







选择红黑树的原因:
首先查询效率和平衡二叉树相差无几,而且红黑树的失衡之后的复衡的代价比较低,不想平衡二叉树需要多次旋转(主要原因还是平衡二叉树追求极致的平衡)
1.为什么hashMap使用红黑树而不是其他结构?
在回答这个问题之前,我们先了解一下有关二叉树的基本内容。
①二叉排序树(又称二叉查找树):
1)若左子树不为空,则左子树上所有结点的值均小于根结点的值。
2)若右子树不为空,则右子树上所有结点的值均大于根节点的值。
3)左右子树也为二叉排序树。
②平衡二叉树(AVL树):是一种二叉查找树,当且仅当两个子树的高度差不超过1时,这个树是平衡二叉树。
③红黑树:是许多二叉查找树中的一种,它能保证在最坏的情况下,基本动态集合操作时间为O(lgn).
问题1:为什么不使用二叉排序树?
问题主要出现在二叉排序树在添加元素的时候极端情况下会出现线性结构。
举例说明:由于二叉排序树左子树所有节点的值均小于根节点的特点,如果我们添加的元素都比根节点小,会导致左子树线性增长,这样就失去了用树型结构替换链表的初衷,导致查询时间增长。所以这是不用二叉查找树的原因。
题2:为什么不使用平衡二叉树呢?
①红黑树不追求"完全平衡",即不像AVL那样要求节点的 |balFact| <= 1,它只要求部分达到平衡,但是提出了为节点增加颜色,红黑是用非严格的平衡来换取增删节点时候旋转次数的降低,任何不平衡都会在三次旋转之内解决,而AVL是严格平衡树,因此在增加或者删除节点的时候,根据不同情况,旋转的次数比红黑树要多。
就插入节点导致树失衡的情况,AVL和RB-Tree都是最多两次树旋转来实现复衡rebalance,旋转的量级是O(1)
删除节点导致失衡,AVL需要维护从被删除节点到根节点root这条路径上所有节点的平衡,旋转的量级为O(logN),而RB-Tree最多只需要旋转3次实现复衡,只需O(1),所以说RB-Tree删除节点的rebalance的效率更高,开销更小!
AVL的结构相较于RB-Tree更为平衡,插入和删除引起失衡,如2所述,RB-Tree复衡效率更高;当然,由于AVL高度平衡,因此AVL的Search效率更高啦。
针对插入和删除节点导致失衡后的rebalance操作,红黑树能够提供一个比较"便宜"的解决方案,降低开销,是对search,insert ,以及delete效率的折衷,总体来说,RB-Tree的统计性能高于AVL.
故引入RB-Tree是功能、性能、空间开销的折中结果。
② AVL更平衡,结构上更加直观,时间效能针对读取而言更高;维护稍慢,空间开销较大。
③ 红黑树,读取略逊于AVL,维护强于AVL,空间开销与AVL类似,内容极多时略优于AVL,维护优于AVL。
基本上主要的几种平衡树看来,红黑树有着良好的稳定性和完整的功能,性能表现也很不错,综合实力强,在诸如STL的场景中需要稳定表现。
Hashmap的key值的比较:
HashMap中的比较key是这样的,先求出key的hashcode(),比较其值是否相等,若相等再比较equals(),若相等则认为他们是相等 的。若equals()不相等则认为他们不相等。如果只重写hashcode()不重写equals()方法,当比较equals()时只是看他们是否为 同一对象(即进行内存地址的比较),所以必定要两个方法一起重写。
Hashcode()方法决定了key值的hash值的多少,但hash值并不能线性的确定该元素的位置,因为从hash值到确定元素存放桶的位置还有一个相与操作(下文有),但此时能明确的时候hash相同的一定在同一个桶中,但不能确定hash大的就一定在后面
hash值相与:
在hashmap的源码中putVal()获取存放桶的位置
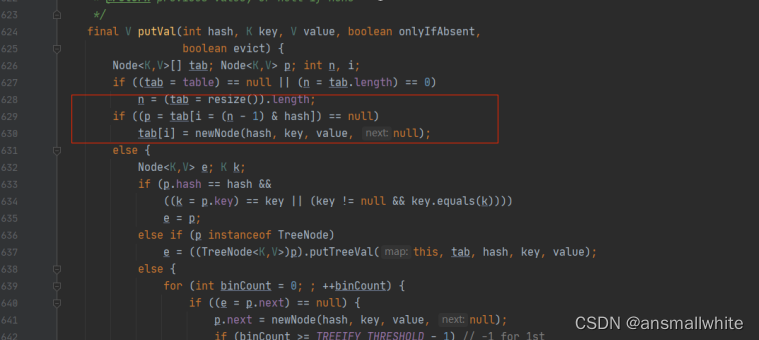
元素存放的数组位置是通过:数组大小size-1和元素的hash值相与得到的
eg:某个元素的k的hash值为0001 1011 1101 1010
当数组大小为16的时候,那就用元素的hash值和(size-1)1111相与得到该元素需要存放的桶的位置(数组的下标)
Ps:之所以用位运算而不是取余,是因为位运算更快;
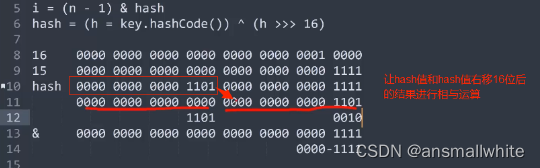
扰动函数:
让元素的hash值和右移16位的数据进行相与运算

让元素的hash值的高位和低位都加入运算,可以让元素更加均匀的分配在hash数组中
扩容机制:
当链表长度达到8的时候会扩容(table的长度小于64),若table长度大于64且链表有长度达到8的,则会进行树化(长度大于8的链表),将链表转为红黑树(空间和时间复杂度权衡下的规定)
如果后期删除了某些元素,当红黑树的长度减为6的时候会再次转化为链表;扩容因子为0.75:当数组被用了0.75倍之后,数组就会扩容两倍,eg:hashmap初试数组长度为16,当用了12个数组之后,就会扩容到32......数组最大长度为2的30次方;
hashmap多线程下扩容死循环的原因:
假如原始hashmap数组下标为【2】的链表情况:
桶2--->node1--->node2---->node3
单线程扩容后:(头插法,因此移动到扩容后的hashmap的时候节点是逆着的)
桶2---->node3---->node2----->node1
多线程扩容时候,如果线程1已经把数据扩容到新的hashmap里面了:
桶2---->node3---->node2----->node1
如果此时线程2由于阻塞了只是先把原始的hashmap的node1放入了桶中,此时线程2的复制node的指针指的是node2(暂且称为指针,其实是记录下一个需要复制的node的地址):
桶2---->node1
但此时线程2指向node2的指针的实际情况是:node2已经进入了线程1扩容好的桶里面了:
桶2---->node3---->node2----->node1
当线程2接着处理的之后:
桶2---->node1---->node2
此时线程2的下一个需要处理的数据就是线程1的环境下的next了,指的是node1,
线程2再处理:
桶2---->node1---->node2----->node1
这就相当于:

相当于线程2处理数据的时候慢了一步,被线程1偷家了,此时线程2标记的地址已经指向了线程1的家里面了
总结:形成死循环的原因就是java1.7的时候对hashmap桶的节点的处理是从头节点开始,导致当对该hashmap进行复制的时候,新的hashmap的桶的链表的顺序和旧链表的顺序是相反的,当改为从尾结点处理,新旧链表的顺序就不会相反了
重写hashcode引起的内存泄露
若hashmap的k值是自定义类对象的话,重写了hashcode和equals方法之后,如果对已经放入map的对象进行修改信息的话,很有可能导致内存泄露:
新建dogg类,重写hashcode(),把三个成员属性的值作为hash生成的依据: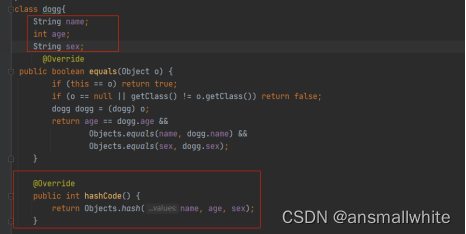
对A对象的name进行修改之后,再用get(key)进行查询的时候,hashmap会根据dogg的hashcode函数生成hash值,然后去自己的哈希数组里面找key对应的桶,去桶里面遍历链表,通过equals()函数对比链表中的数据获得值
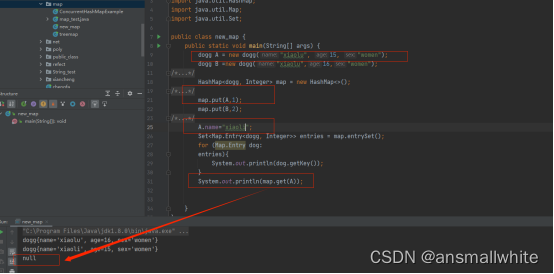
因此修改完name的A的hashcode也发生了变化,此时hashmap就无法通过hashcode找到A所在的桶了,但是遍历hashmap依然可以,因为entrySet用的是桶的游标进行遍历的,A只是改了信息,但是没有移除也没有搬家(因为修改A的信息之后,hashmap不会对其hashcode进行更新,A还在老位置)
避免泄露的方法:当要修改A的值的时候,可以先从hashmap中删除该值,然后进行修改后再插入

















 991
991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









