







作为之前对spark RDD可以说是完全不懂的小白,在阅读部分网友的博客的基础上,我从自己理解的角度和方式来记录一下自己学习spark RDD的过程。
目录
一、RDD介绍
1.1 RDD是什么
RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一个只读的,可分区的弹性分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用。
我们看下官方对rdd特性的介绍:
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
下面对RDD的五个特性进行解释:
- 有一个分片列表。就是能被切分,和hadoop一样的,能够切分的数据才能并行计算。
- 每一个切片(分区)使用同一个函数计算。
- 对其他的RDD的依赖列表, 即RDD具有血统。依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。
- 可选:key-value型的RDD是根据哈希来分区的,类似于mapreduce当中的Paritioner接口,控制key分到哪个reduce。
- 可选:每一个分片的优先计算位置(preferred locations),对于每一个切片(分区)都会偏向于选择就近的进行计算。
看一下这5个特性的函数原型:
//特性1
protected def getPartitions: Array[Partition]
//特性2 对一个分片进行计算,得出一个可遍历的结果
def compute(split: Partition, context: TaskContext): Iterator[T]
//特性3 只计算一次,计算RDD对父RDD的依赖
protected def getDependencies: Seq[Dependency[_]] = deps
//特性4 可选的,分区的方法
@transient val partitioner: Option[Partitioner] = None
//特性5 可选的,指定优先位置,输入参数是split分片,输出结果是一组优先的节点位置
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
1.2 Spark与RDD的关系
(1)为什么会有Spark?因为传统的并行计算模型无法有效的解决迭代计算(iterative)和交互式计算(interactive);而Spark的使命便是解决这两个问题,这也是他存在的价值和理由。
(2)Spark如何解决迭代计算?其主要实现思想就是RDD,把所有计算的数据保存在分布式的内存中。迭代计算通常情况下都是对同一个数据集做反复的迭代计算,数据在内存中将大大提升IO操作。这也是Spark涉及的核心:内存计算。
(3)Spark如何实现交互式计算?因为Spark是用scala语言实现的,Spark和scala能够紧密的集成,所以Spark可以完美的运用scala的解释器,使得其中的scala可以向操作本地集合对象一样轻松操作分布式数据集。
(4)Spark和RDD的关系?可以理解为:RDD是一种具有容错性基于内存的集群计算抽象方法,Spark则是这个抽象方法的实现
1.3 为什么会产生RDD
(1)传统的MapReduce虽然具有自动容错、平衡负载和可拓展性的优点,但是其最大缺点是采用非循环式的数据流模型,使得在迭代计算式要进行大量的磁盘IO操作。RDD正是解决这一缺点的抽象方法
(2)RDD是Spark提供的最重要的抽象的概念,它是一种有容错机制的特殊集合,可以分布在集群的节点上,以函数式编程操作集合的方式,进行各种并行操作。它提供了一种只读、只能由已存在的RDD变换而来的共享内存,然后将所有数据都加载到内存中,方便进行多次重用。
a.它是分布式的,可以分布在多台机器上,进行计算。
b.它是弹性的,计算过程中内存不够时它会和磁盘进行数据交换(缓存管理)。
c.这些限制可以极大的降低自动容错开销
d.实质是一种更为通用的迭代并行计算框架,用户可以显示地控制计算的中间结果,然后将其自由运用于之后的计算。
1.4 RDD底层实现原理
RDD是一个分布式数据集,顾名思义,其数据应该分部存储于多台机器上。事实上,每个RDD的数据都以Block的形式存储于多台机器上,下图是Spark的RDD存储架构图,其中每个Executor会启动一个BlockManagerSlave,并管理一部分Block;而Block的元数据由Driver节点的BlockManagerMaster保存。BlockManagerSlave生成Block后向BlockManagerMaster注册该Block,BlockManagerMaster管理RDD与Block的关系,当RDD不再需要存储的时候,将向BlockManagerSlave发送指令删除相应的Block。

1.5 RDD的操作
a.Actions:对数据集计算后返回一个数值value给驱动程序;例如:Reduce将数据集的所有元素用某个函数聚合后,将最终结果返回给程序。
b.Transformation:根据数据集创建一个新的数据集,计算后返回一个新RDD;例如:Map将数据的每个元素经过某个函数计算后,返回一个新的分布式数据集。
RDD支持两种操作:转换(transformation)和动作(actions)。
转换(transformation):根据数据集创建一个新的数据集,计算后返回一个新RDD;而动作(actions)在数据集上运行计算后,返回一个值给驱动程序。 例如,map就是一种转换,它将数据集每一个元素都传递给函数,并返回一个新的分布数据集表示结果。另一方面,reduce是一种动作,通过一些函数将所有的元素叠加起来,并将最终结果返回给Driver程序。
Spark中的所有转换都是惰性的,也就是说,它们并不会直接计算结果。相反的,它们只是记住应用到基础数据集(上的这些转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这个设计让Spark更加有效率的运行。例如,我们可以实现:通过map创建的一个新数据集,并在reduce中使用,最终只返回reduce的结果给driver,而不是整个大的新数据集。
默认情况下,每一个转换过的RDD都会在执行一个动作时被重新计算。不过,可以使用persist(或者cache)方法,持久化一个RDD在内存中。在这种情况下,Spark将会在集群中,保存相关元素,下次查询这个RDD时,它将能更快速访问。在磁盘上持久化数据集,或在集群间复制数据集也是支持的。
二、通过例子学习spark RDD的操作
在这里我介绍下常见的Action和Transformations函数的操作。
在spark新版中,也许会有更多的action和transformation,可以参照spark的主页 。详见参考文献【1】。
2.1 Action函数
Action函数会产生任务,并会把任务提交到spark集群中。
注意:这些函数一般的返回值都是Unit。
主要包括以下Action函数:
foreach、foreachPartition、collect、subtract、reduce、treeReduce、fold、aggregate、aggregateByKey、count、countByValue、take、first、takeOrdered、top、max、isEmpty、saveAsTextFile、keyBy、keys
foreach
功能说明
在RDD的所有元素使用函数。
函数原型
def foreach(f: T => Unit): Unit 使用例子
注意:若spark是集群模型,会看不到foreach的输出。
scala> val r1 = sc.parallelize(Array("a", "b", "c", "d"))
r1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[19] at parallelize at <console>:24
scala> r1.foreach(item => println("hello " + item))
若是在单机的spark上,可以看到以下效果:
scala> val r1 = sc.parallelize(Array("a", "b", "c", "d"))
r1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> r1.foreach(item => println("hello " + item))
[Stage 0:> (0 + 0) / 2]hello a
hello b
hello c
hello d
foreachPartition
功能说明
在RDD的每个分区上使用同一个处理函数。
函数原型
def foreachPartition(f: Iterator[T] => Unit): Unit使用例子
查看每个分区的数据量大小。
scala> val r1 = sc.parallelize(Array("a", "b", "c", "d", "e", "f", "g", "h", "i"), 3)
r1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> r1.foreachPartition(c=>println(c.length))
3
3
3
collect
功能说明
把RDD的所有元素都返回到本地的数组中。
该函数可以用于打印RDD的内容,在调试的时候非常有用。但注意:若数据量太大,可能导致OOM。
函数原型
def collect(): Array[T]
def collect[U: ClassTag](f: PartialFunction[T, U]): RDD[U]使用例子
scala> val r1 = sc.parallelize(Array("a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k"), 3)
r1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[4] at parallelize at <console>:24
scala> r1.foreachPartition(c=>println(c.length))
3
4
4
scala> r1.collect()
res23: Array[String] = Array(a, b, c, d, e, f, g, h, i, j, k)
subtract
功能说明
执行标准的集合相减操作:A-B。 不去重。
注意:在使用该函数时,要保证两个RDD的元素类型是相同的。
函数原型
def subtract(other: RDD[T]): RDD[T]
def subtract(other: RDD[T], numPartitions: Int): RDD[T]
def subtract(other: RDD[T], p: Partitioner): RDD[T]
使用例子
scala> val r1 = sc.parallelize(1 to 10, 3)
r1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[23] at parallelize at <console>:24
scala> val r2 = sc.parallelize(5 to 15, 3)
r2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[24] at parallelize at <console>:24
scala> val r3 = r1.subtract(r2)
res21: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[28] at subtract at <console>:29
scala> r2.collect()
res26: Array[Int] = Array(5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15)
scala> r1.collect()
res27: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> r3.collect()
res28: Array[Int] = Array(3, 1, 4, 2)
reduce
功能说明
reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。
函数原型
def reduce(f: (T, T) => T): T 使用例子
val c = sc.parallelize(1 to 10)
c.reduce((x, y) => x + y)//结果55具体过程,RDD有1 2 3 4 5 6 7 8 9 10个元素,
1+2=3
3+3=6
6+4=10
10+5=15
15+6=21
21+7=28
28+8=36
36+9=45
45+10=55
另外的一个例子
scala> val a = sc.parallelize(1 to 100, 3)
a: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[33] at parallelize at <console>:24
scala> a.reduce(_+_)
res29: Int = 5050
// 和map结合使用
scala> a.map(_*2).reduce(_+_)
res30: Int = 10100
treeReduce
功能说明
和reduce函数的功能相似,不同的是该函数通过tree的方式对结果进行聚合。
函数原型
def treeReduce(f: (T, T) ⇒ T, depth: Int = 2): T使用例子
val z = sc.parallelize(List(1,2,3,4,5,6), 2)
z.treeReduce(_+_)
res49: Int = 21fold
功能说明
聚合每个分区的值。每个分区内的聚合变量用zeroValue初始化,然后聚合所有分区的结果。
函数原型
def fold(zeroValue: T)(op: (T, T) => T): T 使用例子
说到fold()函数,就不得不提一下之前介绍过的reduce()函数,它俩的区别就在于一个初始值。我们知道,reduce()函数是这样写的:
rdd.reduce(func)
参数是一个函数,这个函数的对rdd中的所有数据进行某种操作,比如:
val l = List(1,2,3,4)
l.reduce((x, y) => x + y)
对于这个x,它代指的是返回值,而y是对rdd各元素的遍历。意思是对 l中的数据进行累加。flod()函数相比reduce()加了一个初始值参数:
rdd.fold(value)(func)
如下:
val l = List(1,2,3,4)
l.fold(0)((x, y) => x + y)
这个计算其实 0 + 1 + 2 + 3 + 4,而reduce()的计算是:1 + 2 + 3 + 4,没有初始值,或者说rdd的第一个元素值是它的初始值。
如果,我们设置多个分区呢?看下面的例子
scala> val a = sc.parallelize(1 to 100, 3)
a: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[33] at parallelize at <console>:24
scala> a.fold(0)(_+_)
res38: Int = 5050
scala> a.fold(1)(_+_)
res38: Int = 5054
scala> a.fold(2)(_+_)
res38: Int = 5058
可以看到分区为3个时,1+(1+2+....+100)+1+1+1=5054
aggregate
功能说明
aggregate函数允许用户将两种不同的reduce functions应用于RDD。 在每个分区中应用第一个reduce函数,以将每个分区内的数据减少为单个结果。第二个reduce函数用于将所有分区的不同缩减结果组合在一起,以得出最终结果。内部分区与跨分区约减具有两个单独的约减功能的能力增加了很大的灵活性。 例如,第一个reduce函数可以是max函数,第二个可以是sum函数。 用户还指定一个初始值。 但这里要注意:
- 不要为分区计算或组合分区假定任何执行顺序。
- 初始值适用于所有的reduce函数。
函数原型
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U 使用例子
刚才说到reduce()和fold(),这两个函数有一个问题,那就是它们的返回值必须与rdd的数据类型相同。比如上面的例子,l的数据是Int,那么reduce()和flod()返回的也必须是Int。aggregate()函数就打破了这个限制。比如返回(Int, Int)。这很有用,比如要计算平均值的时候。
要算平均值,有两个值是要求的,一个是rdd的各元素的累加和,另一个是元素计数,我初始化为(0, 0)。
那么就是:
val l = List(1,2,3,4)
l.aggregate(0, 0)(seqOp, combOp)
那么seqOp和combOp怎么写呢?
我们将seqOp写为:
(x, y) => (x._1 + y, x._2 + 1)
如何理解呢?在讲到reduce()函数的时候有:
val l = List(1,2,3,4)
l.reduce((x, y) => x + y)
对于这个x,它代指的是返回值,而y是对rdd各元素的遍历。
在aggregate()这也一样,x代表返回值,且这里的返回值是(Int, Int),它有两个元素,可以用x._1和x._2来代指这两个元素的,y代表对rdd的元素遍历,可以用x._1 + y表示各个元素的累加和,x._2 + 1就是元素计数。遍历完成后返回的(Int, Int)就是累加和和元素计数。
按理说有这么一个函数就应该结束了,那么后边那个combOp有什么作用呢?
因为rdd的计算是分布式计算,这个函数是将累加器进行合并的。
例如第一个节点遍历1和2, 返回的是(3, 2),第二个节点遍历3和4, 返回的是(7, 2),那么将它们合并的话就是3 + 7, 2 + 2,用程序写就是
(x, y) => (x._1 + y._1, x._2 + y._2)
最后程序是这样的:
val l = List(1,2,3,4)
r = l.aggregate(0, 0)((x, y) => (x._1 + y, x._2 + 1), (x, y) => (x._1 + y._1, x._2 + y._2))
m = r._1 / r._2.toFloadaggregateByKey
功能说明
aggregate 是聚合意思,直观理解就是按照Key进行聚合。
转化: RDD[(K,V)] ==> RDD[(K,U)]
可以看出是返回值的类型不需要和原来的RDD的Value类型一致。
在聚合过程中提供一个中立的初始值zeroValue。
函数原型
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) 使用例子
先看一个有多个分区的例子:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by Edward on 2016/10/27.
*/
object AggregateByKey {
def main(args: Array[String]) {
val sparkConf: SparkConf = new SparkConf().setAppName("AggregateByKey")
.setMaster("local")
val sc: SparkContext = new SparkContext(sparkConf)
val data = List((1, 3), (1, 2), (1, 4), (2, 3))
var rdd = sc.parallelize(data,2)//数据拆分成两个分区
//合并在不同partition中的值,a,b的数据类型为zeroValue的数据类型
def comb(a: String, b: String): String = {
println("comb: " + a + "\t " + b)
a + b
}
//合并在同一个partition中的值, a的数据类型为zeroValue的数据类型,b的数据类型为原value的数据类型
def seq(a: String, b: Int): String = {
println("seq: " + a + "\t " + b)
a + b
}
rdd.foreach(println)
//zeroValue 中立值,定义返回value的类型,并参与运算
//seqOp 用来在一个partition中合并值的
//comb 用来在不同partition中合并值的
val aggregateByKeyRDD: RDD[(Int, String)] = rdd.aggregateByKey("100")(seq,comb)
//打印输出
aggregateByKeyRDD.foreach(println)
sc.stop()
}
}结果:
//将数据拆分成两个分区
//分区一数据
(1,3)
(1,2)
//分区二数据
(1,4)
(2,3)
//分区一相同key的数据进行合并
seq: 100 3 //(1,3)开始和中立值进行合并 合并结果为 1003
seq: 1003 2 //(1,2)再次合并 结果为 10032
//分区二相同key的数据进行合并
seq: 100 4 //(1,4) 开始和中立值进行合并 1004
seq: 100 3 //(2,3) 开始和中立值进行合并 1003
将两个分区的结果进行合并
//key为2的,只在一个分区存在,不需要合并 (2,1003)
(2,1003)
//key为1的, 在两个分区存在,并且数据类型一致,合并
comb: 10032 1004
(1,100321004)
再看一个例子:
scala> val data = sc.parallelize(List((1,2),(1,4),(2,3)))
scala> data.aggregateByKey(3)((x,y)=>math.max(x,y) ,(z,m)=>z+m)
scala> val result = data.aggregateByKey(3)((x,y)=>math.max(x,y) ,(z,m)=>z+m)
scala> result.collectres2: Array[(Int, Int)] = Array((1,7), (2,3))

count
功能说明
返回RDD中所有元素的个数。
函数原型
def count(): Long 使用例子
scala> val a = sc.parallelize(1 to 100, 3)
a: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at parallelize at <console>:24
scala> a.count()
res30: Long = 100
countByValue
功能说明
返回RDD中每个元素的个数,并按java的Map数据结构的方式返回。
函数原型
def countByValue()(implicit ord: Ordering[T] = null): Map[T, Long]使用例子
scala> val a = sc.parallelize(1 to 10, 3)
a: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at parallelize at <console>:24
scala> a.countByValue
res35: scala.collection.Map[Int,Long] = Map(5 -> 1, 10 -> 1, 1 -> 1, 6 -> 1, 9 -> 1, 2 -> 1, 7 -> 1, 3 -> 1, 8 -> 1, 4 -> 1)
scala> val r1 = sc.parallelize(Array("a", "b", "c", "d", "e", "f", "g", "c", "b", "a", "a"), 3)
r1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> r1.countByValue
res0: scala.collection.Map[String,Long] = Map(e -> 1, f -> 1, a -> 3, b -> 2, g -> 1, c -> 2, d -> 1)
take
功能说明
从RDD中返回n个元素。
该函数先会先扫描一个分区,若分区的元素个数不够,则会扫描另一个分区,直到元素个数足够。
注意:该函数会把所有的数据保存到driver端,所以若take的数据量太大,可能会导致OOM。
函数原型
def take(num: Int): Array[T] 使用例子
scala> val r1 = sc.parallelize(Array("a", "b", "c", "d", "e", "f", "g", "c", "b", "a", "a"), 3)
r1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> r1.take(3)
res4: Array[String] = Array(a, b, c)
first
功能说明
查找RDD的第一个数据项并返回它。
函数原型
def first()使用例子
scala> val r1 = sc.parallelize(Array("a", "b", "c", "d", "e", "f", "g", "c", "b", "a", "a"), 3)
r1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> r1.first
res1: String = a
takeOrdered
功能说明
返回RDD的n个元素,并对这n个元素进行排序。
函数原型
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]使用例子
scala> val r1 = sc.parallelize(Array("a", "b", "c", "d", "e", "f", "g", "c", "b", "a", "a"), 3)
r1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> r1.takeOrdered(3)
res6: Array[String] = Array(a, a, a)
scala> val b = sc.parallelize(List("dog", "cat", "ape", "salmon", "gnu"), 2)
b: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[7] at parallelize at <console>:24
scala> b.takeOrdered(2)
res7: Array[String] = Array(ape, cat)
scala> b.takeOrdered(3)
res8: Array[String] = Array(ape, cat, dog)
top
功能说明
返回RDD的前n个元素。
返回元素的顺序是按takeOrdered相反的顺序排列的。
函数原型
def top(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope {
takeOrdered(num)(ord.reverse)
}使用例子
scala> val b = sc.parallelize(List("dog", "cat", "ape", "salmon", "gnu"), 2)
b: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[7] at parallelize at <console>:24
scala> b.top(3)
res12: Array[String] = Array(salmon, gnu, dog)
max
功能说明
返回RDD中最大的元素。
函数原型
def max()(implicit ord: Ordering[T]): T 使用例子
scala> val b = sc.parallelize(List("dog", "cat", "ape", "salmon", "gnu"), 2)
scala> b.max()
res13: String = salmonisEmpty
功能说明
判断一个RDD是否为空。
函数原型
def isEmpty(): Boolean使用例子
scala> val b = sc.parallelize(List("dog", "cat", "ape", "salmon", "gnu"), 2)
b: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[7] at parallelize at <console>:24
scala> b.isEmpty()
res16: Boolean = false
saveAsTextFile
功能说明
把RDD的内容保存到text文件中。
函数原型
def saveAsTextFile(path: String): Unit
def saveAsTextFile(path: String, codec: Class[_ <: CompressionCodec]): Unit使用例子
scala> val b = sc.parallelize(List("dog", "cat", "ape", "salmon", "gnu"), 3)
scala> b.saveAsTextFile("/user/zxh/testdata/rddresult1/")
$ hadoop fs -cat /user/zxh/testdata/rddresult1/*
dog
cat
ape
salmon
gnu
keyBy
功能说明
通过在每个数据项上应用一个函数来构造两部分元组(键 - 值对)。函数的结果成为键,原始数据项成为新创建的元组的值。
函数原型
def keyBy[K](f: T => K): RDD[(K, T)]使用例子
val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
val b = a.keyBy(_.length)
b.collect
res26: Array[(Int, String)] = Array((3,dog), (6,salmon), (6,salmon), (3,rat), (8,elephant))
keys
功能说明
从所有包含的元组中提取key,并将它们返回到新的RDD中。
函数原型
def keys: RDD[K]使用例子
scala> val b = sc.parallelize(List("dog", "cat", "ape", "salmon", "gnu"), 3)
b: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> b.collect()
res2: Array[String] = Array(dog, cat, ape, salmon, gnu)
scala> val c = b.keyBy(_.length)
c: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[4] at keyBy at <console>:26
scala> c.collect()
res4: Array[(Int, String)] = Array((3,dog), (3,cat), (3,ape), (6,salmon), (3,gnu))
scala> c.keys
res5: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[5] at keys at <console>:29
scala> c.keys.collect()
res6: Array[Int] = Array(3, 3, 3, 6, 3)
2.2 Transformations函数
所有的Transformations函数完成后会返回一个新的RDD。
会介绍以下的Transformations函数
map、flatMap、mapPartitions、mapPartitionsWithIndex、filter、distinct、sample、union,++、intersection、glom、zip、zipParititions、zipWithIndex、sortBy、sortByKey
在讲解部分例子的时候测试的数据如下:
$ hadoop fs -cat /user/zxh/pdata/pdata
3350,province_name,上海,5.0
3349,province_name,四川,4.0
3348,province_name,湖南,11.0
3348,province_name,河北,11.0
map
功能说明
在RDD的每个item上使用transformation函数,结果返回一个新的RDD。
函数原型
def map[U: ClassTag](f: T => U): RDD[U]使用例子
// 构建一个rdd
scala> val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"))
// 通过map计算rdd每个成员的长度
scala> val b = a.map(_.length)
// 打印rdd
scala> b.collect().foreach(println)
在spark-shell中执行以上程序,得到的结果如下:
3
6
6
3
8查看一下得到的rdd的类型
scala> b
res5: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[2] at map at <console>:26可以看出该rdd的类型是MapPartitionsRDD,该RDD是通过在父RDD上通过map运算而得到的。
flatMap
功能说明
类似于map,与map相比flatMap有两个很大的区别:
(1) flatMap允许在map函数的基础上扩展成多个成员。
(2) flatMap会将一个长度为N的RDD转换成一个N个元素的集合,然后再把这N个元素合成到一个单个RDD的结果集。
函数原型
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] 使用例子
scala> val a = sc.parallelize(1 to 10)
// 扩展a的元素,把a的每个元素扩展成flatMap中的元素
scala> val b = a.flatMap(1 to _)
// 得到最后的c的结果,可以看到把a的每个元素都扩展成1 到 该元素 的多个值。
scala> val c = b.collect()
c: Array[Int] = Array(1, 1, 2, 1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
flatMap 和 map
通过例子来查看两者的区别:
flatMap的例子
val lines = sc.textFile("/user/zxh/pdata/pdata")
val rs1 = lines.flatMap(line=>line.split(","))
rs1.collect()flatMap的输出如下:
res5: Array[String] = Array(3350, province_name, 上海, 5.0, 3349, province_name, 四川, 4.0, 3348, province_name, 湖南, 11.0, 3348, province_name, 河北, 11.0)
map的例子
val lines = sc.textFile("/user/zxh/pdata/pdata")
val rs2 = lines.map(line => line.split(","))
rs2.collect()res6: Array[Array[String]] = Array(Array(3350, province_name, 上海, 5.0), Array(3349, province_name, 四川, 4.0), Array(3348, province_name, 湖南, 11.0), Array(3348, province_name, 河北, 11.0))
小结 :可以看到flatMap把最后的结果都合并到一个RDD的集合中了,而map是在每个item上输出是什么就保留什么元素,不合合并到一个集合中。
mapPartitions
功能说明
该函数和map函数类似,只不过映射函数的参数由RDD中的每一个元素变成了RDD中每一个分区的迭代器。如果在映射的过程中需要频繁创建额外的对象,使用mapPartitions要比map高效的多。
比如,将RDD中的所有数据通过JDBC连接写入数据库,如果使用map函数,可能要为每一个元素都创建一个connection,这样开销很大,如果使用mapPartitions,那么只需要针对每一个分区建立一个connection。
参数preservesPartitioning表示是否保留父RDD的partitioner分区信息。
函数原型
def mapPartitions[U](f: (Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false)(implicit arg0: ClassTag[U]): RDD[U]使用例子
var rdd1 = sc.makeRDD(1 to 5,2)
//rdd1有两个分区
scala> var rdd3 = rdd1.mapPartitions{ x => {
| var result = List[Int]()
| var i = 0
| while(x.hasNext){
| i += x.next()
| }
| result.::(i).iterator
| }}
rdd3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[84] at mapPartitions at :23
//rdd3将rdd1中每个分区中的数值累加
scala> rdd3.collect
res65: Array[Int] = Array(3, 12)
scala> rdd3.partitions.size
res66: Int = 2mapPartitionsWithIndex
功能说明
函数作用同mapPartitions,不过提供了两个参数,第一个参数为分区的索引。
函数原型
def mapPartitionsWithIndex[U](f: (Int, Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false)(implicit arg0: ClassTag[U]): RDD[U]使用例子
var rdd1 = sc.makeRDD(1 to 5,2)
//rdd1有两个分区
var rdd2 = rdd1.mapPartitionsWithIndex{
(x,iter) => {
var result = List[String]()
var i = 0
while(iter.hasNext){
i += iter.next()
}
result.::(x + "|" + i).iterator
}
}
//rdd2将rdd1中每个分区的数字累加,并在每个分区的累加结果前面加了分区索引
scala> rdd2.collect
res13: Array[String] = Array(0|3, 1|12)filter
功能说明
在RDD对象对象上使用filter函数,并返回满足条件的新的RDD。
函数原型
def filter(f: T => Boolean): RDD[T]使用例子
例子1
scala> val a = sc.parallelize(1 to 10)
scala> val b = a.filter(_>2)
scala> b.collect()
res3: Array[Int] = Array(3, 4, 5, 6, 7, 8, 9, 10)例子2
val lines = sc.textFile("/user/zxh/pdata/pdata")
val r = lines.flatMap(line=>line.split(",")).filter(_.length>5)
scala> r.collect()
res9: Array[String] = Array(province_name, province_name, province_name, province_name)
// 按元素长度进行过滤
scala> val r = lines.flatMap(line=>line.split(",")).filter(_.length>3)
r: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[33] at filter at <console>:26
scala> r.collect()
res11: Array[String] = Array(3350, province_name, 3349, province_name, 3348, province_name, 11.0, 3348, province_name, 11.0)
// 在每个元素中使用函数contains进行过滤
scala> val r = lines.flatMap(line=>line.split(",")).filter(_.contains("33"))
r: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[39] at filter at <console>:26
scala> r.collect()
res14: Array[String] = Array(3350, 3349, 3348, 3348)
distinct
功能说明
对RDD的元素去重。 返回一个包含每个唯一值一次的新RDD。
函数原型
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]使用例子
scala> val r = lines.flatMap(line=>line.split(",")).filter(_.length>3)
r: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[59] at filter at <console>:26
// 这里输出的是有重复的元素
scala> r.collect()
res20: Array[String] = Array(3350, province_name, 3349, province_name, 3348, province_name, 11.0, 3348, province_name, 11.0)
// 调用distinct()后这输出的是去重后的元素
scala> r.distinct().collect()
res21: Array[String] = Array(province_name, 3348, 11.0, 3350, 3349)
sample
功能说明
随机选择RDD项目的一部分数据,并将其返回到新的RDD中。
函数原型
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]withReplacement:是否要替换
fraction:原来的RDD元素大小的百分比
seed:随机数产生器的seed
使用例子
val a = sc.parallelize(1 to 10000, 3)
scala> a.sample(false,0.1,0).count()
res4: Long = 1032
scala> a.sample(false,0.3,0).count()
res5: Long = 2997
scala> a.sample(false,0.2,0).count()
res6: Long = 2018
union,++
功能说明
执行标准集合操作:A联合B。
若元素有重复,会保留重复的元素。
函数原型
def union(other: RDD[T]): RDD[T] 使用例子
scala> val a = sc.parallelize(1 to 5)
a: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at parallelize at <console>:24
scala> val b = sc.parallelize(6 to 9)
b: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at parallelize at <console>:24
scala> a.union(b).collect()
res7: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> (a ++ b).collect()
res9: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
intersection
功能说明
该函数返回两个RDD的交集,并且去重。
函数原型
def intersection(other: RDD[T]): RDD[T]
def intersection(other: RDD[T], numPartitions: Int): RDD[T]
def intersection(other: RDD[T], partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T]使用例子
scala> var rdd1 = sc.makeRDD(1 to 2,1)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[45] at makeRDD at :21
scala> rdd1.collect
res42: Array[Int] = Array(1, 2)
scala> var rdd2 = sc.makeRDD(2 to 3,1)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[46] at makeRDD at :21
scala> rdd2.collect
res43: Array[Int] = Array(2, 3)
scala> rdd1.intersection(rdd2).collect
res45: Array[Int] = Array(2)
scala> var rdd3 = rdd1.intersection(rdd2)
rdd3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[59] at intersection at :25
scala> rdd3.partitions.size
res46: Int = 1
scala> var rdd3 = rdd1.intersection(rdd2,2)
rdd3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[65] at intersection at :25
scala> rdd3.partitions.size
res47: Int = 2glom
功能说明
创建一个新的RDD,该RDD把会将各个分区的所有元素合并到同一个数组中,若有多个分区,就会得到一个有多个数组的集合。
函数原型
def glom(): RDD[Array[T]]使用例子
scala> val a = sc.parallelize(1 to 10, 3)
a: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> a.collect()
res1: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
// 查看一下分区的个数
scala> a.partitions.length
res2: Int = 3
// 调用了glom合并分区的数据
scala> val b = a.glom()
b: org.apache.spark.rdd.RDD[Array[Int]] = MapPartitionsRDD[3] at glom at <console>:26
// 每个分区的数据组成了一个array
scala> b.collect()
res4: Array[Array[Int]] = Array(Array(1, 2, 3), Array(4, 5, 6), Array(7, 8, 9, 10))
zip
功能说明
将两个分区中的第n个分区相互组合,从而连接两个RDD。 生成的RDD将由两部分元组组成,这些元组被解释为键-值(key-value)对。
注意:使用该函数时,两个RDD的分区和元素个数必须一样,否则将会报错。见例子2。
函数原型
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]使用例子
scala> val a = sc.parallelize(1 to 10, 3)
scala> val b = sc.parallelize(11 to 20, 3)
scala> val c = a.zip(b)
c: org.apache.spark.rdd.RDD[(Int, Int)] = ZippedPartitionsRDD2[9] at zip at <console>:28
scala> c.collect()
res8: Array[(Int, Int)] = Array((1,11), (2,12), (3,13), (4,14), (5,15), (6,16), (7,17), (8,18), (9,19), (10,20))
zipParititions
功能说明
和zip的功能相似,但可以提供更多的控制。
函数原型
def zipPartitions[B: ClassTag, V: ClassTag]
(rdd2: RDD[B], preservesPartitioning: Boolean)
(f: (Iterator[T], Iterator[B]) => Iterator[V]): RDD[V]
def zipPartitions[B: ClassTag, V: ClassTag]
(rdd2: RDD[B])
(f: (Iterator[T], Iterator[B]) => Iterator[V]): RDD[V]
def zipPartitions[B: ClassTag, C: ClassTag, V: ClassTag]
(rdd2: RDD[B], rdd3: RDD[C], preservesPartitioning: Boolean)
(f: (Iterator[T], Iterator[B], Iterator[C]) => Iterator[V]): RDD[V]
def zipPartitions[B: ClassTag, C: ClassTag, V: ClassTag]
(rdd2: RDD[B], rdd3: RDD[C])
(f: (Iterator[T], Iterator[B], Iterator[C]) => Iterator[V]): RDD[V]
def zipPartitions[B: ClassTag, C: ClassTag, D: ClassTag, V: ClassTag]
(rdd2: RDD[B], rdd3: RDD[C], rdd4: RDD[D], preservesPartitioning: Boolean)
(f: (Iterator[T], Iterator[B], Iterator[C], Iterator[D]) => Iterator[V]): RDD[V]
def zipPartitions[B: ClassTag, C: ClassTag, D: ClassTag, V: ClassTag]
(rdd2: RDD[B], rdd3: RDD[C], rdd4: RDD[D])
(f: (Iterator[T], Iterator[B], Iterator[C], Iterator[D]) => Iterator[V]): RDD[V]
使用例子
val a = sc.parallelize(0 to 9, 3)
val b = sc.parallelize(10 to 19, 3)
val c = sc.parallelize(100 to 109, 3)
def myfunc(aiter: Iterator[Int], biter: Iterator[Int], citer: Iterator[Int]): Iterator[String] =
{
var res = List[String]()
while (aiter.hasNext && biter.hasNext && citer.hasNext)
{
val x = aiter.next + " " + biter.next + " " + citer.next
res ::= x
}
res.iterator
}
a.zipPartitions(b, c)(myfunc).collect
res50: Array[String] = Array(2 12 102, 1 11 101, 0 10 100, 5 15 105, 4 14 104, 3 13 103, 9 19 109, 8 18 108, 7 17 107, 6 16 106)
zipWithIndex
功能说明
使用元素索引来压缩RDD的元素。索引从0开始。如果RDD分布在多个分区上,则启动一个Spark作业来执行此操作。
函数原型
def zipWithIndex(): RDD[(T, Long)]使用例子
// 字符串的例子
scala> val r1 = sc.parallelize(Array("a", "b", "c", "d"))
r1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[13] at parallelize at <console>:24
scala> val r2 = r1.zipWithIndex
r2: org.apache.spark.rdd.RDD[(String, Long)] = ZippedWithIndexRDD[14] at zipWithIndex at <console>:26
scala> r2.collect()
res10: Array[(String, Long)] = Array((a,0), (b,1), (c,2), (d,3))
// 整数类型的例子
scala> val z = sc.parallelize(1 to 10, 5)
z: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[16] at parallelize at <console>:24
scala> val r2 = z.zipWithIndex
r2: org.apache.spark.rdd.RDD[(Int, Long)] = ZippedWithIndexRDD[18] at zipWithIndex at <console>:26
scala> r2.collect()
res11: Array[(Int, Long)] = Array((1,0), (2,1), (3,2), (4,3), (5,4), (6,5), (7,6), (8,7), (9,8), (10,9))
scala> r2.partitions.length
res12: Int = 5
sortBy
sortBy函数是在org.apache.spark.rdd.RDD类中实现的,它的实现如下:
/**
* Return this RDD sorted by the given key function.
*/
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.size)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] =
this.keyBy[K](f)
.sortByKey(ascending, numPartitions)
.values该函数最多可以传三个参数:
第一个参数是一个函数,该函数的也有一个带T泛型的参数,返回类型和RDD中元素的类型是一致的;
第二个参数是ascending,从字面的意思大家应该可以猜到,是的,这参数决定排序后RDD中的元素是升序还是降序,默认是true,也就是升序;
第三个参数是numPartitions,该参数决定排序后的RDD的分区个数,默认排序后的分区个数和排序之前的个数相等,即为this.partitions.size。
从sortBy函数的实现可以看出,第一个参数是必须传入的,而后面的两个参数可以不传入。而且sortBy函数函数的实现依赖于sortByKey函数,关于sortByKey函数后面会进行说明。keyBy函数也是RDD类中进行实现的,它的主要作用就是将将传进来的每个元素作用于f(x)中,并返回tuples类型的元素,也就变成了Key-Value类型的RDD了,它的实现如下:
/**
* Creates tuples of the elements in this RDD by applying `f`.
*/
def keyBy[K](f: T => K): RDD[(K, T)] = {
map(x => (f(x), x))
}那么,如何使用sortBy函数呢?
scala> val data = List(3,1,90,3,5,12)
data: List[Int] = List(3, 1, 90, 3, 5, 12)
scala> val rdd = sc.parallelize(data)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:14
scala> rdd.collect
res0: Array[Int] = Array(3, 1, 90, 3, 5, 12)
scala> rdd.sortBy(x => x).collect
res1: Array[Int] = Array(1, 3, 3, 5, 12, 90)
scala> rdd.sortBy(x => x, false).collect
res3: Array[Int] = Array(90, 12, 5, 3, 3, 1)
scala> val result = rdd.sortBy(x => x, false)
result: org.apache.spark.rdd.RDD[Int] = MappedRDD[23] at sortBy at <console>:16
scala> result.partitions.size
res9: Int = 2
scala> val result = rdd.sortBy(x => x, false, 1)
result: org.apache.spark.rdd.RDD[Int] = MappedRDD[26] at sortBy at <console>:16
scala> result.partitions.size
res10: Int = 1上面的实例对rdd中的元素进行升序排序。并对排序后的RDD的分区个数进行了修改,上面的result就是排序后的RDD,默认的分区个数是2,而我们对它进行了修改,所以最后变成了1。
sortByKey
sortByKey函数作用于Key-Value形式的RDD,并对Key进行排序。它是在org.apache.spark.rdd.OrderedRDDFunctions中实现的,实现如下
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.size)
: RDD[(K, V)] =
{
val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part)
.setKeyOrdering(if (ascending) ordering else ordering.reverse)
}从函数的实现可以看出,它主要接受两个函数,含义和sortBy一样,这里就不进行解释了。该函数返回的RDD一定是ShuffledRDD类型的,因为对源RDD进行排序,必须进行Shuffle操作,而Shuffle操作的结果RDD就是ShuffledRDD。其实这个函数的实现很优雅,里面用到了RangePartitioner,它可以使得相应的范围Key数据分到同一个partition中,然后内部用到了mapPartitions对每个partition中的数据进行排序,而每个partition中数据的排序用到了标准的sort机制,避免了大量数据的shuffle。下面对sortByKey的使用进行说明:
scala> val a = sc.parallelize(List("wyp", "iteblog", "com", "397090770", "test"), 2)
a: org.apache.spark.rdd.RDD[String] =
ParallelCollectionRDD[30] at parallelize at <console>:12
scala> val b = sc. parallelize (1 to a.count.toInt , 2)
b: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[31] at parallelize at <console>:14
scala> val c = a.zip(b)
c: org.apache.spark.rdd.RDD[(String, Int)] = ZippedPartitionsRDD2[32] at zip at <console>:16
scala> c.sortByKey().collect
res11: Array[(String, Int)] = Array((397090770,4), (com,3), (iteblog,2), (test,5), (wyp,1))上面对Key进行了排序。细心的读者可能会问,sortBy函数中的第一个参数可以对排序方式进行重写。为什么sortByKey没有呢?难道只能用默认的排序规则。不是,是有的。其实在OrderedRDDFunctions类中有个变量ordering它是隐形的:private val ordering = implicitly[Ordering[K]]。他就是默认的排序规则,我们可以对它进行重写,如下:
scala> val b = sc.parallelize(List(3,1,9,12,4))
b: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[38] at parallelize at <console>:12
scala> val c = b.zip(a)
c: org.apache.spark.rdd.RDD[(Int, String)] = ZippedPartitionsRDD2[39] at zip at <console>:16
scala> c.sortByKey().collect
res15: Array[(Int, String)] = Array((1,iteblog), (3,wyp), (4,test), (9,com), (12,397090770))
scala> implicit val sortIntegersByString = new Ordering[Int]{
| override def compare(a: Int, b: Int) =
| a.toString.compare(b.toString)}
sortIntegersByString: Ordering[Int] = $iwC$$iwC$$iwC$$iwC$$iwC$$anon$1@5d533f7a
scala> c.sortByKey().collect
res17: Array[(Int, String)] = Array((1,iteblog), (12,397090770), (3,wyp), (4,test), (9,com))例子中的sortIntegersByString就是修改了默认的排序规则。这样将默认按照Int大小排序改成了对字符串的排序,所以12会排序在3之前。
三、Spark RDD的容错机制
一般而言,RDD容错性具备两种方式:数据检查点和记录数据的更新
- checkpoint机制——数据检查点
- 记录更新机制(即Lineage机制)
3.1 checkpoint机制
checkpoint的意思是建立检查点,类似于快照,传统的Spark任务计算过程中,DAG特别长,集群需要将整个DAG计算完成得到结果,但是如果在这个漫长的计算过程中出现数据丢失,Spark又会根据依赖关系重新从头开始计算一遍结果,这样很浪费性能,当然我们可以考虑将中间计算结果cache或者persist到内存或者磁盘中,但是这样不能保证数据完全不丢失,存储的内存出现了问题或者磁盘坏掉,也会导致Spark再次根据RDD重新再次计算一遍,所以就出现了checkpoint机制,其中checkpoint的作用就是将DAG中比较重要的中间计算结果存储到一个高可用的地方,通常这个地方是HDFS里面。
另外需要注意cache和checkpoint机制之间的区别:
- 检查点是新建一个job来完成的,是执行的完一个job之后,新建一个来完成的;而cache,是job执行过程中进行。
- 检查点对RDD的checkpoint是将数据的血统截断,只保存了想要保存的RDD在HDFS中,而cache的是计算血统的数据在内存中。
- 缓存的清除方式也不一样,checkpoint到HDFS中的RDD需要手动清除,如果不手动清除,会一直存在,可以被下一个驱动程序所使用;而cache到内存和persist到磁盘的partition, 由 blockManager 管理。一旦 driver program 执行结束,也就是 executor 所在进程 CoarseGrainedExecutorBackend stop,blockManager 也会 stop,被 cache 到磁盘上的 RDD 也会被清空(整个 blockManager 使用的 local 文件夹被删除)。
checkpoint机制不足
操作成本高,需要通过数据中心的网络连接在机器之间复制庞大的数据集,而网络带宽往往比内存带宽低得多,同时还需要消耗更多的存储资源。因此Spark侧重于记录更新的方式,即血统机制。
3.2 Lineage机制
RDD只支持粗粒度转换,即只记录单个块上执行的单个操作,然后将创建RDD的一系列变换序列(每个RDD都包含了它是如何由其他RDD变换过来的以及如何重建某一块数据的信息。因此RDD的容错机制又称“血统(Lineage)”容错)记录下来,以便恢复丢失的分区。 Lineage本质上很类似于数据库中的重做日志(Redo Log),只不过这个重做日志粒度很大,是对全局数据做同样的重做进而恢复数据。
相比其他系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD的Lineage记录的是粗颗粒度的特定数据Transformation操作(如filter、map、join等)行为。当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区。因为这种粗颗粒的数据模型,限制了Spark的运用场合,所以Spark并不适用于所有高性能要求的场景,但同时相比细颗粒度的数据模型,也带来了性能的提升。
Rdd在Lineage依赖方面划分成两种依赖:窄依赖(Narrow Dependencies)与宽依赖,根据父RDD分区是对应1个还是多个子RDD分区来区分窄依赖(父分区对应一个子分区)和宽依赖(父分区对应多个子分 区)。
- 窄依赖:指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区,和多个父RDD的分区对应于一个子RDD 的分区。图中,map/filter和union属于第一类,对输入进行协同划分(co-partitioned)的join属于第二类(这个主要表现在spark还支持像groupbykey和reducebykey这样的宽依赖,这样计算子RDD中一个partition的一条记录依赖父RDD中许多partition中的记录,具有相同key的所有tuple最终会放到在同一个partition中,然后被同一个task处理,为了满足这种操作,spark必须进行shuffle,通过在集群的节点间传输数据最终生成一个新的stage和新的partition集合。(同一个stage中所有的RDD的partition数据应该不一致))。
- 宽依赖:指子RDD的分区依赖于父RDD的所有分区,这是因为shuffle类操作,如图中的groupByKey和未经协同划分的join。
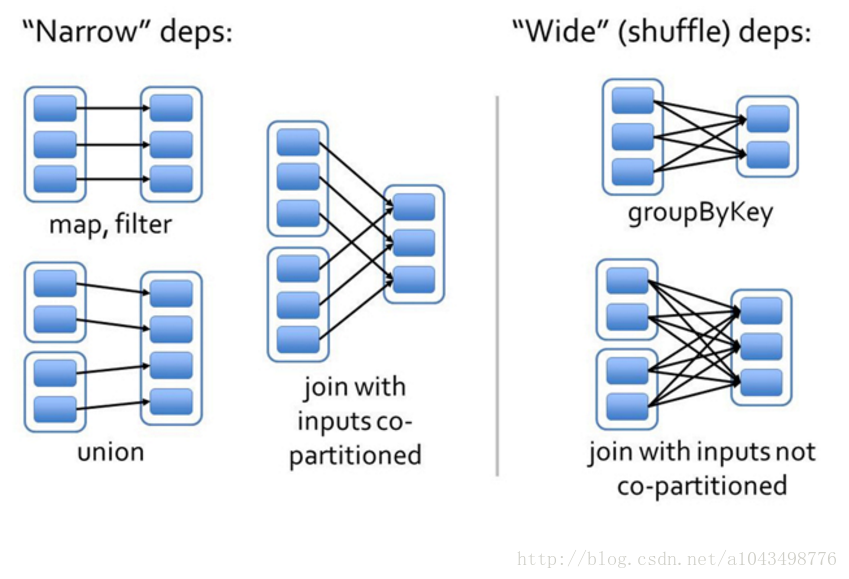
通过介绍窄依赖和宽依赖,我们可以得到以下结论:
第一,窄依赖可以在某个计算节点上直接通过计算父RDD的某块数据计算得到子RDD对应的某块数据;宽依赖则要等到父RDD所有数据都计算完成之后,并且父RDD的计算结果进行hash并传到对应节点上之后才能计算子RDD。
第二,数据丢失时,对于窄依赖只需要重新计算丢失的那一块数据来恢复;对于宽依赖则要将祖先RDD中的所有数据块全部重新计算来恢复。所以在长“血统”链特别是有宽依赖的时候,需要在适当的时机设置数据检查点。也是这两个特性要求对于不同依赖关系要采取不同的任务调度机制和容错恢复机制。
在容错机制中,如果一个节点死机了,而且运算窄依赖,则只要把丢失的父RDD分区重算即可,不依赖于其他节点。而宽依赖需要父RDD的所有分区都存在,重算就很昂贵了。可以这样理解开销:在窄依赖中,在子RDD的分区丢失、重算父RDD分区时,父RDD相应分区的所有数据都是子RDD分区的数据,并不存在冗余计算。在宽依赖情况下,丢失一个子RDD分区重算的每个父RDD的每个分区的所有数据,而这并不是都给丢失的子RDD分区用的,会有一部分数据相当于对应的是未丢失的子RDD分区中需要的数据,这样就会产生冗余计算开销,这也是宽依赖开销更大的原因。因此如果使用Checkpoint算子来做检查点,不仅要考虑Lineage是否足够长,也要考虑是否有宽依赖,对宽依赖加Checkpoint是最物有所值的。
参考文献
【2】Spark RDD详解
【7】通过例子学习spark rdd--Transformations函数
【8】Spark算子:RDD基本转换操作(5)–mapPartitions、mapPartitionsWithIndex
【9】Spark: sortBy和sortByKey函数详解
【10】spark的数据容错机制















 1864
1864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









