






《看漫画学python》需要的自取:
链接
文章目录
标识符
命名规则:
区分大小写:myname和Myname是两个不同的标识符
首字符可以是下划线_或者字母,但不允许为数字
除首字母外其他字符必须是下划线,字母和数字
关键字不能做标识符
不用使用python的内置函数作为自己的标识符
代码注释
#+空格+注释内容
#coding=utf-8或者# --coding:utf-8 --’
模块
一个模块就是一个文件,保存代码最小单元
模块中可以声明类,变量,函数,属性
模块导入语法
语法一: import modelName
import time
timenow = time.localtime()
print(time.strftime(‘%Y-%m-%d %H:%M:%S’,timenow))
语法二: import modelName as xx
import time as t
timenow = t.localtime()
print(t.strftime(‘%Y-%m-%d %H:%M:%S’,timenow))
语法三: from xxx import xxx
from selenium import webdriver
数据类型
Python3 中有六个标准的数据类型:
Number(数字)不可变数据类型
String(字符串)不可变数据类型
List(列表) 可变数据类型
Tuple(元组)不可变数据类型
Sets(集合)
Dictionary(字典)
Python3 的六个标准数据类型中:
不可变数据(四个):Number(数字)、String(字符串)、Tuple(元组)、Sets(集合);
可变数据(两个):List(列表)、Dictionary(字典)
多个变量赋值:
a=b=c=1
a,b,c=1,2,“runoob”
Number(数字)
Python3 支持 int、float、bool、complex(复数)。
内置的 type() 函数可以用来查询变量所指的对象类型。
>>> a, b, c, d = 20, 5.5, True, 4+3j
>>> print(type(a), type(b), type(c), type(d))
<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
数学运算
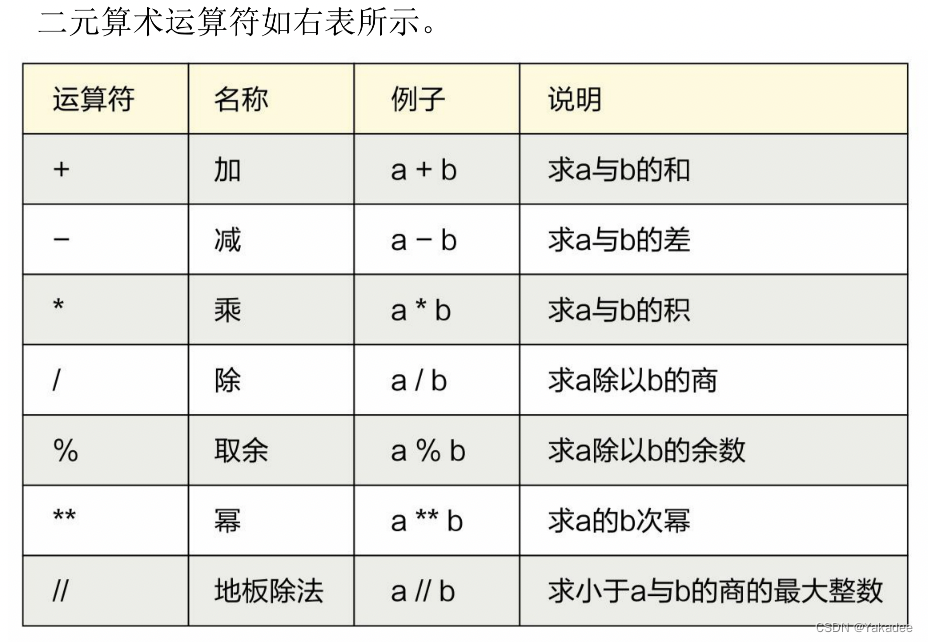
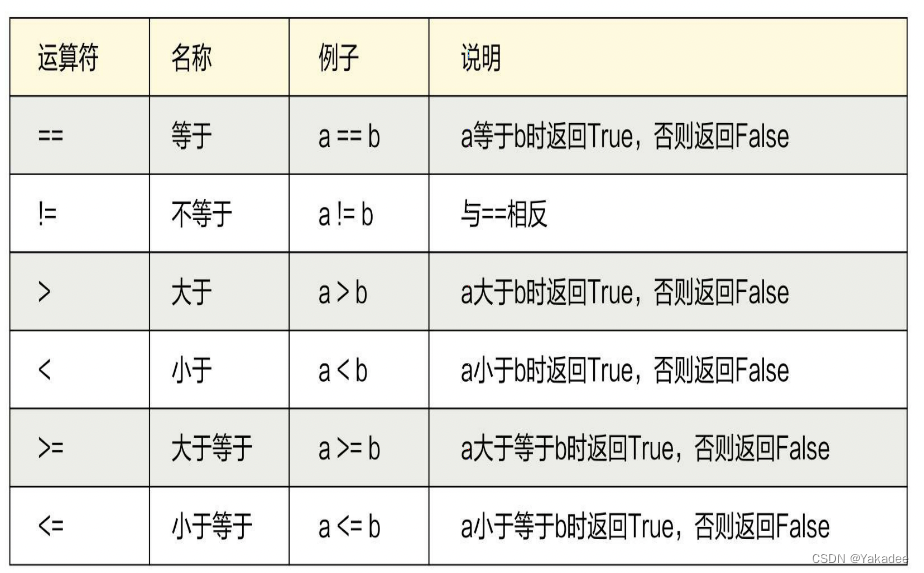
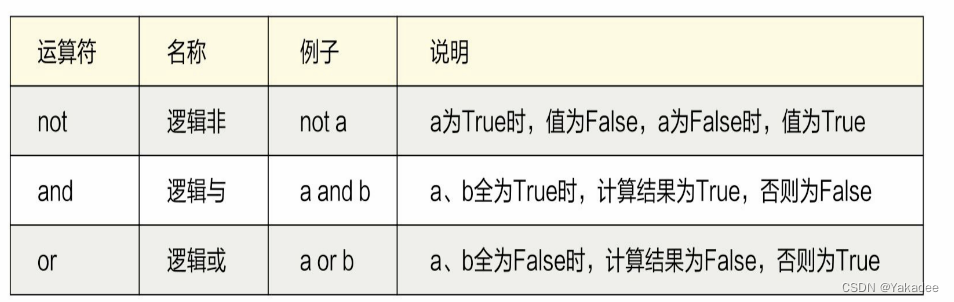
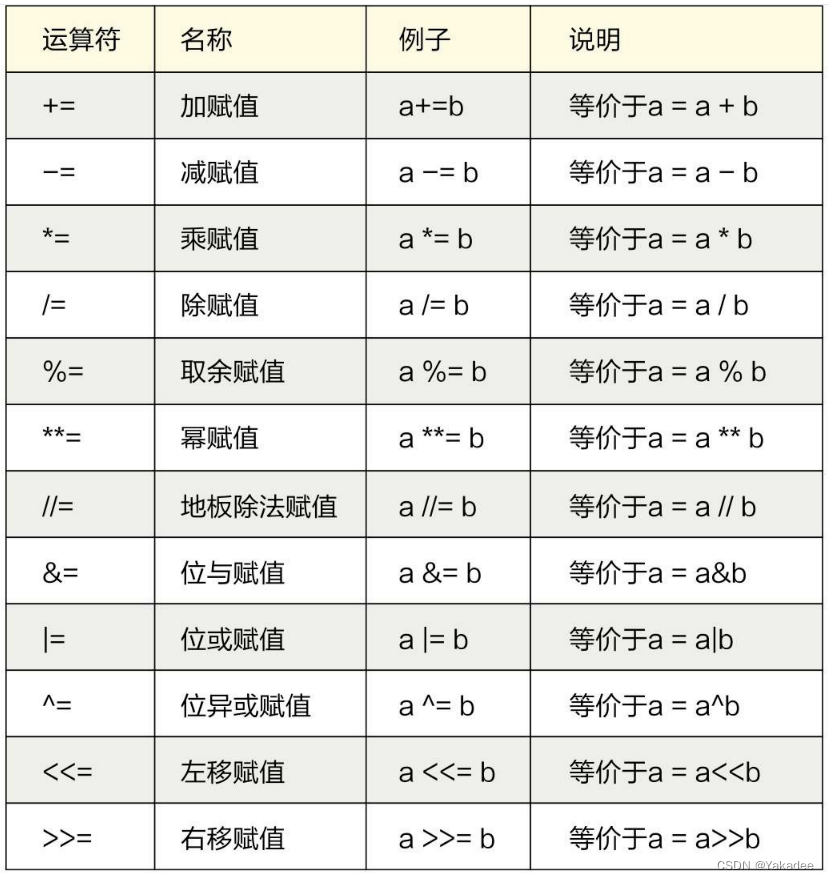
按位取反公式:~a=(a+1)*-1
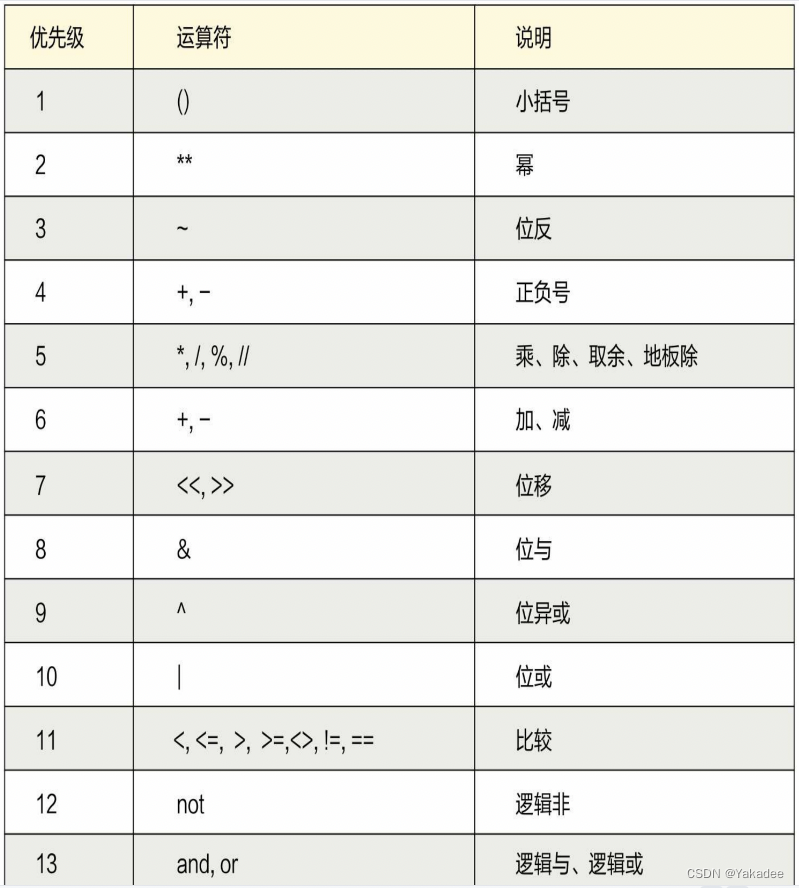
运算优先级
string类型
字符串切片
格式:变量[start🔚step] 含头不含尾,左闭右开
start::开始索引值 索引值从左到右 从0开始 索引值从右到左,从‐1开始
end:结束索引值
step:步长 默认为1
str_num="123456789"
# 取单字符 字符串中倒数第二个字符
print("字符串中倒数第二个字符:",str_num[‐2])
# 字符串反转 从右到左
print("字符串反转:",str_num[::‐1])
格式化
"""
字符串格式化
"""
# 字符串格式表示方式一
print("%s[%s期,工作年限:%d],欢迎来到码尚学院VIP课堂"%("大雨","M211",3))
# 字符串格式表示方式二
print("{1}[{0}期,工作年限:{2}],欢迎来到码尚学院VIP课堂".format("大雨","M211",3))
# 字符串格式表示方式三 f 字面量格式化
name="大雨"
q="M211"
year="2"
print(f"{name}[{q}期,工作年限:{year}],欢迎来到码尚学院VIP课堂")
字符串常见函数
- join:通过分隔符合并成一个新的字符
- split:通过分隔符截开多个字符,存储在列表中
- replace:替换
- find:(查找字符, 开始索引,结束索引值)查找字符串,找到返回开始索引值,没有找到
- index:与find的区别就是没有找到就报错
- count:(查询字符, 开始索引,结束索引值) 返回某个字符在指定范围出现次数
- startswith:(匹配字符, 开始索引,结束索引值) 判断是否以某个字符开头
- endswith:(匹配字符, 开始索引,结束索引值) 判断是否以某个字符结尾
join_str="helloworld"
new_str="‐".join(join_str)
print(new_str)
# split()
# 通过分隔符截取字符串 通过分隔符,返回列表数据
names="hefan;大雨;志大叔"
namel=names.split(";")
print(namel,type(namel))
# replace(原字符, 新字符)
# 替换字符串
str_old="1234567"
new_str=str_old.replace("123","000")
print(new_str)
# find(查找字符, 开始索引,结束索引值)查找字符串,找到返回开始索引值,没有找到
返回‐1
ss_str="12345678"
print(ss_str.find("8"))
# index ‐‐>find区别在于,index如果没有找到则报错
ss_str="12345678888"
print(ss_str.index("8"))
# count(查询字符, 开始索引,结束索引值) 返回某个字符在指定范围出现次数
print(ss_str.count("0"))
# startswith(匹配字符, 开始索引,结束索引值) 判断是否以某个字符开头
print(ss_str.startswith("123"))
# endswith(匹配字符, 开始索引,结束索引值) 判断是否以某个字符结尾
print(ss_str.endswith("123"))
序列
包括:列表list,字符串str,元组tuple和字节序列
列表
列表也支持切片的方式,是可变数据类型
创建列表有2种方式:
1.用[]括起来,用逗号分隔。[元素1,元素2…]
2.list(iterable):参数iterable是可迭代对象(字符串,列表,元组,集合和字典等)
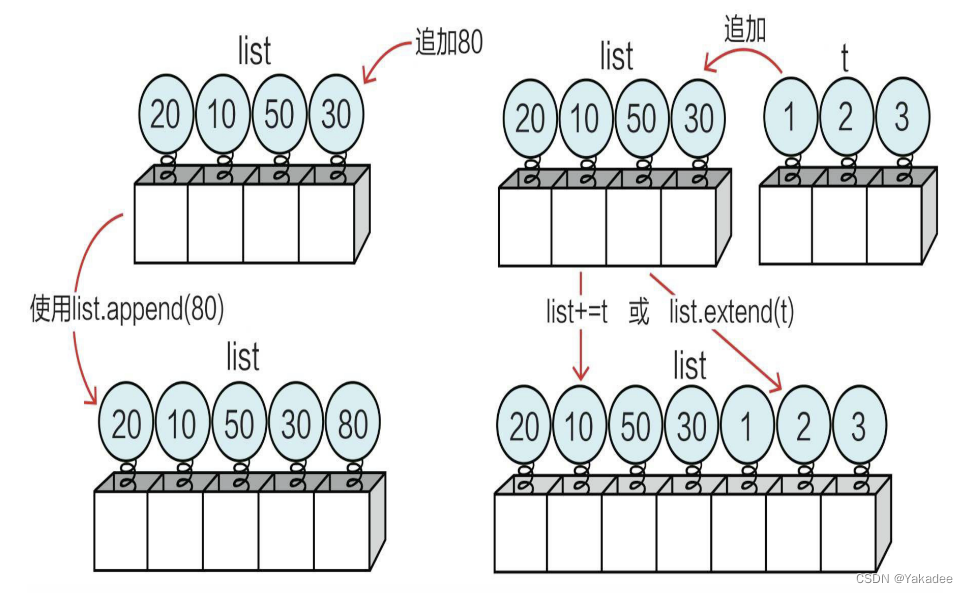
追加元素
列表是可变的序列对象,可以追加元素,方法有2种:
1.追加单个元素,append(x)
2.追加多个元素,用+运算符或者extend(t)方法
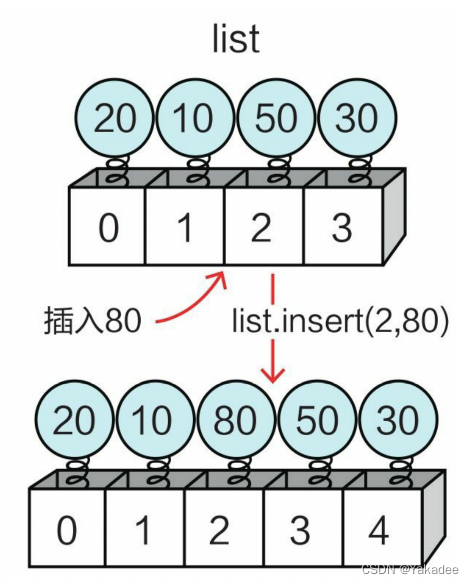
插入元素
使用list.insert(i,x),i:索引位置,x:要插入的元素
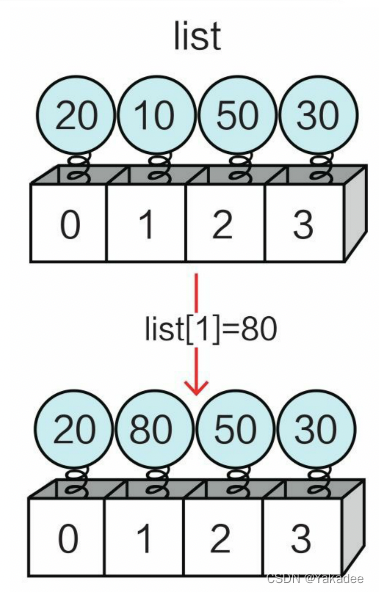
替换元素
列表下标索引元素放在=的左边,进行赋值即可。
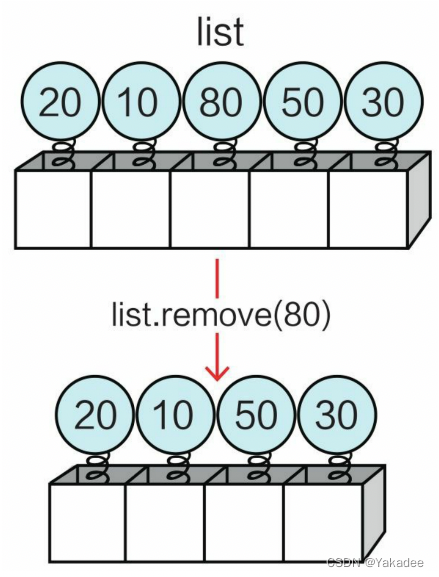
>>> list=[20,10,50,30]
>>> list[1]=80
>>> list
[20, 80, 50, 30]
删除元素
remove和pop删除的区别:remove是根据value值删除,pop是根据index值删除
使用list.remove(X),如果匹配到多个,就删除第一个
查找元素
元组
元组可以和string一样支持切片,不支持修改,可以连接
元素不可变序列
元组创建有2种方法:
1.tuple(iterable):参数iterable是可迭代对象(字符串,列表,元组,集合和字典等)
2.(元素1,元素2…),小括号可以省略
>>> 21,32,43,45
(21, 32, 43, 45)
>>> ('hello','world')
('hello', 'world')
>>> ('hello','world',1,2,3)
('hello', 'world', 1, 2, 3)
>>> tuple('hello')
('h', 'e', 'l', 'l', 'o')
>>> tuple([11,12,14,15])
(11, 12, 14, 15)
>>> t=1,
>>> t
(1,)
>>> type(t)
<class 'tuple'>
>>> t=(1,)
>>> type(t)
<class 'tuple'>
>>> a=()
>>> type(a)
<class 'tuple'>
>>>
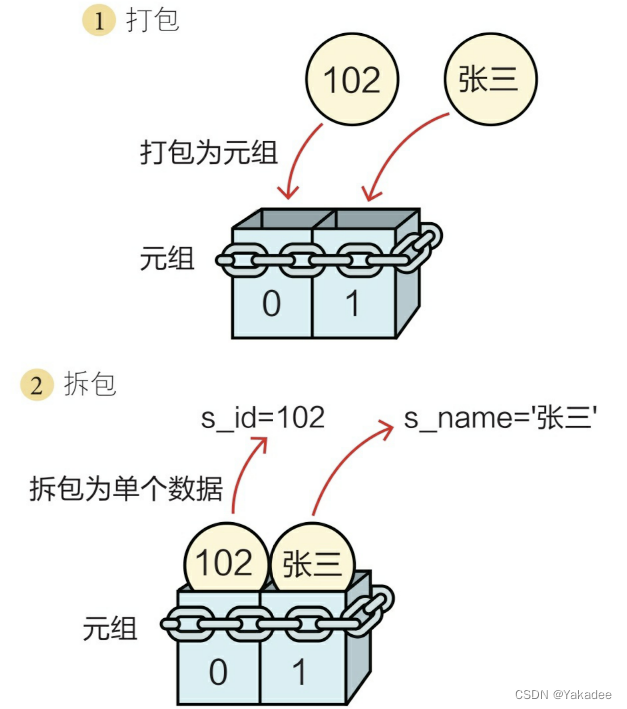
元组拆包
创建元组,将多个数据放入元组,这个过程称为元组打包。
将元组中元素取出,分别赋值给不同的变量。
>>> s_id,s_name=(102,"tom")
>>> s_id
102
>>> s_name
'tom'
集合
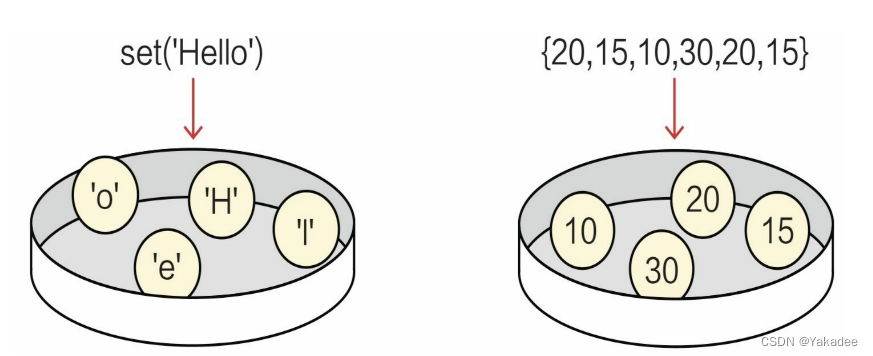
是一种可迭代,无序的,不能包含重复元素的容器
两种方式创建集合:
1.set(iterable):参数iterable是可迭代对象(字符串,列表,元组,集合和字典等)
2.{元素1,元素2,…}指定具体的集合元素,逗号分隔
修改集合
add(elem):添加元素,如果元素存在,则不能添加,不会报错
remove(elem):删除元素,如果元素不存在,报错
clear():清除集合
>>> sset={'tom','lily','hello'}
>>> sset.add('amanda')
>>> sset
{'amanda', 'lily', 'hello', 'tom'}
>>> sset.remove('hello')
>>> 'hello' in sset
False
>>> sset
{'amanda', 'lily', 'tom'}
>>> sset.remove('hello')
Traceback (most recent call last):
File "<pyshell#9>", line 1, in <module>
sset.remove('hello')
KeyError: 'hello'
>>> sset.clear()
>>> sset
set()
>>>
字典
可迭代,通过key来访问元素的可变的容器类型的数据
创建字典
两种方式创建:
1.dict()函数
2.{key1:value1,key2:value2…}
>>> dict({102:'tom',105:'amanda',103:'lily'})
{102: 'tom', 105: 'amanda', 103: 'lily'}
>>> dict(((102,'tom'),(105,'amanda'),(106,'lily')))
{102: 'tom', 105: 'amanda', 106: 'lily'}
>>> dict([(102,'tom'),(105,'amadna'),(103,'lily')])
{102: 'tom', 105: 'amadna', 103: 'lily'}
>>> dict([zip([102,105,103],['tom','amadna','lily']))
SyntaxError: closing parenthesis ')' does not match opening parenthesis '['
>>> dict(zip([102,105,103],['tom','amadna','lily']))
{102: 'tom', 105: 'amadna', 103: 'lily'}
>>> dict1={102:'tom',105:'amanda',103:'lily'}
>>> dict1
{102: 'tom', 105: 'amanda', 103: 'lily'}
>>>
修改字典
>>> dict1[103]
'lily'
>>> dict1[110]='jessic'
>>> dict1
{102: 'tom', 105: 'amanda', 103: 'lily', 110: 'jessic'}
>>> dict1[103]='honey'
>>> dict1
{102: 'tom', 105: 'amanda', 103: 'honey', 110: 'jessic'}
>>> dict1.pop(102)
'tom'
>>> dict1
{105: 'amanda', 103: 'honey', 110: 'jessic'}
>>>
访问字典视图
3种方法访问字典视图:
items():返回字典的所有键值对视图
keys():返回字典键视图
values():返回字典值视图
>>> dict1
{105: 'amanda', 103: 'honey', 110: 'jessic'}
>>> dict1.items()
dict_items([(105, 'amanda'), (103, 'honey'), (110, 'jessic')])
>>> list(dict1.items())
[(105, 'amanda'), (103, 'honey'), (110, 'jessic')]
>>> dict1.keys()
dict_keys([105, 103, 110])
>>> dict1.values()
dict_values(['amanda', 'honey', 'jessic'])
遍历字典
s_dict={102:'lily',105:'amanda',108:'tom'}
print('-----遍历-----')
for s_id in s_dict.keys():
print(str(s_id))
print('-----遍历-----')
for s_name in s_dict.values():
print(s_name)
print('-----遍历-----')
for s_id,s_name in s_dict.items():
print('id:{0}-name:{1}'.format(s_id,s_name))
函数和方法的区别:
方法隶属于类,通过类或者对象调用方法,例如list.append(x)
函数不属于任何类,可以直接调用,例如list(iterable)
语句流程控制
if循环
-
if语句
x = 5
y = 8
z = 4
s = 5
if x < y:
print(‘x is less than y’)
if x < y > z:
print(‘x is less than y and greater than z’)
if x <= s:
print(‘x is less than or equal to s’) -
if…else语句
x = 5
y = 8
if x > y:
print(‘x is greater than y’)
else:
print(‘x is not greater than y’) -
这里介绍 if elif else语句
x = 5
y = 8
z = 15
if x > y:
print(‘x is greater than y’)
elif x < z:
print(‘x is less than z’)
else:
print(‘上面的if 和elfi 语句都不会被执行的时候,才会到这里执行代码’)
while循环
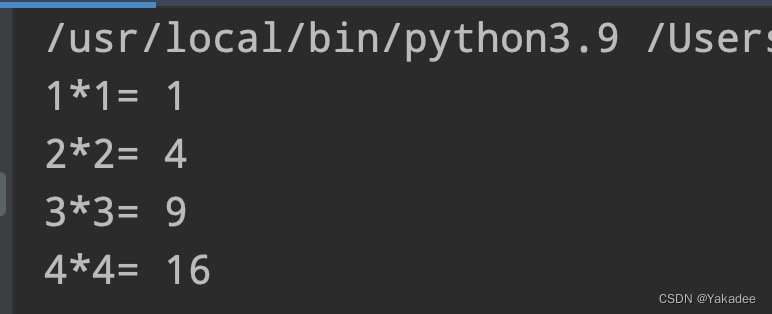
i=0
while i*i<10:
i+=1
print(str(i)+'*'+str(i)+'=',i*i)
- while…else循环
i=0
while i*i<10:
i+=1
print(str(i)+'*'+str(i)+'=',i*i)
else:
print('while over!')
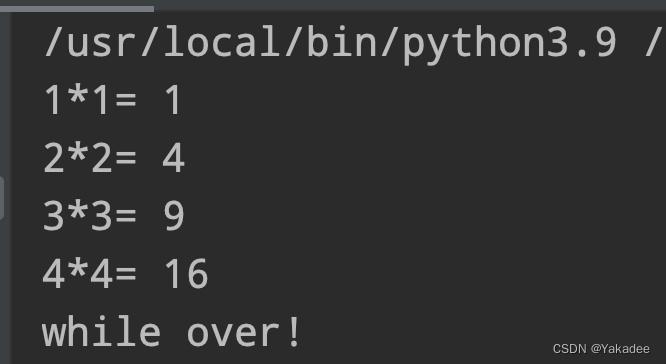
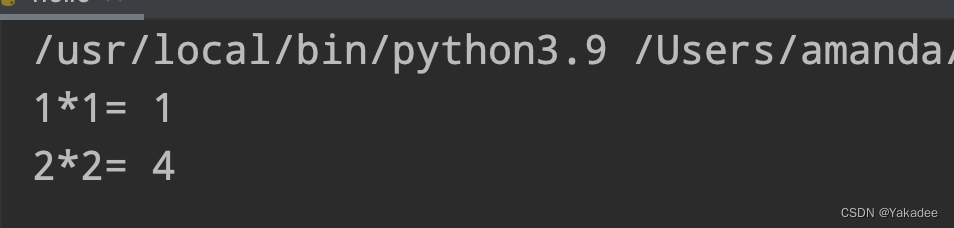
else是在循环体正常结束后才执行,如果遇到break,return和有异常发生时不会被执行
i=0
while i*i<10:
i+=1
if i==3:
break
print(str(i)+'*'+str(i)+'=',i*i)
else:
print('while over!')
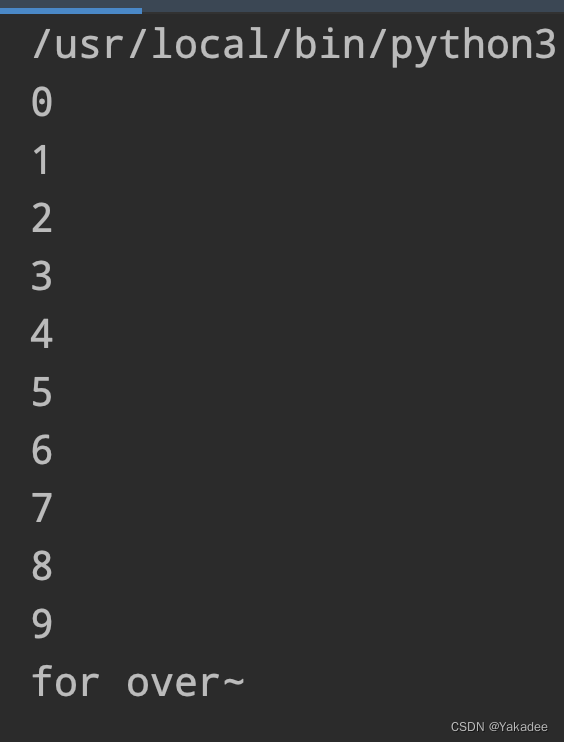
for循环
for-in语句
遍历列表 (for循环中的else和while循环使用一致)
for item in range(10):
print(item)
else:
print("for over~")
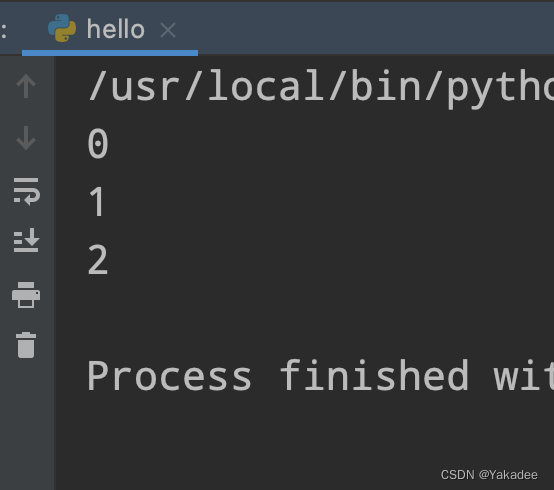
for item in range(10):
if item==3:
break
print(item)
else:
print("for over~")














 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









