于块数据文件特定位置的输入流
- getTmpInputStreams(Block b, long blkoff, long ckoff):获得位于块数据文件特定位置的输入流,块文件还位于临时目录中
- writeToBlock(Block b, boolean isRecovery):创建块文件,并获得文件输出流
- updateBlock(Block oldblock, Block newblock):更新块
- finalizeBlock(Block b):完成块的写操作
- unfinalizeBlock(Block b):关闭块文件的写,删除与块相关的临时文件
- getBlockReport():得到块的报告
- isValidBlock(Block b):检查块是否正常
- invalidate(Block invalidBlks[]):检查多个块是否正常
- checkDataDir():检查存储目录是否正常
- shutdown():关闭FSDataset
- getChannelPosition(Block b, BlockWriteStreams stream):获得在数据输出流中的当前位置
- setChannelPosition(Block b, BlockWriteStreams stream, long dataOffset, long ckOffset):设置在数据输出流中的位置
- validateBlockMetadata(Block b):验证块元数据文件
FSDataset有以下几个主要属性:
- volumes: 卷集合
- ongoingCreates: 当前正在活动的文件
- maxBlocksPerDir: 每个目录能保存的最大块数
- volumeMap: 块的信息
FSDataset在创建输出流或位于特定位置的输入流时,使用RandomAccessFile,这样可以随机寻址,可以得到或设置流的位置。当完成块的写操作时,将块添加到volumeMap,并从ongoingCreates中删除。比较复杂的方法是writeToBlock,其处理过程如下所示:
- 如果块数据文件已经存在并且当前要进行恢复,将块数据文件跟与其硬链接的文件分离,需要对文件进行恢复有两种情况:客户端重新打开连接并重新发送数据包;往块追加数据
- 如果块在ongoingCreates中,将其删去
- 如果不是恢复操作,获得存放块文件的卷,创建临时文件,将块添加到volumeMap中
- 对于恢复操作,如果块临时文件存在,重用临时文件,将块添加到volumeMap中;如果块临时文件不存在,将块数据文件和对应的元数据文件移动到临时目录中,将块添加到volumeMap中
- 将块添加到ongoingCreates中
- 返回块文件输出流
前提
Hadoop版本:hadoop-0.20.2
概述
之前已经对datanode的结构和存储进行了分析,本文将分析datanode的行为,能明确数据在datanode之间如何传输。在datanode中,块数据的接收和发送主要是通过DataXceiver,这部分的网络传输没有采用RPC,而是传输的TCP连接,这部分所涉及到的类的包结构如下所示 :
- org.apache.hadoop.hdfs.server.datanode
- BlockMetadataHeader
- BlockReceiver
- BlockSender
- BlockTransferThrottler
- DataXceiver
- DataXceiverServer
以下是DataXceiver相关的类图:
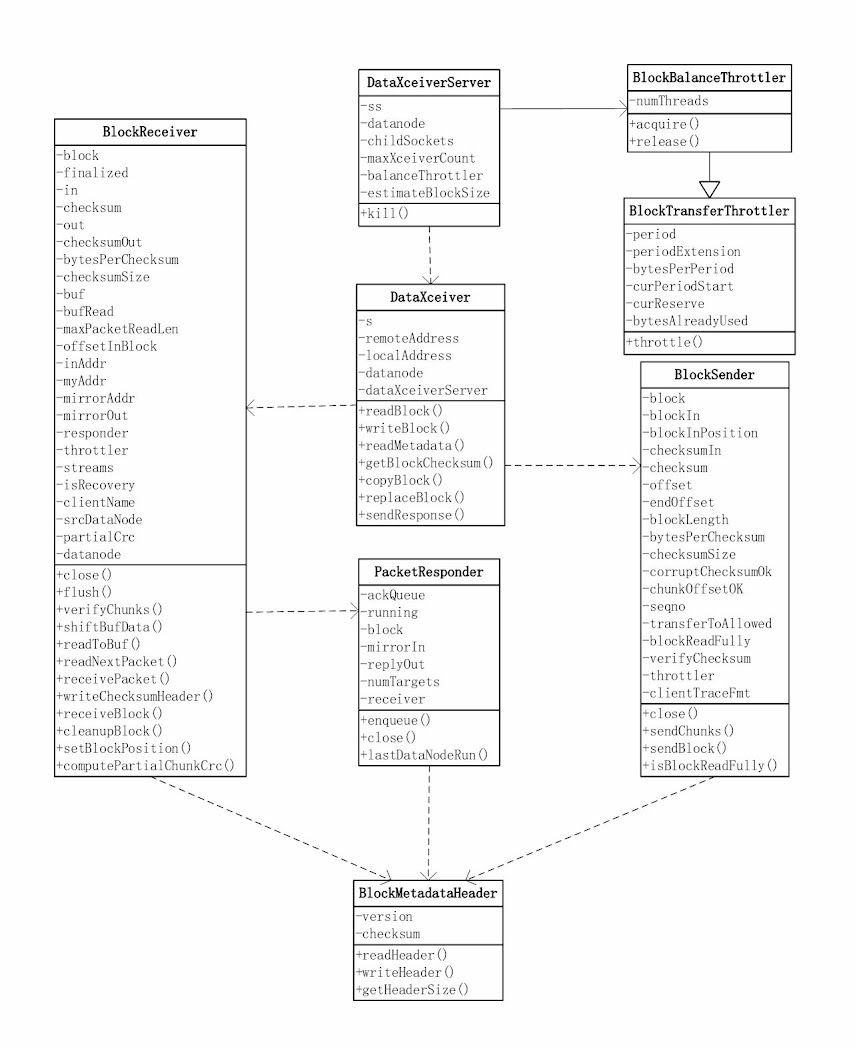
DataXceiver
在datanode上由DataXceiver来负责数据的接收与发送,我们先来看DataXceiverServer和DataXceiver这两个类。
DataXceiverServer相对比较简单,创建一个ServerSocket来接受请求,每接受一个连接,就创建一个DataXceiver用于处理请求,并将Socket存在一个名为childSockets的Map中。此外,还创建一个BlockBalanceThrottler对象用来控制DataXceiver的数目以及流量均衡。
DataXceiver才是真正处理请求的地方,支持六种操作,相关操作在DataTransferProtocol中定义,如下所示:
public static final byte OP_WRITE_BLOCK = (byte) 80;
public static final byte OP_READ_BLOCK = (byte) 81;
public static final byte OP_READ_METADATA = (byte) 82;
public static final byte OP_REPLACE_BLOCK = (byte) 83;
public static final byte OP_COPY_BLOCK = (byte) 84;
public static final byte OP_BLOCK_CHECKSUM = (byte) 85;
操作的状态也在DataTransferProtocol中定义,如下所示:
public static final int OP_STATUS_SUCCESS = 0;
public static final int OP_STATUS_ERROR = 1;
public static final int OP_STATUS_ERROR_CHECKSUM = 2;
public static final int OP_STATUS_ERROR_INVALID = 3;
public static final int OP_STATUS_ERROR_EXISTS = 4;
public static final int OP_STATUS_CHECKSUM_OK = 5;
客户端请求的头部数据是这样的:
+----------------------------------------------+
| 2 bytes version | 1 byte OP |
+----------------------------------------------+
最开始的两个字节是版本信息,接着的1个字节表示上述的操作。
OP_READ_BLOCK是读块数据操作,客户端请求的头部数据如下所示,DataXceiver会创建一个BlockSender对象用来向客户端发送数据。
+-----------------------------------+
| 8 byte Block ID | 8 byte genstamp |
+-----------------------------------+
| 8 byte start offset|8 byte length |
+-----------------------------------+
| 4 byte length | <DFSClient id> |
+-----------------------------------+
其中第二个length是<DFSClient id>的长度。
如果处理过程中出错,那么发送后状态信息后中断连接,返回的数据如下所示:
+----------------------------------------------+
| 2 byte OP_STATUS_ERROR |
+----------------------------------------------+
如果操作成功,返回的数据如下所示:
+----------------------------------------------+
| 2 byte OP_STATUS_SUCCESS | actual data |
+----------------------------------------------+
OP_WRITE_BLOCK是写块数据操作,客户端请求的头部数据如下所示,DataXceiver会创建一个BlockReceiver对象用来接收客户端的数据。
+------------------------------------------------+
| 8 byte Block ID | 8 byte genstamp |
+------------------------------------------------+
| 4 byte num of datanodes in entire pipeline |
+------------------------------------------------+
| 1 byte is recovery | 4 byte length |
+------------------------------------------------+
| <DFSClient id> | 1 byte has src node |
+------------------------------------------------+
| src datanode info | 4 byte num of targets |
+------------------------------------------------+
| target datanodes |
+-----------------------+
写块数据是一个比较复杂的操作,头部信息就不少:其中length是的长度;当有src node时,才有src datanode info数据;datanode信息的格式见HDFS源码分析(2):datanode协议数据结构一节中的相关类图。
HDFS的写操作需要多个datanode来参与,默认是3个,这些datanode形成一个pipeline,如HDFS源码分析(1):datanode概况中client写数据图中所示,这些datanode在这里被称为target datanode,客户端发送的数据会由一个datanode传送到另一个datanode,直到最后一个datanode,对请求的response是从最后一个datanode开始,按数据传送的相反路径逐一传送,每经过一个datanode,该datanode会将收到的及其自已的response发给下一个datanode,当到达客户端时,客户端就能知道所有datanode的response。
OP_READ_METADATA是读块元数据操作,客户端请求的头部数据如下所示:
+------------------------------------------------+
| 8 byte Block ID | 8 byte genstamp |
+------------------------------------------------+
返回的数据如下所示:
+------------------------------------------------+
| 1 byte status | 4 byte length of metadata |
+------------------------------------------------+
| meta data | 0 |
+------------------------------------------------+
OP_REPLACE_BLOCK是替换块数据操作,主要用于负载均衡,DataXceiver会接收一个块并写到磁盘上,操作完成后通知namenode删除源数据块,客户端请求的头部数据如下所示:
+------------------------------------------------+
| 8 byte Block ID | 8 byte genstamp |
+------------------------------------------------+
| 4 byte length | source node id |
+------------------------------------------------+
| source data node |
+-----------------------+
具体的处理过程是这样的:向source datanode发送拷贝块请求,然后接收source datanode的响应,创建一个BlockReceiver用于接收块数据,最后通知namenode已经接收完块数据。返回的数据以下所示:
+----------------------------------------------+
| 2 byte status |
+----------------------------------------------+
OP_COPY_BLOCK是复制块数据操作,主要用于负载均衡,将块数据发送到发起请求的datanode,DataXceiver会创建一个BlockReceiver对象用来发送数据,请求的头部数据如下所示:
+------------------------------------------------+
| 8 byte Block ID | 8 byte genstamp |
+------------------------------------------------+
返回的数据如下所示:
+------------------------------------------------+
| block data | d |
+------------------------------------------------+
OP_BLOCK_CHECKSUM是获得块checksum操作,对块的所有checksum做MD5摘要,客户端请求的头部数据如下所示:
+------------------------------------------------+
| 8 byte Block ID | 8 byte genstamp |
+------------------------------------------------+
返回的数据如下所示:
+------------------------------------------------+
| 2 byte status | 4 byte bytes per CRC |
+------------------------------------------------+
| 8 byte CRC per block| 16 byte md5 digest |
+------------------------------------------------+
前提
Hadoop版本:hadoop-0.20.2
概述
现在已经知道datanode是通过DataXceiver来处理客户端和其它datanode的请求,在分析DataXceiver时已经对除数据块的读与写之外的操作进行了说明,本文主要分析比较复杂而且非常重要的两个操作:读与写。对于用户而言,HDFS用得最多的两个操作就是写和读文件,而且在大部分情况下,是一次写入,多次读取,满足高吞吐量需求而非低延迟,除去客户端与namenode的协商,剩下的部分主要是客户端直接与datanode通信(数据流的头部在上篇文章中已介绍),发送或接收数据,而这些数据在datanode如何接收并写入磁盘、如何从磁盘读出并发送出去就是本文所要介绍的内容。
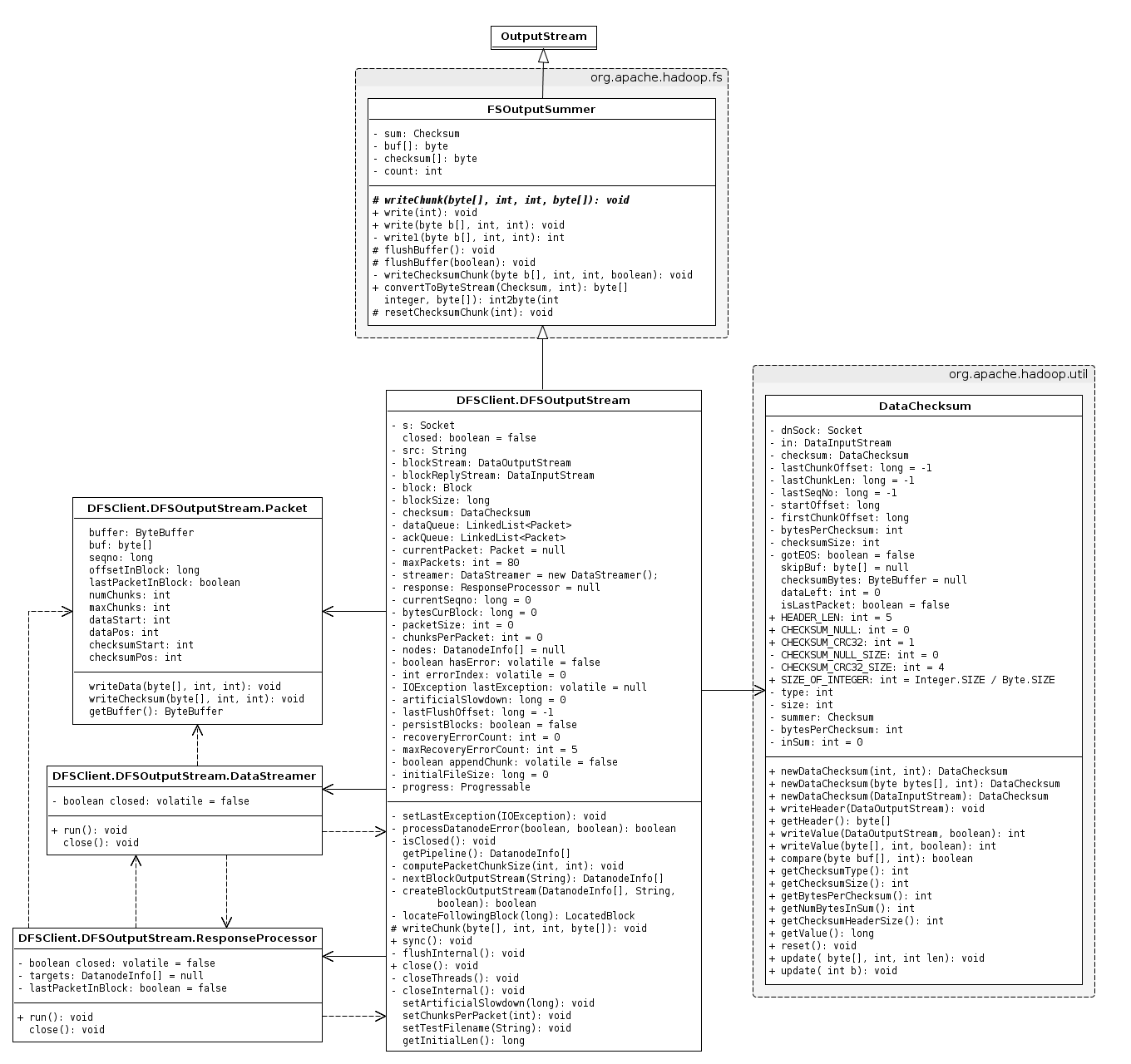
DataChecksum
无论是读数据还是写数据,都会涉及到checksum,我们先来看看DataChecksum的结构,该类位于org.apache.hadoop.util这个包下,有以下几个主要属性:
- type:checksum的类型,有CHECKSUM_NULL和CHECKSUM_CRC32两种
- size:checksum的大小(字节),CHECKSUM_NULL的大小是0,CHECKSUM_CRC32的大小是4
- summer:真正用来做checksum的对象,CHECKSUM_NULL使用的是ChecksumNull这个自定义的不干实事的类,CHECKSUM_CRC32使用的是java提供的CRC32
- bytesPerChecksum:用来做checksum的数据片的大小(字节),即HDFS会把块文件(block)分成多个分片(chunk),对每个分片做checksum,那么读或写数据的最小单位是分片
- inSum:已经做checksum的总字节数
DataChecksum的header有5个字节,其中type占1个字节,bytesPerChecksum占4个字节。
DataChecksum有如下几类方法:
- newDataChecksum:创建一个新的DataChecksum
- writeHeader:将checksum header写到输出流
- getHeader:将checksum header存到一个byte数组中,并返回
- writeValue:将checksum计算结果写到输出流或缓冲区中
- getValue:返回checksum计算结果
- reset:重置checksum
- update:更新checksum
一直在说一个块有数据文件和元数据文件,有了上边对checksum的分析,下面我们来揭开datanode上管理数据块元数据的BlockMetadataHeader的面纱,数据块无数据的最大部分是块的CRC,这部分与namenode与块相关的功能无关。
有两个属性:
- version:元数据版本(2个字节)
- checksum:数据校验和(header占5个字节)
那么元数据文件的header总共有7个字节,元数据文件的结构大概如下所示:
+---------------------------------------------------+
| 2 byte version | 1 byte checksum type |
+---------------------------------------------------+
| 4 byte bytesPerChecksum | 4 byte checksum |
+---------------------------------------------------+
| Sequence of checksums |
+--------------------------+
BlockMetadataHeader提供以下几类方法:
- readHeader:从文件或输入流读取header
- writeHeader:将header写到输出流
- getHeaderSize:得到header的大小,该版本是7
BlockSender
从BlockSender这个名字我们就能够知道它的作用是用于发送块文件,首先,我们来看看其重要的属性:
- block:读取的数据块
- blockIn:本地磁盘的块文件
- blockInPosition:是否使用transferTo()
- checksumIn:本地磁盘的块元数据文件
- checksum:checksum stream
- offset:读取的数据在块中的起始位置
- endOffset:结束位置
- blockLength:块的长度
- bytesPerChecksum:chunk大小
- checksumSize:checksum大小
- corruptChecksumOk:是否需要验证checksum是否损坏
- chunkOffsetOK:是否需要发送chunk的开始位置
- seqno:packet编号
- transferToAllowed:是否允许transferTo
- blockReadFully:如果整个块被读取,设置为true
- verifyChecksum:在读数据时,是否检查checksum
下面,我们来看看其构造方法,其定义如下:
BlockSender(Block block, long startOffset, long length,
boolean corruptChecksumOk, boolean chunkOffsetOK,
boolean verifyChecksum, DataNode datanode, String clientTraceFmt);
参数有很多:
- block:要读取的块
- startOffset:读取数据的开始位置
- length:读取数据的长度
- corruptChecksumOk:是否需要验证checksum是否损坏
- chunkOffsetOK:是否需要发送chunk的开始位置
- verifyChecksum:在读数据时,是否检查checksum
- datanode:当前所在的datanode
- clientTraceFmt:client trace log message的格式
初始化的过程如下:
- 读取元数据,加载checksum
- 计算bytesPerChecksum和checksumSize,
- 检查并调整开始位置和结束位置,使开始位置和结束位置与验证块的边界对齐
- 将checksum数据定位到正确的位置
- 将块数据文件输入流定位到正确的位置
首先,我们来看看sendBlock方法,其定义如下:
long sendBlock(DataOutputStream out, OutputStream baseStream,
BlockTransferThrottler throttler) throws IOException;
其中:
- out:是块数据要写出的流
- baseStream:如果不为null,那么out是该流的包装器,即out封装了baseStream
- throttler:用于控制流量
sendBlock的处理流程是这样的:
- 将数据的header(checksum header,如果需要发送块的开始位置还需要再加一offset)写到out
- 检查是或允许transferTo(verifyChecksum为false,baseStream是SocketOutputStream,blockIn是FileInputStream),这种方式使用FileChannel来传输数据,而不是先将数据读取到缓冲区
- 计算每个packet数据(checksum和数据)的大小
- 将所有packet写到out
- 将一整数(int)0写到out,标记块的结束
到此我们知道发送的块数据如下所示:
+-----------------------------------------------------+
| 1 byte checksum type | 4 byte bytesPerChecksum |
+-----------------------------------------------------+
| 8 byte offset if chunkOffsetOK=true |
+-----------------------------------------------------+
| Sequence of data PACKETs | 4 byte 0 |
+-----------------------------------------------------+
接下来,我们来看看sendChunks的处理流程,sendChunks的功能是发送一个packet,具体发送的chunk数由参数maxChunks指定:
- 计算真实的chunk数numChunks和packet的大小packetLen
- 将packet header(packet大小packetLen、数据在block中的位置offset、packet编号seqno、是否是最后一个packet、真实数据的大小len)写到out
- 读取checksum数据到缓冲区,如果corruptChecksumOk为真,那么在出错时修复数据
- 如果不允许transferTo,读取真实数据到缓冲区,如果verifyChecksum为真,那么检查checksum,最后将checksum和真实数据写到out
- 如果允许transferTo,调用SocketOutputStream的transferToFully方法传输数据
- 做流量控制
由以上分析,我们可知packet的结构如下:
+-----------------------------------------------------+
| 4 byte packet length (excluding packet header) |
+-----------------------------------------------------+
| 8 byte offset in the block | 8 byte sequence number |
+-----------------------------------------------------+
| 1 byte isLastPacketInBlock |
+-----------------------------------------------------+
| 4 byte Length of actual data |
+-----------------------------------------------------+
| x byte checksum data. x is defined below |
+-----------------------------------------------------+
| actual data ...... |
+-----------------------------------------------------+
其中x是根据以下表达式计算出来的:
x = (length of data + BYTE_PER_CHECKSUM - 1)/BYTES_PER_CHECKSUM *
CHECKSUM_SIZE
BlockReceiver
BlockReceiver主要作用是接收块文件,首先,我们来看看其重要的属性:
- block:接收的块
- in:接收数据的流
- out:本地磁盘的块文件
- checksum:计算checksum
- checksumOut:本地磁盘的元数据文件
- bytesPerChecksum:用来做checksum的数据片的大小
- checksumSize:checksum的大小
- buf:存接收的数据,一个完整的packet
- bufRead:接收的合法的数据的大小
- offsetInBlock:接收的数据在块中的位置
- mirrorAddr:pipeline中下一个datanode的地址
- mirrorOut:用于将数据发送到pipeline中下一个datanode
- responder:用于应答的线程
- isRecovery:是否是恢复操作(覆盖或追加)
- inAddr:数据发送方的地址
- myAddr:本地的地址
下面,我们来看看其构造方法,其定义如下:
BlockReceiver(Block block, DataInputStream in, String inAddr,
String myAddr, boolean isRecovery, String clientName,
DatanodeInfo srcDataNode, DataNode datanode) throws IOException {
参数也有不少:
- block:接收的块
- in:接收数据的流
- inAddr:数据发送方的地址
- myAddr:本地的地址
- isRecovery:是否是恢复操作,即原来文件已经存在
- clientName:客户端名字
- srcDataNode:发送数据的datanode
- datanode:本datanode
初始化的过程如下:
- 读取checksum信息
- 打开本地的块文件和元数据文件,并检查块是否正确
- 如果是恢复操作,将块从blockScanner中删除
BlockReceiver这个类比较复杂,有一千行左右代码,我们以客户端写文件为例来说明其处理过程,如下图所示:
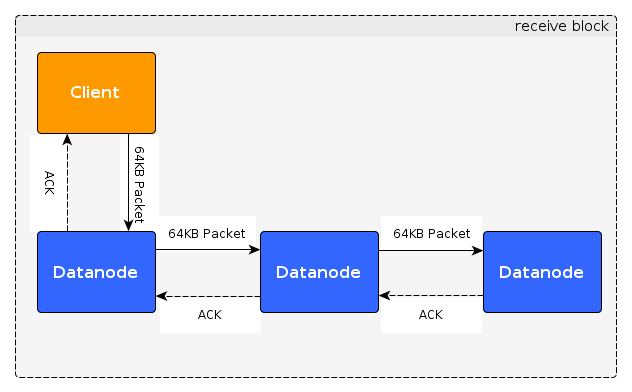
从上图可以看出数据被分成64KB的packet从客户端沿着pipeline逐一发送到所有的datanode,到达最后一个datanode后,应答信息ACK从最后一个datanode沿着pipeline送回客户端,客户端收到ACK就能够知道数据是否发送成功。对于每个datanode,其职责是接收数据包并将数据包发送到其下游datanode,收到ACK后,对ACK进行加工后发送给上游的datanode或client。如果是拷贝块数据操作,是不需要发送应答包的,过程比上图要简单,只需要把数据从一个datanode发送到另一个datanode。
那么,可以将下面的内容分成接收数据和发送应答包两部分,首先,我们来看看接收数据的入口receiveBlock方法:
void receiveBlock(
DataOutputStream mirrOut, // output to next datanode
DataInputStream mirrIn, // input from next datanode
DataOutputStream replyOut, // output to previous datanode
String mirrAddr, BlockTransferThrottler throttlerArg,
int numTargets) throws IOException;
先来分析其参数:
- mirrOut:到下游datanode的输出流,用以发送数据包
- mirrIn:来自下游datanode的输入流,用以接收应答包
- replyOut:到上流datanode的输出流,用以发送应答包
- mirrAddr:下游datanode的地址
- throttlerArg:节流器,用于控制流量
- numTargets:下游datanode的数量,用于确认应答包是否正确
处理的过程如下面的流程图所示:

在这个过程中,需要注意的是setBlockPosition这个方法,如果块文件之前已经finalize了,并且isRecovery为false或者offsetInBlock超过块的大小,那么会抛异常。前边已经讲到每个块文件会被分割成多个chunk,然后对每个chunk做checksum,在这里,如果offsetInBlock不与chunk的边界对齐,那么需要先读出offsetInBlock所位于chunk在offsetInBlock之前数据的checksum,再更新接收到的数据,这样才能确保checksum的正确性。
下面就来看看发送应答包是怎么回事,相关的类有PacketResponder、Packet和PipelineAck,PipelineAck是接口org.apache.hadoop.hdfs.protocol.DataTransferProtocol的内部静态类。先来看看简单的Packet,纯粹就是一个数据结构,有两个属性:
- seqno:packet的编号
- lastPacketInBlock:是否是最后一个包
PipelineAck封装了应答的内容,我们来看看其属性:
- seqno:packet的编号
- replies:一个数组,下游datanode及其自己的答应,数组中每个元素的取值是上一篇文章中操作的状态
- HEART_BEAT:心跳应答对象,seqno为-1,replies中只有一个值OP_STATUS_SUCCESS
一个ACK的内容如下所示:
+-----------------------------------------------------+
| 8 byte seqno | Sequence of 2 byte replies |
+-----------------------------------------------------+
如何判断一个ACK是否是成功呢?很简单,只要replies中有值不为OP_STATUS_SUCCESS,那么就不成功。
好了,只剩下一个PacketResponder了,先看其属性:
- ackQueue:等待应答的packet队列
- running:PacketResponder是否在运行
- block:数据块
- mirrorIn:来自下游datanode的输入流,用以接收应答包
- replyOut:到上流datanode的输出流,用以发送应答包
- numTargets:下游datanode的数量,用于确认应答包是否正确
- receiver:PacketResponder的所有者
PacketResponder的处理有两种不同的方式:numTargets=0,说明这是pipeline的最后一个datanode;有下游datanode。
先来看看最后一个datanode是如何处理每个packet的:
- 如果ackQueue中没有元素,先等待一段时间,如果距上次发送心跳的时间间距超过某阈值,发送心跳给上游的datanode,重复以上操作直到ackQueue不为空
- 如果当前packet是最后一个,finalize数据块,并通知datanode接收完数据块
- 发送ACK给上游的datanode
如果不是最后一个datanode又是如何处理的:
- 接收下游datanode的ACK
- 如果是心跳ACK,直接发送给上游datanode,接着处理下个packet
- 如果非心跳ACK,先检查接收到的ACK的packet编号和当前队列中第一个元素的packet编号是否一致
- 如果当前packet是最后一个,finalize数据块,并通知datanode接收完数据块
- 构造ACK消息,replies的第一个元素是自己的状态,值为OP_STATUS_SUCCESS,如果没有收到下游datanode的ACK,其它元素的值为OP_STATUS_ERROR,否则其它元素的值为接收到的原值
- 将ACK消息发送给上游datanode
- 如果ACK有错,中止PacketResponder的运行
前提
Hadoop版本:hadoop-0.20.2
概述
DataBlockScanner是datanode上很重要的部分,用于周期性地对块文件进行校验,当客户端读取整个块时,也会通知DataBlockScanner校验结果。这个类位于包org.apache.hadoop.hdfs.server.datanode中,与DataBlockScanner相关的类图如下所示:

相关参数
与扫描相关的参数有:
- 最大扫描速度是8 MB/s,通过BlockTransferThrottler来限制流量
- 最小扫描速度是1 MB/s
- 默认扫描周期是3周,扫描周期可通过配置${dfs.datanode.scan.period.hours}来设置
与扫描日志相关的参数有:
- 日志文件名前缀是dncp_block_verification.log
- 共有两个日志:当前日志,文件后缀是.curr;前一个日志,文件后缀是.prev
- minRollingPeriod:日志最小滚动周期是6小时
- minWarnPeriod:日志最小警告周期是6小时,在一个警告周期内只有发出一个警告
- minLineLimit:日志最小行数限制是1000
采用滚动日志方式,只有当前行数curNumLines超过最大行数maxNumLines,并且距离上次滚动日志的时间
超过minRollingPeriod时,才将dncp_block_verification.log.curr重命名为dncp_block_verification.log.prev,将新的日志写到dncp_block_verification.log.curr中。
扫描过程
块的信息用BlockScanInfo来表示,在比较时先对比最后扫描时间,如果扫描时间一样,再比较块的信息,这样,能保证从blockInfoSet中取出的第一个元素的最后扫描时间距离现在最久。
将块添加到扫描集合中时,为其在上个扫描周期中随机选择一个时间作为最后扫描时间,避免所有块在同一时间进行扫描。
扫描的过程如下:
- 检查blockInfoSet中的第一个块的最后扫描时间距离现在是否超过一个扫描周期,如果不超过,休眠1秒后开始下次检查
- 如果超过一个扫描周期,那么对该块进行校验,校验使用BlockSender这个类来读取一个完整的块,读取的数据输出到NullOutputStream这个流,我们知道BlockSender在读取数据时,可以检查checksum,以此来判断是否校验成功。如果校验失败,进行第二次校验,如果两次都失败,说明该块有错误,通知namenode块坏了。
除了DataBlockScanner本身会校验块,DataXceiver在处理读请求时,如果读取整个块的数据,也对块进行校验,并通知DataBlockScanner校验结果。DataXceiver在处理写请求时,将块写入磁盘后,会将块添加到扫描列表中。
前提
Hadoop版本:hadoop-0.20.2
概述
datanode在启动后,会定期向namenode发送心跳报告,并处理namenode返回的命令,经过前面的分析,已经基本弄清楚datanode相关的类,本文将分三部分对剩下的Datanode这个类进行分析,分别是datanode的启动、公共接口和运行。Datanode位于org.apache.hadoop.hdfs.server.datanode这个包,类图如下所示:

datanode的启动
首先,先看看Datanode的静态初始化块:
static{
Configuration.addDefaultResource("hdfs-default.xml");
Configuration.addDefaultResource("hdfs-site.xml");
}
也就是说,datanode在启动时会加载hdfs-default.xml和hdfs-site.xml这两个配置文件,默认的配置文件hdfs-default.xml位于src/hdfs目录,非hadoop-0.20.2可能路径会不相同,最终会跟生成的class文件一起打包进hadoop-core-*.jar,一般与datanode相关的配置放在hdfs-site.xml这个配置文件中。
下面,从入口main方法开始,逐步分析datanode的初始化与启动。
1. main:
- 调用createDataNode方法创建datanode
- 等datanode线程结束
2. createDataNode:
- 调用instantiateDataNode方法初始化datanode
- 调用runDatanodeDaemon方法运行datanode线程
3. instantiateDataNode:
- 解析启动参数
- 如果设置了机架配置${dfs.network.script},退出程序
- 通过配置${dfs.data.dir}得到datanode的存储目录
- 调用makeInstance方法创建实例
4.makeInstance:
- 检查数据存储目录的合法性
- 初始化DataNode对象
5.DataNode:
- 调用startDataNode方法启动datanode
- 如果启动出错,调用shutdown方法关闭datanode
6.startDataNode:
- 获得本地主机名和namenode的地址
- 连接namenode,本地datanode的名称为:“machineName:port”
- 从namenode得到version和id信息
- 初始化存储目录结构,如果有目录没有格式化,对其进行格式化
- 打开datanode监听端口ss,默认端口是50010
- 初始化DataXceiverServer后台线程,使用ss接收请求
- 初始化DataBlockScanner,块的校验只支持FSDataset
- 初始化并启动datanode信息服务器infoServer,默认访问地址是http://0.0.0.0:50075,如果允许https,默认https端口是50475
- infoServer添加DataBlockScanner的Servlet,访问地址是http://0.0.0.0:50075/blockScannerReport
- 初始化并启动ipc服务器,用于RPC调用,默认端口是50020
datanode的接口
getProtocolVersion:
取得datanode的协议版本。
getBlockMetaDataInfo:
取得块元数据信息。
updateBlock:
更新块信息,这个方法会更改块的时间戳,所有会重命令元数据信息文件,如果块文件的长度有变,会改变块文件和元数据信息文件的内容。
recoverBlock:
恢复一个块,先检查块的时间戳,对时间戳比本地块要新的datanode做同步块操作,在同步时,调用namenode的nextGenerationStamp方法来得到一个新的时间戳,对每个datanode通过RPC调用updateBlock方法来更新远程datanode的块,最后调用namenode的commitBlockSynchronization方法来提交块的更新。
datanode的运行
首先会启动DataXceiverServer,然后进入datanode的正常运行:
- 检查是否需要升级
- 调用offerService方法提供服务
来看看offerService这个方法是如何执行的:
- 检查心跳间隔是否超时,如是向namenode发送心跳报告,内容是dfs的容量、剩余的空间和DataXceiverServer的数量等,调用processCommand方法处理namenode返回的命令
- 通知namenode已经接收的块
- 检查块报告间隔是否超时,如是向namenode发送块报告,调用processCommand方法处理namenode返回的命令
- 如果没到下个发送心跳的时候,休眠
接下来看processCommand方法是如何处理命令的,关于这些命令对应的操作,之前的文章中已经提到过,这些操作在DatanodeProtocol中定义:
- DNA_UNKNOWN = 0:未知操作
- DNA_TRANSFER = 1:传输块到另一个datanode,创建DataTransfer来传输每个块,请求的类型是OP_WRITE_BLOCK,使用BlockSender来发送块和元数据文件,不对块进行校验
- DNA_INVALIDATE = 2:不合法的块,将所有块删除
- DNA_SHUTDOWN = 3:停止datanode,停止infoServer、DataXceiverServer、DataBlockScanner和处理线程,将存储目录解锁,DataBlockScanner结束可能需要等待1小时
- DNA_REGISTER = 4:重新注册
- DNA_FINALIZE = 5:完成升级,调用DataStorage的finalizeUpgrade方法完成升级
- DNA_RECOVERBLOCK = 6:请求块恢复,创建线程来恢复块,每个线程服务一个块,对于每个块,调用recoverBlock来恢复块信息
除了以上的操作,还支持UpgradeCommand.UC_ACTION_START_UPGRADE这个操作,主要用于HDFS的升级。
datanode的相关配置
以下是与datanode相关的配置,括号中是配置的默认值:
- slave.host.name
- dfs.block.size (67108864 B):块的大小
- dfs.blockreport.intervalMsec (3600000 ms):发送块报告的时间间隔
- dfs.blockreport.initialDelay (0):启动datanode后首次发送块报告的时间
- dfs.heartbeat.interval (3 s):发送心跳报告的时间间隔
- dfs.support.append (true):是否支持块文件的追加操作
- dfs.network.script:机架配置,datanode不允许对rack进行配置
- dfs.socket.timeout (1 min)
- dfs.write.packet.size (64*1024 B):datanode写或读数据的packet大小
- dfs.datanode.startup:启动选项
- dfs.data.dir (${hadoop.tmp.dir}/dfs/data):datanode存储目录
- dfs.datanode.dns.interface(default)
- dfs.datanode.dns.nameserver (default)
- dfs.datanode.socket.write.timeout (8min)
- dfs.datanode.transferTo.allowed (true)
- dfs.datanode.bindAddress
- dfs.datanode.port
- dfs.datanode.address (0.0.0.0:50010):datanode接受数据请求的地址和端口
- dfs.datanode.info.bindAddress
- dfs.datanode.info.port
- dfs.datanode.http.address (0.0.0.0:50075):datanode信息服务器的地址和端口用于查看dfs使用情况
- dfs.https.enable (false)
- dfs.https.need.client.auth (false)
- dfs.https.server.keystore.resource (ssl-server.xml)
- dfs.datanode.https.address (0.0.0.0:50475)
- dfs.datanode.ipc.address 0.0.0.0:50020:RPC服务的地址和端口
- dfs.datanode.simulateddatastorage
- dfs.datanode.scan.period.hours:扫描块的周期
- dfs.datanode.handler.count (3):处理RPC服务的线程数
- dfs.datanode.max.xcievers (256):DataXceiver的数量
- dfs.datanode.numblocks (64):每个目录能容纳的最多块数以及子目录数
- dfs.datanode.du.reserved (0):dfs的预留空间
前提
Hadoop版本:hadoop-0.20.2
概述
之前已对HDFS的datanode部分的源码进行了分析,还剩client和namenode这个最最重要的部分,本着从简单入手,打算继续把namenode当成是一个黑盒,先分析client的代码,毕竟client的代码行数与namenode相比要少得多。
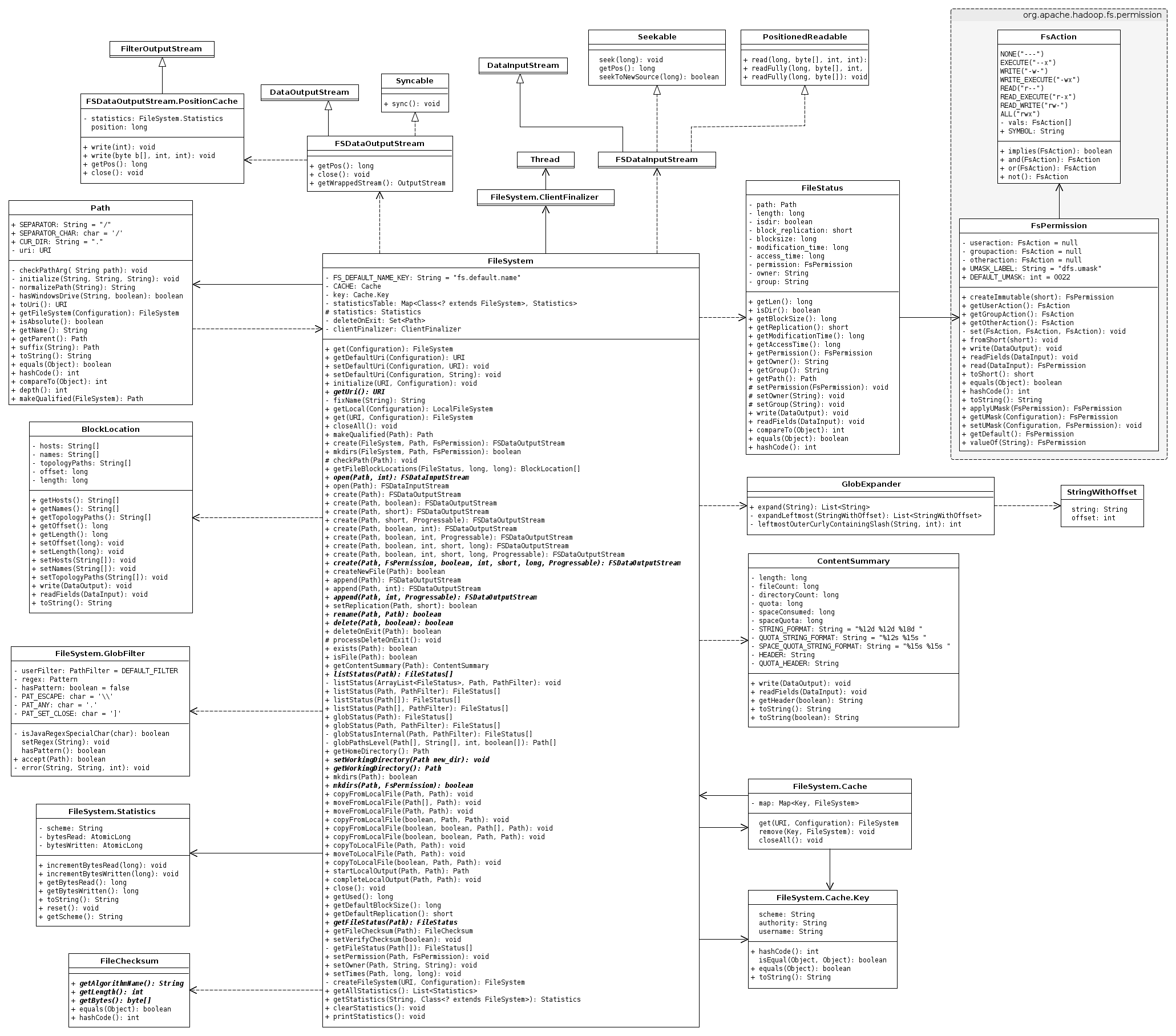
很粗地把client的代码浏览了一下,发现client暴露给用户的接口是DistributedFileSystem这个东东,该类实现了FileSystem这个通用文件系统的抽象类。FileSystem位于core中,并不是HDFS专用的,先对FileSystem进行分析,有助于从宏观上去剖析DFS。
本以为把FileSystem这个类的代码看一遍应该就差不多了,看着看着才发觉FileSystem这个类好庞大、关联依赖的类好多,从下面的类图就可以看出来。虽说类多、方法多,但逻辑相对简单,比较容易理解。

本文所涉及到的类的包结构如下:
- org.apache.hadoop.fs
- BlockLocation
- ContentSummary
- FileChecksum
- FileSystem
- FileStatus
- FSDataInputStream
- FSDataOutputStream
- FSPermission
- GlobExpander
- Path
- PositionedReadable
- Seekable
- Syncable
- org.apache.hadoop.fs.permission
下面将简单介绍几个重要的类。
FileSystem
上文已说过FileSystem是一个通用文件系统的抽象基类,它可能被实现为分布式文件系统或本地文件系统。
先来看其重要成员:
- CACHE: 静态成员,对打开的文件系统实例做cache,在计算机领域里面,cache是非常重要的,做文件系统怎么能少得了它呢!
- statisticsTable: 静态成员,保存各文件系统实例的统计信息
- key: 文件系统实例在CACHE中的键
- statistics: 文件系统实例在读写统计
- deleteOnExit: 退出时需要删除的文件,这个功能很实用,Java里的文件也有这么个功能
- clientFinalizer: 一个线程,用于在退出时关闭所有缓存的文件系统
从其成员,我们可以看到FileSystem有两个功能:缓存和统计。
下面我们来瞧瞧FileSystem的方法,总共有70多个,够吓人的,不过不能被吓倒了,要硬着头皮去看看究竟在做些什么事情,传统的文件系统里都会有的创建目录、创建文件、打开文件、列举目录的文件、重命名文件、关闭文件等功能都覆盖到,除此还有其它一些重要的方法:
- getFileBlockLocations: 取得文件中某个区域的内容所在块(可能会存储在多个块中)的位置
- exists: 检查路径是否存在
- isFile: 检查给定路径是否是一个文件
- getContentSummary: 取得给定路径的统计情况,包括文件总大小、文件数目和目录数目,会递归统计子目录的情况
- listStatus: 如果给定路径是目录,列举该目录的文件和子目录的状态
- globStatus: 返回匹配特定模式的所有文件,跟Linux的命令行很像,可以使用通配来扩展
- getHomeDirectory: 取得用户的主目录
- *etWorkingDirectory: 设置和取得当前工作目录
- copyFromLocalFile: 将文件从本地文件系统拷贝到当前文件系统
- copyToLocalFile: 将文件从当前文件系统拷贝到本地文件系统
- moveFromLocalFile: 将文件从本地文件系统移动到当前文件系统
- moveToLocalFile: 将文件从当前文件系统移到到本地文件系统
- getFileStatus: 取得文件的状态
- setPermission: 设置文件的访问权限,该方法为空
- setOwner: 设置文件所属的用户和组,该方法为空
- setTimes: 设置文件的修改时间和访问时间,该方法为空
- getAllStatistics: 取得所有文件系统的统计情况
- getStatistics: 取得某个特定文件系统的统计情况
细心的读者是否发现漏了两个重要的静态方法:
- get: 根据URI取得一个FileSystem实例,如果允许缓存,会中从缓存中取出,否则将调用createFileSystem创建一个新实例
- createFileSystem: 以URI的scheme为键从配置中得到实现该scheme的类名的值,然后创建一个新的FileSystem实例
在Hadoop生态系统中,可能会经常用到HDFS,也可能会经常见到如下代码:
FileSystem fs = FileSystem.get(URI.create(uri), conf);
上述代码的作用是通过一个uri来取得对应文件系统的实例。
FileSystem.Cache
用于缓存创建的文件系统,实现并不复杂,使用一个HashMap,Map的键类型是Key,值类型是FileSystem。
Key有三个属性:
- scheme: 该属性从URI中取得,比如一个URI“http://server/index.html”,那么scheme就是http
- authority: 该属性也从URI中取得,在上述的例子中,authority就是server,authority包括用户信息、主机以及端口
- username: 当前登陆的用户,具体细节可见org.apache.hadoop.security.UserGroupInformation,这个类我没细看
由此可见,缓冲使用scheme、authority和username来标识文件系统。
FileSystem.Statistics
用于统计文件系统的情况,有三个属性:
- scheme: 标识文件系统,像HDFS文件系统该属性就为hdfs
- bytesRead: 记录目前读取的字节数,类型为AtomicLong,以避免数据不同步问题
- bytesWritten: 记录目前写入的字节数,类型为AtomicLong,以避免数据不同步问题
Path
用于描述文件或目录的路径,路径使用斜线(/)作为目录的分隔符,如果一个路径以斜线开头则是绝对路径。主要是封装了URI,增添一些检查和处理,使该类能正确处理不同文件系统的路径和目录分隔符。
该类方法名比较直接观,处理逻辑也不复杂,这里就不作一一介绍。
BlockLocation
用于保存文件中一个块的信息,这块和HDFS中的Block是一致的。看其属性就能大概知道其用途:
- hosts: datanode的主机名
- names: datanode的名字,样式为“hostname:portNumber”
- topologyPaths: 在网络拓扑中的完整路径名,没看到用它来做啥事
- offset: 该块在文件中的位置
- length: 该块的大小
FileStatus
用于记录文件/目录的信息,记录的内容和Unix、Linux系统很像:
- path: 文件/目录路径
- length: 文件/目录大小
- isdir: 是否是目录
- block_replication: 块的副本数,这个值难道不是整个系统一致?
- blocksize: 块的大小,这个值难道不是整个系统一致?
- modification_time: 文件/目录最后修改时间
- access_time: 文件/目录最后访问时间
- permission: 文件/目录的访问权限,下文会介绍
- owner: 文件/目录的所有者
- group: 文件/目录所属的组
FsPermission
用于控制文件/目录的访问权限,使用POSIX权限方式,控制用户、组、其它的权限,权限有读、写、执行,相信大家都很熟悉。
FSDataOutputStream
在文件系统中用于输出数据的流,继承DataOutputStream,实现Syncable接口,因此,必须支持sync操作。
这个类很简单,当实现一个具体的文件系统时,需要自己定制一个输出流,实现特定的功能,只要继承自FSDataOutputStream,就能符合FileSystem的接口。
在文件系统中用于输入数据的流,继承DataInputStream,实现Seekable和PositionReadable接口,因此,必须支持seek和从某个位置开始读取的操作。
这个类也是很简单,当实现一个具体的文件系统时,需要自己定制一个输入流,实现特定的功能,只要继承自FSDataInputStream,就能符合FileSystem的接口。
后记
文中若有错误或疏漏之处,烦请批评指正。
前提
Hadoop版本:hadoop-0.20.2
概述
在上一篇文章中HDFS源码分析(8):FileSystem已对Hadoop的文件系统接口进行了简单的介绍,相信读者也能猜到HDFS会对外提供什么样的接口。为了让读者对HDFS有个总体的把握,本文将对DistributedFileSystem和DFSClient进行分析,这两个类都位于包org.apache.hadoop.hdfs下。
好了,废话不多说,真奔主题吧。
DistributedFileSystem
DistributedFileSystem是用于DFS系统的抽象文件系统的实现,继承自FileSystem,用户在使用HDFS时,所使用的文件系统就是该实现。但是DistributedFileSystem的实现并不复杂,没有过多的逻辑,大部分方法会间接调用DFSClient的方法,使DFSClient能兼容Hadoop的FileSystem接口,从而能在Hadoop系统中工作,这不就是设计模式中的Adapter(适配器)模式吗?
我们先来看看与DistributedFileSystem相关的类图,由于涉及到的类繁多,因此只列出关键类的属性和方法,其它的类只有类名:
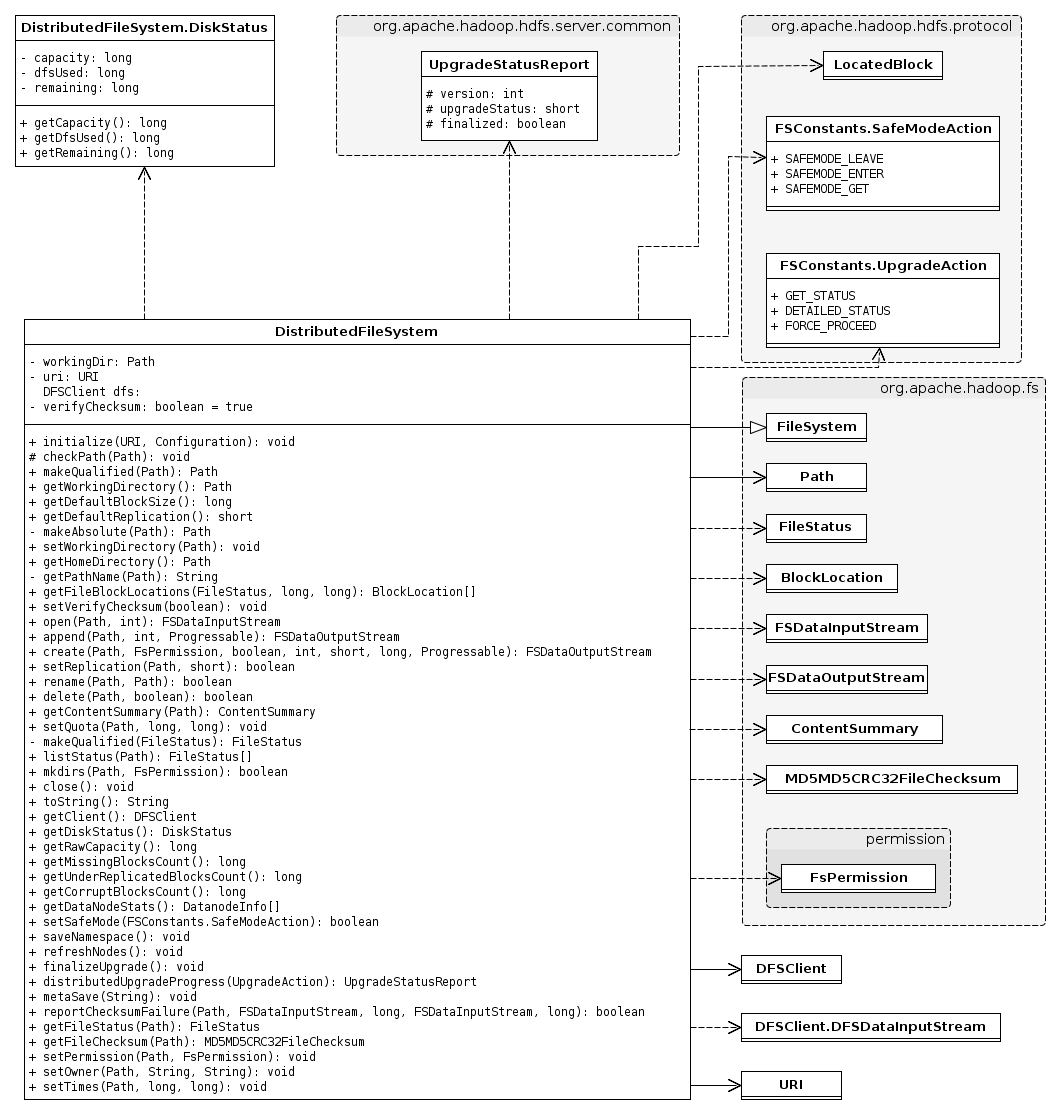
从上图可以看出依赖或关联的类基本是HDFS中通用的类和org.apache.hadoop.fs包下的与文件系统相关的类,DistributedFileSystem的大部分方法会调用DFSClien对应的方法,待下方分析DFSClient时再进行介绍。
先来看看类的初始,在静态初始化块中加载了hdfs-default.xml和hdfs-site.xml配置文件,其中包含了namenode的信息以及一些与HDFS相关的参数;在初始化对象时,从uri中得到namenode地址,设置默认工作目录为用户目录。
有三个方法频繁被其它方法调用:
- checkPath,检查路径的scheme、port和authority,允许显式指定默认端口的路径;
- makeQualified,归一化显式指定默认端口的路径;
- getPathName,检查路径的合法性,并将相对路径转换成绝对路径。
DFSClient
DFSClient是一个真正实现了客户端功能的类,它能够连接到一个Hadoop文件系统并执行基本的文件任务。它使用ClientProtocol来和NameNode通信,并且使用Socket直接连接到DataNode来完成块数据的读/写。Hadoop 用户应该得到一个DistributedFileSystem实例,该实现使用了DFSClient来处理文件系统任务,而不是直接使用DFSClient。
我们先来看看与DFSClient相关的类图,由于涉及到的类繁多,因此只列出关键类的属性和方法,其它的类只有类名:
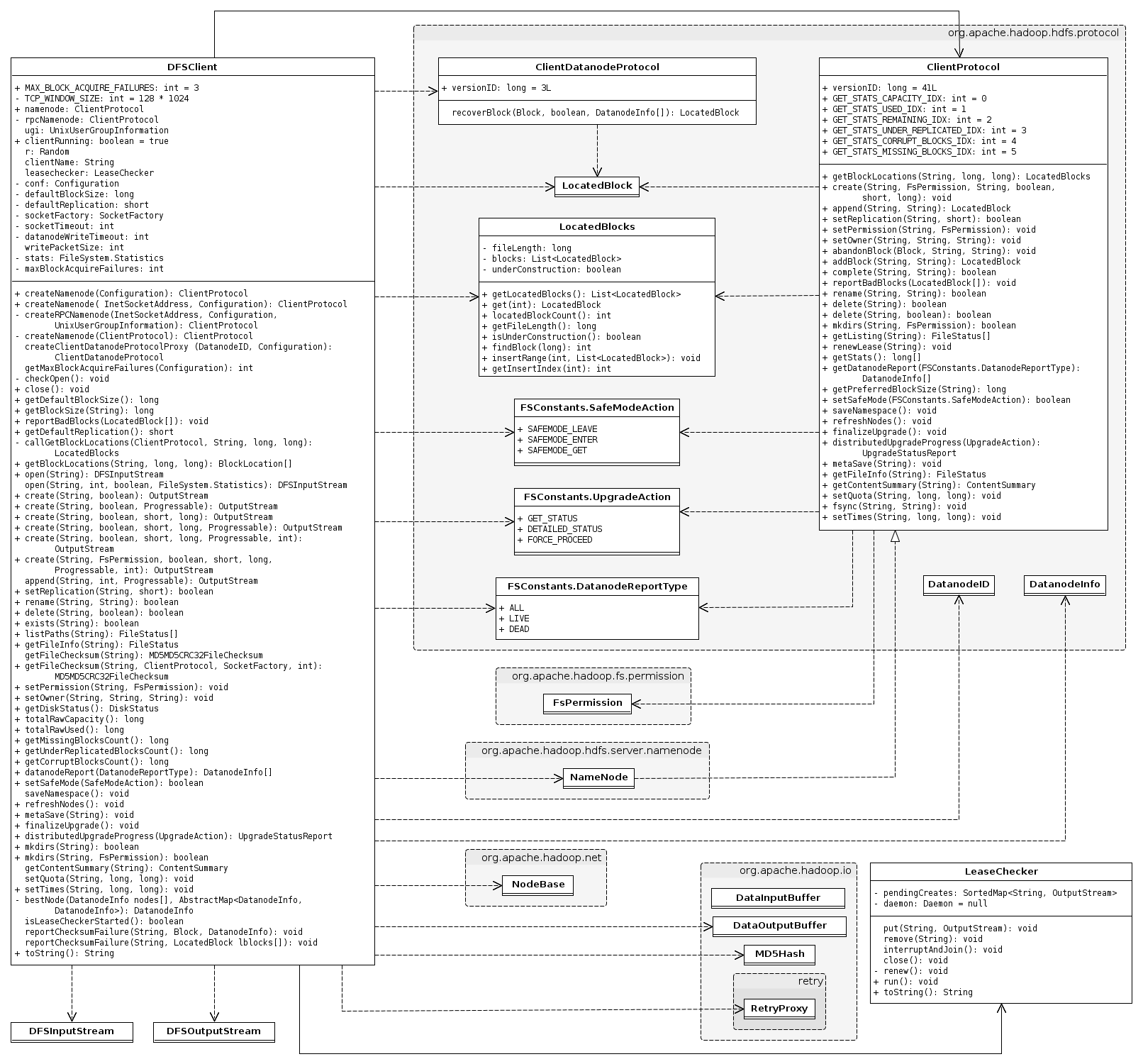
看着上图这么多类,一下子就没有头绪,先来看看DFSClient一些重要的属性:
- MAX_BLOCK_ACQUIRE_FAILURES:块最大请求失败次数,值为3
- TCP_WINDOW_SIZE:TCP窗口的大小,值为128KB,在seek操作中会用到,假如目标位置在当前块内及在当前位置之后,并且与当前位置的距离不超过TCP_WINDOW_SIZE,那么这些数据很可能在TCP缓冲区中,只需要通过读取操作来跳过这些数据
- rpcNamenode:通过建立一个RPC代理来和namenode通信
- namenode:在rcpNamenode基础上封装了一个Retry代理,添加了一些RetryPolicy
- leasechecker:租约管理,用于管理正被写入的文件输出流
- defaultBlockSize:块大小,默认是64MB
- defaultReplication:副本数,默认是3
- socketTimeout:socket超时时间,默认是60秒
- datanodeWriteTimeout:datanode写超时时间,默认是480秒
- writePacketSize:写数据时,一个packet的大小,默认是64KB
- maxBlockAcquireFailures:块最大请求失败次数,默认是3,主要用于向datanode请求块时,失败了可以重试
DSClient的属性主要是在初始化对象时设置,其中涉及到几个参数,如下所示:
- dfs.socket.timeout:读超时
- dfs.datanode.socket.write.timeout:写超时
- dfs.write.packet.size:一个的packet大小
- dfs.client.max.block.acquire.failures:块最大请求失败次数
- mapred.task.id:map reduce的ID,如果不为空,clientName设置为“DFSClient_”,否则clientName设置为“DFSClient_”
- dfs.block.size:块大小
- dfs.replication:副本数
接下来,可以来看看DFSClient的方法,笔者发现很多方法是通过RPC调namenode的方法,这些方法不需赘述了,相信读者都能看出要实现什么操作,下面着重说一下部分方法:
- checkOpen:这个方法被频繁调用,但过程很简单,只是检查一下clientRunning的值
- getBlockLocations:由于从namenode得到的所有块以LocatedBlocks来描述,那么需要从LocatedBlocks从提取出每个块及拥有该块的datanode信息,并以BlockLocation来描述每个块,最后返回的是BlockLocation数组
- getFileChecksum:得到文件的checksum,过程稍微复杂了一点
- 得到文件所有块的位置
- 对于每个块,向datanode请求checksum信息,返回的信息中包括块的所有checksum的MD5摘要,如果向一个datanode请求失败,会向另一datanode请求
- 将所有块的MD5合并,并计算这些内容的MD5摘要
- bestNode:挑选一个不在deadNodes中的节点
HftpFileSystem
HftpFileSystem是一种用于通过HTTP方式访问文件系统的协议实现,该实现提供了一个有限的、只读的文件系统接口。
实现时,HftpFileSystem通过打开一个到namenode的HTTP连接来读取数据和元信息,主要支持三种操作:
- open:向namenode发出http请求,地址是/data/path/to/file,并带有查询串,形式如query1=val1&query2=val2,相信了解http协议的GET方法肯定不觉得陌生
- listStatus和getFileStatus:都是向namenode发出http请求,地址是/listPaths/path/to/file
- getFileChecksum:向namdenode发现http请求,地址是/fileChecksum/path/to/file
HftpFileSystem的工作目录是根目录,不能设置根目录,不支持append、create、rename、delete、mkdirs等操作。
还有一个HsftpFileSystem类,继承自HftpFileSystem,通过https与namenode连接,需要建立ssl。
类图如下:

后记
关于文件的输入流和输出流,敬请关注下一篇文章。
前提
Hadoop版本:hadoop-0.20.2
概述
在上一篇文章中HDFS源码分析(9):DFSClient初步介绍了HDFS客户端的相关内容,但由于篇幅关系,没有对HDFS的输入/输出流进行介绍,而这正是本文的重点。数据的读取和写入是客户端最重要的功能,也是最主要的逻辑,本文将分成输入和输出两部分对HDFS的文件流进行分析。主要的类位于org.apache.hadoop.hdfs.DFSClient类中。
DFSInputStream的主要功能是向namenode获取块信息,并且从datanode读取数据,但涉及到的问题也不少:一个文件被分割成多个块,每个块可能存储在不同的datanode;如果一个datanode挂了,要尝试另一个datanode;文件损坏了……因此,我们必须仔细地进行分析,那么,当要在客户端添加或修改功能时才不至于无从下手。
先来看看类图,从总体上把握类之间的关系,由于类比较多,所以略去了不少类,只剩下一些重要的类,因此下面的类图并不完整:

DataChecksum这个类的说明可见HDFS源码分析(5):datanode数据块的读与写。
1. FSInputChecker
FSInputChecker是一个通用的输入流,继承FSInputStream,用于在返回数据给用户之前校验数据checksum。关键的属性有如下这些:
- file:读取的数据所在的文件
- buf:数据缓冲区
- checkum:checksum缓冲区
- pos:数据缓冲区的当前位置
- count:数据缓冲区中数据的长度
- chunkPos:输入流的位置
为了做得更通用,有两个与具体的实现细节相关的抽象方法将由子类去实现:
- readChunk: 从文件中读取一个chunk放到数据缓冲区,并把该chunk的checksum放到checksum缓冲区
- getChunkPosition:得到包含位置pos的chunk的起始位置
剩下的比较重要的操作有read、skip和seek。
read操作有两种方式:一种是一次只读取一个字节,只需要从缓冲区中读出一个字节即可,如果缓冲区空了,就从输入流中读取一批数据到缓冲区;一种是一次读取多个字节,并把数据存到用户缓冲区,会重复调用更底层的读取方法来读取尽可能多的数据。
无论是使用哪种方式的read方法,都会调用readChecksumChunk这个方法。readChecksumChunk方法又会进一步调用readChunk来从输入流中读出chunk和checksum,如果需要,可以对checksum进行验证,如果读数据失败,可以尝试另一副本,重新读取数据。
skip操作会从输入流中跳过和忽略指定数量的字节,在实现上调用了seek操作。
如果seek的位置所在的chunk在当前缓冲区内,那么只要修改当前的位置pos即可;否则需要重新计算chunkPos,并跳过从chunk起始位置到指定位置之间的数据。
2. BlockReader
BlockReader继承FSInputChecker,封装了Client和Datanode之间的连接,知道块的checksum、offset等信息。关键的属性有如下这些:
- in:数据输入流
- checksum:
- lastChunkOffset:最后一个读取的chunk的偏移量
- lastChunkLen:最后一个读取的chunk的长度
- lastSeqNo:最后一个packet的编号
- startOffset:欲读取数据在块中的偏移量
- firstChunkOffset:读取的第一个chunk在块中的偏移量
- bytesPerChecksum:chunk的大小
- checksumSize:checksum的大小
- isLastPacket:是否是最后一个packet
BlockReader覆盖了父类的很多方法,但不支持seekToNewSource、seek、getChunkPosition及读取单个字节。
首先,我们来看看如何创建一个新的BlockReader实例,所做的事情其实很简单,只是向datanode请求一个OP_READ_BLOCK操作,如果操作成功,那么创建一个数据输入流并根据返回的数据创建一个DataChecksum实例。
read方法只比FSInputChecker多了一些检查。在读取第一个chunk时,可能需要跳过startOffset之前的一些字节。如果到了块的结尾并且需要验证checksum,要向datanode发送OP_STATUS_CHECKSUM_OK,以确认块未损坏。
skip方法通过读取当前位置到目标位置之间的字节来路过这些数据,而不是调用seek。
好了,只剩下最重要的readChunk方法:
- 如果到达块结尾,将startOffset置为-1,返回-1
- 计算新chunk的偏移量
- 如果前一个包的数据已读取完毕,读取下一个packet的头部及checksum
- 从输入流中读取一个chunk,多缓冲区中读出该chunk的checksum
- 如果当前packet是最后一个并且当前packet的数据已全部读完,将gotEOS置为true,标志着到达块结尾
3. DFSInputStream
经过前面的预热,我们可以正式进入输入流的主题,DFSInputStream从文件中读取数据,在必要时与namenode和不同的datanode协商。关键的属性有如下这些:
- closed:流是否已关闭
- src:文件
- prefetchSize:从namenode预取数据的大小,默认是10个块,可以通过配置项dfs.read.prefetch.size来设置
- blockReader:用于读取块的数据
- verifyChecksum:是否验证数据的checksum
- locatedBlocks:存储块的信息
- currentNode:当前读取数据的datanode
- currentBlock:当前块
- pos:文件偏移量
- blockEnd:当前块末尾在文件中的位置
- failures:失败次数
- deadNodes:已经崩溃的datanode
下面将对重要的方法一一讲解。
getBlockAt方法的功能是获取在特定位置offset的块,首先检查offset所在的块是否在缓存中,如果没有就从namenode取回大小为prefetchSize的数据所在的块,更新pos、blockEnd和currentBlock。
getBlockRange方法的功能是获取从特定位置offset开始,长度为length的数据所在块的列表,如果块本地没有缓存,就从namenode取回这些数据所在的块,并与本地已有的块合并。
blockSeekTo方法的功能是获得包含位置target所在的块的datanode,按以下步骤处理:
- 关闭blockReader
- 关闭与当前datanode的连接
- 计算target所在的块
- 选择包含块的一个datanode,并进行连接,如果连接失败,将datanode加入deadNodes,重试其它的datanode
- 创建新的BlockReader
readBuffer方法的功能是读取数据到用户缓冲区,调用BlockReader来读取数据,如果读取失败会重试。
read(byte buf[], int off, int len)方法是为用户提供的读取数据接口,如果读完一个块,会找开下一个块继续读取,调用readBuffer来读数据到缓冲区。
chooseDataNode方法的功能是为块选择一个datanode,如果没能找到,清空deadNodes,重新从namenode获取块列表。
fetchBlockByteRange方法的功能是读取一个块从start到end之间的数据,调用BlockReader来读取。
read(long position, byte[] buffer, int offset, int length)方法是读取从文件的position位置开始,长度为length的数据。
seek方法是作用是定位到任意的位置,只有当目标位置在当前块中,并且与当前位置的距离不超过TCP窗口大小才调用BlockReader的skip方法,跳过部分字节,否则只修改相应的属性值。
seekToBlockSource和seekToNewSource方法都调用blockSeekTo来定位到目标位置,可以重新选择datanode。
4. DFSDataInputStream
这个类比较简单,只是封装了DFSDataInputStream的几个方法。
DFSOutputStream
DFSOutputStream的主要功能是通过namenode获取块的信息,并将用户写的数据发送到datanode。客户端写的数据将被缓存在流中,数据被分割成一个个packet,每个packet默认大小为64KB。每个packet由trunk组成,每个trunk通常是512B,并且带有相关的checksum。当客户端填满当前的packet,这个packet会被放到dataQueue中排队。DataStreamer线程会从dataQueue中挑选packet,将其发送给一个datanode,并将其从dataQuque转移到ackQueue。ResponseProcessor接收datanode的ack,当接收到所有datanode对一个packet成功的ack,ResponseProcessor从ackQueue中删除相应的packet。在出错时,从ackQueue中删除packet,通过从原来的pipeline删除坏的datanode来建立新的pipeline。
先来看看类图,从总体上把握类之间的关系,由于类比较多,所以略去了不少类,只剩下一些重要的类,因此下面的类图并不完整:
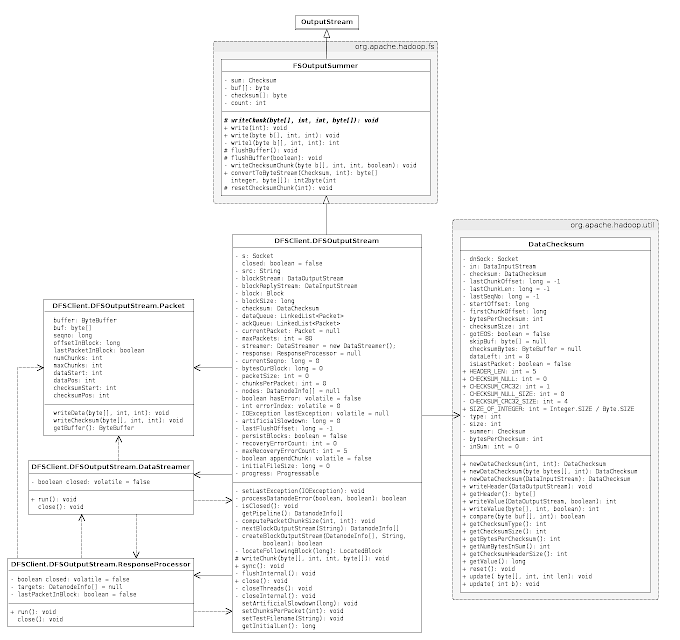
1. Packet
DFSOutputStream是以packet为单位发送数据,每个packet默认大小为64KB,关键的属性有如下这些:
- buffer:ByteBuffer缓冲区
- buf:byte数组缓冲区,只有一个buffer或buf不为空
- seqno:packet在块中的编号
- offsetInBlock:在块中的偏移量
- lastPacketInBlock:是否是块的最后一个packet
- numChunks:当前块中的chunk数
- maxChunks:packet中最大的chunk数
- dataStart:数据在缓冲区中的开始位置
- dataPos:数据在缓冲区中的写入位置
- checksumStart:checksum在缓冲区中的开始位置
- checksumPos:checksum在缓冲区中的写入位置
Packet有三个方法:
- writeData:将数据写入到缓冲区中
- writeChecksum:将checksum写入到缓冲区中
- getBuffer:将数据从buf拷贝到buffer
2. DataStreamer
DataStreamer负责发送数据包(packet)到pipeline上的datanode,它从namenode取回块的id和位置,并将packet发送给datanode。当所有的packet发送完毕,并收到每个块的ack,DataStreamer关闭当前块。 DataStreamer是一个线程,我们来看看它的处理过程是怎样的:
- 如果DataStreamer关闭了或客户端没在运行,停止处理过程
- 如果检查到错误,关闭response
- 从dataQueue取出一个packet
- 从namenode得到新的块
- 将packet放入ackQueue
- 将数据写入datanode
- 如果当前packet是块的最后一个,写入整数0,标志着块的结束
- 如果当前packet是块的最后一个,等待ackQueue的所有packet处理完,然后将response、blockStream和blockReplyStream关闭
3. ResponseProcessor
ResponseProcessor负责处理datanode返回的应答,当一个packet的应答到达时,该packet从ackQueue中删除。关键的属性有如下这些:
- closed:ResponseProcessor是否关闭
- targets:目标datanode,每个packet只有收到targets所表示的所有datanode的ack才算数据发送成功
- lastPacketInBlock:是否是块的最后一个packet
下面来看看ResponseProcessor的处理过程:
- 如果DataStreamer关闭了、客户端没在运行或已处理了块的最后一个packet,停止处理过程
- 从pipeline读出ack
- 处理所有datanode的应答状态
4. FSOutputSummer
这是一个通用的输出流,用于在数据被写入下层输出流之前产生checksum。关键的属性有如下这些:
- sum:数据checksum
- buf:存储数据的内部缓冲区
- checksum:存储checksum的内部缓冲区
- count:数据缓冲区中的合法字节数
下面来看看有什么方法。
有一个抽象方法名为writeChunk,顾名思义,这个方法的功能是将一个数据块及其checksum写入到下层的输出流。
write(int b)方法的功能是写入单个字节。
write(byte b[], int off, int len)方法的功能是写入固定长度的字节,与普通write方法不同的地方是该方法会将所有的字节写入而不是返回已写入的字节数。
write1是内部的写入方法,将用户缓冲区的数据拷贝到内部缓冲区,如果内部缓冲区,将数据刷新到输出流。
flushBuffer方法的功能是将数据及其checksum写入到输出流中。
writeChecksumChunk方法的功能是将数据和checksum写入下层的输出流。
5. DFSOutputStream
这个类才是输出部分的重头戏,涵盖客户端向HDFS写文件的大部分逻辑,封装了与namenode和datanode通信的逻辑,关键的属性有如下这些:
- closed:是否关闭
- src:文件名
- blockStream:连接datanode的块输出流
- blockReplyStream:来自datanode的应答输入流
- block:当前块
- blockSize:块大小
- checksum:校验和
- dataQueue:数据队列,等待发送的所有packet
- ackQueue:应答队列,已发送,等待应答的所有packet
- currentPacket:当前的packet
- maxPackets:最大packet数
- streamer:用于发送packet到datanode
- response:用于处理datanode发送的应答
- currentSeqno:当前packet的编号
- bytesCurBlock:当前块已写入的字节数
- packetSize:packet的大小(包括header)
- chunksPerPacket:每个packet的chunk数
- nodes:存放当前块的所有datanode
- hasError:是否出错
- errorIndex:出错的datanode索引
- lastException:上一个异常
- lastFlushOffset:上次flush的位置
- persistBlocks:是否向namenode持久化块
- recoveryErrorCount:恢复错误的次数
- maxRecoveryErrorCount:最大恢复错误次数
- appendChunk:是否追求数据到部分块
- initialFileSize:文件打开时的大小
下面来看看一些方法。
processDatanodeError方法用于处理datanode的错误,当调用返回后需要休眠一段时间时,返回true。调用这个方法前,需要确保response已关闭。下面是其简单的处理流程:
- 关闭blockStream和blockReplyStream
- 将packet从ackQueue移到dataQueue
- 删除坏datanode
- 通过RPC调用datanode的recoverBlock方法来恢复块,如果有错,返回true
- 如果没有可用的datanode,关闭DFSOutputStream和streamer,返回false
- 创建块输出流,如果不成功,转到3
computePacketChunkSize方法根据packet和chunk的实际大小来计算在HDFS中当前块packet的大小和一个packet中chunk的数量。
nextBlockOutputStream方法打开一个写往datanode的输出流,调用locateFollowingBlock请求下一个块,再调用createBlockOutputStream创建块输出流,如果出错可以重试,重试次数可以由配置参数createBlockOutputStream来设置,默认值是3。
createBlockOutputStream方法会与pipeline中的第一个datanode建立连接,为后继写数据做准备:
- 将persistBlocks设为true,以便在下次flush时在namenode上持久化块
- 与datanode建立socket连接
- 向datanode发送OP_WRITE_BLOCK请求
- 接收ack,检查是否有坏的datanode
locateFollowingBlock方法的主要功能定位下一个块,通过向namenode请求为文件添加新的块来实现,如果出现错误可以重试,重试次数可以由配置参数dfs.client.block.write.locateFollowingBlock.retries来设置,默认值是5。
writeChunk方法的主要功能是将一个chunk的数据和checksum写入到输出流中,处理流程以下:
- 如果dataQueue和ackQueue的总大小超过maxPackets,一直等待
- 如果currentPacket为空,创建一个新的packet
- 将数据和checksum写入当前packet
- 如果当前packet的chunk数达到最大chunk数或者当前块的大小等于块的大小,将currentPacket放入dataQueue
- 调用computePacketChunkSize重新计算packetSize和chunksPerPacket的值
sync方法的主要功能是将所有数据写到datanode,并等待收到datanode的ack,如果persistBlocks为true,调用namenode的fsync方法同步文件。
flushInternal方法的主要功能是等待dataQueue的packet都发送完毕,并等待ackQueue中的packet都接收到ack。



























 478
478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









